







Real-Time Detection of Unauthorized Unmanned Aerial Vehicles Using SEB-YOLOv8s
使用SEB-YOLOv8s实时检测未经授权的无人机

0.论文摘要
摘要:针对无人机的实时检测,复杂背景下无人机小目标容易漏检、难以检测的问题。为了在降低内存和计算成本的同时保持较高的检测性能,本文提出了SEB-YOLOv8s检测方法。首先,使用SPD-Conv重建YOLOv8网络结构,以减少计算负担并加快处理速度,同时保留更多小目标的浅层特征。其次,我们设计了AttC2f模块,并用它替换了YOLOv8s主干中的C2f模块,增强了模型获取准确信息的能力,丰富了提取的相关信息。最后,引入双层路由注意优化网络的颈部部分,降低模型对干扰信息的注意并过滤掉。实验结果表明,该方法的mAP50达到90.5%,准确率达到95.9%,与原模型相比分别提高了2.2%和1.9%。mAP50-95提升2.7%,模型占用内存大小仅增加2.5 MB,有效实现了低内存消耗的高精度实时检测。
1.研究背景
随着社会技术的不断创新和科技电子设备的进步,无人机技术得到了快速发展,并在农业、交通、军事等领域得到了广泛应用[1,2],但这也引发了误用和违规行为的增加,对社会和国家安全构成潜在威胁[3]。
因此,反无人机系统对于确保公共安全、国家安全和关键基础设施的安全至关重要。然而,有效探测无人机是对抗无人机的先决条件,为反无人机系统提供必要的信息,以协助及时采取反制措施。
如今,由于特征提取能力强的深度学习目标检测方法发展迅速,将深度学习应用于无人机检测逐渐成为研究热点。这种方法在效率和成本方面具有优势。然而,计算机视觉对无人机的实时检测还存在一些挑战:一是无人机在复杂背景下容易被漏检和误检;二是小型靶标无人机频频被忽视;第三,难以平衡算法的检测成本和性能。YOLOv8是当前YOLO系列中的一个杰出算法,已经在计算机视觉领域取得了重大成就。YOLOv8采用无锚点检测方式,在检测速度和准确率方面表现出色。因此,本文对YOLOv8s进行了增强,提出了SEB-YOLOv8s算法,以平衡检测性能和计算资源消耗。这是为了解决探测小型目标无人机和无人机在复杂背景中被遗漏或误检测的倾向。我们对这项工作的主要贡献概述如下:
•我们提出了用于无人机实时检测的SEB-YOLOv8s算法。针对复杂背景下无人机小目标易漏检、难辨别的挑战,SEB-YOLOv8s检测方法显著提高了检测效率。这种改进来自于SPD-Conv模块的集成,AttC2f模块的设计,以最大限度地利用来自特征图的空间信息,以及BRA模块的引入,以平衡计算成本,同时保持高检测性能。
•AttC2f模块的设计增强了信息提取能力,可以聚合跨通道语义信息,捕捉不同维度之间的交互,提高浅层特征中小目标信息的利用率,提高小目标和复杂背景的检测性能。
•我们使用公共数据集Anti-UAV评估了我们提出的实时UAV检测算法。实验结果表明,它可以在降低成本消耗的情况下实时实现高精度检测,在性能方面明显优于YOLOv8s。检测性能堪比YOLOv8x的五分之一,而模型大小仍然只有它的五分之一。
2.相关工作
现有的无人机检测研究不仅依赖于计算机视觉技术,还使用其他检测技术来检测无人机。以下是一些典型的研究成果。
使用深度学习神经网络和计算机视觉技术来检测无人机是一种强大的方法。此前,Mahdavi等[4]将深度学习神经网络与SVM和KNN分类等传统机器学习方法分别用于无人机检测,发现神经网络分类器的准确率更高。为了探测更远距离的无人机,Magoulianitis等[5]利用超分辨率技术将数据在到达探测系统前放大两倍,增加了无人机在图像屏幕上的存在感。这与Faster R-CNN[6]检测系统相结合,提高了检测过程的召回率。Zeng等[7]通过提出基于RetinaNet的无人机检测网络,解决了无人机尺寸差异较大的问题。他们以Res2net为骨干网络,从多个感受野中提取无人机目标特征,并通过新颖的混合特征金字塔结构设计了卷积神经网络。这种结构实现了分层多尺度特征融合,增强了跨不同无人机尺寸检测的鲁棒性。针对漏检、精度低、检测速度慢等问题,Hamid R.Alsanad等[8]在YOLOv3[9]的基础上进行了改进,提高了检测规模,减少了小型无人机检测的漏检。这显示了优于传统检测方法的潜力,但具有单个大目标的无人机数据场景仍然缺乏对小型无人机和复杂场景下无人机的检测能力。