






首先贴出来复现的该文章描述的DCNN Python代码,供读者参考学习。
import torch.nn as nn
class UWB_CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=7, stride=1, padding=0)
nn.BatchNorm2d(32, momentum=0.5),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=0)
nn.BatchNorm2d(64, momentum=0.5),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=9, stride=1, padding=0)
nn.BatchNorm2d(128, momentum=0.5),
nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.Conv2d(128, 8, kernel_size=9, stride=1, padding=0)
nn.BatchNorm2d(8, momentum=0.5),
nn.ReLU(),
nn.Flatten()
)
self.lin1 = nn.Sequential(
nn.Linear(in_features = 8*64*163, out_features=384, bias=True),
nn.BatchNorm1d(384, momentum=0.3),
nn.ReLU()
)
self.lin2 = nn.Sequential(
nn.Linear(in_features = 384, out_features=256, bias=True),
nn.BatchNorm1d(256, momentum=0.3),
nn.ReLU()
)
self.prediction = nn.Linear(in_features = 256, out_features=12, bias=True)
def forward(self, x):
x = self.conv1(x.float())
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.lin1(x)
x = self.lin2(x)
x = self.prediction(x)
return x在过去的几十年里,深度学习算法在信号检测和分类中变得越来越普遍。然而,要设计机器学习算法,就需要一个足够的数据集。由于几个开源的基于相机的手势数据集的存在,这个描述符呈现了UWB-Gesture,即用超宽带(UWB)脉冲雷达获得的12个动态手势的最早的公共数据集。该数据集包含了从8名不同的人类志愿者中收集的总共9600个样本。UWB-Gesture消除了使用UWB雷达硬件来训练和测试算法的需要。此外,该数据集可以为研究界提供一个竞争环境,以比较不同手势识别 (HGR) 算法的准确性,从而能够通过 UWB 雷达在 HGR 领域提供可重复的研究结果。三个雷达被放置在三个不同的位置来获取数据,并且为了灵活性,各自的数据被独立保存。
Background & Summary
手势识别 (HGR) 提供了一种方便而自然的人机交互方法。可以使用手势构建人机交互的用户友好界面。在 HGR 中,首先使用合适的传感器获取手势数据,然后识别所获取的传感信号中的模式以识别不同的手部运动。存在多种用于数据采集的传感器,包括可穿戴设备1、摄像头2和雷达传感器。最近,雷达被认为是 HGR 的关键支持技术,因为它比其他传感器具有许多优势;例如,与基于摄像头的传感器相比,雷达不易受到雷电的影响。此外,基于雷达的 HGR 系统不需要可穿戴设备。目前,多种商用设备(如 Google Pixel 4 智能手机)都配备了用于 HGR 的内置雷达。
