







 本文详细描述了MODFLOW-SURFACT/MODHMS的代码结构,包括其模块化设计、运行流程和传输模拟的三种类型。重点介绍了如何准备输入文件,包括流输入文件的修改和新传输文件的创建。文章还涵盖了空间和时间离散化的设置以及输入指令的详细说明。
本文详细描述了MODFLOW-SURFACT/MODHMS的代码结构,包括其模块化设计、运行流程和传输模拟的三种类型。重点介绍了如何准备输入文件,包括流输入文件的修改和新传输文件的创建。文章还涵盖了空间和时间离散化的设置以及输入指令的详细说明。
3.1 概述
本章介绍了 MODFLOW-SURFACT/MODHMS 代码结构和操作,并提供了准备 ACT 模块和相关包的输入文件的说明。 对于每台计算机运行,MODFLOW-SURFACT/MODHMS 提供流量和相关传输问题的双重分析。 如前所述,MODFLOW-SURFACT/MODHMS 的输入准备非常简单,并遵循 MODFLOW 格式结构。 运输模拟利用所有 MODFLOW 数据集,并且消除了该数据的重复。
本章介绍了输入准备指南,假设用户具有用于地下水流分析的现有数据文件,并准备好继续编辑这些文件以及为污染物迁移分析创建其他输入文件。 如果这个假设不正确,用户将需要参考 MODFLOW 用户手册和 MODFLOW-SURFACT/MODHMS 文件第一卷来创建流量输入文件。
3.2 代码结构及运行
MODFLOW-SURFACT/MODHMS 保留了原始 MODFLOW 代码的模块化结构。 类似的代码结构设计旨在促进流和传输模块的使用一致,并最大限度地减少用户的学习曲线。
MODFLOW-SURFACT/MODHMS 提供对流量和相关传输问题的完整分析。 图 3.1 显示了描述代码功能操作的一般流程图。 计算机内存首先被分配给流和传输模块的阵列。 接下来是读取和处理流和传输数据的例程。 然后读取每个应力周期的流量和传输的边界数据,并进入时间步进循环。 然后求解地下水流方程,然后求解每个时间步长的溶质输运方程。 如果流量处于稳态,则仅在第一个时间步长求解流量方程。 如图 3.1 所示,每个流时间步长输入一次传输模块。 图 3.2 所示为瞬态传输分析的一般程序。 传输例程组装并求解模拟中考虑的每个物种的传输方程。 对于非线性情况,执行迭代直到每个物种获得收敛。
使用 MODFLOW-SURFACT/MODHMS 可以进行三种类型的传输模拟,如下所述。
1. 瞬态流场中的瞬态输运模拟。
2. 稳态流场中的瞬态输运模拟。
3. 稳态流场中的稳态输运模拟。
第一种情况是瞬态流场中瞬态传输的最常见情况,其中针对每个应力周期的每个流动时间步长求解传输方程。 第二种情况是通过在MODFLOW中设置稳态标志(即ISS ≠ 0)来进行稳态流动模拟的情况。 随后,在该稳态速度场中,针对每个应力周期,针对所有时间步执行相关的输运模拟。 如果流场在应力周期之间发生变化,则通过设置 MODFLOW 的稳态标志(即 ISS≠0)并使用非常大的 (1010) 时间步长来进行场(场景 3)。
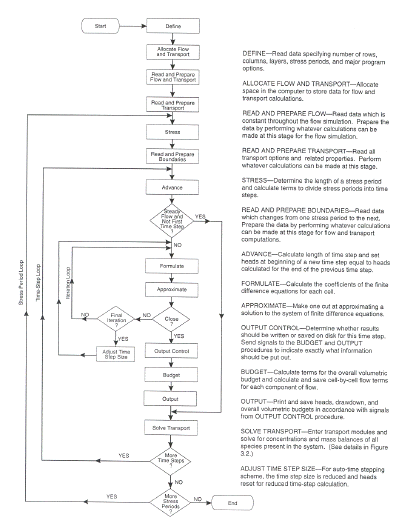
图 3.1 流程图描述了集成 MODFLOW-SURFACT/MODHMS 代码的功能操作。

