







MGFN : Magnitude-Contrastive Glance-and-Focus Network for Weakly-Supervised Video Anomaly Detection 论文阅读
文章信息:

发表于:AAAI2023
文章链接:https://arxiv.org/abs/2211.15098
源代码:https://github.com/carolchenyx/MGFN.
备注:选取的baseline是RTFM
Abstract
监控视频中异常的弱监督检测是一项具有挑战性的任务。超越现有工作对于长视频中异常定位能力不足的局限性,我们提出了
- 一种新颖的扫视与聚焦网络,以有效地整合时空信息,实现精确的异常检测。
此外,我们在经验上发现,现有方法通常使用特征幅度来表示异常程度,但忽视了场景变化的影响,因此由于特征幅度在场景之间的不一致性而导致性能不佳。
为了解决这个问题,我们提出了
- 特征放大机制和幅度对比损失来增强特征幅度的区分能力,用于检测异常。
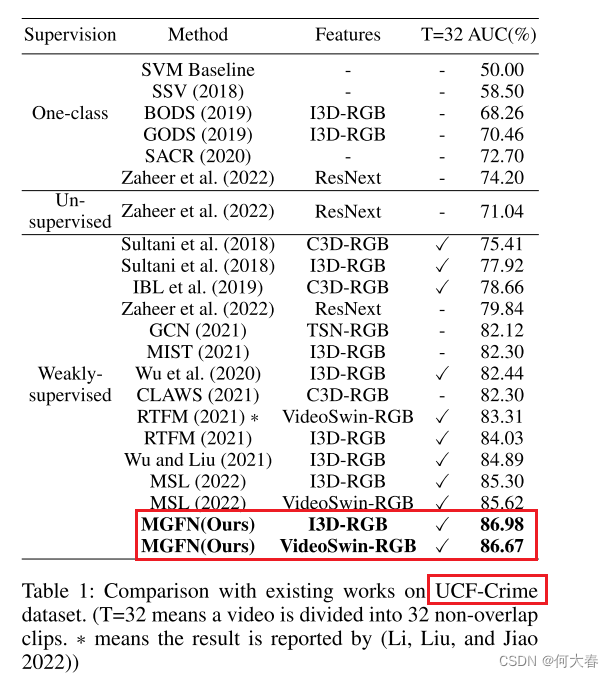
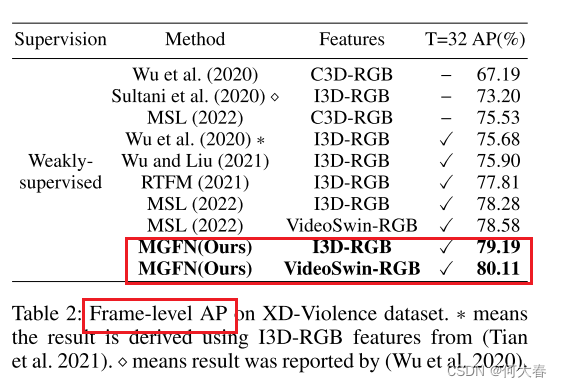
在两个大型基准数据集 UCF-Crime 和 XD-Violence 上的实验结果表明,我们的方法优于现有最先进的方法。
方法
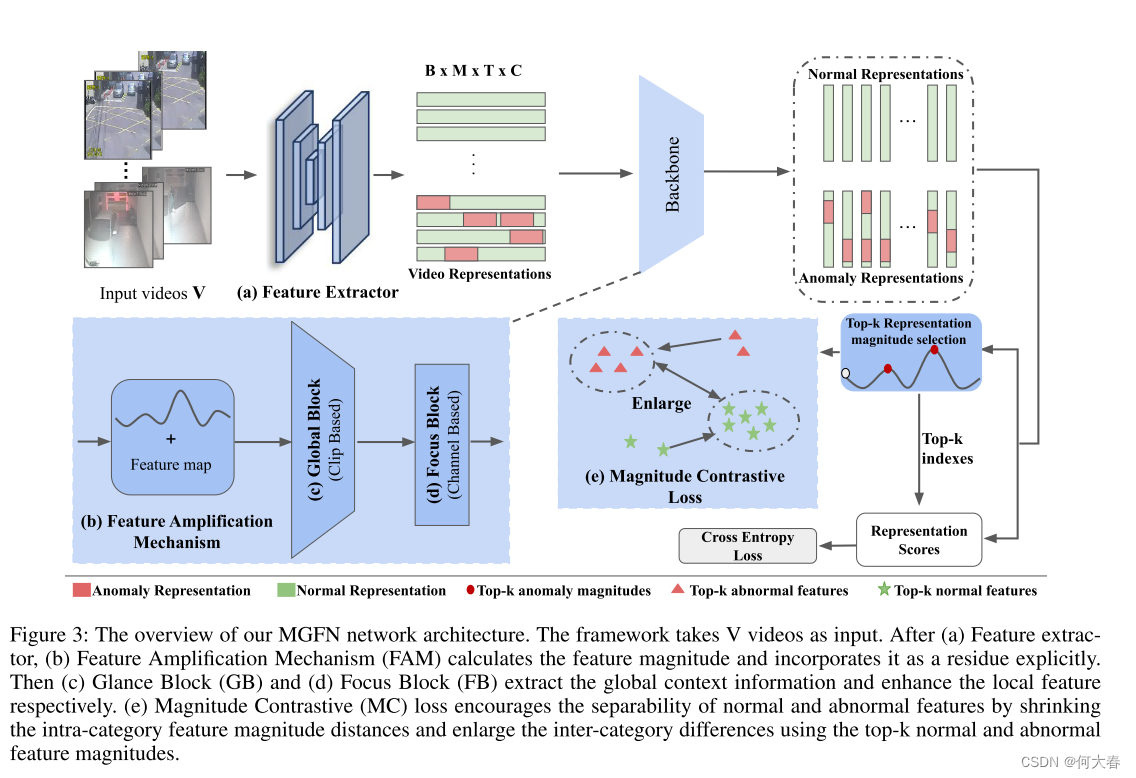
我们的框架架构如图3所示。首先,特征提取器以带有视频级注释的未修剪视频
V
V
V作为输入(见图3(a)),其中,
V
i
∈
R
N
i
×
H
×
W
×
3
V_i∈\mathbb{R}^{N_i×H×W×3}
Vi∈RNi×H×W×3,
N
i
N_i
Ni,
H
H
H,
W
W
W分别表示视频
V
i
V_i
Vi的帧数、高度和宽度。然后我们将每个视频序列均匀分成
T
T
T个片段,并将特征提取器生成的特征图表示为:
F
=
F=
F={
f
i
,
t
,其中
i
∈
[
1
,
B
]
f^{i,t},其中i∈[1,B]
fi,t,其中i∈[1,B],t∈[1,T]}
∈
R
B
×
T
×
P
×
C
∈\mathbb{R}^{B×T×P×C}
∈RB×T×P×C,其中P是每个视频片段的作物数量,C是特征维度,
f
i
,
t
∈
R
P
×
C
f^{i,t}∈\mathbb{R}^{P×C}
fi,t∈RP×C表示
V
i
V_i
Vi中第
t
t
t个视频片段的特征。