深度学习算法在手势识别和分类方面表现出巨大潜力。最近的研究表明,基于超宽带 (UWB) 雷达的手势分类具有很高的分类精度,其中使用深度学习方法对几种滑动和圆形手势进行分类。同样,谷歌的研究人员设计并制造了一款名为 Soli 的微型雷达,专门用于手势识别和感应,使用由低维特征驱动的随机森林分类器。最近,Wang 等人。使用相同的 Soli 雷达传感器,使用基于卷积神经网络 (CNN) 的分类器对 11种不同的手势进行分类。另一项研究使用用于车辆和信息娱乐界面的雷达传感器识别了六种不同的手势,并将分类输出(类)输入到 Android 系统以根据手势执行所需的操作。此外,还建立了一个名为“雷达输入与交互分类”(RadarCat)的系统,以提供一组应用程序,包括基于手势识别的随机森林分类器。最近,Park 等人 专注于提供雷达硬件和手势识别算法;使用长短期记忆 (LSTM) 对六种不同的手势进行分类。上述研究表明,基于机器学习的解决方案将使雷达传感器对 HGR 产生相当大的积极影响。然而,机器学习算法基于学习范式,因此需要一些开销,例如足够的计算能力和足够大的数据集来训练算法。如果没有足够的硬件组装和采集环境,通常无法开发和测试深度学习框架。因此,要在不购买硬件的情况下构建 HGR 算法,需要通过雷达传感器获取的手势公共数据集。
有几种用于训练深度学习算法的(信号和图像)数据集可供公众下载。例如,ImageNet和 LabelMe提供了大量用于视觉对象识别的图像集合。这些数据集消除了获取图像来测试不同机器学习算法的需要,同时提供了一个竞争平台来比较不同算法在类似环境中的性能。最近,发布了一小部分针对 COVID-19的政府响应事件,195 个国家的政府发布了 13,000 多项政策公告;该公共数据集可用于训练 CNN 以检测 COVID-19。同样,PhysioBank提供了超过 75 个数据集的集合,其中包含来自患者和健康个体的不同生物医学信号样本,例如心肺和神经信号。然而,基于视觉的手势数据集很少;其中包括剑桥手势数据库(2009 年发布),其中包含九个不同手势类别的九百个图像序列、MSRGesture3D(2012 年发布)1和 EgoGesture(2018 年发布)。
此外,RGBD-HuDaAct数据集提供了使用摄像机和深度传感器获取的人类活动识别数据集。Pisharady 和 Serbeck报告了对所有可用的基于视觉的手势数据集的全面审查,最近发布了一个连续波雷达数据集,其中包含六个不同人类受试者在 223 分钟内记录的生命体征和心跳。然而,没有这样的公共雷达手势数据集。对于所有关于使用雷达和其他无线电传感器的 HGR 的研究,研究人员首先收集训练数据,然后测试他们的算法。
在本文中,我们介绍了有史以来第一个使用超宽带 (UWB) 脉冲雷达收集的手势数据集。我们预计,该数据集可以消除获取算法测试数据的需要,并为研究界提供一个竞争环境,以比较现有和新提出的算法的准确性。图 1 显示了本研究的总体摘要和范围。部署了三个以单站配置独立运行的不同雷达传感器,每个雷达传感器的数据分别保存在存储库中。因此,可以使用单个雷达传感器或同时利用来自多个雷达传感器的信号来评估 HGR 算法。如图 1 所示,后面的部分还将演示基于 CNN 的分类器的应用示例。
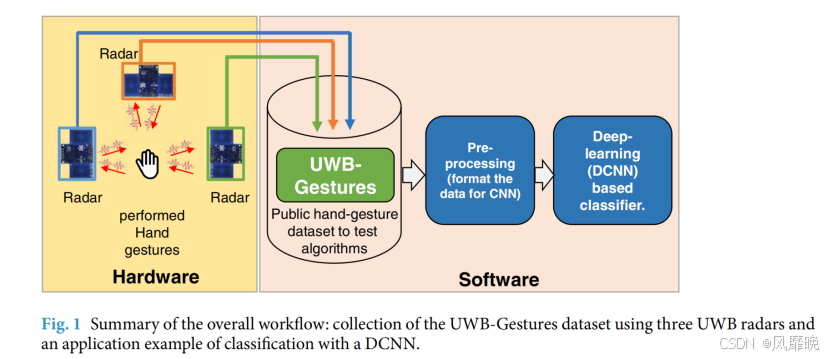
Methods
