






CVPR2022
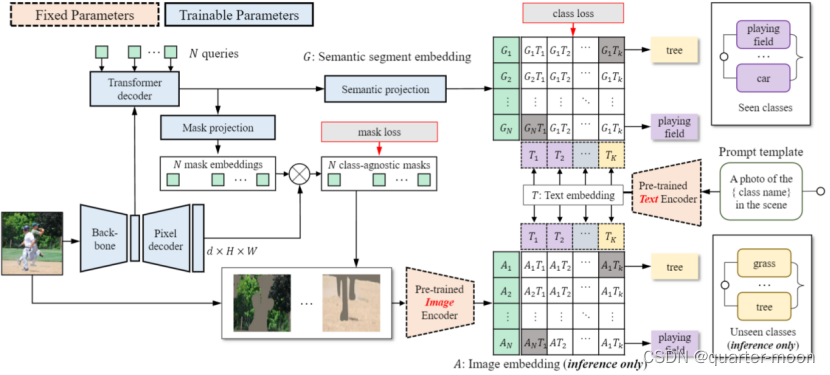
进行Zero-shot语义分割的ZegFormer:首先将N个query(N取100,一般小于语义数量)和backbone得到的特征提供给transformer decoder,生成N个segment embedding。然后将每个segment embedding分别再经过一层全连接改变通道数得到语义嵌入,以及通过mlp得到mask embedding。Mask embedding与pixel decoder的输出相乘得到不知道对应类别的二进制掩码,而语义嵌入则通过用clip得到的文本嵌入进行分类。
训练阶段,只使用所看到的类来训练分类头,在生成的二进制掩码mask和语义嵌入经过文本嵌入作为分类器得到的分类logits,使用bipartite matching,损失和二分图匹配的cost与mask former一样。
Inference阶段,通过二进制掩码mask原图(或者crop原图,论文消融分析得到mask同时crop原图效果最好),得到只包含对应语义的图,将其输入clip预训练好的image encoder得到图片embedding,和训练阶段类似使用文本嵌入作为分类器得到预测语义类。
总体上看,使用ResNet50作为骨干,FPN作为像素解码器。Image encoder采用clip的vit-B
/16。
为什么采用mask former的结果生成mask?(1)由于mask的学习不涉及语义类别,相当于从ZS3中分离出一个类未知学习子任务。类不可知论任务对训练集不包含的类别具有很强的泛化能力。(2)由于人类经常将语义与整个图像或至少片段相关联,从语义建立到片段级视觉特征的联系比建立到像素级视觉特征的联系更为自然。因此,论文说zegformer比像素级zero-shot分类更有效地将知识从可见类转移到不可见类。
对“无对象”类别的处理?如果某个query和任何ground truth之间的IoU很低,就需要一个“无对象”类别。因此添加了一个额外的可学习嵌入T0∈Rd表示“无对象”。对于分段查询,所见类和“无对象”的预测概率分布计算如下。
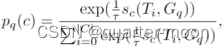
,其中![]() 是余弦相似度。
是余弦相似度。![]() 是语义嵌入,Ti是文本嵌入。p 'q (c)是用图像embedding代替Gq,只用在inference阶段的预测分数。
是语义嵌入,Ti是文本嵌入。p 'q (c)是用图像embedding代替Gq,只用在inference阶段的预测分数。
Inference阶段两个预测分数如何结合?
(1)zegformer-seg结构:结合使用语义嵌入预测的分数和mask,通过计算每像素类概率![]() ,其中(h, w)是图像中的位置。由于数据不平衡的问题导致预测偏向于可见的类别。通过降低所见类的分数来校准预测。然后计算每个像素的最终类别预测为:
,其中(h, w)是图像中的位置。由于数据不平衡的问题导致预测偏向于可见的类别。通过降低所见类的分数来校准预测。然后计算每个像素的最终类别预测为:
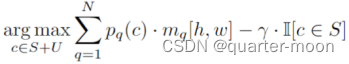
其中γ∈[0,1]为标定因子。当c属于所见类时,指示函数I = 1。
- 论文采用的:如果c∈U(不可见集),使用pq (c)和p 'q (c)。两种分类分数的贡献用λ来平衡。由于如果c∈S(可见集), pq (c)通常比p 'q (c)更准确,因此不希望p 'q (c)有助于对S的预测。因此,我们计算
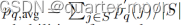 。这样,可见类和不可见类的概率可以调整到相同的范围,并且只有pq (c)有助于区分可见类。论文采用的是在zegformer-seg的基础上将pq (c)用下式的pq,fusion (c)代替。
。这样,可见类和不可见类的概率可以调整到相同的范围,并且只有pq (c)有助于区分可见类。论文采用的是在zegformer-seg的基础上将pq (c)用下式的pq,fusion (c)代替。
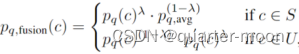
结果:
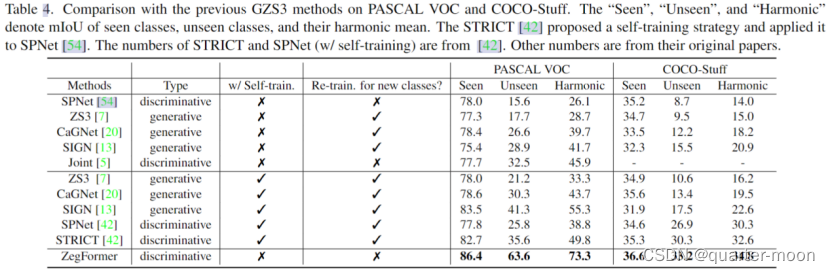
Zegformer上的结果:
Zegot和zegformer和zegclip的比较:
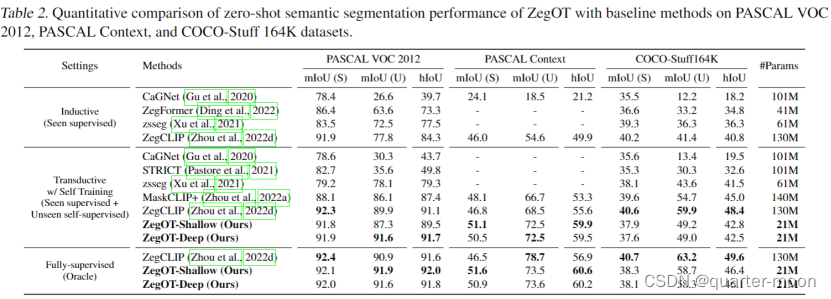
可以看到,zegot在pascal context和pascal voc上都和zegclip基本一致,但在coco-stuff164k上zegclip效果更好。















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









