







5. Running PEST ...................................................................................................................108
5.1 Introduction.................................................................................................................108
5.1.1 General ................................................................................................................108
5.1.2 Checking PEST’s Input Data ..............................................................................108
5.1.3 Versions of PEST................................................................................................108
5.1.4 Starting PEST......................................................................................................109
5.1.5 Command Line Switches ....................................................................................109
5.2 The PEST Run Record File.........................................................................................114
5.2.1 An Example.........................................................................................................114
5.2.2 Echoing the Input Data Set..................................................................................123
5.2.3 The Parameter Estimation Record.......................................................................123
5.2.4 Optimised Parameter Values and Confidence Intervals......................................125
5.2.5 Observations and Prior Information....................................................................126
5.2.6 Objective Function ..............................................................................................127
5.2.7 Correlation Coefficient........................................................................................127
5.2.8 Analysis of Residuals..........................................................................................127
5.2.9 Kullback-Leibler (K-L) Information Loss Statistics...........................................127
5.2.10 Post-Calibration Parameter Covariance Matrix ................................................128
5.2.11 Correlation Coefficient Matrix..........................................................................129
5.2.12 Normalised Eigenvector Matrix and Eigenvalues.............................................129
5.3 Other PEST Output Files ............................................................................................130
5.3.1 General ................................................................................................................130
5.3.2 Parameter Value File...........................................................................................130
5.3.3 Parameter Sensitivity File ...................................................................................131
5.3.4 Observation Sensitivity File ................................................................................134
5.3.5 Residuals File ......................................................................................................135
5.3.6 Interim Residuals File .........................................................................................136
5.3.7 The Matrix File....................................................................................................136
5.3.8 The Condition Number File ................................................................................137
5.3.9 Singular Value Decomposition File ....................................................................138
5.3.10 LSQR Output File .............................................................................................138
5.3.11 Run Management Record File...........................................................................138
5.3.12 Pareto Output Files............................................................................................138
5.3.13 The Jacobian Matrix File...................................................................................138
5.3.14 Resolution Data File..........................................................................................139
5.3.15 Other Files.........................................................................................................139
5.3.16 PEST’s Screen Output.......................................................................................139
5.3.17 Run-time Errors.................................................................................................140
5.4 Stopping and Restarting PEST....................................................................................141
5.4.1 Interrupting PEST Execution ..............................................................................141
5.4.2 Restarting PEST ..................................................................................................141
5.4.3 Why Stop PEST?.................................................................................................141
5.5 If PEST Won’t Work ..................................................................................................142
5.5.1 General ................................................................................................................142