基于文献调查的手势选择。首先,我们进行了简短的文献综述以选择手势,因为目前还没有选择雷达传感器收集的手势来测试 HGR 算法的标准。研究人员总是随机选择一组手势来评估他们的算法。然而,研究表明,手势的性质通常是相同的,即滑动、滑动、推动和循环旋转等动作。例如,Kim 和 Tomajian使用 10 种类似性质的手势通过多普勒雷达执行 HGR。Khan 等人。使用 UWB 雷达对从三个不同的人类志愿者那里获得的五种手势进行分类,包括手滑动和指向手势。同样,Ryu 等人构建了一个基于特征的手势识别算法,并在 7 种手势上进行了测试,包括向左、向右、向上、向下、顺时针和逆时针移动手以及推手。最近对基于雷达传感器的 HGR20 的研究使用了类似性质的手势来测试其算法。尽管手势的性质相似,但每项研究中的数据采集环境和雷达类型都不同。因此,每种新算法的性能评估都会根据记录的数据集而变化。此外,在所有上述研究中,用于训练和评估算法的数据集都由少量样本组成。例如,Fhager 等人使用的数据集。26 每个手势仅包含 180 个样本。Ryu 等人。22 出于训练目的,仅执行了 7 个手势中的每一个 15 次。少量的训练样本和人类参与者可能会导致机器学习算法出现偏差,并导致仅给出已知数据样本的过度拟合;因此,该算法可能对未知的测试数据样本不够稳健。为了应对上述挑战,所提出的数据集具有以下特点:
- UWB-Gestures 包含大多数(如果不是全部)以前在基于雷达的 HGR 研究中使用的手势,因为没有获取手势的程序标准。
- 使用多个志愿者来获取数据以提供更大的手势内变化。
- 使用多个(三个)雷达传感器进行数据采集,并且可以单独访问每个雷达传感器的数据,以便在硬件放置和雷达传感器数量偏好方面提供灵活性。多个雷达传感器还允许手部跟踪和轨迹预测。
在本文中,我们展示了有史以来第一个包含十二种不同动态手势的公开数据集(称为 UWB-Gestures),如图 2(a–l) 所示,其中的手势是通过 UWB 脉冲雷达获取的。每个手势的视频形式可在 (http://casp.hanyang.ac.kr/uwbgestures) 上找到。我们选择了八个滑动手势,如图 1(a–h) 所示:从左到右 (LR) 滑动、从右到左 (RL) 滑动、从上到下 (UD) 滑动、从下到上 (DU) 滑动、对角线-LR-UD 滑动、对角线-LR-DU 滑动、对角线-RL-UD 滑动和对角线-RL-DU 滑动。此外,图 2(i–k)显示了顺时针旋转(CW)、逆时针(CCW)旋转和向内推的手势。为每个用户添加了一个空手势,以允许手势和非手势分类。图 2 中显示的手代表每个手势的起点。如前所述,这些手势是根据其他研究人员的偏好精心挑选的。
参与者。数据来自 8 位不同的参与者,以介绍更多手势内变化。表 1 列出了每个参与者的详细信息,可用于分析不同手型的手势内和手势间变化。参与者的平均年龄为 25.75 岁,平均体重指数 (BMI) 为 22.19±5 kg/m2。虽然参与数据采集过程的大多数人类参与者都从事研究职业,但他们在数据采集之前都接受了基础培训。
数据采集硬件。对于数据采集,我们选择了 Novelda的 XeTru X4 UWB 脉冲雷达传感器,因为它体积小,广泛应用于不同的基于雷达传感器的应用中,例如手势识别生命体征监测 和汽车。表 2 列出了雷达传感器的详细技术规格。
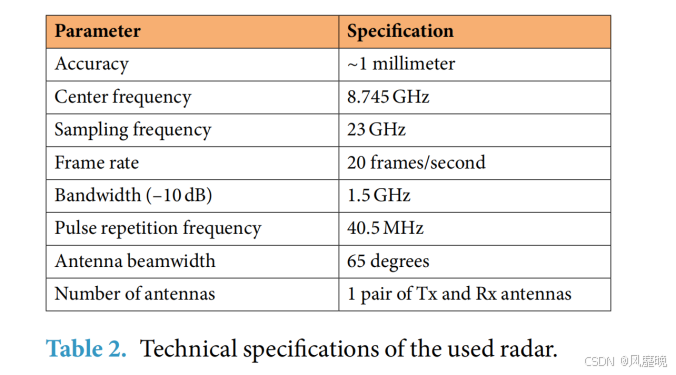
如表 2 所示,Novelda 雷达传感器是一种 UWB 脉冲雷达传感器,带宽为 2GHz,中心频率为 8.745GHz。连接图如图 3(a)所示,该图表明 Novelda 雷达传感器由一对发射机 (Tx) 和接收机 (Rx) 天线以及一个 DSP 微控制器组成,该微控制器进一步连接到主机,其中使用 MATLAB 来收集和保存数据。完整雷达芯片的正面和背面如图 3(b)所示。

该数据集由韩国首尔汉阳大学收集。与传统的窄带雷达传感器不同,UWB 雷达在很短的时间内发射具有宽频谱的信号。对于每个发射的脉冲状信号序列,相应的接收信号 x[n] 由来自 N 个不同路径的反射信号和加性噪声项组成。因此,接收到的 UWB 信号是这 N 个延迟和失真信号的线性组合,可以表示为:
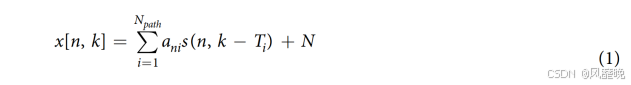
其中 s[n] 表示接收器接收到的发射脉冲形状的估计值,该估计值通常会因多种不同因素而失真,例如物体的反射、折射和散射系数,N 表示加性噪声。此外,ani 和 Ti 分别表示信号的缩放因子和持续时间。等式 (1) 中的项 N 和 K 分别表示 2D 接收雷达信号矩阵的行和列,分别称为快时间和慢时间。这里,雷达信号矩阵的快速时间(行)表示手与雷达的距离,而慢速时间(列)表示雷达发射的帧(手势的持续时间)。等式 (1) 中表示的信号包含来自目标(手)的反射和来自雷达传感器操作区域内的静态物体(例如人体)的不需要的反射。这些不需要的反射通常被称为杂波。包含单个手势动作接收到的手部反射的最终二维矩阵可以表示为:

本文记录了 4.5 秒的手势,相当于 90 行(慢速)。我们将雷达的探测范围调整为 1.2 米,得到 189 个快速样本。
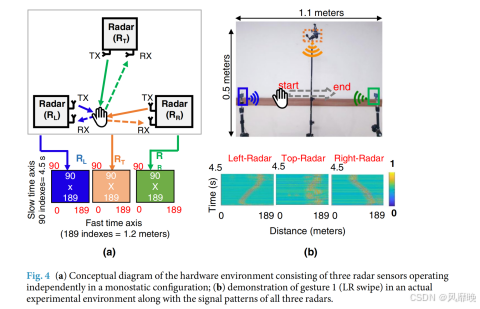
数据采集装置。概念性采集装置如图 4(a)所示,包括 3 个雷达,分别为 RL、RT 和 RR(分别放置在实验装置的左侧、顶部和右侧)。这三个雷达均在单站配置中独立运行,每个雷达独立进行信号传输和接收。手势是在三个雷达的中间执行的。左侧和右侧雷达之间的距离为 1.1 米,水平雷达中点与顶部雷达之间的距离为 0.55 米。图 4(b)说明了实际实验装置以及手势 1(左右滑动)针对所有三个雷达的数据矩阵。如图 4(b)所示,当手从左向右移动时,可以看到左侧雷达(RL)的目标信号远离它。相反,可以看到目标信号向 RR 移动。对于所用雷达的情况,1米的距离包含156个快速时间。每个样本由90个慢速时间帧组成,相当于4.5秒的持续时间。
Data Records
UWB-Gestures 数据集可在 Figshare31 (https://doi.org/10.6084/m9.fgshare.12652592) 下载。数据放在两个单独的文件夹中以符合文件大小限制。由于数据是使用 MATLAB 收集的,因此存储的文件是 MAT 文件。此外,为了确保数据集的免许可证分发,我们将数据集转换为逗号分隔值 (CSV) 文件。为清楚起见,每个手势的模态视频都可以在我们的主页上找到。数据描述符的结构如图 5 所示。数据集包含八个目录,对应于表 1 中列出的每个个体参与者。每个文件夹还包含两个目录,其中包含原始数据和去杂波数据。原始数据包含原始形式的记录手势,而去杂波数据由原始数据的预处理版本组成。在预处理过程中,使用环回滤波器根据以下原理估计杂波:
![]()
其中 c 表示杂波项,它是使用先前估计的杂波和当前接收的雷达信号 x[n] 提取的,而 alpha (α) 项表示控制滤波器学习率的加权因子。具体来说,对于我们的数据集,alpha 被选为 0.9。然后从接收的雷达信号 x 中减去估计的杂波 c 以获得无杂波输出 y。
![]()
作为演示如何访问文件夹中子文件的示例,访问包含人类志愿者 2 执行的手势 4(DU 滑动)的所有杂波消除样本的文件的链接如下所示:
~\UWB-Gestures\HV_02\ClutterRemovedData_HV02\HV_02_G4_ClutterRemoved.mat
此处,HV_02 指人类志愿者 2,G4 指手势 4。包含与三个不同雷达系统相对应的单独变量的最终 MAT 文件表示如下:
• Lef Radar: HV2_G4_RadarLef_ClutterRemoved_100samples.
• Top Radar: HV2_G4_RadarTop_ClutterRemoved_100samples.
• Right Radar: HV2_G4_RadarRight_ClutterRemoved_100samples.