以特征图 𝐹 作为输入,特征放大机制(FAM)(图3(b))明确计算特征范数 𝑀 以增强 𝐹 。然后,Glance Block(GB)和Focus Block(FB)(图3(c,d))结合了基于视频片段级transformer(VCT)和自注意力卷积(SAC)构建的全局和局部特征。与(Tian et al. 2021)中简单地最大化异常特征 f a f_a fa的幅度并最小化正常特征 f n f_n fn 不同,我们设计了一个幅度对比(MC)损失(图3(e))来最大化正常特征和异常特征之间的可分性。接下来,我们将详细介绍 MGFN 的每个组件以及网络训练中的损失函数。
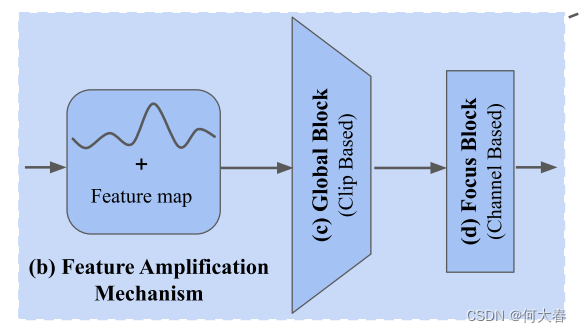
Feature Amplification Mechanism (FAM)
如图3(b)所示,FAM 首先明确地根据方程(1)计算
f
i
,
t
f^{i,t}
fi,t的特征范数
M
i
,
t
M^{i,t}
Mi,t。
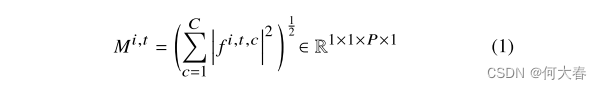
其中,c表示特征维度索引。
随后,FAM通过将一维卷积调制特征范数
C
o
n
v
1
D
(
M
i
,
t
)
Conv1D(M^{i,t})
Conv1D(Mi,t)添加到
f
i
,
j
f^{i,j}
fi,j作为残差,得到增强的特征
F
F
A
M
=
F_{FAM}=
FFAM={
f
F
A
M
i
,
t
f^{i,t}_{FAM}
fFAMi,t}如等式2所示:
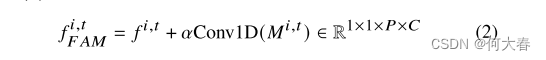
其中,𝛼是一个超参数,用于控制范数项的影响效果,Conv1D是一个单层一维卷积网络,用于调制每个维度的特征范数。
在不影响特征图的维度的情况下,FAM通过明确地将特征范数(一种统一的异常表示)纳入网络中来放大特征图,从而使得后面将要讨论的幅度对比损失受益。
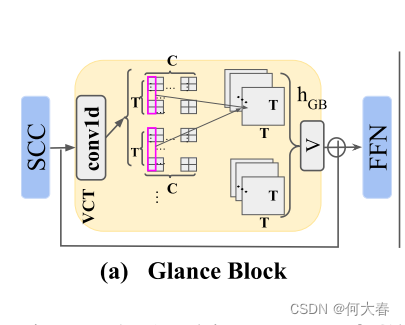
Glance Block
Glance Block的架构如图4(a)所示。为了减轻计算负担,我们首先使用卷积将特征图𝐹𝐴𝑀中的维度从𝐶减少到𝐶/32。经过一个短路卷积(SCC)输出特征图
F
s
c
c
_
G
B
∈
R
B
×
T
×
P
×
C
/
32
F_{scc\_GB} \in \mathbb{R}^{B×T×P×C/32}
Fscc_GB∈RB×T×P×C/32,我们构建一个视频片段级transformer(VCT)来学习片段之间的全局相关性。具体来说,我们建立了一个注意力映射