5.5.2 Model Output File not Found..............................................................................142
5.5.3 Objective Function Gradient Zero.......................................................................142
5.5.4 Erratic Objective Function Behaviour caused by Bad Derivatives.....................143
5.5.5 Other Factors Leading to Erratic Objective Function Behaviour .......................144
5.5.6 Excessive Number of Model Runs......................................................................144
5.5.7 Discontinuous Problems......................................................................................144
5.5.8 Parameter Correlation and Insensitivity..............................................................145
5.6 PEST Postprocessing ..................................................................................................145
5.6.1 General ................................................................................................................145
5.6.2 Calibration as Hypothesis-Testing ......................................................................145
5.6.3 Traditional Statistics............................................................................................147
5.6.4 Statistics Appropriate to Regularised Inversion..................................................147
5.6.5 Information Content of the Calibration Dataset..................................................147
5.6.6 Model Outputs based on Optimal Parameter Values ..........................................148
5. 运行PEST
5.1介绍
5.1.1一般
本章描述了如何运行PEST来解决一个基本的反问题,以及它在这样做时写入的文件类型。重点主要是在非并行环境中以“估计”模式运行PEST。更复杂的PEST行为模式,以及模型运行的并行化,是后面章节的主题。
5.1.2检查PEST的输入数据
在前面的章节中已经详细讨论了PEST的输入文件要求。在将这些文件提交给PEST进行参数估计运行之前,您应该检查其中包含的所有信息在语法上是否一致且正确。这可以使用本手册第二部分中描述的实用程序PESTCHEK, TEMPCHEK和INSCHEK来完成。
PEST本身对其输入数据集进行一些检查;如果它的任何输入文件中有任何语法错误,或者某些数据元素的类型不正确(例如,real而不是integer, integer而不是character), PEST将停止执行,并给出相应的错误消息。然而,PEST没有进行广泛的一致性检查。
因此,除非您使用上面提到的实用程序自己执行输入数据检查,否则PEST可能会基于错误的数据集开始执行。
有时会检测到错误,并且PEST将以错误消息终止执行。在其他情况下,PEST可能开始反转过程,只是在稍后的某个阶段终止执行,并出现一个运行时错误消息,该消息可能与最初引起问题的不一致没有什么关系。
5.1.3 PEST的版本
在撰写本文时,PEST的版本列在表5.1中。

表5.1中列出的所有PEST版本都运行在WINDOWS操作系统上。由于PEST源代码是免费提供的,用户可以自己编译UNIX版本的PEST、Parallel PEST和BEOPEST。
表5.1中列出的所有版本的PEST都可以互换使用。就反转引擎而言,它们都共享相同的源代码。然而,对于相同的逆问题,它们可能并不都提供相同的解决方案,特别是如果该问题是病态的,并且正则化没有得到适当的表述。不同的编译器以不同的方式进行计算和执行代码优化。通常情况下,这并不重要。然而,当试图对一个病态矩阵求逆时,它可能会产生很大的影响。
在某些情况下,模型运行的并行化也会产生影响。虽然雅可比矩阵的内容不受用于填充它的模型运行是串行还是并行进行的影响,但基于不同马夸特lambda值的参数升级测试可能会受到并行化的影响。后者是一个涉及决策制定的串行过程,特别是当参数达到其界限时。并行PEST和BEOPEST尝试在预期某些结果的情况下对这些模型运行进行“先发制人的并行化”。此外,由于有多个处理器可供使用,并行PEST和BEOPEST可能能够测试比使用串行PEST时更多的Marquardt lambda。虽然最终,所有版本的PEST都会选择一个参数集用于下一次迭代,该参数集就PEST当前的操作模式而言是“最佳的”,但串行版本的PEST和并行版本的PEST之间的参数集可能会有所不同,因为在并行环境中可能会测试更多的Marquardt lambda,并且由于PEST对参数达到其边界的响应在这两个环境之间存在差异。因此,通往最优参数集的路径可能会有所不同。
Doherty(2015)解释说,反演过程的结果不是“正确”的参数集,特别是在数据稀缺和雅可比矩阵的零空间有很多维度的情况下。期望的最佳反演结果是误差方差最小的参数集。PEST套件提供线性和非线性工具,用于评估估计参数集的校准后不确定性。通常这种不确定性很高。不同版本的PEST计算的最小误差方差参数集的估计值之间的微小差异应该从这个角度来看待
5.1.4启动PEST
表5.1中列出的所有PEST版本都可以使用命令PEST case运行,其中“PEST”被该表第一列中列出的适当可执行文件的名称和case所取代。pst是PEST控制文件的名称。然而,BEOPEST需要一个命令行开关来通知它必须用于TCP/IP通信的端口。
5.1.5命令行切换
如果使用,命令行开关跟随命令中的PEST控制文件的名称来运行PEST。例如,如果使用“/i”开关启动PEST执行,则使用命令pest case /i
一般来说,一次只能使用一个命令行开关,因为使用这些开关的结果通常是互斥的。例外情况是“/t”开关和BEOPEST“/h”开关。在启动BEOPEST执行时,必须使用“/h”开关。由于该开关的功能与其他PEST开关的功能没有重叠,因此在启动BEOPEST时,也可以使用后者中的任何一个。如果有,必须放在/h开关前。因此这个命令是合法的。
![]()
而这个命令不是:
![]()
现在详细讨论每个PEST命令行开关的作用。
![]()
如果PEST以“/i”开关启动,它会立即提示输入JCO文件的名称(例如:
存储雅可比矩阵的二进制文件)。它在第一次迭代中使用存储在该文件中的雅可比矩阵。因此不需要进行基于有限参数差分的填充矩阵所需的模型运行。然而,对于所有后续迭代,PEST以通常的方式填充雅可比矩阵。
“/i”开关在许多上下文中都很有用。例如,它允许您更改PEST设置,并以很少的计算代价重新开始反转过程。更重要的是,它促进了校准约束蒙特卡罗分析的实现。
使用本手册第二部分中讨论的PREDUNC7和RANDPAR实用程序,可以对后验参数协方差矩阵进行线性近似采样。然后可以调整构成这些样本的参数值,使校准目标函数降至某一阈值以下。对于所有采样参数集的重新调整过程的第一次(通常是唯一的)迭代,可以使用相同的雅可比矩阵。
如果使用“/i”开关启动了PEST执行,那么一旦它开始执行,它就会提示
![]()
您应该使用在之前的PEST运行期间(通常是第一次迭代)生成的JCO文件的名称来响应它。该文件的名称可以是case。其中case是当前PEST case的文件名基础。然而,这是一个危险的过程,因为JCO填充将被破坏,然后在当前的PEST运行中被覆盖。JCO文件使用不同的文件名基要好得多。
用于生成JCO文件的PEST控制文件必须以与当前PEST控制文件相同的顺序引用相同的参数(具有相同的日志转换状态),而PEST可以通过使用“/i”开关来访问JCO文件。然而,两个文件之间的先验信息可能不同。权重也可以不同。如果您对当前PEST控制文件与以前的Jacobian矩阵文件的兼容性有任何疑问,请使用JCO2JCO实用程序创建一个保证兼容性的新JCO文件。可以使用JCOCHEK实用程序检查兼容性。请参阅本手册的第二部分。
“/d”和“/s”都是重启开关。前者用于重新启动串行PEST运行,而后者用于重新启动并行PEST(包括BEOPEST)运行。当使用这两个开关中的任何一个启动PEST时,它立即读取一系列二进制文件,这些文件是在先前基于相同PEST控制文件运行的PEST上写入的。大多数这些文件的文件名基础与当前的PEST控制文件相同。然而,重要的是要注意,只有当PEST控制文件的“控制数据”部分中的RSTFLE变量设置为“restart”时,才会保存这些重启文件。
使用这些开关中的任何一个都会指示PEST在其先前执行中断的同一位置重新开始执行。因此,没有模型运行被浪费。串行和并行版本的PEST需要不同的开关,因为在这两种情况下,PEST以不同的方式存储其重启数据。这源于在这两种情况下管理模型运行的不同方式。
当使用“/r”开关重新启动PEST时,它不会在它停止的地方恢复执行;相反,它在迭代开始时重新开始参数估计过程,在迭代开始时,它被先前中断。
PEST也可以用“/j”开关重新启动,这是其用户交互功能的一个组成部分。在这种情况下,它在最后一次尝试计算参数升级的反转过程的那个点重新开始执行。详细信息请参见6.2节。
(随着现代规范化方法的引入,用户干预很少(如果有的话)。)请注意以下与PEST重启开关有关的要点。
1. 并行PEST和BEOPEST不能用“/d”开关重新启动。
2. 非并行PEST不能用“/s”开关重新启动。
3. 先前停止的并行PEST运行可以使用“/r”或“/j”开关重新启动为非并行PEST,并行PEST或BEOPEST。
4. 先前停止的非并行PEST运行可以使用“/r”或“/j”开关重新启动为非并行PEST、并行PEST或BEOPEST。
5. 先前停止的并行PEST或BEOPEST运行不能使用“/s”开关重新启动为非并行PEST。
6. 先前停止的非并行PEST或BEOPEST运行不能使用“/d”开关重新启动为并行PEST。
在这个阶段,您可能想知道为什么,如果“/s”和“/d”开关具有相同的作用,它们不能在并行和非并行PEST之间互换使用。如上所述,原因在于这两个版本的PEST之间的运行管理是不同的。对于并行PEST,运行不一定按顺序进行。重新启动文件中的运行结果也没有按顺序存储。对于非并行的PEST,重启文件不保存运行结果;而是包含雅可比矩阵的片段。当使用高阶差分进行导数计算时,这可以大大节省文件存储。此外,这种重新启动方法更容易与外部导数计算相结合- -目前只有在PEST的非并行版本中才有这种方法。