为了检测容易出现漏检和误检的无人机,Cheng等[10]提出了无人机检测方法YOLOv4-MCA。该方法选择MobileViT作为骨干网,其轻量级特征可以降低计算成本,同时有效提取无人机目标的全局和局部特征。它还采用协调注意力来改进路径聚合网络(PANet),优化无人机目标的锚定框架。这种方法提高了检测效率,减少了漏检,并最大限度地减少了无人机的误检。Hansen Liu等[11]通过剪枝YOLOv4[12]的卷积通道和快捷层,设计了为快速移动无人机量身定制的实时检测算法,提高了无人机目标检测的速度,但代价是检测精度降低。Ulzhalgas Seidaliyeva等人[13]针对无人机快速移动的特点设计了量身定制的实时检测算法,提高检测精度。他们使用固定摄像头收集数据,并将探测无人机的任务分为两个独立的任务。为了提高无人机检测的准确性,使用固定摄像机收集数据,并将无人机检测任务分为两个独立的任务:检测运动物体和对检测到的物体(如无人机、鸟类和背景)进行分类。运动物体的检测基于背景减除,而分类使用卷积神经网络(CNN)进行。该方法在检测无人机时可以获得较高的精度和处理速度,但高度依赖静态背景,对复杂背景的适应性有限。吕耀文等人[14]旨在充分利用高分辨率无人机图像来提高无人机探测的准确性。作者利用静止摄像机获取的高分辨率图像检测无人机,提出了背景差分与改进YOLOv5s相结合的检测方法,排除了背景信息,提高了检测效率,但过度依赖静态背景,对复杂环境下的无人机检测无效。尽管有这些改进,但无人机的探测仍然面临挑战,因为小型无人机目标难以探测,并且在复杂背景下容易受到干扰。
除了图像处理技术,其他传感技术也被应用于无人机探测。Sara等[15]利用卷积神经网络(CNN)、递归神经网络(RNN)、卷积递归神经网络(CRNN)等深度学习技术,通过飞行中无人机独特的声学指纹来检测和识别无人机。它能够检测无人机的存在并识别无人机的类型,但无法确定无人机位置的准确信息。M.Yaacoub等[16]提出了一种基于卷积神经网络(CNN)和迁移学习的无人机声学识别方法,以提高反无人机系统的声学检测能力。该方法在大型音频数据集AudioSet上预训练CNN,并在自定义声学数据集上进行微调,实现了基于log-Meier谱特征的无人机声音的高效分类和检测,为基于深度学习技术的声音检测器研究奠定了基础。