










最近因为在做图像分类考虑到一些样本不平均的问题
所以有机会尝试了一下FocalLoss这个损失函数(由Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár提出)
也重新的理解了一次这个损失函数是如何运作
首先我们要知道FocalLoss诞生的原由,要解决什么样的问题?
解决问题
针对one-stage的目标检测框架(例如SSD, YOLO)中正(前景)负(背景)样本极度不平均,负样本loss值主导整个梯度下降, 正样本占比小, 导致模型只专注学习负样本上
在仔细了解FocalLoss之前
我们还是有必要简单回顾一下CE 的过程
二分类 CrossEntropy
L = − y l o g ( p ) + ( 1 − y ) l o g ( 1 − p ) L = -ylog(p) + (1-y)log(1-p) L=−ylog(p)+(1−y)log(1−p)
也能够如下形式表达
L
=
{
−
l
o
g
(
p
)
i
f
y
=
1
−
l
o
g
(
1
−
p
)
,
o
t
h
e
r
w
i
s
e
L =\begin{cases} -log(p) \quad if\quad y =1\\ -log(1-p), \quad otherwise \end{cases}
L={−log(p)ify=1−log(1−p),otherwise
y经过sigmoid输出,值在[0, 1]之间
当概率p值越大, 算出的loss值肯定越小
多分类 CrossEntropy
C E ( P t ) = − l o g ( p t ) CE(P_t) = -log(pt) CE(Pt)=−log(pt)
經過softmax運算求得概率prob,
p
t
=
e
x
[
c
l
a
s
s
]
∑
j
e
x
[
j
]
pt = \frac{e^{x[class]}}{\sum_j e^{x[j]}}
pt=∑jex[j]ex[class]
其实CE的公式简单明了, 但是当遇到样本极度不平均的情况下加总所有的loss值时, 正样本的loss值占比会非常小, 什么意思呢? 我们留到最后的例子说明
把今天的主角请出来!
Focal Loss
- F L ( P t ) = − α ( 1 − p t ) r l o g ( p t ) FL(P_t) = -\alpha(1-p_t)^rlog(pt) FL(Pt)=−α(1−pt)rlog(pt)
α t = { α , i f y = 1 1 − α , o t h e r w i s e \alpha_t =\begin{cases} \alpha , \quad if\quad y =1\\ 1 - \alpha, \quad otherwise \end{cases} αt={α,ify=11−α,otherwise
从公式可以看出
基于原来的CrossEntropy, 多了一组 α ( 1 − p t ) γ \alpha(1-p_t)^\gamma α(1−pt)γ, 同时多了两个超参数 a l p h a alpha alpha, γ \gamma γ
在不考虑 α \alpha α 和 γ \gamma γ时, ( 1 − p t ) (1-p_t) (1−pt), 所以当 p t p_t pt越大时,赋予的权重就越小, p t p_t pt越小,赋予的权重就越大
Gamma γ \gamma γ
如果只把gamma考虑进来 ( 1 − p t ) γ l o g ( p t ) (1-p_t)^\gamma log(p_t) (1−pt)γlog(pt), 来简单的比较一下和CE的差别
- 假设gamma = 2
- 负样本prob = 0.95 带入公式
( 1 − 0.95 ) 2 l o g ( 0.95 ) (1-0.95)^2 log(0.95) (1−0.95)2log(0.95) = − [ 0.0 5 2 ( − 0.02227639 ) ] = 0.00005569 -[0.05^2 (-0.02227639)] = 0.00005569 −[0.052(−0.02227639)]=0.00005569