然而,可以自由地承认,需要一个通用的运行管理器。希望这将是未来PEST发展的结果。在这个阶段,“/s”和“/d”开关将组合在一起。

使用“/t”开关,您可以提供一个简短的文本字符串,然后将其记录在PEST运行记录文件的顶部附近,并且在反转过程的每次迭代期间也将其写入屏幕。如果正在进行一系列PEST运行(例如,作为校准约束随机参数字段的零空间蒙特卡罗生成的一部分),这允许用户知道当前PEST运行序列中的位置。
用户提供的文本字符串必须跟随“/t”命令行开关。例如,假设与特定的PEST运行(其中PEST控制文件的名称是case.pst)相关联的文本字符串是“我的文本”。这可以通过如下方式运行PEST来提供。
![]()
应注意以下几点。
•运行描述符文本必须用双引号括起来。
•必须紧跟“/t”开关。
•如果提供了“/t”开关而没有随后的文本运行描述符,PEST将记录一条错误消息,然后停止执行。
•其他开关可以与“/t”开关和运行描述符文本一起出现在PEST命令行上。它们可以在“/t”开关和相关的运行描述符文本之前或之后。但是,“/t”开关不能跟随BEOPEST运行所需的“/h”开关和辅助信息,因为这些必须总是最后出现在BEOPEST命令行上。
•为重新启动的PEST运行提供的运行描述符可以不同于为原始PEST运行提供的运行描述符。它是特定于运行的,而不是特定于案例的。
•如果在命令行中省略了“/t”开关和文本运行描述符,那么无论是在屏幕上还是在运行记录文件中都不会提及(空白)运行描述符。
运行描述符写在运行记录文件的顶部。在重新启动该文件的记录之后,它也会立即记录在运行记录文件中。它在每次PEST迭代开始时被写入屏幕。请看下面的例子。

![]()
“/p1”开关只能与并行PEST和BEOPEST一起使用。它指示并行PEST或BEOPEST与用于填充雅可比矩阵的模型并行地进行反演过程的第一次模型运行。第一次模型运行用于计算初始目标函数,并用于计算有限差分导数计算中使用的参考模型输出。将此运行与参数增量变化的运行并行进行,可以防止代理在等待此初始运行完成时处于空闲状态。
本手册的第11章详细讨论了模型运行的并行化。
![]()
如果PEST或BEOPEST以“/f”命令行开关启动,它们根本不进行参数估计。相反,它们进行一系列模型运行,专门用于使用不同的参数集计算模型输出。这些参数集必须在运行这些程序之前记录的一系列参数值文件中提供。这些参数值文件可以使用pest套件实用程序(如RANDPAR、RANDPAR1和LHS2PEST)来构建。正如本手册第二部分所讨论的,参数值文件的协议是这样的,每个文件中存储一组参数。PEST/BEOPEST期望将这些文件命名为具有公共文件名基的序列。假设文件名库为sample。那么参数值文件必须命名为sample1。sample2不相上下。par之上。票面价值,等等。序列不需要从1开始;但是序列中不能有间隙。这些文件中出现的参数名称必须相同。它们必须与PEST控制文件中出现的参数相对应,在此基础上运行PEST或BEOPEST。
假设使用以下命令启动PEST:
![]()
然后在开始执行时,它读取PEST控制文件case.pst。然后发出一系列提示。这些提示以及对这些提示的可能响应如下所示。

对上述提示的响应指示PEST读取文件sample101。对样200。以获得100组参数值。(如果从这些文件中读取的参数名称与PEST控制文件案例中记录的参数名称不一致。pst, PEST将停止执行并显示相应的错误消息。)然后PEST根据这些参数值执行模型运行。每次模型运行完成后,PEST计算目标函数分量,并将其写入屏幕和运行记录文件中;它还在运行结果文件中记录该运行的参数值和模型输出。然后启动下一个模型运行。
运行结果文件的规范在本手册的第二部分中提供。
假设使用以下命令启动BEOPEST:
![]()
然后,除了上面的提示,它还会问:
输入并行运行包大小:
假设对这个提示的响应是“50”。然后BEOPEST管理器将以50个包为单位执行模型运行。目标函数计算,并在运行结果文件中记录运行结果,然后在每个运行包完成时进行。重要的是要确保选择的运行包大小可以使代理空闲的可能性最小化;因此,在上述示例中,可用于执行模型运行的代理数量应该是5、10、25、50或100。实际上,运行包的大小没有理由不能等于必须计算模型输出的参数集的总数。这是一个方便的问题。然而,有时运行包大小的一个有用选择是一个数字,它是可用代理数量的一个小倍数。这允许您在完成模型运行的完整集合之前查看目标函数,从而允许验证模型的行为是否符合您的期望。另一方面,如果模型运行时间对参数值敏感,则由于其他代理上的模型运行时间较慢,一些代理在等待模型运行数据包完成时可能会间歇性地处于空闲状态。因此,如果运行包大小等于必须进行的运行次数,则可以获得最大的效率。
在模型运行失败的情况下,如果以“/f”开关启动,PEST和BEOPEST都不会停止执行并显示错误消息。PEST和BEOPEST也不会尝试使用另一个代理重复失败的模型运行。相反,PEST和BEOPEST都假定模型不喜欢提供给它的参数集。目标函数记为-1.11E35。所有与违规参数集相关的模型输出都记录在运行结果文件中为-1.11E35。因此,很容易识别模型运行故障。
正如本手册第二部分所记载的,参数值文件为PEST用于向模型输入文件写入数字的PRECIS和DPOINT变量提供值;它还为每个参数提供SCALE和OFFSET。当使用" /f "命令行选项运行时,PEST和BEOPEST在读取它们所指向的参数值文件序列时忽略所有这些。相反,所有这些变量的值都是从PEST控制文件中获得的。这使得编写参数值文件的参数值生成器不必知道这些控制变量的值。
5.2 PEST运行记录文件
5.2.1举例
当PEST执行时,它将参数估计过程的详细记录写入名为case的文件。其中case是通过其命令行定向到的PEST控制文件的文件名基础。当参数和/或观察值数量很大时,该文件可能会变得非常长,以至于用户很难在其中导航。如果将PEST控制文件的“控制数据”部分中的VERBOSEREC变量设置为“noverboserec”,则可以大大缩短。
图5.2显示了这样一个运行记录文件;与图5.2对应的PEST控制文件如图4.1所示。请注意,这个例子并没有证明测量和基于优化参数集计算的相应模型结果之间有很好的拟合。这是因为它是为了演示参数估计过程的许多方面而制作的,这些方面将在下面的页面中讨论。还要注意,PEST是在“估计”模式下运行的,以便产生如图5.2所示的运行记录。在“预测分析”、“正则化”或“帕累托”模式下运行PEST会产生略有不同的运行记录文件。
图5.2 PEST运行记录文件图4.1显示了相应的PEST控制文件
现在详细讨论PEST运行记录文件的各个部分。
5.2.2回显输入数据集
PEST通过读取所有输入数据开始执行。一旦读取,它就会将大部分数据回显到运行记录文件中。因此,该文件的第一部分只是对PEST控制文件中包含的大部分信息的重述。请注意,字母“na”代表“不适用”;在图5.2中,多次使用“na”来表示某个特定的PEST变量对反演过程没有影响。因此,例如,参数“ro1”的更改限制类型不适用,因为该参数是固定的。
运行记录文件中引用的参数初始值及其上限和下限的数字可能与PEST控制文件中提供的数字略有不同。只有当模型输入文件中该参数占用的空间不足以表示这些数字中的任何一个,使其达到与PEST控制文件中引用的数字相同的精度时,才会发生这种情况。然后,PEST调整这些数字的内部表示,使它们的表达精度与它们被写入模型输入文件时的精度相同。
5.2.3参数估计记录
PEST对输入数据进行回调后,计算由初始参数集产生的目标函数;它将这个初始目标函数值与初始参数值本身一起记录在运行记录文件中。然后,从第一次迭代开始,认真地开始反转过程。在计算雅可比矩阵后,PEST尝试使用一个或多个马夸特lambda来改进目标函数。当它这样做的时候,它记录相应的目标函数值,在迭代开始的时候以绝对的形式和作为目标函数值的一部分。
在图5.1的第一次迭代期间,PEST测试了两个马夸特lambda;因为第二个lambda导致的目标函数相对于第一个测试的下降小于0.03(即PHIREDLAM),所以PEST不测试任何进一步的lambda。相反,在列出更新的参数值以及计算更新的参数集的参数值(即迭代开始时的参数值)之后,它将继续进行下一次迭代。注意,在迭代结束时记录的“前一个参数值”与前一个迭代中确定的值不一致的唯一情况是,当刚刚进行三点或五点导数计算时,前一个迭代未能降低目标函数;此时,PEST将目前达到的目标函数值最小的参数集作为新迭代的起始参数。
在每次迭代结束时,PEST记录两个或多个非常重要的信息片段(取决于它的输入设置);在图5.1的情况下,它是两个。这是最大因子参数变化和最大相对参数变化。正如前几章所讨论的,每个可调参数必须指定为因子限制、相对限制或绝对限制;在图5.1中,所有可调参数都是因子限制的,因子限制为3.0。在高度非线性的反演环境中,因子、相对和绝对变化极限(即FACPARMAX、RELPARMAX和absolute (N))的适当设置对于实现反演过程的稳定性可能很重要。请注意,除了迭代过程中遇到的最大因子值和相关参数更改之外,PEST还记录了经历这些更改的参数的名称。在没有任何正则化(例如奇异值分解、LSQR和/或Tikhonov)的情况下,这些信息可能对决定哪些参数(如果有的话)应该固定,或者在反转过程中遇到麻烦时暂时保持在当前值至关重要。有关用户干预可用选项的详细信息,请参阅本手册的第6章。然而,请注意,PEST提供访问的数值正则化方法提供了比人工正则化及其随之而来的用户干预需要更好的实现反演稳定性的方法。
在每次迭代结束时记录最大因素、相对和(如果相关的话)绝对参数变化也可以帮助您判断是否明智地设置了相关的更改限制变量(即FACPARMAX、RELPARMAX以及可能的一个或多个absolute (N)变量)。在本例中,只需要最大因子变化,因为没有参数是相对有限的或绝对有限的;然而,仍然记录最大的相对参数变化,因为PEST的终止标准之一涉及使用相对参数变化。请注意,如果图5.1中的某些参数是相对限制或绝对限制的,则这部分运行记录将略有不同,因为只有因子限制的参数才会提供最大因子参数变化。最大相对参数变化将仅适用于相对有限的参数,最大绝对变化将仅适用于绝对(N)限制的参数(对于每个N)。然而,由于其与上述终止准则的相关性,将添加进一步记录所有参数的最大相对参数变化的行。
从图5.1的PEST运行记录可以看出,在迭代2中,其中一个参数“h2”发生了允许的最大因子变化,从而限制了参数升级向量的大小。在迭代3中,参数“h1”通过引起允许的最大参数因子变化来限制参数升级向量的大小。
如果将PEST控制文件中的FACPARMAX设置为高于3.0(建议设置默认值10.0),那么这种情况下的收敛可能会更快地实现。
在第二次迭代开始时,参数“ro2”处于其上界。在计算雅可比矩阵并计算升级向量后,PEST注意到参数ro2不希望移动回其域;因此,它暂时将该参数冻结在其上限,并仅根据剩余的可调参数计算升级向量。PEST通知用户,因此暂时禁止移动参数“ro2”。在迭代3开始时,再次释放参数“ro2”,以防在前一次迭代中,随着其他可调参数的升级,它想要回到其域的内部部分。
在第三次迭代中,只测试一个Marquardt lambda,通过使用这个lambda,目标函数已经降低到0.3倍以下;0.3是用户为PEST控制变量PHIRATSUF提供的值。
