







前言
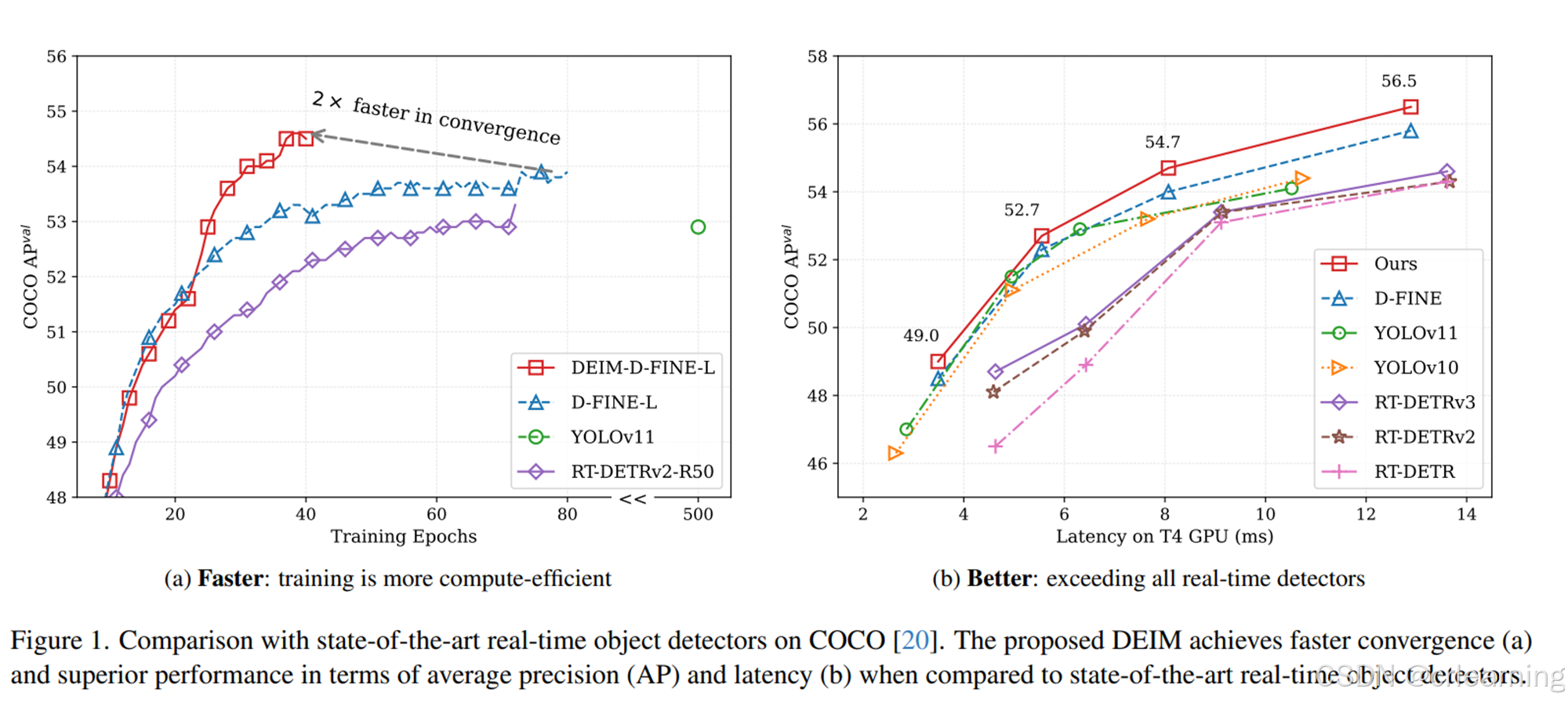
超越D-FINE和RT-DETRv3的最新模型DEIM,基于RT-DETR和D-FINE基线代码进行创新,提出了两个创新点。从论文中的效果图中可观察到,模型收敛速度更快并且效果更好。(代码也简单,可用于DETR系列实验提点)
论文地址:https://arxiv.org/pdf/2412.04234
代码地址:https://github.com/ShihuaHuang95/DEIM
本文主要分析该文章提出的创新点,及其为什么work。
主要创新点
论文主要提出两个点 Dense O2O 密集一对一匹配和MAL (Matchability Aware Loss)匹配感知损失
1、Dense O2O 密集一对一匹配
为什么需要它:
DETR系列的一个主要限制是收敛速度较慢,部分原因在于其采用的一对一(O2O)匹配策略,每个目标仅对应一个正样本,导致监督信号稀疏,影响模型的有效学习。
为解决监督稀缺问题,O2M训练为每个目标引入辅助正样本以增加监督,放宽了O2O匹配的约束。Group DETR通过使用多个具有独立O2O匹配的查询组来实现这一点,但它们也需要额外的解码器,从而增加了计算开销,并存在生成与传统检测器类似的冗余高质量预测的风险。
所以是否存在一种效果和O2M方式相接近的O2O方式呢?