请注意,表示每个雷达值的所有变量都保存为单独的 CSV 文件,因此 CSV 文件的数量是 MAT 文件的三倍。每个手势的所有样本都放在一个 2D 文件中,水平轴表示快速时间,垂直轴表示慢速时间。如上所述,每组 90 个慢速时间值构成 1 个手势样本。还包括一个用于访问和查看手势样本的 MATLAB 脚本,并在后面的部分中详细讨论。
Technical Validation
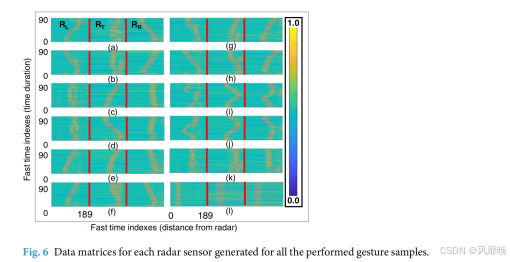
信号模式分析。图 6 显示了所有剩余手势的信号模式。如图 6 所示,每个手势运动都对应一个独特的模式。作为一个实际示例,对于 LR 滑动和 RL 滑动情况,右侧和左侧雷达传感器显示相反的模式,而雷达 3 显示一条垂直直线。另一方面,对于 UD 滑动和 DU 滑动情况,左侧和右侧雷达显示垂直直线模式,而雷达 3 显示变化的模式。每个手势都可以观察到类似的变化。类似地,图 6(i)和(j)分别显示了对应于顺时针和逆时针旋转手势的雷达图像。
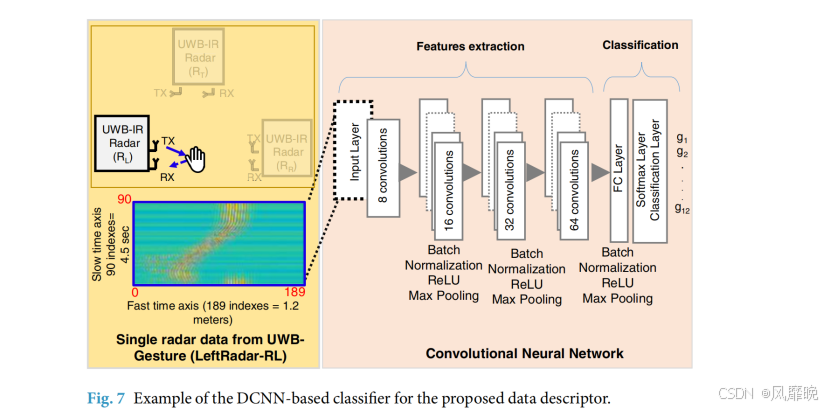
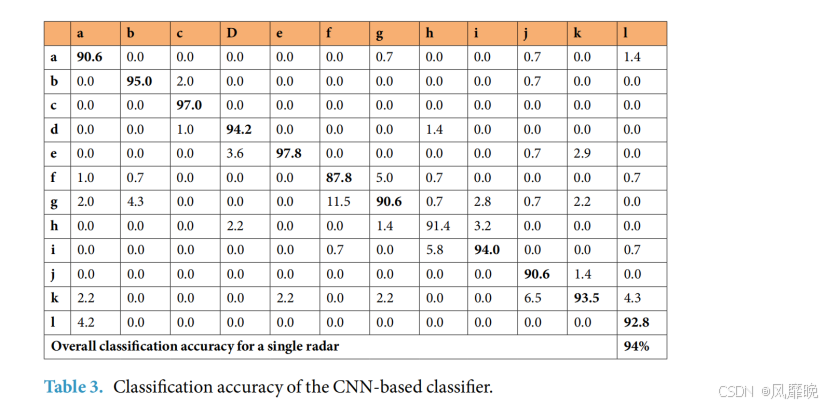
基于 CNN 的分类器示例。为了提供应用所提数据集的示例,我们实现了一个具有四个隐藏层的新型 DCNN 分类器,如图 7 所示。雷达数据矩阵被转换成图像,这些图像作为输入输入到 DCNN 架构中。我们仅使用单个雷达传感器(左雷达)进行分类。因此,DCNN 的输入层的大小为 90×189(单个雷达数据矩阵的快速时间×慢速时间)。我们对四个隐藏层中的每一个都采用 3×3 卷积滤波器。学习率设置为 0.01,并使用 30 个时期进行训练。表 3 展示了图 7 中所示的 4 层 DCNN 算法的分类准确率,输入仅来自左雷达传感器(RL)。每行的第一列代表原始类别,而第一行代表预测的手势类别。对角线值表示总体成功率,其他地方的值表示分类误差。在表 3 中,为清晰起见,表示成功率的对角线项以粗体标记。基于 4 层 DCNN 架构的分类器对单个雷达传感器的准确率为 94%。

















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