在第4次迭代结束时,PEST计算出与第3次迭代相比目标函数的相对减少小于0.1;也就是说,它小于用户提供的有害生物控制变量PHIREDSWH的值。因此,当至少一个参数组(本例中的两个组)的输入变量FORCEN被设置为“switch”时,PEST记录了这样一个事实,即它将从现在开始使用中心差异来计算这些组成员的导数。然而,中心导数的使用不会导致目标函数的进一步显著降低,也不会导致参数值的急剧变化,目标函数几乎通过仅使用正导数而尽可能地减小。(在其他情况下,特别是涉及比上述示例更多的可调参数的情况下,引入中心导数通常可以使停滞的反演过程再次移动。)图5.1所记录的参数估计过程在迭代8结束时,当最低的4个目标函数值(即NPHISTP)彼此之间的相对距离小于0.005(即PHIREDSTP)时终止。(如本手册其他地方所述,允许PEST终止反转过程本身并不重要。如果您觉得目标函数不太可能进一步下降,您可以随时终止反转过程。这可以节省许多浪费的模型运行。)注意,PEST在反演过程开始时和每次迭代开始时列出了当前目标函数的值,它还列出了每个观察组(包括仅由先验信息组成的观察组“prgp1”)对目标函数的贡献。这是有价值的信息,因为如果用户注意到一个特定的群体要么主导了目标函数,要么被另一个贡献者“视为”主导的结果,他/她可能希望调整观察或先验信息权重,并再次开始反转过程。本手册第2部分中记录的PWTADJ1实用程序可以自动执行权重调整过程。
5.2.4优化后的参数值和置信区间
在完成反转过程之后,PEST将该过程的结果打印到运行记录文件的第三部分。首先,它列出估计的参数值。这个过程分为三个阶段;可调参数,然后是固定参数,最后是任何固定参数。
如果在反演过程中没有使用正则化,PEST然后计算估计参数的95%置信限。但是,您应该仔细注意以下关于置信限的要点。
•置信限只能在计算后验协方差矩阵的线性近似时获得。如果,由于任何原因,它没有被计算(例如,因为逆问题是病态的,因为奇异值分解或LSQR被用来解决逆问题,或者因为已经使用了Tikhonov正则化),那么将不会提供置信限。要在这些条件下建立参数和预测置信限,必须使用本手册第二部分中记录的实用程序,如GENLINPRED、PREDUNC7和其他程序。
•正如PEST运行记录文件中所指出的,参数置信限是基于相同的线性假设来计算的,该假设用于推导每次PEST迭代期间实施的参数改进方程。如果置信限很大,它们很可能会延伸到参数空间,而不是线性假设本身。这将特别适用于对数转换参数,在PEST运行记录中引用的置信区间实际上是由PEST从协方差矩阵评估的参数的对数的置信区间。如果置信区间在对数域中由于线性假设的破坏而被夸大,那么它们在非对数变换数的域中将被夸大得多。
•95%置信区间的计算不考虑参数上界和下界。因此,上限或下限可以位于参数允许的范围之外。在图5.1中,“ro2”的置信上限远高于参数输入变量PARUBND为该参数提供的允许上限。PEST不会截断参数域边界的置信区间,以免提供校准后参数确定性的过度乐观印象。
•计算参数置信区间高度依赖于支撑模型的假设。如果可估计参数的定义是人工正则化过程的结果,在这个过程中,为了实现问题的完备性,消除了不可估计的系统属性异质性,那么归因于这些参数的不确定性可能低估了与重要模型预测可能依赖的系统属性细节相关的不确定性。这可能导致对预测不确定性的严重低估。
没有为绑定参数提供置信限。所有绑定参数的父参数都是“骑在它们的背上”来估计的;因此,各自父参数的置信区间反映了它们与关联参数的联系。
注意,在PEST运行结束时,还可以在PEST参数值文件中找到估计参数值的列表。它具有与PEST控制文件相同的文件名基础,但扩展名为“。par”。
5.2.5观察值和先验信息
在运行记录文件中记录估计的参数集后,PEST记录测量的观测值,以及根据估计的参数集计算的模型生成的对应值。还列出了两者之间的差异(即残差),以及用户提供的观测权值集。当使用协方差矩阵而不是特定观察组的权重时,字符串“Cov.Mat。,而不是PEST控制文件中提供的重量(在这种情况下没有意义)。根据观察结果,列出了用户提供和模型优化的先验信息值;先验信息值是先验信息方程右侧的数字。正如对观测所做的那样,残差和用户提供的权重被列示为先验信息方程。
5.2.6目标功能
接下来列出目标函数,以及不同观察组对目标函数的贡献。
5.2.7相关系数
接下来在运行记录文件中记录与当前参数估计问题相关的相关系数,该相关系数由Doherty(2015)的公式5.3.2计算得出。
5.2.8残差分析
运行记录文件的下一部分列出了一些与残差相关的统计数据——首先是所有残差,然后分别是每个观察组(包括分配了先验信息的任何观察组)。理想情况下,在参数估计过程完成后,加权残差的均值应为零,并且是随机分布的。运行记录文件的这一部分中包含的信息有助于评估是否存在这种情况。它还允许用户立即识别异常值(那些残差异常高的观测值)。
在计算残差统计量时,忽略权值为零的观测值。
5.2.9 K-L信息丢失统计
接下来记录AIC、AICC、BIC和KIC信息标准。参见Doherty(2015)第5.5.6节,了解这些标准的定义和相应的讨论。应注意以下几点。
1. 以上统计数据仅在PEST以“估计”模式运行时计算;如果PEST以“预测分析”、“正则化”或“帕累托”模式运行,则不计算它们。如果使用截断奇异值分解或LSQR实现反问题的解,也不计算它们。
2. 如果一个问题非常不确定,以至于协方差矩阵无法计算(由于J tQJ不能被反转),那么这些统计数据也将无法计算。
作者必须承认,在高度参数化的反演和伴随的不确定性分析可以使用本手册后面描述的高效、最先进的正则化方法进行的情况下,他看不到这些统计数据的用处。他们忽略了一个事实,即世界是一个复杂的地方,“最大可能性”在这种复杂性面前失去了意义。
相反,本手册第二部分中描述的由PREDVAR1实用程序计算的统计数据可以识别自然系统的复杂性。他们还认识到这样一个事实,即一种或另一种正则化对于反问题的唯一解是必需的,并且“唯一性成本”是在校准模型中表示自然系统属性的分辨率的重大损失。PREDVAR*工具套件所采用的方法提供了一种比K-L统计更连贯的方法来估计用于解决反问题的最佳参数数量。他们使用奇异值分解作为探索方法,利用过少参数引起的系统细节损失来对抗过多参数引起的观测放大或结构噪声。
实际上,现在建模者在校准环境模型时不需要追求参数简约的路径。现代正则化方法保证了模型校准逆问题的最小误差方差的解决,而不管它的病态状态。在模型被校准后,零空间蒙特卡罗等方法允许探索模型预测的不确定性,其中主要贡献者可能是无法唯一估计的参数-如果遵循K-L统计给出的建议,这些参数将从模型中完全省略。毕竟,如果模型要探索预测的不确定性,就必须在模型中表示可以估计的参数;通常是那些不能唯一估计的参数需要在用于该目的的模型中表示。进一步的讨论见Doherty(2015)。
5.2.10校准后参数协方差矩阵
当PEST以“估计”或“预测分析”模式运行时,如果既不使用奇异值分解也不使用LSQR求解逆问题,则在PEST运行记录文件的末尾记录三个矩阵。这些是校正后的参数协方差矩阵、参数相关系数矩阵和参数协方差矩阵的特征向量矩阵(后两个矩阵由第一个矩阵推导而来)。
校正后协方差矩阵采用Doherty(2015)式5.2.13计算。
正如文中所解释的那样,以这种方式计算的不确定性没有考虑通常需要的人工正则化,而这种正则化通常需要表述一个适定的逆问题。因此,它们没有考虑到这样一个事实,即通过反演过程调整的参数可能在很大一部分参数空间上平均(从而消除了该空间内系统属性异质性的表达)。它们也不代表由于不可估计而被捆绑或固定的参数。
协方差矩阵始终是一个具有尽可能多的行(和列)的方形对称矩阵,因为有可调参数;因此,对于反演过程中出现的每一个参数,都有一个行(列),这个行(列)既不固定也不捆绑。协方差矩阵中行(列)的排列顺序与前面估计参数值列表中可调节参数的出现顺序相同。(这与PEST控制文件和运行记录文件的第一部分中可调参数的出现顺序相同。)校正后协方差矩阵的元素属于PEST实际调整的参数,是反演过程的副产品;这意味着当参数进行对数变换时,与该参数相关的协方差矩阵的元素实际上属于该参数的对数(以10为底)。还要注意,占据协方差矩阵元素的方差和协方差只有在其计算所基于的线性假设有效的情况下才有效。
协方差矩阵的对角元素为可调参数的校正后方差;对于图5.1所示的运行记录文件,这些差异从左上到右下依次属于参数log(“ro2”)、“h1”和log(“h2”)。
参数的方差是其标准差的平方。
协方差矩阵的非对角元素表示参数对之间的协方差;因此,例如,占据上述协方差矩阵第二行第三列的元素表示“h1”与log(“h2”)的协方差。
当可调参数多于8个时,协方差矩阵的行以“wrap”形式书写;也就是说,在写了八个数字之后,PEST开始新的一行来写第九个数字。类似地,如果有超过16个可调参数,则第17个数字在新行开始。但是请注意,协方差矩阵的每一行都是从运行记录文件的新行开始的。
5.2.11相关系数矩阵
相关系数矩阵由校正后的协方差矩阵计算,使用Doherty(2015)的公式3.5.3。相关系数矩阵的行数和列数与协方差矩阵相同;此外,这些行和列与可调参数(或其日志)相关的方式与协方差矩阵的方式相同。与协方差矩阵一样,相关系数矩阵也是对称的。
相关系数矩阵的对角元素总是统一的;非对角线元素总是在1.0和-1.0之间。非对角线元素越接近1.0或-1.0,与该元素的行号和列号相对应的参数的相关性就越高。由此可见,对于图5.1运行记录文件中记录的相关系数矩阵,参数“ro2”和“h2”的日志表现出适度的相关性。然而,在这个协方差矩阵中出现的相关系数都没有高到足以表明相关参数的可估计性的非唯一性。
正如Doherty(2015)所指出的那样,虽然相关系数矩阵中包含的信息有可能告诉用户逆问题当前是否病态(或正在接近这种情况),以及过度的参数相关性是否导致了这种情况,但在实践中,为该矩阵的元素计算的值通常会受到它们试图暴露的病态的有害影响。在这方面,校正后协方差矩阵的特征值和特征向量是更可靠的信息来源。
5.2.12归一化特征向量矩阵和特征值
特征向量矩阵由尽可能多的可调参数组成,每列包含一个校正后协方差矩阵的归一化特征向量。
因为协方差矩阵是正定的,所以这些特征向量是实数且正交的;它们表示m个可调参数所占据的m维空间中校准后概率“椭球”的轴线方向。
在所述特征向量矩阵中,所述特征向量按其各自特征值的递增顺序从左至右排列;特征值列在特征向量矩阵下面。每个特征值的平方根是m维可调参数空间中后校正概率椭球对应的半轴长度。
如果特定特征值与后校正协方差矩阵的最低特征值之比特别大,则相应的特征向量在参数空间中定义了一个相对不敏感的方向。与最高特征值相关的特征向量在许多参数估计问题中特别值得注意,因为它定义了最大不敏感的方向,从而定义了可调参数空间中校准后概率椭球体的最大伸长。如果这个特征向量由单个元素主导,那么与该元素相关的参数可能是相当不敏感的,“其不敏感的大小”由相应特征值大小的平方根定义。然而,如果这个特征向量包含许多重要的组成部分,而不仅仅是一个,那么这是与一组参数(即参数相关性)相关的不敏感性的指示。相关参数是指特征向量成分明显不为零的参数。
校正后协方差矩阵的最高特征值与最低特征值之比尤为重要。该比值的平方根与PEST在求解参数升级向量时必须求反的矩阵的“条件数”有关,参见Doherty(2015)的方程5.2.11和5.2.13。如果一个矩阵的条件数过高,则该矩阵的反演在数值上变得困难(导致伪逆矩阵)甚至不可能。在参数估计环境中,这是当校正后参数概率椭球的延伸增加到无穷大时,反问题的解趋于非唯一性的结果。一般来说,如果校正后协方差矩阵的最高特征值与最低特征值之比大于107左右,则极有可能由于参数不敏感和/或相关性导致的矩阵病态,PEST在计算参数升级向量时遇到了严重困难。除非反问题的解采用奇异值分解或LSQR(希望包含Tikhonov正则化来引导反演过程向合理的参数值方向发展),否则PEST的性能可能会因此严重下降。这正是为什么建议采用这些解决方案过程的原因。
5.3其他PEST输出文件
5.3.1一般
由PEST编写的所有文件都列在附录b中。其中许多是二进制文件,对PEST用户来说意义不大,但在尝试中期重启和/或管理并行模型运行时,对PEST非常重要。其他文件由PEST专门为用户的利益而记录。其中一些包含允许您在运行PEST时监视其性能的信息。其他包含支持反转过程运行后求值的信息。现在讨论这些对用户有益的文件。
5.3.2参数值文件