刨析问题:如何有效增加正样本数量,从而提供更密集的监督信息?
what:
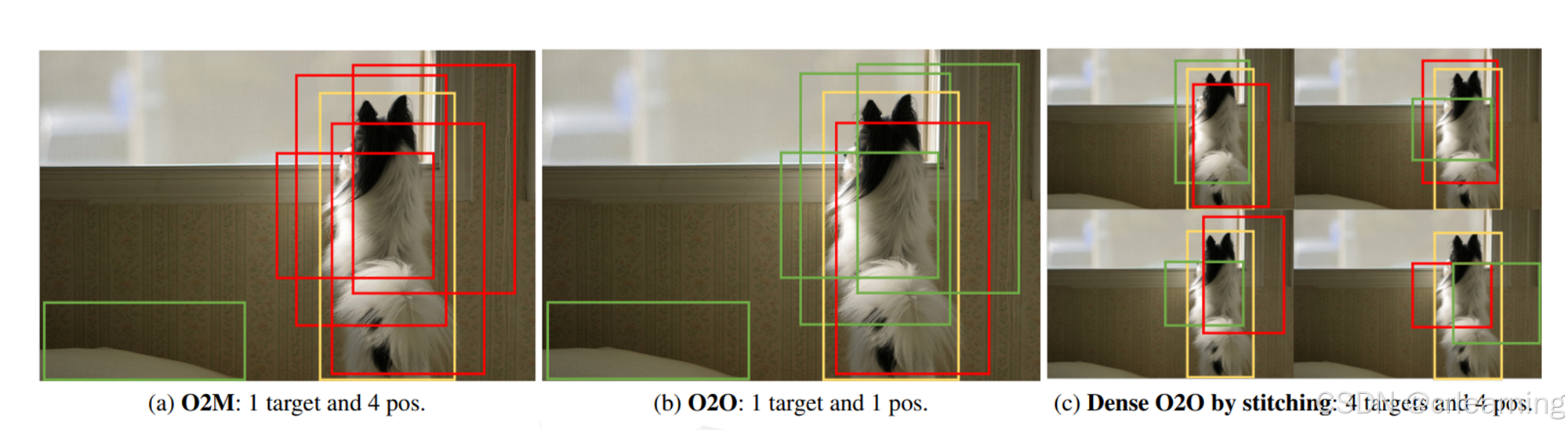
上图呈现的是三种匹配方式,作者通过Mosaic 数据增强,将单目标图片拼接成多目标图片,增加匹配数量,实现同一个“目标”多个query匹配,但其本质还是一对一,只是将图片实例复制拼接;
why work:
以下个人理解:
1、为什么不直接用copypaste:直接复制GT可能会导致模型过拟合于特定目标,降低泛化能力。而复制整张图片可以保留目标的上下文和背景信息,也不会破环原图的结构。
2、为什么不直接用O2M,而用Dense O2O?