A
∈
R
1
×
T
×
T
×
P
A\in \mathbb{R}^{1×T×T×P}
A∈R1×T×T×P来明确地不同的时间片段的相关性。
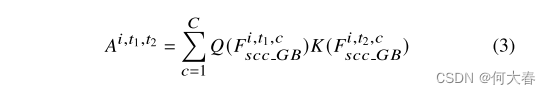
其中,
t
1
t_1
t1,
t
2
t_2
t2 ∈ [1, 𝑇],𝑄,𝐾是transformer中的一维“查询”和“键”卷积。
接下来,我们使用softmax标准化来生成
a
∈
R
1
×
T
×
T
×
P
a∈ \mathbb{R}^{1×T×T×P}
a∈R1×T×T×P,其中
a
i
,
t
1
,
:
a^{i,t_1,:}
ai,t1,:表示其他片段与片段
t
1
t_1
t1相关联的程度。
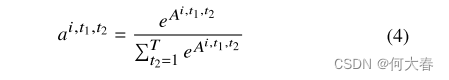
视频片段级transformer(VCT)的输出
F
a
t
t
_
G
B
∈
R
B
×
T
×
P
×
C
/
32
F_{att\_GB} \in \mathbb{R}^{B×T×P×C/32}
Fatt_GB∈RB×T×P×C/32是长视频中所有片段(包括正常和异常片段,如果存在的话)的加权平均值:
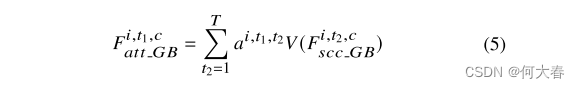
因此,Glance Block为网络提供了关于“正常情况是什么样子”的知识,以更好地检测异常事件。此外,它帮助网络更好地利用长期的时间上下文。
Glance Block包含一个额外的前馈网络(FFN),包括两个全连接层和一个 GeLU 非线性函数,以进一步提高模型的表示能力。输出特征图 F G B F_{GB} FGB 被送入接下来的Focus Block块。
Focus Block
如图4(b)所示,Focus Block(FB)由一个短路卷积(SCC)、一个自注意力卷积(SAC)和一个前馈网络(FFN)组成。以 F G B F_{GB} FGB为输入,我们首先通过卷积将通道数增加到𝐶/16。然后,SSC 生成特征图 F S C C _ F B F_{SCC\_FB} FSCC_FB。
受自注意力机制启发,我们提出了自注意力卷积(SAC)来增强每个视频片段中的特征学习。具体地,我们利用
F
S
C
C
_
F
B
F_{SCC\_FB}
FSCC_FB 作为特征图和卷积核,并将这一步骤制定为一个卷积,卷积核大小为5,如方程(6)和(7)所示。
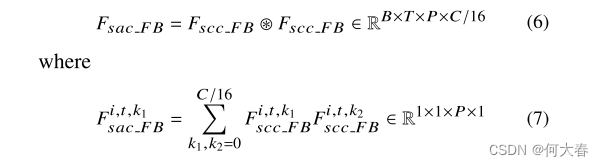