在反转过程的每次迭代结束时,PEST将迄今为止获得的最佳参数集(如果PEST以“估计”模式运行,这是目标函数最低的集合)写入一个名为case的文件。par,其中case是PEST控制文件的文件名基础;这种类型的文件被称为PEST“参数值文件”。在一次PEST运行结束时,参数值文件包含最优参数集。图5.3演示了这样一个文件。请注意,TEMPCHEK实用程序可以使用参数值文件来基于模板文件构建模型输入文件,petgen可以使用参数值为PEST控制文件分配初始值,PARREP可以使用参数值文件从旧的PEST控制文件构建新的PEST控制文件。RANDPAR实用程序可以生成一组参数值文件,其内容构成参数概率密度函数的样本。请参阅本手册的第2部分,了解这些工具以及其他PEST实用程序生成和使用参数值文件的更多细节。
single point
ro1 1.000000 1.000000 0.0000000
ro2 40.00090 1.000000 0.0000000
ro3 1.000000 1.000000 0.0000000
h1 1.000003 1.000000 0.0000000
h2 9.999799 1.000000 0.0000000图5.3参数值文件。
参数值文件的第一行引用了字符变量PRECIS和DPOINT,它们的值在PEST控制文件的“控制数据”部分中提供。然后,每个参数都跟着一行。每行包含一个参数的名称、当前值以及在PEST控制文件中提供的该参数的SCALE和OFFSET变量的值。
如果将PEST控制文件的“控制数据”部分中的PARSAVEITN变量设置为“PARSAVEITN”,则在每次迭代过程结束时保存名为case.par.N的参数值文件。如果将PARSAVERUN变量设置为“PARSAVERUN”并使用BEOPEST,则将使用一系列名为case.par的参数值文件。记录N_M,其中N为运行包索引,M为运行号。详见本手册4.2.10章节。
5.3.3参数敏感性文件
在每次PEST迭代过程中,大部分时间都用于雅可比矩阵的计算。在此过程中,模型必须至少运行m次,其中m是可调参数的数量。正如Doherty(2015)第5.3.1节所解释的那样,PEST根据雅可比矩阵的内容计算出与所有观测值的每个参数的灵敏度相关的数字(后者根据用户分配的权重进行加权)。参数i的“复合灵敏度”定义为

其中J是雅可比矩阵,Q是权矩阵。式5.3.1中的N为非零权值的观测值个数。
从另一个角度来看,第i个参数的复合灵敏度是与该参数相关的雅可比矩阵列的归一化(相对于观测值的数量)幅度,该列的每个元素乘以与各自观测值相关的权重。回想一下,雅可比矩阵的每一列都列出了所有模型生成的观测值对特定参数的导数。
在计算完雅可比矩阵之后,PEST立即将复合参数灵敏度写入名为case的“参数灵敏度文件”。sen,其中case是当前的case名称(即当前PEST控制文件的文件名基础)。图5.4显示了参数敏感性文件的摘录。

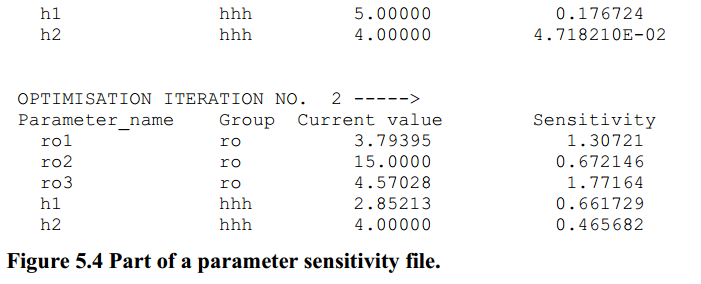
在参数灵敏度文件中记录的复合灵敏度是“PEST所看到的”灵敏度。因此,如果一个参数是对数变换的,则灵敏度是根据该参数的对数来表示的。
如果在反问题中没有任何形式的正则化特征(例如,如果不使用Tikhonov正则化,和/或如果既不使用奇异值分解也不使用LSQR作为解决方法),那么复合参数敏感性可以用于识别那些可能由于对模型结果缺乏敏感性而降低参数估计过程性能的参数。
在每次迭代反演过程中,在计算雅可比矩阵之后立即将信息附加到参数灵敏度文件中。在重启的情况下,参数敏感性文件不会被覆盖;相反,PEST保留文件的内容,将有关后续迭代的信息附加到现有文件的末尾。
通过这种方式,用户能够通过参数估计过程跟踪每个参数的复合灵敏度的变化。
检查参数灵敏度文件时,应注意以下几点。
•如果PEST工作在“预测分析”模式下,它假设分配给构成“预测”观察组唯一成员的观测值的权重为零。因此,该观察组的唯一成员对任何参数的复合灵敏度都没有贡献。然而,对于在模拟结束时写入参数灵敏度文件的信息,情况略有不同,见下文。
•如果PEST以“正则化”模式工作,分配给观察组“regul”成员的权重随迭代而变化(见第9章)。任何迭代的复合参数敏感性都是使用名称以“regul”开头的观察组成员的最优权重因子(由PEST在迭代的基础上计算)来计算的。
•如果提供观测值协方差矩阵而不是任何观测组的观测值权重,则在计算复合参数灵敏度时将自动考虑到这一点。
在PEST执行终止时记录的灵敏度信息
在反演过程结束时(或者如果使用“带统计信息的停止”选项过早地停止PEST—参见下文),PEST根据在PEST运行期间计算的最佳雅可比矩阵提供了复合参数灵敏度的完整列表。“最佳”是根据PEST的任务来定义的;这可能是最小化目标函数(“估计”模式),最大化/最小化受目标函数约束的预测(“预测分析”模式),或者最小化目标函数的正则化成分,受制于目标函数的测量成分(“正则化”模式)的约束。当PEST在“帕累托”模式下运行时,“最佳”没有意义。
参数估计过程中计算“最佳”雅可比矩阵的点每次运行都不相同。它可能是在最后一次迭代期间计算的,或者可能是在一些迭代之前计算的,由于迭代没有成功,后续尝试改进反转过程的结果。还要注意的是,如果在最后的迭代过程中,反演过程的结果有一个边际的改进,但不足以保证进行另一次迭代,那么灵敏度将不完全对应于估计的参数值,因为在这些条件下,PEST在停止执行之前不会计算另一个雅可比矩阵。然而,PEST在最后一次迭代开始时使用的接近最佳参数值的基础上计算的灵敏度应该与它将使用最终参数估计计算的灵敏度非常接近。但是,如果您希望获得使用最终参数值计算的雅可比矩阵,则可以执行以下操作。
1. 使用PARREP实用程序(请参阅本手册的第二部分)构建一个新的PEST控制文件,其中初始参数值是优化的参数值。
2. 将该文件中的NOPTMAX设置为-1,从而请求PEST计算雅可比矩阵,然后根据该矩阵计算统计信息,然后停止执行。
3. 在这个只考虑灵敏度的运行中,您可能希望将每个参数组的FORCEN变量设置为“always_3”(甚至是“always_5”),从而确保PEST以最大的精度计算导数。
4. 如果在“正则化”模式下工作,则将初始权重因子(WFINIT)设置为之前反演运行期间确定的最佳权重因子(除非在之前的PEST运行中将正则化控制变量IREGADJ设置为非零值,在这种情况下,正则化组间权重的相关性将受到干扰,这种方法将不适用)。然而,一个更好的主意是使用SUBREG1实用程序在进行仅灵敏度运行之前消除PEST控制文件中的正则化。这使您可以单独得出关于校准数据集的信息内容及其支持反演过程的唯一解决方案的能力(或缺乏能力)的结论。
5. 然后运行PEST。
在参数灵敏度文件的末尾写入“完成参数灵敏度”时,PEST列出了所有观察组对每个参数的复合灵敏度,以及每个单独观察组的复合灵敏度。利用公式5.3.1计算加权雅可比矩阵各自列的大小来评估每个观察组的复合参数敏感性,其总和仅限于该特定观察组的成员。然后将量级除以该观察组中权重非为零的成员的数量。
当PEST以“预测分析”模式运行时,观察组“预测”值得特别注意。如上所述,在此模式下运行PEST时,它不包含在总体参数灵敏度的计算中。但由于是一个独立的观测组,PEST在参数灵敏度文件的末尾列出了该组单个成员对各参数的综合灵敏度,以及其他观测组的综合灵敏度。在此计算中使用的观察权重是分配给在PEST控制文件中包含观察组“预测”的唯一成员的观察的权重。
当在“正则化”模式下使用PEST时,在记录参数对这些组的综合灵敏度之前,将名称以“正则”开头的观察组的权重乘以作为反演过程一部分确定的最优正则化权重因子;如果IREGADJ设置为非零值,则组间相对权重也会得到优化。
5.3.4观测灵敏度文件
定义观测值oj的复合观测灵敏度为

也就是说,观测值j的复合灵敏度是雅可比矩阵第j行的大小乘以与该观测值相关的权值;然后将该量级除以可调参数的数量。因此,它是该观测值对参数估计过程中涉及的所有参数的灵敏度的度量;详见Doherty(2015)第5.3.3节。在运行结束时,PEST将所有观测值和相应的模型计算值以及所有观测值的复合灵敏度列在“观测灵敏度文件”中。该文件名为case.seo。
虽然复合观测灵敏度可以有一些用途,但它们通常不能像复合参数灵敏度那样传达有用的信息。事实上,在某些情况下,他们提供的信息甚至可能有点欺骗性。因此,虽然复合观测灵敏度值高,乍一看,表明观测值对反演过程至关重要,因为它的信息含量高,但事实未必如此。与第一次观测几乎在同一时间和/或地点进行的另一次观测可能携带几乎相同的信息。在这种情况下,有可能从反演过程中省略其中一个观测值而不受惩罚,因为它所携带的信息是多余的,只要其他观测值包含在该过程中。因此,虽然高的复合观测灵敏度值确实意味着它所属的观测值可能对许多参数敏感,但这并不表明该观测值对反演过程特别不可或缺,因为这只能在存在或不存在具有类似灵敏度的其他观测值的情况下决定。
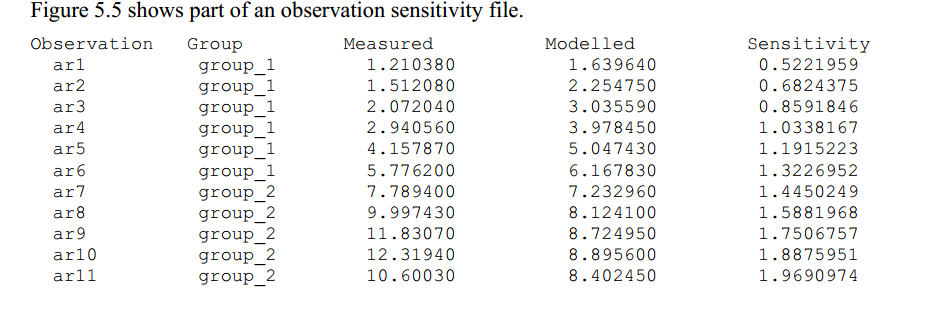
图5.5观测灵敏度文件的一部分。
5.3.5残差文件
在执行完成后,PEST编写一个“残差文件”,将观测值的名称、观测值所属的组、测量值和模拟值、两者之间的差异(即残差)、测量值和模拟值乘以各自的权重、加权残差、测量标准差和“自然权重”。该文件可以很容易地导入到电子表格中,用于各种类型的分析和绘图。它的名字叫case。res,其中case是当前PEST用例的名称。
需要对残差文件中提出的最后两种数据类型进行解释。在完成反演过程后,PEST计算出一个“参考方差”(也称为“加权残差标准差”),σ 2r为

式中Φ0为估计参数对应的目标函数,n为观测值个数,m为可调参数个数。当PEST以“估计”模式运行时,Φ0是最小的反对函数。当PEST以“预测分析”模式运行时,这是在PEST以这种模式运行时所进行的最大化或最小化过程中起作用的目标函数约束。当PEST以“正则化”模式运行时,Φ0包括正则化观察和先验信息。当在后两种模式下运行时,参考方差没有在“估计”模式下运行时那么有意义。进一步讨论请参见Doherty(2015)第5.2.2节。
在观测残差文件中表示的“自然权重”是用户提供的权重除以参考方差的平方根。然而,对于实际上是正则化组的观察组,用户提供的权重首先根据PEST的Tikhonov正则化实现进行调整。
如果为一个或多个观察组提供协方差矩阵而不是权重,则对残差文件进行轻微修改。在PEST运行记录文件中,权重没有记录在剩余文件中。相反,在权重应该写的地方,字符串“Cov”。
Mat.”被记录下来。在本应记录加权测量值、加权观测值、加权残差、测量标准偏差和自然权重的地方,“na”表示“不适用”。
当一个协方差矩阵分配给一个或多个观察组时,PEST写入“旋转残差文件”以及普通残差文件;该文件名为case.rsr。对于未分配协方差矩阵的观察组,此文件中的条目与残差文件中的条目相同。然而,对于那些分配了协方差矩阵的“旋转残差”和“旋转权重”(及其函数)表示代替实际残差和权重。
设C(ε)为用户提供的观测协方差矩阵。分配协方差矩阵的观察组的目标函数分量使用公式3.7.2计算,现在重复为公式5.3.4。
![]()
通过奇异值分解,可以得到C(ε)为
![]()
式中,E为标准正交矩阵,F为奇异值递减排列的对角矩阵;参见Doherty(2015)。式5.3.4可写成
![]()
其中“旋转残差”s的矢量计算为
![]()
这个等价于

第i个wi是F -1的第i个对角线元素的平方根。Si和wi是在旋转残差文件中表示的旋转残差和权值。旋转观测值及其模型生成的对应值以相同的方式计算,即通过乘以E矩阵。
由于为该组的成员计算了一组新的“旋转观测值”,因此用户为原始观测值分配的名称不再适用。因此,当PEST在该文件中列出新观测的名称时,它通过在原始观测的名称中添加字符串“_r”来制定新的观测名称。然而,重要的是要注意,一个旋转的观测值,其名称是通过在原始观测值的名称中添加字符串“_r”来形成的,与原始观测值的直接关系并不比与原始观测组的任何其他成员的直接关系更多;这种观测的命名约定只是为了方便。
5.3.6临时残留文件
在每次迭代的开始,PEST都会写入一个名为case的文件。rei其中case是PEST控制文件的文件名基础。该文件是“临时”或“临时”剩余文件。
它包含六列数据。前两列引用观察名称和组名称;然后跟踪观察值(由用户提供)及其当前模型生成的对应值。当前的残差和权重将在随后的列中介绍。