- 避免低质量匹配: O2M直接将多个预测框与一个GT匹配,容易引入误匹配。而Dense O2O避免了这个问题,因为每个GT始终只与一个高质量预测框匹配,确保匹配质量稳定。
- 稳定训练: O2O匹配在目标检测中更稳定,梯度更新更平滑。而O2M虽然速度快,但训练波动较大,容易导致模型不收敛或性能不稳定。
how效果如何:
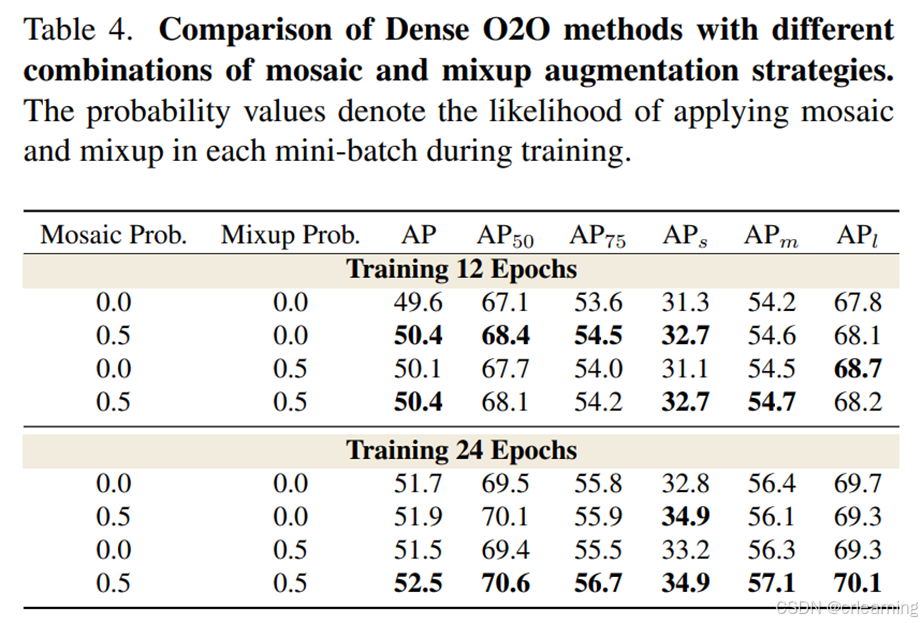
作者在coco数据集上进行实验,结果如下:呈正向
2、MAL匹配感知损失
MAL是对VFL的优化,针对IOU低置信度高的badcase进行优化。它的工作原理较为简单:
what:
目前RT-DETR中采用的也是VFL,那么先看看VFL是什么,以及它的缺点:
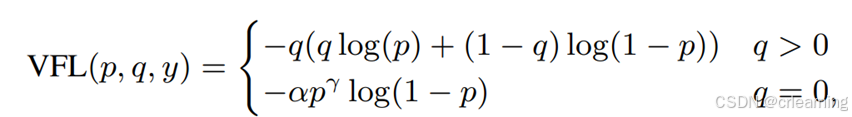
其中q代表IoU,p为预测的置信度,从而导致q过小时,VFL整体则偏小。所以对于 IoU 较低的匹配,损失不会随着置信度增加而增加。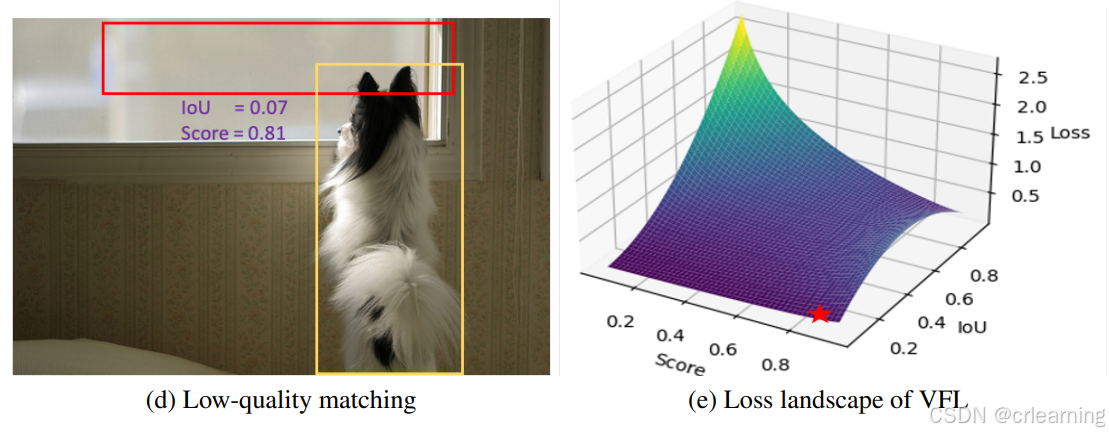
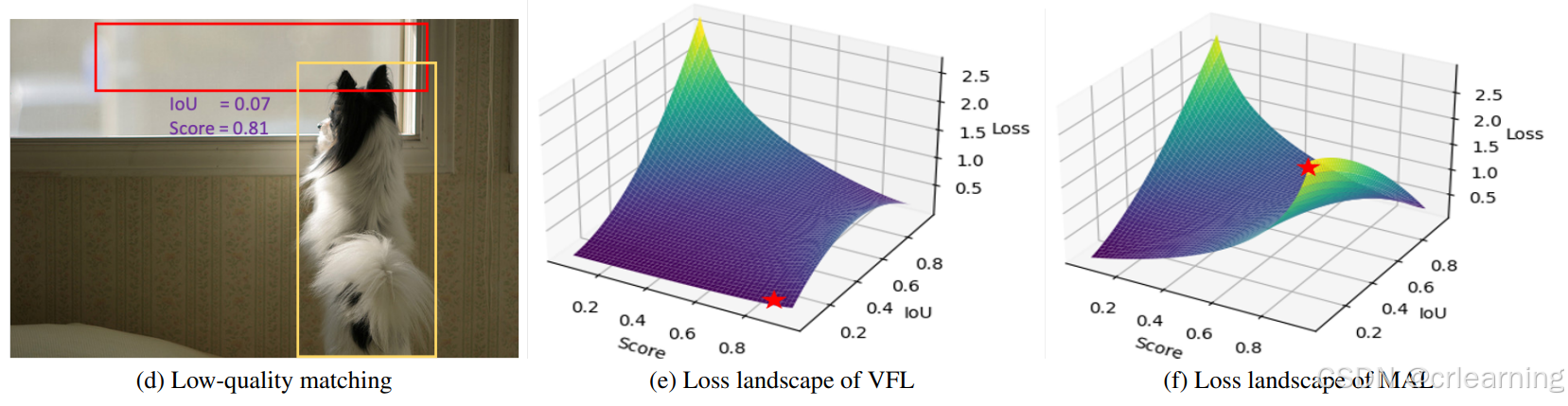
通过可视化来说,红色框为IOU小但置信度却很高的badcase,我们希望模型给它一个较高的损失,但是从右图中的VFL来看,红星代表框的损失位置,明显不符合预期。
为了解决这个问题,文中给出了MAL:对比VFL就是将系数q去除
