






HOMIE: Humanoid Loco-Manipulation with Isomorphic Exoskeleton Cockpit
研究动机
- 大多数遥操作人形机器人的方式主要集中在控制上半身,由于缺乏机器人自由移动或调整姿势(如蹲下)以适应不同的任务需求,显著限制了机器人的操作空间。
- 人形机器人全身操作方法要求操作者亲自移动来控制机器人的运动,这使得在长距离内保持精确和稳定的全身操作变得极具挑战性。
- 主流的远程操作系统通常依赖基于视觉的方法或异构外骨骼来确定末端执行器的姿态,然后通过逆运动学来计算关节位置。 然而,姿态估计和逆向运动学求解都会引入不准确性,这会损害远程操作的精确性和可靠性。
解决方案
提出HOMIE,一种人形机器人远程操作座舱,由人形机器人移动操作策略和基于外骨骼的硬件系统组成。该座舱使单个操作员能够精确高效地控制人形机器人的全身动作,以执行各种移动操作任务。具体来说,引入了三种核心技术到基于强化学习的训练框架中:上半身姿态课程、高度跟踪奖励和对称性利用。这些组件共同增强了机器人的物理灵活性,使其能够实现稳健行走、快速蹲下到任何所需高度以及在动态上半身动作期间保持稳定平衡,从而显著扩大了机器人的操作工作空间,超越了现有解决方案。与依赖于来自动捕数据的动作先验的全身控制方法不同,该框架消除了这种依赖性,从而实现了一个更高效的流程。硬件系统包括同构外骨骼手臂、一对运动感应手套和一个踏板。 踏板设计用于获取移动命令,解放操作者的上半身,使同时获取上半身姿态成为可能。由于外骨骼手臂与受控机器人等效,每副手套有 15 个自由度,比大多数现有的灵巧手多。该框架可以直接从外骨骼读数设置上半身关节位置,无需进行逆运动学计算,从而实现更快更准确的远程操作。
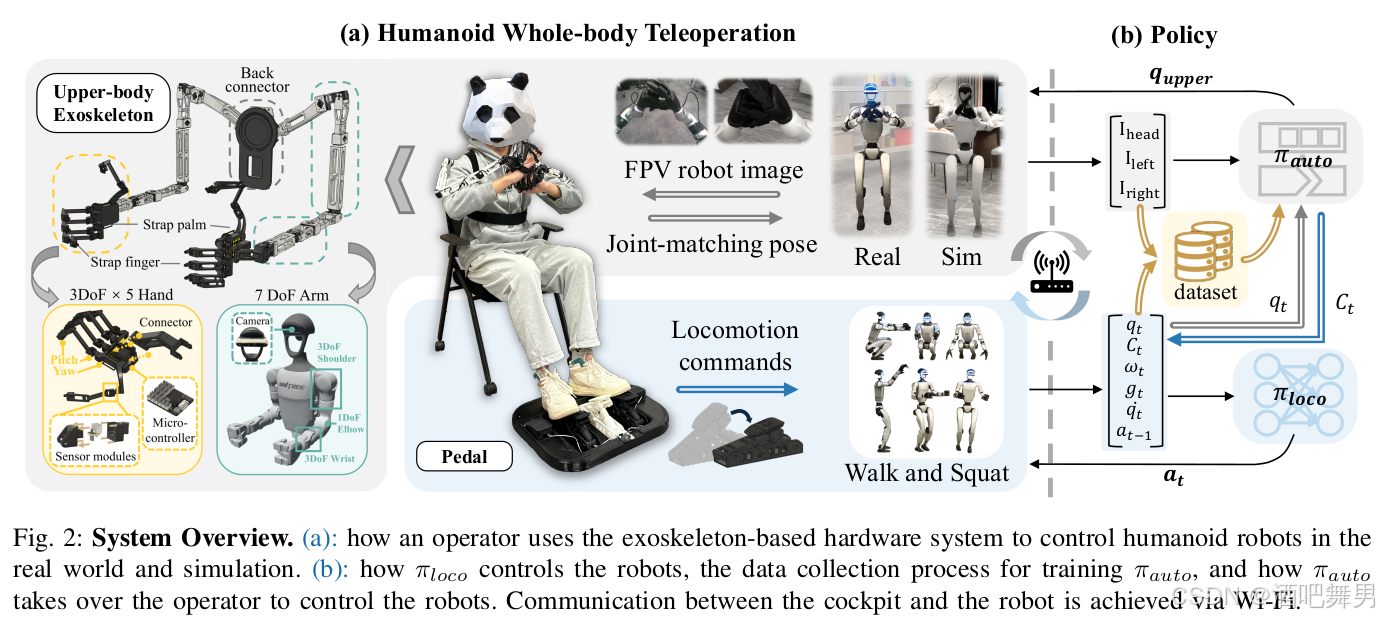
技术路线
系统概述:HOMIE由底层策略 π l o c o \pi_{loco} πloco和基于外骨骼的硬件系统组成。在给定时间 t t t,操作员通过显示器以机器人第一视角观察。通过踩踏踏板,操作员提供所需的移动命令 C t = [ v x , t , ω y a w , h t ] C_t=[v_{x,t},\omega_{yaw},h_t] Ct=[vx,t,ωyaw,ht],分别为期望前进/后退速度,专项速度,机器人躯体的目标高度。策略 π l o c o \pi_{loco} πloco基于 C t C_t Ct控制机器人的下身,同时,操作员控制外骨骼提供所需的关节角度供机器人的上身使用,外骨骼关节角直接设置到机器人本体上。通过该系统可收集演示数据并使用它们训练自主策略 π a u t o \pi_{auto} πauto,并接管操作员,从而驱动机器人自主执行任务。
行走策略训练:单步观察定义为 O t = [ C t , ω t , g t , q t , q ˙ t , a t − 1 ] O_t=[C_t,\omega_t,g_t,q_t,\dot{q}_t,a_{t-1}] Ot=[Ct,ωt,gt,qt,q˙t,at−1],分别为命令、机器人本体角速度、重力在机器人躯干坐标系的投影、关节角度、关节角速度,上一帧的动作。然后,堆叠连续五帧 O t − 5 : t O_{t-5:t} Ot−5:t来获取完整的观察值。策略输出的 a t a_t at与机器人的下肢关节一一对应。在获取策略输出的动作后,使用PD控制器去计算关节电机的力矩,以驱动电机工作实现机器人运动。
使用课程学习技术以确保策略在机器人上半身以任何连续变化的姿态下仍能完成移动任务。通过上身动作比例 r a r_a ra来调整上半身关节角度的采样范围。训练初期 r a = 0 r_a=0 ra=0,每当策略驱动机器人跟踪线速度并达到奖励阈值时, r a r_a ra增加0.05,直至最大值1。首先,从概率分布中采样 r a ′ r'_a ra′:
p ( x ∣ r a ) = 20 ( 1 − r a ) e − 20 ( 1 − r a ) x 1 − e − 20 ( 1 − r a , r a ∈ [ 0 , 1 ) p(x|r_a)=\frac{20(1-r_a)e^{-20(1-r_a)x}}{1-e^{-20(1-r_a}},r_a \in [0,1) p(x∣ra)=1−e−20(1−ra20(1−ra)e−20(1−ra)x,ra∈[0,1)