应注意以下几点。
1. 残差文件中记录的模型生成的观测值属于在参数估计过程阶段计算的最佳参数,在此阶段编写临时残差文件。
2. 如果观测值属于提供协方差矩阵的组,则不能为其分配权重。因此,按照惯例通过了对残余物的立案。在参数估计过程结束时,记录字符串“Cov”。Mat”是用来代替重量的。
3. 正如本手册第9章所解释的,正则化组成员的权重在整个反演过程中都会发生变化。因此这些权重在不同情况下是不同的。在正则反演过程的不同阶段记录的Rei文件。
5.3.7矩阵文件
在每次迭代中,在计算完雅可比矩阵后,PEST计算出当前参数值集的“校正后”协方差矩阵和相关系数矩阵,以及协方差矩阵的特征值和归一化特征向量。
但是,这只有在满足以下条件时才会发生。
•害虫控制文件“控制数据”部分的ICOV、ICOR和IEIG设置为1;•没有使用形式或正则化(因为使用正则化使这些矩阵毫无意义);因此,既不使用奇异值分解也不使用LSQR求解逆问题,也不使用Tikhonov正则化;•矩阵jtqj是可逆的,其中J是雅可比矩阵,Q是权矩阵。
这些矩阵被写入一个名为“矩阵文件”的特殊文件中。这个文件命名为case。mtt,其中case是当前的case名称(即PEST控制文件的文件名基础)。每次写入此文件时,前一个同名文件都会被覆盖。因此,矩阵文件中包含的矩阵属于最近的迭代。
如果ICOV、ICOR或IEIG中的任何一个设置为零,则矩阵文件中不记录相应的矩阵。如果它们都被设置为零,那么没有矩阵被写入这个文件。如果ICOV设置为1,则PEST记录协方差矩阵到矩阵文件中,同时记录当前参数值和标准差。(参数的标准差是其方差的平方根;参数方差由协方差矩阵的对角元素组成。与协方差和相关矩阵的元素一样,如果参数在参数估计过程中进行对数变换,则参数的标准差实际上属于该参数的对数。
细心的PEST用户可能会注意到在最终矩阵文件中记录的矩阵与在PEST运行结束时在运行记录文件中记录的矩阵之间的细微差异。如果在参数估计过程中获得的最低目标函数是由PEST在其最后迭代中计算的,那么您可能会期望这两组矩阵非常相似。然而,它们之间往往存在差异。产生这些差异的原因是,对于记录在矩阵文件中的矩阵,计算所用的参考方差(见式5.3.3)是使用上一次迭代结束时计算的目标函数来计算的,而对于记录在运行记录文件中的协方差及相关矩阵,计算所用的参考方差是使用整个参数估计过程中计算出的最佳目标函数。如果在最后一次参数升级时计算出最佳目标函数,那么这将与上次迭代开始时计算的结果略有不同。
5.3.8条件号文件
除非PEST使用奇异值分解或LSQR来解反问题,否则它会将计算参数升级(即J tQJ + λI)必须反转的矩阵的条件数写入“条件数文件”。记录在每次PEST迭代期间测试的每个Marquardt lambda的条件号。
条件编号文件命名为case. nd,其中case是PEST控制文件的文件名基础。如果条件数很高(通常大于大约104),这表明PEST可能无法正确地反转矩阵,这是由于参数过度不敏感或相关性引起的接近或完全奇异的结果。至少,这是估计参数的非唯一性的指示;至多意味着PEST可能没有成功地降低目标函数。无论哪种情况,你都应该重新表述反问题。要么保持一些固定的参数,或者更好的是,对参数估计问题引入某种形式的正则化(例如奇异值分解和/或Tikhonov)。
5.3.9奇异值分解文件
如果PEST控制文件的“奇异值分解”部分中的EIGWRITE变量设置为1,那么PEST将写入一个名为case的文件。svd(其中case是PEST控制文件的文件名基础)。它在每次计算参数升级向量时扩展该文件。在每次这样的情况下,它记录奇异值(按降序排列)和对应的奇异向量(J tQJ +整机I)。同时记录实际用于参数升级向量计算的奇异值个数(即截断小奇异值和零奇异值后剩余的奇异值个数)。每次测试Marquardt lambda时进行奇异值分解,并计算相应的参数升级向量。
在参数数量较多的情况下,奇异值分解输出文件可能变得非常大。此外,除非将RLAMBDA1设置为零(不建议这样做),否则此文件中包含的信息依赖于Marquardt lambda的当前值。
本手册第2部分中描述的许多实用程序提供了与从该文件中获得的相同(或更好)的信息。因此,在大多数使用PEST的情况下,不值得记录。
5.3.10 LSQR输出文件
如果将PEST控制文件的“lsqr”部分中的LSQRWRITE变量设置为1,则将lsqr求解器生成的信息写入名为case的文件。其中case是PEST控制文件的文件名基础。每次被PEST调用时,LSQR求解器都会生成新的信息;因此,这个文件可能会变得相当长。
5.3.11运行管理记录文件
如果模型运行是使用parallel PEST或BEOPEST并行进行的,那么PEST会记录一个名为case.rmf的运行管理记录文件。这包含了PEST管理器和每个代理之间通信的历史记录,这些代理参数化单独的模型运行,并为这些运行发出系统命令。
5.3.12 Pareto输出文件
命名为case.par的文件。N,案例。豆荚和箱子。如果在“pareto”模式下运行PEST,则记录ppd。
其中前两个是ASCII文件,而第三个是二进制文件。文件case.par. n包含迭代n结束时计算的参数值。ppd在PEST运行时不断更新,包含在Pareto运行期间计算的目标函数。文件的情况。ppd是一个二进制文件,可以由特定于pareto的PEST后处理器访问。
5.3.13雅可比矩阵文件
在由PEST实现的反转过程的任何阶段,对应于该过程阶段所获得的最佳参数的雅可比矩阵可以在名为case.jco的二进制文件中找到。在第3.6节中讨论了该文件内容的许多用途中的一些。在本手册的第一部分和第二部分中,这个文件通常被简单地称为“JCO文件”。
5.3.14分辨率数据文件
除非PEST控制文件“控制数据”部分中的IRES变量设置为0,否则如果PEST采用任何形式或正则化(奇异值分解,LSQR和/或Tikhonov),它将写入名为case的“分辨率数据文件”。rsd,其中case是PEST控制文件的文件名基础。(注意,如果在PEST控制文件中省略了可选的IRES变量,则假定其值为“1”)。
解析数据文件为二进制文件,用户无法读取其内容。相反,它由RESPROC和本手册第二部分中描述的相关实用程序程序使用。
PEST在反演过程中多次更新分辨率数据文件,使其中的数据始终属于该过程阶段获得的最佳参数;因此,只要估计的参数得到改进,它就会被覆盖。
5.3.15其他文件
如果将PEST控制文件的“控制数据”部分中的RSTFLE变量设置为1,则PEST将写入一系列二进制数据文件,其中包含在反转过程过早终止时重新开始执行所需的信息。这些文件的列表见附录B。
如果模型运行是并行进行的,PEST使用名为PEST ###的二进制直接访问文件。Dap和pest###。用于在参数和观察运行队列中存储条目的Dao。
5.3.16 PEST的屏幕输出
除了将参数估计过程的进度记录到运行记录文件中外,PEST还将一些运行时信息打印到屏幕上;通过这种方式,用户可以随时了解该进程的状态。
除非您使用并行PEST或BEOPEST(其中管理器和代理在单独的命令行窗口中运行),否则PEST控制的模型可能会将自己的输出写入屏幕。如果是这种情况,它将干扰PEST向屏幕显示运行记录信息。也许这不会让您担心,因为它允许您检查模型在PEST的控制下是否正确运行;在任何情况下,您都可以在PEST运行时通过在文本编辑器中打开它来检查运行记录文件。但是,如果您发现模型和PEST都使用同一屏幕很烦人,您可以使用模型命令行中的“>”符号将模型屏幕输出重定向到一个文件;这将使屏幕只显示PEST的运行时信息。因此,例如,如果一个名为modelrun.exe的程序由PEST作为模型命令行运行,或者在PEST通过模型命令行运行的批处理文件中引用,则可以使用命令modelrun > temp.dat将其屏幕输出定向到名为temp.dat的文件,或者可以使用命令modelrun > nul来运行modelrun.exe。在后一种情况下,屏幕输出只是“丢失”,因为没有空文件。在UNIX环境中,上面的第二个命令应该替换为modelrun > /dev/null
5.3.17运行时错误
如上所述,PEST对其输入数据集执行有限的检查。如果在其输入数据中出现错误或不一致,PEST将以运行时错误消息终止执行。与PESTCHEK(参见本手册第二部分)不同,PEST不会继续读取其输入数据文件,以确定是否存在更多错误,以便它也可以列出它们;相反,一旦它注意到有什么不对劲,它就会停止执行。
其他错误可能在稍后的反演过程中出现。例如,如果指令集未能定位特定的观察值,PEST将立即停止执行,并显示相应的运行时错误消息。如果模型以一种您在编写指令集时没有预料到的方式改变了输出文件的结构以响应某一组参数值,则可能发生这种情况。如果模型由于某些内部模型数值故障而过早终止执行,也可能出现这种情况。因此,如果运行时错误消息通知您PEST不能正确地读取模型输出文件,您应该检查屏幕和模型输出文件,以查找模型生成的错误消息。如果屏幕上有一条编译器生成的错误消息,告诉您有浮点数或其他错误,然后是一条PEST运行时错误消息,告诉您找不到观测值,那么是模型而不是PEST对该错误负责。然后,您应该仔细检查模型输出文件,寻找有关错误发生原因的线索。在某些情况下,您会发现一个或多个模型参数超出了它们允许的范围,在这种情况下,您将不得不在PEST控制文件中相应地调整它们的上限和/或下限。
如果包含模型可执行文件的目录(即文件夹)没有在PATH环境变量或PEST控制文件的“模型命令行”部分中引用,则会发生另一个与模型相关的错误,可能导致这种类型的PEST运行时错误。在这种情况下,在PEST尝试运行第一个模型之后,您将收到消息Running model .....在PEST运行时错误消息通知您不能打开模型输出文件之前,错误的命令或文件名。(注意,然而,如果模型可执行文件驻留在当前目录中,则不需要模型路径。)区分PEST错误和模型错误通常很容易,因为当PEST运行模型时,它会通过屏幕输出通知您。模型生成的错误(如果发生)将始终跟随这样的消息。此外,PEST运行时错误消息被清楚地标记为这样,如图5.6所示。如果您正在使用并行PEST或BEOPEST,则模型窗口将不同于PEST窗口。在这种情况下,区分源自模型的错误和源自PEST的错误会容易得多。

PEST运行时错误被写入屏幕和PEST运行记录文件。
5.4停止和重启PEST
5.4.1中断PEST执行
在每个模型结束时,运行PEST检查是否存在一个名为PEST的文件。被调用的目录(即文件夹)中的STP。如果这个文件存在,PEST读取文件中的第一项。如果该项为“1”,则PEST立即停止执行。如果为“2”,则在输出参数统计信息后,PEST停止执行。如果为“3”,PEST暂停执行。要在暂停后恢复PEST执行,请重写文件PEST。以“0”作为第一项的STP。
文件的害虫。用户可以使用任何文本编辑器在运行PEST的另一个窗口中编写stp。然而,这个文件也可以使用PEST提供的程序PPAUSE, PUNPAUSE, PSTOP和PSTOPST来编写,只需在另一个命令行窗口的PEST工作文件夹中输入相应程序的名称作为命令。顾名思义,PPAUSE给pest写一个“3”。stp命令告诉PEST暂停执行;PUNPAUSE给pest写一个“0”。告诉STP恢复执行;PSTOP写一个“1”来告诉PEST停止执行,而PSTOPSTP指示PEST停止执行,并通过在文件PEST .stp中写一个“2”来打印出完整的参数统计信息。注意,如果非并行版本的PEST正在运行,那么PEST将不会响应文件PEST的存在。STP,直到当前模型运行完成。相比之下,并行PEST和BEOPEST立即响应;然而,在PEST执行停止后,模型的各种事件将继续在它们自己的窗口中运行直至完成。
当然,还有另一种方法可以阻止PEST。只需在运行PEST的命令行窗口中按一下。如果正在运行非并行版本的PEST,则可能需要连续按几次这些键,以便终止模型和PEST的执行。
5.4.2重启PEST
参见5.1.5节中关于重启开关的讨论。
5.4.3为什么要停止PEST?