如果是原始的CE
−
l
o
g
(
0.95
)
=
0.02227639
- log(0.95)= 0.02227639
−log(0.95)=0.02227639
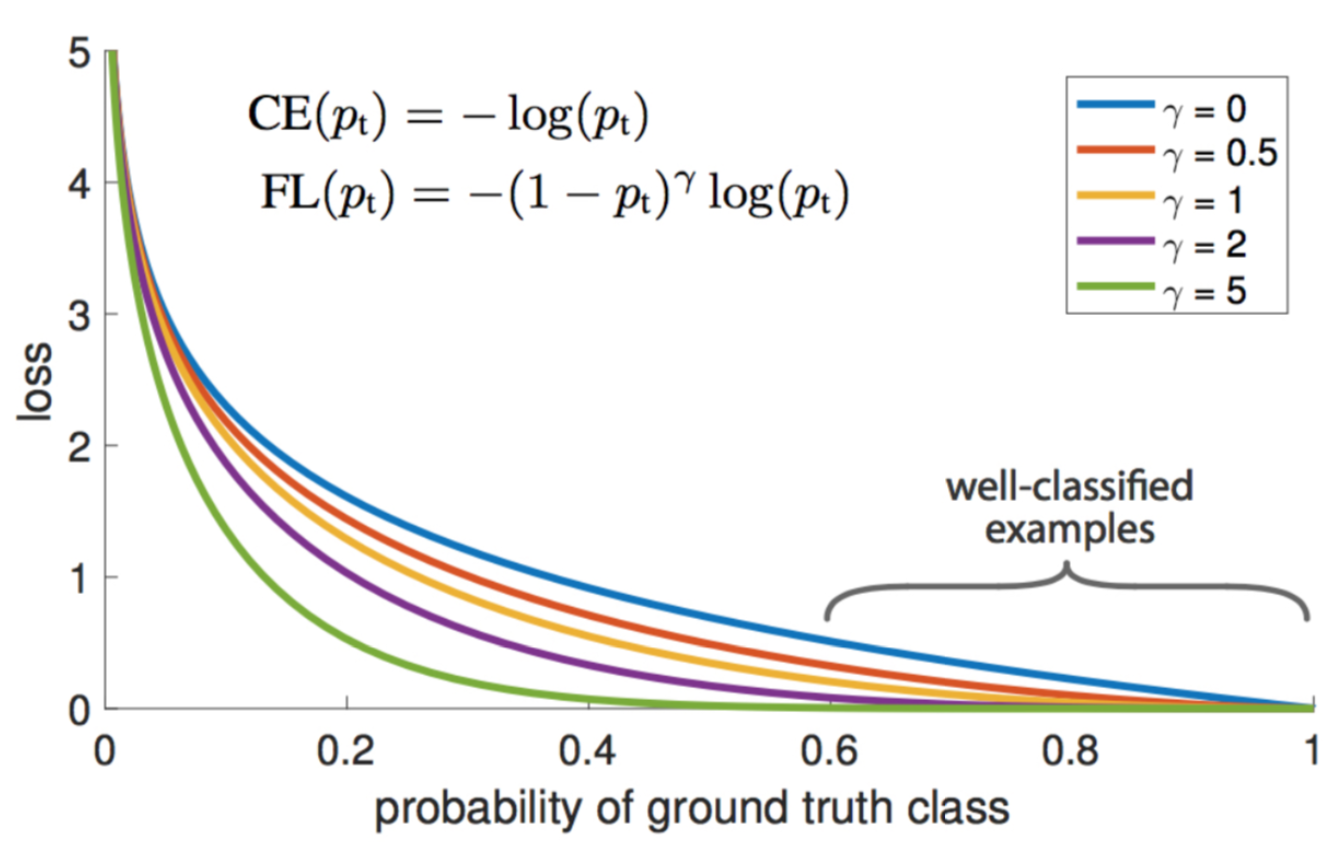
gamma能够有效降低负样本(简单样本)的Loss值, 简单样本的概率越大效果越强
如下图能理解gamma在越大, 概率越大的简单样本的loss可以降的越低
作者建议
γ
\gamma
γ 为2最佳
Alpha α \alpha α
那么接下来说说 发哥
α
\alpha
α, 主要用来调和正负样本权重比的
直接带入以下例子
栗子time
为了能够比较出差异, 直接用极端的例子, 其实也就是one-stage 目标检测的情况
假设我们模型
-
负样本10000笔资料probability(pt) = 0.95(简单样本), 这边可以理解为easy-example
-
正样本10笔资料, probability(pt) = 0.05(困难样本),
直接带入CrossEntropy和FocalLoss进行比较
- 带入CrossEntropy - C E ( P t ) = − l o g ( p t ) CE(P_t) = -log(pt) CE(Pt)=−log(pt)
- 负样本 : log(p_t) * 样本数(100000) = 0.02227 * 100000 = 2227
- 正样本 : log(p_t) * 样本数(10) = 1.30102 * 10 = 13.0102
total loss = 2227+13.0102 = 2240
正样本占比:13.0102 / 2240 = 0.0058
- 带入FocalLoss
假设alpha = 0.25, gamma=2
- 负样本 : 0.75*(1-0.95)^2 * 0.02227 *样本数(100000) = 0.00004176 * 100000 = 4.1756
- 正样本 : 0.25* (1-0.05)^2 * 1.30102 *样本数(10)= 0.29354264 * 10 = 2.935
total loss = 4.175 + 2.935 = 7.110
正样本占比:2.935/7.110 = 0.4127(与0.0058差距甚大)
经过比较, 我们算出CE正样本的值占总loss比例是0.0058, 而负样本是0.4127
差距甚大, 可以看出FL能有效提升正样本的loss占比
上面的例子中alpha取值为0.25, gamma=2, 这是作者建议的最佳值
alpha 的0.25代表的是正样本, 所以负样本就会是1-0.25 = 0.75
这里也许有些奇怪, 就理论上来看,alpha值设定为0.75(因为正样本通常数量小)是比较合理, 但是毕竟还有gamma值在, 已经将负样本损失值降低许多,可理解为alpha和gamma相互牵制,alpha也不让正样本占比过大,因此最终设定为0.25, 如果有更好的理解欢迎留言一起讨论
PS. gamma = 2, alpha = 0.25是经过作者不断尝试出的一般最佳值
最后我们记得 gamma及 alpha 两兄弟的作用
- γ \gamma γ 负责降低简单样本的损失值, 以解决加总后负样本loss值很大
- α \alpha α 调和正负样本的不平均,如果设置0.25, 那么就表示负样本为0.75, 对应公式 1 − α 1 - \alpha 1−α
老样子,还是习惯写文章搭配代码解释比较清楚
用的是Chao CHEN (chaochancs@gmail.com)写的FocalLoss pytorch版本
论文连接 https://arxiv.org/abs/1708.02002
源码连接 https://github.com/marvis/pytorch-yolo2/blob/master/FocalLoss.py
上面的源码注解 https://github.com/Stephenfang51/Focal_loss_turtorial

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