然后根据分布 U ( 0 , r a ′ ) \mathcal{U}(0,r'_a) U(0,ra′)重采样 a t a_t at,实际上采样 a t a_t at:
a i = U ( 0 , − 1 20 ( 1 − r a ) l n ( 1 − U ( 0 , 1 ) ( 1 − e − 20 ( 1 − r a ) ) ) a_i=\mathcal{U}(0,-\frac{1}{20(1-r_a)}ln(1-\mathcal{U}(0,1)(1-e^{-20(1-r_a)})) ai=U(0,−20(1−ra)1ln(1−U(0,1)(1−e−20(1−ra)))
与直接使用 U ( 0 , r a ′ ) \mathcal{U}(0,r'_a) U(0,ra′)相比,这种方法以更平滑和渐进的方式接近最终目标。为模拟由座舱控制时上半身运动的连续变化,每1秒根据上述过程重新采样目标上半身姿态。然后使用均匀插值,确保目标运动在1秒间隔内逐渐从当前值变化到期望值。如果没有这种方法,会发现机器人在连续运动中难以保持平衡。
跟踪高度可以显著扩展人形机器人的可行操作工作空间,从而帮助机器人执行更多的移动操作任务。因此, π l o c o \pi_{loco} πloco需要使机器人能够蹲到目标高度 h t h_t ht。为了实现这一点,设计奖励函数:
r k n e e = − ∣ ∣ ( h r , t − h t ) × ( q k n e e , t − q k n e e , m i n q k n e e , m a x − q k n e e , m i n − 1 2 ) ∣ ∣ r_{knee}=-||(h_{r,t}-h_t)\times(\frac{q_{knee,t}-q_{knee,min}}{q_{knee,max}-q_{knee,min}}-\frac{1}{2})|| rknee=−∣∣(hr,t−ht)×(qknee,max−qknee,minqknee,t−qknee,min−21)∣∣
其中 h r , t h_{r,t} hr,t是机器人的实际高度, q k n e e , m i n q_{knee,min} qknee,min和 q k n e e , m a x q_{knee,max} qknee,max是膝关节的最小和最大值。 q k n e e , t q_{knee,t} qknee,t是膝关节的当前值。在训练过程中,每4秒重新采样所有命令。在此过程中,随机选择三分之一的环境来训练机器人蹲下,而其余三分之二则专注于机器人站立和行走。这种策略有助于平衡蹲下和行走的学习。此外,相同的环境在学习蹲下和学习行走之间切换,使策略能够平滑地过渡到蹲下和行走任务。
对称利用:每次从仿真中获取 T t = ( s t , a t , r t , s t + 1 ) T_t=(s_t,a_t,r_t,s_{t+1}) Tt=(st,at,rt,st+1)后,对其进行翻转操作。具体来说,根据机器人x-z平面的对称性Actor和Critic的观察结果进行对称变换。包括将机器人左右关节的位置、速度和动作以及期望的转向速度在x-z平面上进行翻转,以获得一个镜像 T t ′ T'_t Tt′。然后将 T t T_t Tt和 T t ′ T'_t Tt′都添加到回放存储中。这个过程有助于提高数据效率,并确保采样数据的对称性,从而降低训练策略在左右性能上不对称的可能性。在学习阶段,将此过程应用于从回放存储中获得的样本 T t T_t Tt,以获得 T t ′ T'_t Tt′。然后将 Tt 和 Tt′ 分别通过演员和评论家网络,得到 a t a_t at、 a t ′ a'_t at′、 V t V_t Vt、 V t ′ V'_t Vt′,用于计算额外的损失。
L
s
y
m
a
c
t
o
r
=
M
S
E
(
a
t
,
a
t
′
)
L_{sym}^{actor}=MSE(a_t,a'_t)
Lsymactor=MSE(at,at′)
L
s
y
m
c
r
i
t
i
c
=
M
S
E
(
V
t
,
V
t
′
)
L_{sym}^{critic}=MSE(V_t,V'_t)
Lsymcritic=MSE(Vt,Vt′)

外骨骼:略。
实验结果
请阅读原文。
方法限制
- 无法确保在多种地形上可靠地行走,仍然限制了操作范围。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