然而,该研究主要集中在声音检测上,并没有解决无人机位置的准确确定。现有的无人机检测技术依赖于深度学习,资源要求高,不易应用于嵌入式设备。Brighente等[17]开发了反无人机音频监视哨兵(ADASS),这是第一个可以在物联网设备中实现的基于噪声的无人机检测系统。该系统使用嵌入式机器学习模型和压缩卷积神经网络对来自机载麦克风的音频信号进行分类,使其能够远程监控飞行中的无人机。然而,其在复杂噪声环境中的有效性需要进一步研究。Przemyslaw Flak等人[18]提出了一种基于射频传感器网格的无人机监视系统,该系统使用分布式传感器网格和定制神经网络架构,可分为三个阶段,包括软件无线电(SDR)设备中的信号采集和硬件加速时频域变换计算、用于无人机存在检测的嵌入式计算机以及数据融合中心的无人机识别。射频方法的独特优势在于,它能够实现早期入侵检测(识别无人机的发射顺序并在起飞前指示操作员的位置)和对无人机进行分类。该系统不仅在嘈杂的模拟环境中表现出出色的性能,在室外场景中进行验证,而且在传感器网络中实现了高度的准确性。然而,它存在高数据传输负载和测试场景缺乏复杂性的问题。
这些非基于图像的检测方法在检测UAV方面表现出良好的能力,特别是在特定场景或特殊情况下(例如,当音频或RF信号很强时)。然而,非基于图像的方法的应用场景往往有限。与现有的基于图像和非基于图像的无人机检测方法相比,本文提出的SEB-YOLOv8s算法具有更广泛的适用性。它在在复杂背景下检测小型目标无人机和无人机,并且在资源使用方面也具有成本效益。我们相信这项工作将是对无人机探测领域的有效补充。该方法将在下一节中详细描述。
3.主要工作&核心思想
在本节中,首先,介绍YOLOv8算法;然后详细描述了本文提出的用于无人机目标检测的SEB-YOLOv8s网络,以解决实时检测无人机时小目标容易漏检和复杂背景下无人机目标难以检测的问题。
YOLOv8-YOLOv8N、YOLOv8s、YOLOv8m、YOLOv8l-和YOLOv8x有五种不同的模型,随着模型大小的增加,检测精度也会增加。该模型的网络结构由三个主要部分组成:主干、颈部和头部。网络结构如图1所示,图中的数字表示模型的层数。