类似于自注意力机制,我们的自注意力卷积允许每个通道访问附近的通道,以学习通道间的相关性,而无需任何可学习的权重。经过两层前馈网络,Focus Block输出特征图
F
F
B
F_{FB}
FFB。

Loss Functions
在本节中,我们介绍我们的损失函数。由于异常检测是一个二元分类问题,对于预测得分,一个自然的损失函数是类似于现有工作(Wan等,2020;Zhong等,2019;Wu等,2020;Tian等,2021)的sigmoid交叉熵损失: L s c e = − y log ( s i , j ) − ( 1 − y ) log ( 1 − s i , j ) L_{sce} = -y \log(s^{i, j}) - (1 - y) \log(1 - s^{i, j}) Lsce=−ylog(si,j)−(1−y)log(1−si,j)其中,𝑦是视频级别的真实标签(𝑦 = 1 表示异常),而 s i , j s^{i, j} si,j 是片段 𝑗 的预测异常概率。
Magnitude Contrastive Loss为了更好地鼓励特征可分性,我们提出了等式(8)的幅度对比(MC)损失
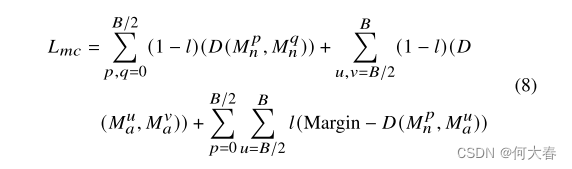
请注意,在一个训练批次𝐵中,我们抽样了𝐵/2个正常视频和𝐵/2个异常视频。𝑝,𝑞是正常片段的索引,而𝑢,𝑣是异常片段的索引。
M
a
M_a
Ma表示异常片段的前k个特征幅度,
M
n
M_n
Mn表示正常片段的前k个特征幅度。𝐷(·,·)是一个距离度量,稍后将会描述。𝑙是一个指示函数,其中𝑙 = 1表示采样了一对正常和异常片段𝑝,𝑢。在这种情况下,𝐿𝑚𝑐增加了它们之间特征幅度的距离。𝑙 = 0表示两个采样的片段𝑝,𝑞或𝑢,𝑣都是正常或异常的,其中
L
m
c
L_{mc}
Lmc将它们分组在一起。
与 Tian 等人(Tian et al.,2021)简单地增加异常片段的特征幅度并减小正常片段的做法不同,我们的 MC 损失学习了一种场景自适应的跨视频特征幅度分布。具体来说,MC 损失不会强制要求所有不同场景中的异常特征都大于正常特征。相反,它鼓励模型使用适当的分布将它们分开。例如,我们允许一个有大量运动的正常视频具有比异常视频更大的特征幅度。伴随网络学习到的其他特征,例如与场景和运动相关的特征,模型仍然可以正确预测异常。此外,我们进一步发现在同一视频和相似场景中,异常特征幅度通常大于正常特征幅度(见图2(c)),这与 RTFM 损失的目标一致(Tian et al.,2021).
