








论文标题:
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
论文链接:
https://arxiv.org/abs/2012.07436
源码链接:
https://github.com/zhouhaoyi/ETDataset
摘要
许多实际应用都需要对长序列时间序列进行预测,例如电力消耗规划。长序列时间序列预测(LSTF)要求模型具有较高的预测能力,即能够有效地精确捕捉输出与输入之间的长期依赖关系。最近的研究表明,Transformer具有提高预测能力的潜力。然而,Transformer存在一些严重的问题,这些问题使它不能直接应用于LSTF,包括二次时间复杂度、高内存占用和编码器-解码器架构的固有局限性。为了解决这些问题,我们设计了一个高效的基于Transformer的LSTF模型,命名为Informer,它有三个显著的特点:(i) ProbSparse自我注意机制,在时间复杂度和内存使用方面达到O(L log L),在序列依赖对齐方面具有相当的性能。(ii)自注意力蒸馏通过将级联层输入减半来突出注意力,并有效地处理极长的输入序列。(iii)生成式解码器虽然概念简单,但对长时间序列的预测进行一次正向操作,而不是step-by-step地进行,大大提高了长序列预测的推理速度。在4个大规模数据集上的大量实验表明,Informer方法明显优于现有方法,为LSTF问题提供了一种新的解决方案。
三个主要问题:1.计算复杂度,2.内存,3.推理速度
主要贡献:
1.概率稀疏自注意力(ProbSparse self-attention),通过“筛选”Query 中的重要部分,减少相似度计算;
2.自注意力蒸馏(Self-attention distilling),通过卷积和最大池化减少维度和网络参数量;
3.生成式解码器(Generative style decoder),一次前向计算输出所有预测结果。
方法
依然是encoder-decoder架构
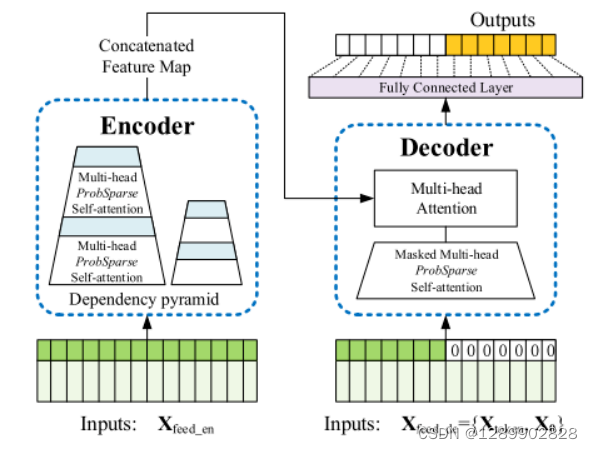
高效的自注意力机制
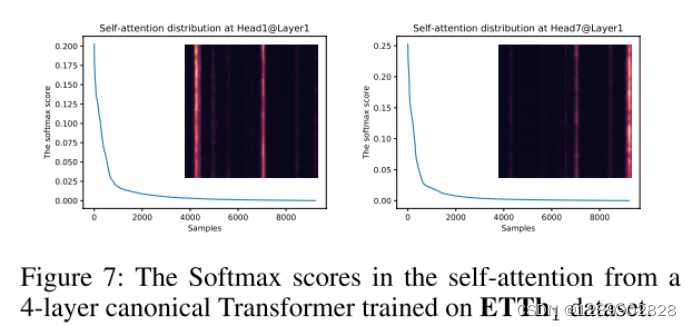
原来的自注意力机制存在稀疏性,较少的点积贡献了绝大部分的注意力得分。
第i个query的稀疏性评价公式
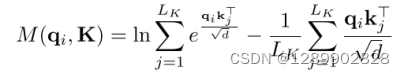
ProbSparse self-attetion的公式

蒸馏操作
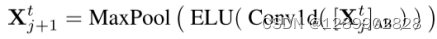
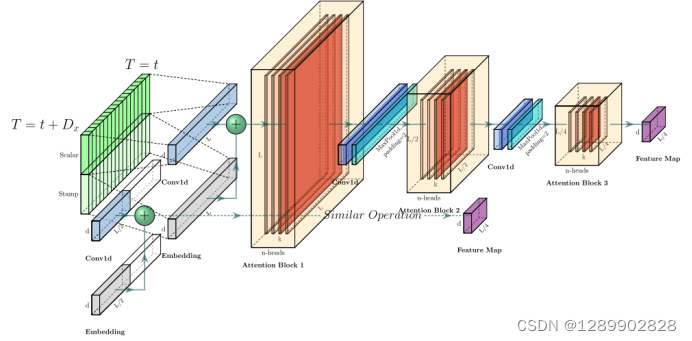
解码器
一次前向计算,预测长序列输出
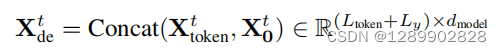
实验结果
单变量长序列预测和多变量的长序列预测,都不错。

参数敏感度
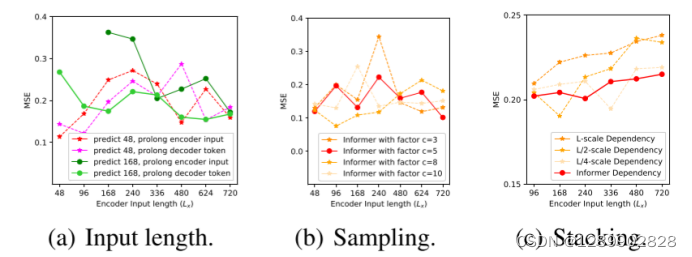
消融实验
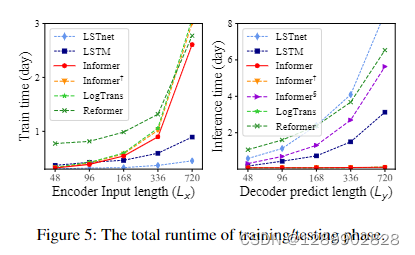
可以看出训练时间上没有什么优势,推理很快。














 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