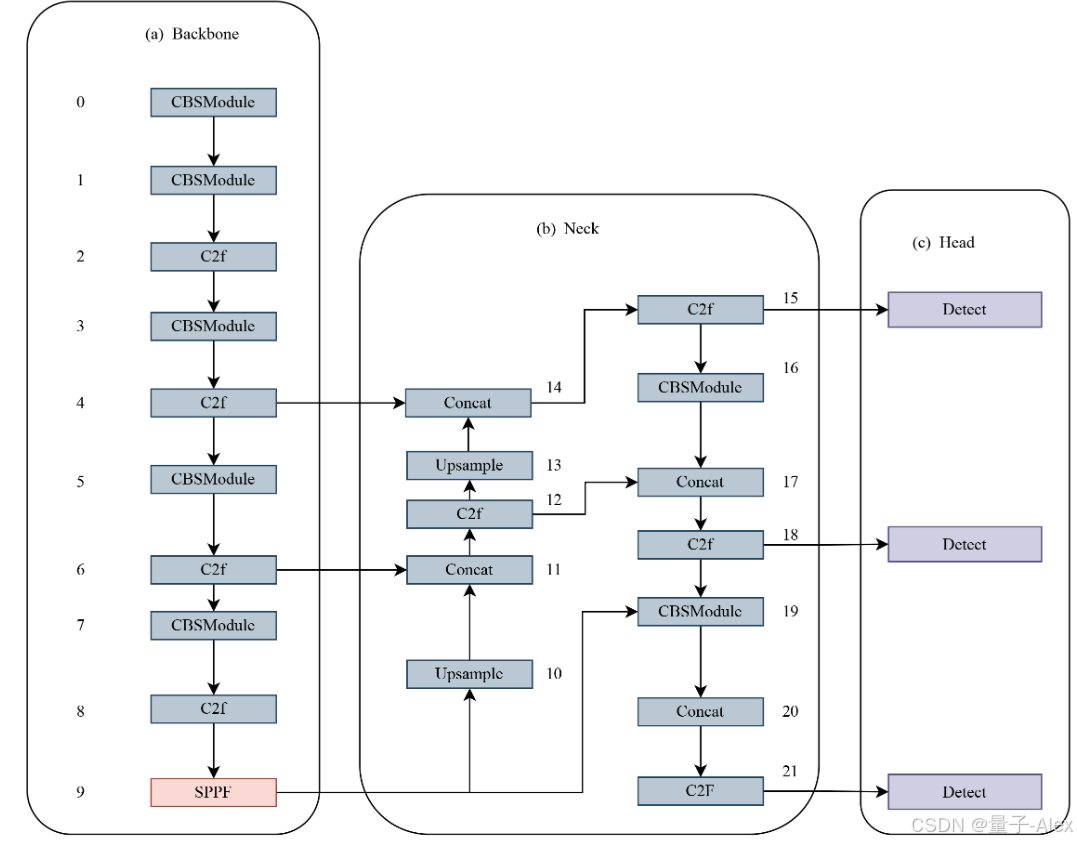
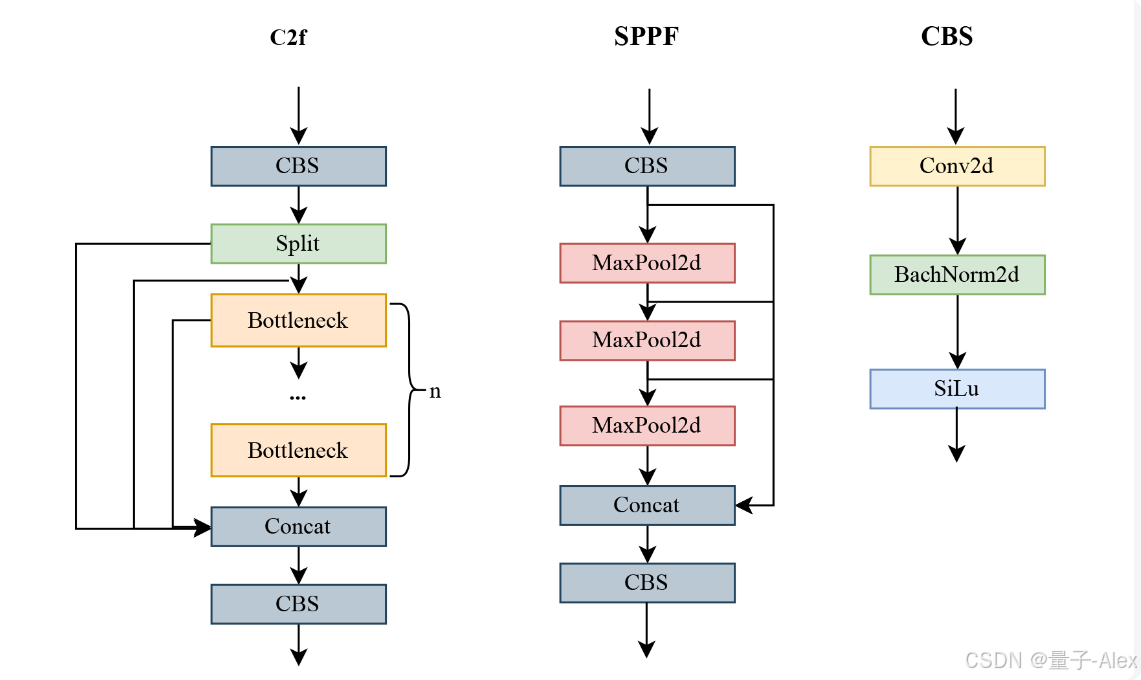
图1。YOLOv8的网络结构。
在主干部分,YOLOv8将修改后的CSPDarknet53作为主干网络,通过C2f模块获取不同尺度的特征。这里,C2f模块使用梯度分流连接,跨级部分模块(CSP)用于执行具有批量归一化和SiLU激活函数的卷积运算,最后通过快速空间金字塔池(SPFF)模块输出特征图。
在颈部部分,YOLOv8的灵感来自PANet[19]结构。与之前的模型相比,YOLOv8简化了上采样后的卷积运算PAN结构,在保证性能的同时减少了计算量以降低复杂度。通过结合PAN和FPN的优点,形成PAN-FPN自上而下和自下而上的融合特征,融合浅层和深层类型的信息,增加特征的信息量,提高特征图的质量,使其更加完整和丰富。
在头部部分,YOLOv8使用解耦的头部结构来检测头部。结构设计为检测框回归预测和目标分类的两个独立分支,分别选取两种不同的损失函数,即用于检测框回归预测的分布式焦点损失(DFL)[20]和用于分类选择的完全相交完全IoU(CIoU)[21]。这种解耦检测结构可以更好地适应不同任务的特点,提高模型在对象分类和检测框回归方面的性能。
3.1 SEB-YOLOv8s的体系结构
SEB-YOLOv8s的框架如图2所示,图中的数字表示模型的层。由于图像中小比例无人机检测不佳和复杂背景下无人机检测困难的挑战,YOLOv8尽管能够通过结合其颈部PAN和FPN的优势以及三个检测头来检测各种规模的无人机,但并不能完全满足多样化场景下实时无人机检测的要求,尤其是在检测复杂背景下的小目标和无人机时。为了缓解这些问题,本文使用YOLOv8s作为基础模型,旨在平衡模型大小和检测性能。同时在整体网络结构构建、提取特征语义信息丰富、注意力机制等方面进行改进。改进战略的主要思路概述如下:
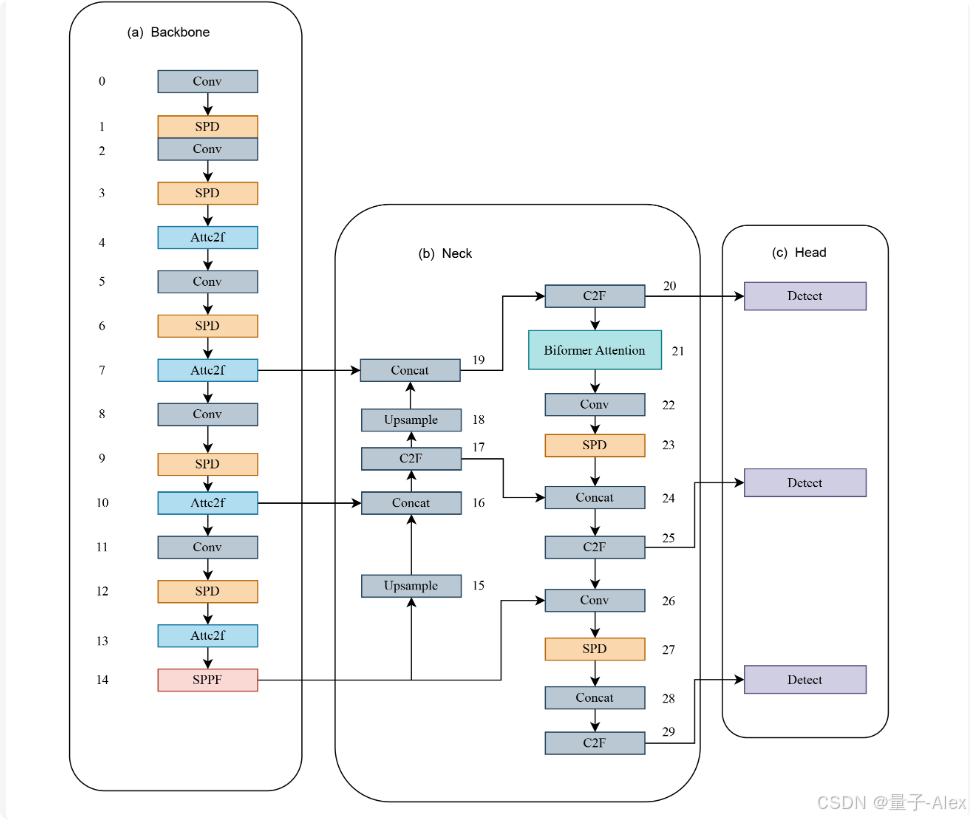
图2。SEB-YOLOv8s的网络结构。
首先,引入SPD-Conv模块,重新配置网络结构,以保留无人机在小目标或低质量图像上更多的浅层语义信息。