D
(
M
n
p
,
M
n
q
)
D\left(M_n^p,M_n^q \right)
D(Mnp,Mnq)定义如公式(9)所示:
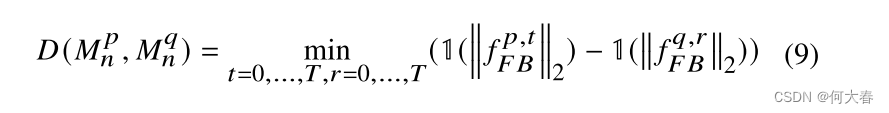
𝟙 是一个 top-k 均值函数,其中 𝟙( ||
f
F
p
,
t
B
f^{p,t}_FB
fFp,tB||
2
_2
2 ) 是在
f
F
B
p
,
{
1
,
.
.
.
,
T
}
f_{FB}^{p,\{1,...,T\}}
fFBp,{1,...,T} 中顶部k个特征幅度中的一个。 𝐷 (·, ·) 基于每个视频的𝑇个片段中的顶部k个最大特征幅度片段推导出特征距离。选择顶部k个片段而不是整个视频序列有助于在视频级别弱监督下进行模型训练。由于缺乏片段级别的异常性真实标签,顶部k个选择帮助
L
m
c
L_{mc}
Lmc关注那些在异常视频中最有可能异常的片段,以及正常视频中最困难的情况。同时,我们还从顶部k个正常片段和顶部k个异常片段中选择最大距离对,并通过
L
m
c
L_{mc}
Lmc 鼓励它们的相似性。
类似地,正常特征量和异常特征量之间的距离
D
(
M
n
p
,
M
a
u
)
D\left(M_n^p,M_a^u \right)
D(Mnp,Mau)被定义为等式(10)。
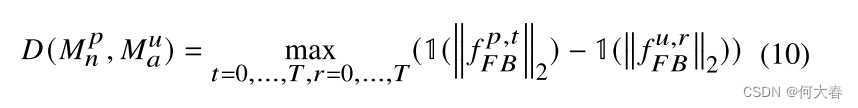
Overall Loss Functions在 Sultani 等人(Sultani, Chen, and Shah 2018)的工作中,我们采用了时间平滑损失
L
t
s
=
∑
j
=
1
T
(
s
a
i
,
j
)
L_{ts} = \sum_{j=1}^{T} (s_a^{i,j})
Lts=∑j=1T(sai,j) 和稀疏性损失
L
s
p
=
∑
j
=
1
T
(
s
a
i
,
j
−
s
a
i
,
j
+
1
)
2
L_{sp} = \sum_{j=1}^{T} (s_a^{i,j} - s_a^{i,j+1})^2
Lsp=∑j=1T(sai,j−sai,j+1)2 ,其中
s
i
,
j
s_{i,j}
si,j 表示异常片段的预测分数。它们作为正则化项,平滑相邻视频片段的预测分数。因此,在模型训练中的总损失为:
L
=
L
s
c
e
+
λ
1
L
t
s
+
λ
2
L
s
p
+
λ
3
L
m
c
L = L_{sce} + \lambda_1 L_{ts} + \lambda_2 L_{sp} + \lambda_3 L_{mc}
L=Lsce+λ1Lts+λ2Lsp+λ3Lmc,其中
λ
1
,
λ
2
,
λ
3
\lambda_1, \lambda_2, \lambda_3
λ1,λ2,λ3 是平衡损失项的损失权重。
Experiment
Conclusion
这篇论文介绍了一个新颖的框架 MGFN,其中包含一个扫描与聚焦模块和一个幅度对比损失用于异常检测。
模仿人类的全局到局部视觉系统,提出的 MGFN 包含一个扫描和聚焦机制,以有效地整合全局上下文和局部特征。
此外,提出了一个特征放大机制(FAM),用于增强模型对特征幅度的感知。
为了学习场景自适应的跨视频特征幅度分布,引入了一个幅度对比损失,以鼓励正常和异常特征幅度的可分离性。
在两个大型数据集 UCF-Crime 和 XD-Violence 上的实验结果表明,该方法在很大程度上优于现有的最新工作。















 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