在满足PEST控制文件中“控制数据”部分规定的终止标准或其他特定于其在“预测分析”、“正则化”或“帕累托”模式中的使用的终止标准之前,PEST很少需要继续执行。在运行PEST的大多数情况下,您将知道反转过程何时“失去动力”。当参数数很高时,继续该过程的成本也很高,因为重新填充雅可比矩阵需要许多模型运行(特别是如果PEST已经切换到使用三点或五点有限差分导数)。
用户终止执行PEST的原因可能包括以下几点。
•从迄今为止获得的目标函数可以明显看出,模型结果与相应的现场测量结果之间将无法实现良好的拟合。因此,在重新开始参数估计过程之前,模型可能需要修改。
•估计参数的值可能是不现实的。这可能被解释为过度拟合正在发生的迹象。您可以决定应该再次运行PEST,并采取适当的措施来防止这种情况发生。如果在“正则化”模式下运行,可能需要更高的PHIMLIM控制变量值。
•目标函数从迭代到迭代的行为可能是不稳定的。这可能表明有限差分导数被较差的模型数值性能所破坏。您可能希望在使用适当的防御措施开始另一个PEST运行之前,使用JACTEST实用程序测试这个假设。
5.5如果PEST不起作用
5.5.1一般
如果要求PEST解决的逆问题是病态的,那么早期版本的PEST经常会遇到困难。病态性使得jtqj矩阵奇异,因此不可逆。有时使用高马夸特lambda值表示(J tQJ+λI)可逆,并允许基于pest的反演继续进行。然而,这并没有改变反问题本质上的非唯一性。马夸特lambda也没有提供一个数值上有效的正则化装置。因此,这取决于用户认识到反问题的非唯一性,然后识别那些不敏感或高度相关的参数,使其从参数估计过程中移除。然后将这些固定或绑在一起,重复进行PEST测试。或者,可以调用PEST提供的手动或自动用户干预功能(见第6章)来协助PEST处理问题不适。然而,这些策略不能保证通过历史匹配过程获得的参数集具有最小的误差方差。
现在情况不同了。如果认识到自然系统固有的复杂性(如果要量化参数和预测的不确定性,就必须接受它),那么大多数逆问题都是病态的。然而,通过使用以下设置运行PEST,通常可以获得这些问题的最小误差方差解决方案,并保证数值稳定性。
•将RLAMFAC设置为-3;•使用奇异值分解或LSQR来解决逆问题;•采用吉洪诺夫正则化。ADDREG1实用程序通常是将Tikhonov正则化引入PEST输入数据集的最简单方法。
如果PEST不能与这些措施一起工作,那么必须确定并纠正其失败的原因。下面将讨论导致PEST运行失败的几个可能原因及其解决方案。
5.5.2找不到模型输出文件
在运行模型之前,PEST删除PEST控制文件的“模型输入/输出”部分中列出的模型输出文件。这些是相应指令文件必须读取的模型输出文件。如果由于某种原因,模型运行失败,这些模型输出文件将不存在。然后PEST将发出如图5.6所示的错误消息。此错误消息几乎总是表示模型没有运行,或者没有运行到完成。
5.5.3目标函数梯度零
如果所有模型输出对所有参数的灵敏度都为零,则PEST发出以下错误消息。
Phi gradient zero in non-frozen parameter space.如果只有一个模型输入文件有对应的模板文件,并且为这个模型输入文件提供的名称不正确,就会出现这种情况。然后,PEST将参数值写入一个文件,而模型读取另一个文件。(PESTCHEK程序可以检测到许多错误,但它不能检测到这个错误。)当然,这个问题很容易纠正。
它只需要将错误的模型输入文件的名称替换为正确的模型输入文件的名称。
如果在PEST控制文件的“模型输入/输出”部分中引用了多个模型输入文件,并且如果其中只有一个命名不正确,那么输入文件命名错误的问题就更难以检测。它可以通过只写入该模型输入文件的参数的零值复合灵敏度来揭示(尽管如果采用正则化,这将被隐藏,因为正则化的真正目的是在不存在的地方创建灵敏度)。也可能通过倒置过程没有调整仅在该模型输入文件中表示的参数来揭示。
5.5.4不良导数导致的目标函数行为不稳定
如果PEST工作良好,目标函数首先下降得很快,然后下降得更慢,然后不再下降。从快速向下运动到完全不运动的过渡通常是逐步进行的。
然而,有时,目标函数在一次迭代中迅速下降,然后在下一个迭代中根本不下降。有时它迅速上升,然后又迅速下降。
这通常是有问题的有限差分导数的标志。
有问题的有限差分导数可能有以下任何一种原因。
•参数值没有以足够的精度写入模型输入文件;•在批处理或脚本文件中引用的不同可执行文件之间以低于完全精度的数字传递,其中PEST作为“模型”运行;•参数增量太低;•该模型在数值上遇到困难;•模型求解器收敛标准设置不够严密。
可以使用本手册第2部分中描述的JACTEST实用程序检查有限差分导数的完整性。可以采取以下步骤来减轻模型损坏衍生品的有害影响。
•衍生增量可以增加;•DERINLB衍生控制变量可用于由低参数值引起的低参数增量;•模型求解器收敛准则可以收紧;•如果这样做是可行的,可以禁用模型数值策略,如自适应时间步进,因为它可能会给模型输出引入少量的“数值噪声”;•PEST的“拆分斜率分析”功能可以被调用来检测和防御模型数值输出粒度(见3.5.7节);•可以使用五点有限差分模板(见3.5.2节);•可以激活PEST的“自动用户干预”功能,将DOAUI控制变量设置为“auid”(参见6.4节)。
5.5.5导致目标函数行为不稳定的其他因素
如果降低目标函数的失败,或目标函数的不稳定行为,是由于极端的问题非线性而不是退化的有限差分导数,这可以通过限制任何参数在任何一次迭代中允许改变的数量来解决。可以使用PEST控制文件“控制数据”部分中引用的FACPARMAX、RELPARMAX和ABSOLUTE(N)变量来施加参数更改限制。
参数的对数变换通常会对PEST性能产生深远的影响。正如本手册其他部分所讨论的,如果模型输出和模型参数是对数转换的,那么模型输出和模型参数之间的关系通常是线性的。所有参数的对数变换通常与通过其固有变量对参数进行归一化的结果相似。这防止了那些数值用数值小的数字表示的参数的超敏感性(如地下水模型中补给的情况)。如果由于参数可能变为零或负值而无法进行日志转换,则可以使用PEST控制文件“参数数据”部分中可用的SCALE控制变量来降低单个超敏感参数的灵敏度。位于PEST控制文件“控制数据”部分中的BOUNDSCALE变量引入了参数相对于其固有变量的全局归一化。
5.5.6模型运行次数过多
在高度参数化的上下文中,参数可以有数百个、数千个甚至数万个。在这种情况下,有限差分导数计算所需的模型运行次数很快就会变得过多。虽然并行化和svd辅助的使用可以大大减少模型运行的负担,但是在许多情况下,一些简单的步骤也可以非常有效地减少这种负担。
当参数到达其边界时,参数升级向量的长度被缩短以适应这一点。这可以大大减缓反演过程的进展。如果目标函数不落在参数升级向量缩短的迭代上,PEST可能会根据驻留在PEST控制文件的“控制数据”部分中的PHIREDSWH变量的设置过早地开始使用高阶导数计算。因此,PEST在下一次迭代期间进行的模型运行的数量增加了一倍(如果使用五点衍生模板,则增加了四倍)。
通过适当设置NOPTSWITCH变量,可以防止过早开始高阶有限差分导数计算。
还应考虑扩大参数范围。从概念上讲,Tikhonov正则化是一种比使用边界更好的保持参数敏感性的方法。
通过使用适当的目标测量目标函数,可以很容易地防止可能要求参数采用异常值的过拟合。参见第9章。
5.5.7不连续问题
使用Doherty(2015)中推导的方程(基于梯度的反演)是基于模型输出是参数的连续可微函数的假设。如果一个模型的算法基础违反了这个假设,那么PEST在估计该模型的参数时将有极大的困难。
(然而,如果依赖关系是连续的,如果不是连续可微的,它可能仍然有一些成功。)如果模型输出相对于参数的不连续程度不是太高,那么上面讨论的一些可以用来适应较差的数值导数的策略可能会成功地适应由模型算法缺陷引起的不连续。然而,如果模型参数和模型输出之间的关系过于退化,那么就别无选择,只能使用所谓的“全局方法”来估计模型参数。兼容pest的CMAES_P和SCEUA_P全局优化器(特别是后者)在这方面可能很有用。请参阅本手册第16章。
5.5.8参数相关性和不敏感性
如上所述,在没有采用数值正则化形式的情况下(这是不推荐的做法),在参数相关性和/或不灵敏度使得J tQJ矩阵不可逆转的情况下,反演过程可能会失败。“经典”建议是识别导致该矩阵不可逆转性的参数,然后将它们从参数估计过程中移除。复合灵敏度可以帮助识别不敏感的参数;一个好的经验法则是,如果反演过程中涉及的参数的最高和最低复合灵敏度之比大于约100,那么应该从该过程中删除最不敏感的参数。