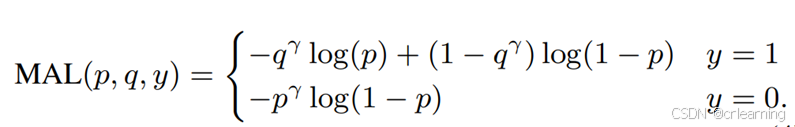
从函数曲线可以看出,在IOU低置信度高时,损失升高,其他部分不变。
代码层面也比较简单:
# VFL中的权重
weight = self.alpha * pred_score.pow(self.gamma) * (1 - target) + target_score
# MAL中的权重
weight = self.mal_alpha * pred_score.pow(self.gamma) * (1 - target) + target
### MAL中当target为1时,weight=1;而VFL中weight=target_score(也就是IOU)how:
MAL和VFL在不同case上的loss曲线:
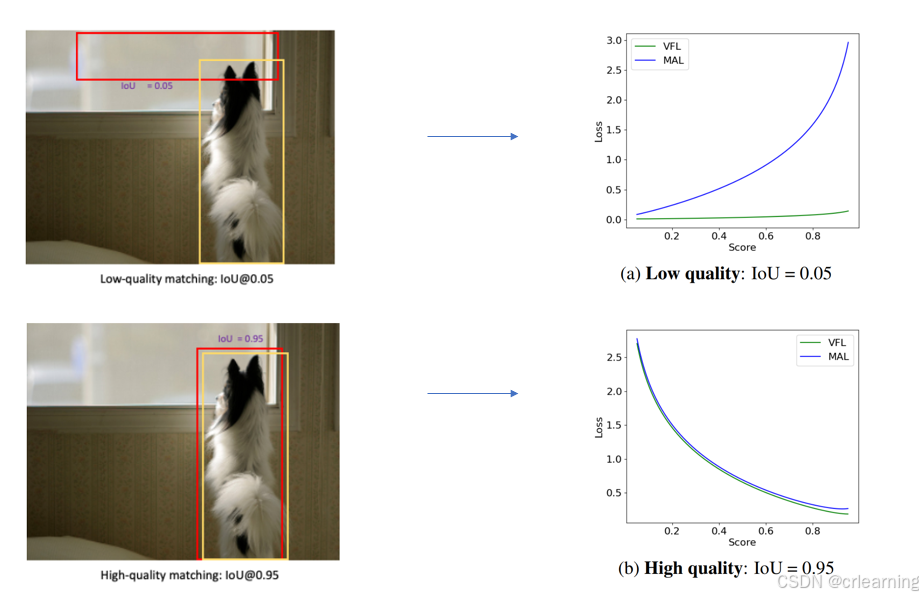
3、消融实验结果:
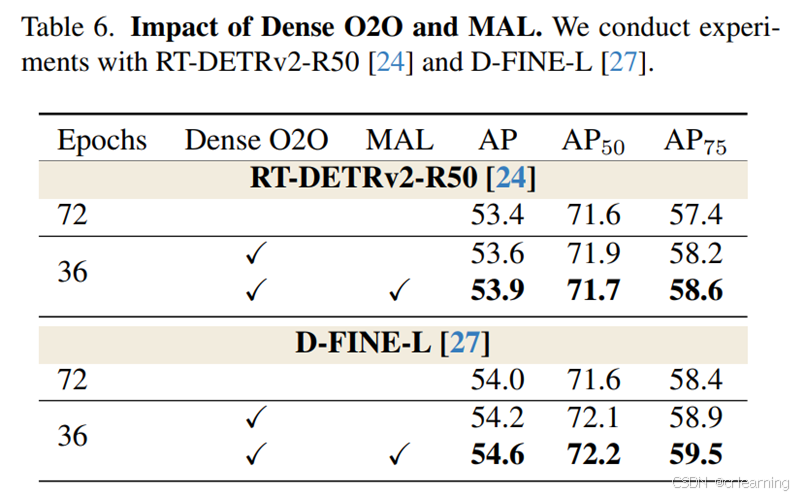
总结
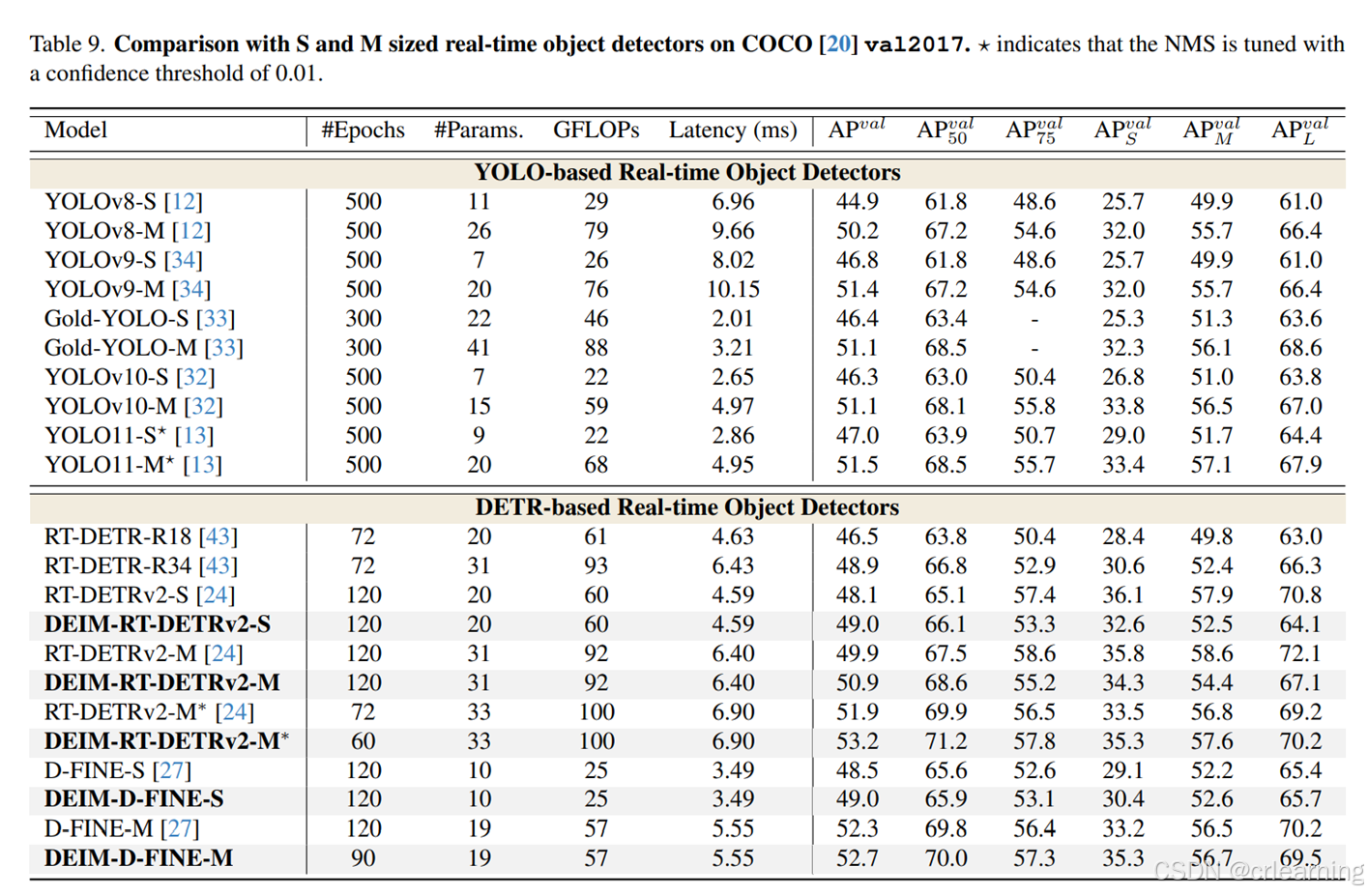
DEIM这篇文章给出了两个即插即用模块,能够帮助做DETR实验的炼丹师们提点。最后是对比其他SOTA模型的实验效果:


















 2114
2114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