然后,为了提高浅层特征图中对无人机的注意力并抑制复杂背景的干扰,提出了AttC2f模块,使模型更充分地利用特征图的空间信息,其中引入的EMA模块具有不需要特征图降尺度的优点,并且能够提供更全面的特征图,引入EMA模块来提供高质量的像素级深度特征图,而不需要特征图降尺度。最后,引入两层路由注意机制,通过筛选特征图过滤掉最不相关的区域,以较少的计算量增加对无人机目标的注意,可以兼顾实时检测速度和更好的检测性能。
3.1.1 增强的功能细节
在探测无人机时,其在图像中的比例相对较小,难以在远距离探测无人机小目标。尽管深度学习神经网络已经在各个领域做出了重大贡献,但用于提取小目标特征的步进卷积和池化操作仍然会产生损失,尤其是在具有低像素计数或小目标的图像中。无人机分为大型、中型和小型,虽然YOLOv8的多尺度检测有助于无人机的检测,但多尺度融合通常涉及跨步卷积和最大池化。随着网络深度的增加,出现了细节信息丢失、特征表示不够准确等问题。传统卷积可以学习有限的特征;因此,对于小目标特征或不清晰图像的提取,结果往往不令人满意。在本文中,我们引入了一个非跨步卷积或池化模块(SPD-Conv)[22]来重新调整网络结构。
SPD-Conv由两部分组成:空间到深度(SPD)层和非跨步卷积。首先,SPD部分应用神经网络内的原始图像变换技术[23]扩展来对特征图进行下采样,然后进行非步幅卷积(步幅=1)来进一步变换特征图。SPD通过将原始特征图X切片成多个子特征图并沿通道维度连接它们以形成X’来对其进行下采样。每个子特征图是原始特征图的子集,具有一定程度的下采样。在SPD特征变换层之后,通过添加非跨步卷积层将下采样的特征图X′进一步变换为X′,以降低通道维数并提取更多的鉴别特征信息。这种方法有助于减少计算负担,加快网络的处理速度,同时保留重要信息。在本文中,我们将原始模型CBS模块中的跨步卷积替换为非跨步卷积,使用SPD结合非跨步卷积来调整网络结构,最大限度地减少无人机目标的特征损失,保留更多的浅层语义信息。
3.1.2 用AttC2f模块替换C2f