图 3.2 描述瞬态传输分析计算程序的流程图。
如果在处理场景 2 和 3 时,稳态流不收敛,则需要在很长一段时间内使用瞬态模拟方法来解决问题,直到存储项减少到可忽略不计的值并达到稳态条件 。 然后,最终的一组水头值可以用作代码的起始条件,以在使用完全瞬态方法的后续组合流动/传输模拟运行中完成分析。 由于流场接近或处于稳态,因此流动解应该快速收敛。
MODFLOW-SURFACT/MODHMS 中的传输解决方案选项可以通过基本传输 (BTN1) 包中设置的两个标志来指定(第 3.4.2 节中描述)。 标志 IACLVL 控制空间精度,标志 THETRD 控制时间离散化精度。 标志 IACLVL 提供以下空间近似选项:
如果在处理场景 2 和 3 时,稳态流不收敛,则需要在很长一段时间内使用瞬态模拟方法来解决问题,直到存储项减少到可忽略不计的值并达到稳态条件 。 然后,最终的一组水头值可以用作代码的起始条件,以在使用完全瞬态方法的后续组合流动/传输模拟运行中完成分析。 由于流场接近或处于稳态,因此流动解应该快速收敛。
MODFLOW-SURFACT/MODHMS 中的传输解决方案选项可以通过基本传输 (BTN1) 包中设置的两个标志来指定(第 3.4.2 节中描述)。 标志 IACLVL 控制空间精度,标志 THETRD 控制时间离散化精度。 标志 IACLVL 提供以下空间近似选项:
1. 全上游加权(IACLVL=0);
2. 由代码自动确定上游因子的混合(上游-中心差组合)加权(IACLVL=1);
3. 用户定义的空间权重(IACLVL=–1); 或者
4. 采用 van Leer 通量限制器的 TVD 方案 (IACLVL–2)。
前三个方案是线性方案,而最后一个方案是非线性的,用于非显式时间步进。 建议新手运输建模者为早期校准模拟设置 IACLVL = 0 或 1,对于需要更高精度的最终模拟,可以将其切换为 IACLVL = –2。
THETRD 标志提供以下时间离散化选项:
1. 自动选择隐式(THETRD=0);
2. 完全隐式时间加权(THETRD=1);
3. 曲柄尼科尔森时间加权(THETRD=0.5); 和
4. 明确的时间加权 (THETRD=0.0001)。
建议新手运输建模者始终使用 THETRD=0。 对于非 TVD 方案,这将提供具有二阶时间精度的 Crank-Nicolson 时间加权。 对于 TVD 方案,选择的隐式尽可能接近 Crank-Nicolson,而不违反 TVD 属性。 有经验的建模者可以选择 THETRD 的任何值,从完全隐式到完全显式。 当使用显式方案时,稳定性条件由 MODFLOW-SURFACT/MODHMS 自动检查。 通过设置 IACLVL=–2 并将最大传输迭代次数 (MXITERC) 设置为 2,可以针对线性传输问题实施通量校正传输 (FCT) 方案。用户应确保模拟中的库朗数不会比 1 大很多 当使用 FCT 方案时,为了保持解的精度。 请注意,库朗数定义为 VΔt/Δx,其中 V 是污染物或溶质速度,Δt 是时间步长,Δx 是网格节点间距。
对于非线性传输模拟(由于非线性延迟或使用非线性 TVD 方案),传输迭代的最大数量 (MXITERC) 应大于 1。 如果在指定的迭代次数(建议次数在 5 到 25 之间)内未实现收敛,则时间步长减半,并针对该物种重复传输解决方案。 重复此过程,直到实现收敛或达到最大时间步减少数 (NNOTCV),从而中止模拟。 在进入下一个目标时间步之前,获得所有子时间步的收敛解。 可以通过设置 MXITERC=1 来实现对此项的时间滞后,但不建议这样做。 FCT类型的更新可以通过将MXITERC设置为2来执行。
对于包含残差、溶解 NAPL 相(即,如果 IEQPART=2)的输运模拟,索引 MXOUTIT 确定非线性输运迭代的最大数量(建议值在 5 到 25 之间),索引 NITFLASH 确定牛顿迭代的最大数量 在闪存计算期间执行(建议值在 10 到 30 之间)。 如果 MXOUTIT 设置为 1,则重新分配 NAPL 阶段的饱和更新会出现时间滞后,但不建议这样做。 如果 MXOUTIT=2,则在进入下一个时间步之前执行校正迭代,如 FCT 方案中那样。 对于 MXOUTIT $3,传输解决方案将继续进行直至收敛。 如果在规定的 MXOUTIT 迭代内未实现收敛,则时间步长减半,并且针对较小的时间值,与闪存计算一起重复所有物种的传输解决方案。 在进入下一个目标时间步骤之前,获得所有子时间步骤的收敛解。
请注意,自动时间步进不受非线性传输模拟收敛行为的影响。 当用于稳态流动条件时,自动时间步长的
行为类似于 MODFLOW 的常规时间步长增量方案,具有不能超过的时间步长最大限制。 最大时间步长是所有涉及传输的模拟的重要考虑因素,因为大库朗数可能会因时间离散误差而产生显着的数值色散。 用户对空间和时间离散化的良好判断是不容易替代的。
3.3 输入准备的基本程序
如前所述,MODFLOW-SURFACT/MODHMS 旨在在单台计算机运行中对地下水流和污染物迁移进行双重分析。 因此,在此阶段假设用户已经创建或获得了用于地下水流模拟的输入文件。 有了这个假设,涉及运输模拟选项所需的输入准备的基本程序就很简单了。
本质上,用户需要修改相关的流输入文件并创建最多三个新的输入文件,其中包含传输建模所需的附加信息。 表 3.1 显示了相关流程包和三个传输包的识别和输入功能,下一节将介绍输入准备的详细说明。
3.4 输入指令
3.4.1 概述
本节提供了准备代码所需的附加输入数据的一般和具体说明,以便在同一计算机运行中同时进行输运模拟和地下水流模拟。
用户通过 BAS 包的控制变量(ITRAN)指定传输模拟的要求,如第 3.4.2 节所述。 BAS 包已被修改,以合并 ITRAN 和传输分析所需的附加输入文件单元。 BTN1、HCN1 和 PCN1 包使用这些输入文件单元读取与传输参数和第一类边界条件相关的数据,如第 3.4.3 节到第 3.4.5 节中所述。 第 3.4.6 节到第 3.4.11 节提供了 WEL、DRN、RIV、GHB、RSF4 和 FWL4 包的输入指令,所有这些包都经过修改以纳入用于传输模拟的附加接收器/源数据。 请注意,接收器/源包仅在需要时才被调用(即,当相关接收器/源存在于流域中时)。
为了求解输运矩阵方程,MODFLOW-SURFACT/MODHMS 采用了具有矩阵预处理和正交加速的迭代方法,称为 Orthomin 技术,包含在 PCG4 包中。 第 3.4.12 节提供了 PCG4 求解器的输入指令。 最后,第 3.4.13 节和第 3.4.14 节详细介绍了 OC 和 ATO4 包的输入指令。 整个流动和传输模拟打印输出由从这两个中选择的包控制。 请注意,特别提倡使用 ATO4 包的自适应时间步进来进行无侧限流模拟。
















 2170
2170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