不幸的是,复合灵敏度不允许识别相关参数。理论上,这些可以通过分析校准后的协方差矩阵,以及从该矩阵中计算出的量,如参数相关矩阵和校准后协方差矩阵的特征值/特征向量来识别。但是,如果参数相关性太高,以至于定义了一个零空间,则无法获得校准后的协方差矩阵(因为J tQJ是奇异的)。
幸运的是,当使用上面5.5.1节提供的设置进行反转过程时,这些考虑是无关紧要的。当对非唯一逆问题进行适当的正则化,并使用奇异值分解或LSQR作为求解机制时,求解非唯一逆问题很容易实现。这样得到的反问题的解是不正确的,因为这是不可能的;然而,它是最小的误差方差。
5.6 PEST后处理
5.6.1 General
在完成反转过程后,必须仔细检查该过程的结果。本节的目的是提供一些关于如何最好地实现这一目标的想法,并建议通过本手册第二部分中描述的PEST实用软件提供一些处理选项。
5.6.2校准为假设检验
由于Doherty(2015)讨论的原因,反演过程的结果很少导致对“正确”参数值的估计。相反,它导致反问题的解接近于最小误差方差的解。因此,从该过程中获得的参数为后校准参数和预测不确定度分析提供了最佳起点。
在实际建模实践中,为了寻求模型校准逆问题的最小误差方差解,通常会多次运行PEST。早期的PEST运行通常构成一种假设测试形式,在提供合理参数的情况下,测试模型复制真实世界行为的能力。如果不能做到这一点,那么该模型构成系统行为的合理模拟器的假设就可以被拒绝。因此,必须对模型的边界条件或模拟器本身进行修改。与人工历史匹配相比,基于机器的历史匹配的一个优点是,建模者可以确保模型输出和现场测量之间的拟合与给定当前使用的建模概念之间的拟合一样好。如果这种拟合是不可接受的,或者如果支持这种拟合的参数是不可接受的,那么就需要对模型进行修订。
什么是“合适人选”的问题很重要。模型结果和实地测量结果之间的拟合很少与测量噪声的预期相符。在几乎所有的环境建模案例中,由模型缺陷产生的所谓“结构噪声”主导着模型与测量的不匹配。这种噪音的程度很难或不可能事先判断。此外,这种“噪声”不是随机的,没有协方差矩阵;参见Doherty(2015)的第9章,对这个问题进行了全面的讨论。因此,有些人建议对残差统计量进行定量分析的程序很少在环境模型的校准中占有一席之地。然而,这并不能消除对模型与测量不匹配的详细主观分析的需要。因此,模型输出和实地测量应以你所能得到的任何方式进行定性比较-通常以尽可能提示可能需要对模型进行更改的方式进行比较。这些包括但不限于:•模型输出图和相应的随时间的现场测量;•空间残差图。
有时有用的策略是将模型输出内插到相应的现场测量点,然后将其轮廓化,就好像它们是现场数据。将这个图叠加在实际现场数据的等高线地图上(使用相同的等高线算法绘制等高线),可能会表明导致这些等高线差异的模型缺陷的位置和性质。
最终,模型用户必须接受他/她的模型并不是真实世界行为的完美模拟器。由于Doherty(2015)中概述的原因,必须容忍模型输出与现场测量之间的非最佳拟合。如果在“正则化”模式下运行PEST,建模者可以使用PHIMLIM正则化控制变量选择他/她自己的拟合水平;这个变量设置了目标测量目标函数,PEST是不允许冒险的。有时,为了确定PEST实际能够达到的拟合水平,一开始将这个值设置得较低是有益的。这种策略的不可避免的结果将是对参数值的估计不具有吸引力,这构成了“过度拟合”发生的证据。然后可以进行第二次PEST测试,将PHIMLIM设置为比上一次PEST测试中获得的最佳测量目标函数高5%至10%;通常最后5%到10%的拟合会导致大多数不需要的参数移动。结果通常是一个更好的参数集,模型与测量的拟合几乎没有退化。同时,建模者已经证明,他/她可以获得他/她想要的更好的拟合,但他/她已经有意识地决定为了更好地要求估计参数域的最小误差方差状态而避开更好的拟合。
通过反转过程推断出的参数值的可接受性或不可接受性始终是一个主观判断问题。White等人(2014)表明,如果一个模型所需的预测在类型和位置上与它所校准的数据相似,那么估计参数在颁布有缺陷模型的输出与相应的系统状态测量之间的良好拟合时可能被迫发挥替代作用,如果有的话,可能只会在很小程度上降低模型的预测性能。然而,当模型必须做出部分依赖于零空间的预测时,则应保留估计参数值的合理性。
这可能需要创造性地制定一个目标函数,并接受模型输出和现场测量之间不太完美的拟合。
5.6.3传统统计
如果反问题是在没有数学正则化装置的帮助下进行的,那么正则化必须手动进行。正如已经讨论过的,这需要从反演过程中识别和去除顽固性参数。检查校准后的协方差矩阵,特别是其特征值,可以在这方面有所帮助。如果该矩阵的最高特征值与最低特征值之比大于107,则问题的病态性太大,无法用数值方法求解。在最高特征值对应的特征向量中特征最强的参数必须考虑从反演过程中去除。如果单个参数占主导地位,则该参数不敏感。
如果多个参数在这个特征向量中有严重的非零值,那么它们可能是相关的。至少其中一个应该被修复。
如果由于J tQJ矩阵的不可逆性而无法计算出校准后的协方差矩阵,则应检查复合参数的灵敏度,并从反演过程中去除不敏感的参数。
本手册第2部分中记录的EIGPROC实用程序可以帮助您找到由于其不敏感性和/或相关性而可能导致非正则化反演过程出现大多数问题的参数。
5.6.4适合正则化反演的统计量
SSSTAT实用程序提供了一套与灵敏度相关的信息,可以告知用户反演过程的“状态”,就参数可估计性和观测的信息内容而言。GENLINPRED实用程序提供了类似的信息,如果先前的参数不确定性和预测灵敏度可用,则扩展其分析,包括参数和预测不确定性。在先验参数不确定性可用的情况下,PREDUNC7实用程序计算校准后的协方差矩阵。这可以使用PEST矩阵工具进行奇异值分解和特征分析。
SUPCALC实用程序计算解空间中的最佳维数,因此,通过推断,计算零空间。
5.6.5校准数据集信息内容
INFSTAT和INFSTAT1实用程序提供关于校准数据集的不同元素对参数估计的贡献的信息。如果预测敏感性是可用的,PREDUNC5将其扩展到预测。
SUPOBSPAR和SUPOBSPAR1实用程序描述了从校准数据集到参数解空间的信息流。
请参阅本手册的第二部分,了解上述实用程序的文档,以及许多其他实用程序的文档,这些实用程序可以为PEST进行的反转过程的结果增加价值。
5.6.6基于最优参数值的模型输出
在终止执行之前,PEST使用优化的参数值进行最后的模型运行。因此,在PEST运行结束时,所有模型输入文件都包含优化的参数,所有模型输出文件都包含基于这些参数计算的模型输出。
但是,请注意,在以下情况下,PEST将不会进行最终的模型运行:•如果使用“不带统计信息的停止”实用程序PSTOP终止其执行,或者如果您按下;•如果它因为遇到错误条件而终止执行;•是否正在进行svd辅助参数估计;•如果它正在作为并行PEST或BEOPEST运行,并且使用“stopwithstatistics”实用程序PSTOPST终止。
在最后一种情况下,PEST无法执行最终模型运行的原因是,当用户向PEST发出终止执行的指令时,所有代理通常都很忙。因此,最终的模型运行不能立即分配给任何代理。
但是,如果并行PEST在正常情况下终止执行,则最后的模型运行将由最快的可用代理进行;如果希望了解这是哪个代理,请参阅运行管理记录文件。然后,该代理使用的工作目录将包含基于优化参数值编写的模型输入和输出文件。
如果需要,使用估计参数的最终模型运行也可以手动进行。
有很多方法可以做到这一点,最简单的如下所示。
1. 使用PARREP实用程序创建一个新的PEST控制文件,该文件与现有的PEST控制文件相同,但使用优化的参数值替换该文件“参数数据”部分中的初始参数值。(如上所述,优化后的参数值可通过参数值文件获得;命名为case.par。)如果需要,可以使用SUBREG1实用程序从该文件中删除正则化。
2. 编辑新的PEST控制文件,将NOPTMAX(该文件“控制数据”部分第8行第一个变量)设置为0;因此,PEST将只进行一次模型运行,计算目标函数,然后停止执行。
或者,将NOPTMAX设置为-2以计算雅可比矩阵,或将NOPTMAX设置为-1以计算雅可比矩阵,然后提供完整的pest运行结束打印输出。
3. 使用新的控制文件运行PEST。
















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