对于复杂背景中的无人机检测,背景和无人机的细节或特征交叉,无人机目标是一小部分,通常会出现特征要么没有提取出来,要么被错误分类为背景特征,导致检测泄漏。为了解决这个问题,通过引入一个名为AttC2f的新模块,对C2f模块进行了改进,其结构如图3所示。这种修改增强了对无人机目标的关注,对计算的影响最小。在AttC2f模块中引入了高效多尺度注意力模块(EMA)[24];EMA模块通过跨空间通道的语义信息的并行化和聚合来采用多尺度卷积进行学习。通过分支选择不同大小的卷积核允许CNN在相同的特征提取阶段内收集不同尺度的空间信息。此外,并行子网块的引入有助于有效地捕获不同维度之间的交互并在它们之间建立依赖关系,有效地捕获远程依赖关系和精确的位置信息,从而增强卷积神经网络(CNN)对高层特征图的像素级关注。
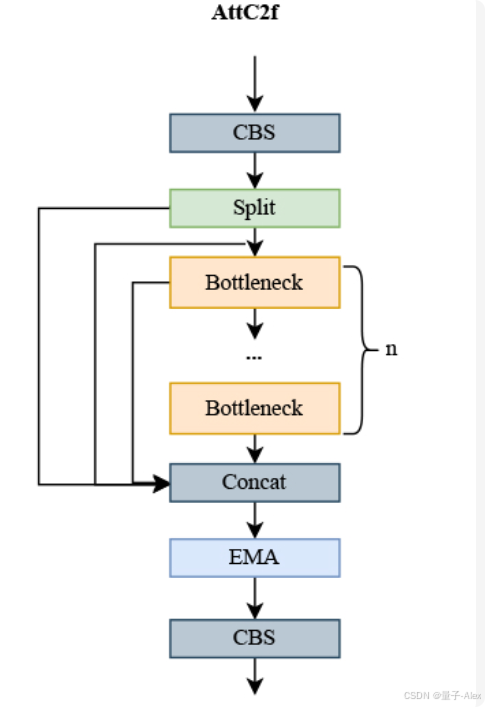
图3.AttC2f模块。
与通过降低通道的维度来建模跨通道关系的通道或空间注意力机制相反,降低通道维度来建模跨通道关系可能具有许多含义和缺点。首先,通道降维可能导致信息丢失,因为较少的通道可能无法完全捕获原始数据的所有细节。第二,计算成本可能会增加,尽管1 × 1卷积相对轻量级,但在大型网络中仍然需要考虑计算开销。超参数的选择也成为一个挑战,不恰当的选择会导致性能下降。此外,通道降维可能并不适用于所有任务,其有效性可能取决于任务的特性和数据的特性。最后,通道降维可能会降低模型的可解释性,因为较少的通道可能不如原始通道直观。EMA模块高效地学习通道描述,同时在卷积运算中保留通道维数,并提供更好的深度特征图,用于生成更好的像素级注意力。EMA的整体结构如图4所示。
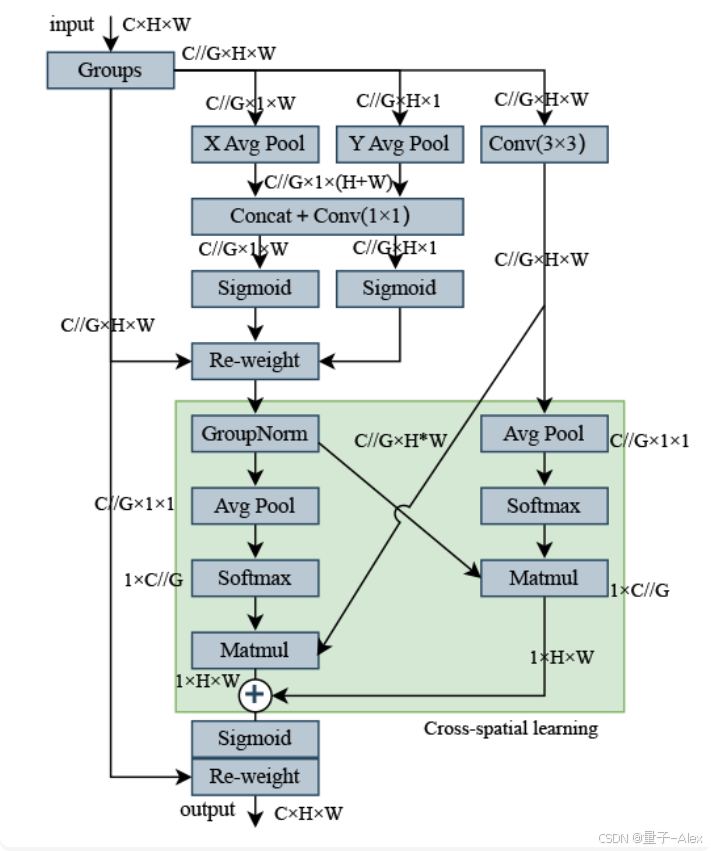
图4.EMA模块。
特征分组:EMA模块通过通道分组将输入特征图 X ∈ R H × W × C X ∈ \mathbb{R}^{H×W×C} X∈RH×W×C划分为多个跨通道维度的子特征 G G
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3676
3676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











