





摘要
本文提出一种新颖的视角,利用现有的KGE模型的强大功能,将精力集中在怎样插入时间数据上。
还发现了目前用于评估静态模型在时间图上的性能的过程中存在的问题,并介绍了两种消除这些问题的方法。
介绍
提出与模型无关的SpliMe方法,使用事实的有效时间以三种不同的方式嵌入谓词,(1)时间戳(2)分割(3)合并。SpliMe的核心是一个转换函数,它将TKG映射为一个新的表示,其中在实体和/或谓词级别包含时间范围。
揭示了时间知识图上评估静态模型存在的问题。具体说,当前过程会导致test-leakage,即测试集中的元素出现在训练集中。本文提供了两个过程来修复这个错误。
预备知识
网络接近度度量一对节点之间的接近或相似度。该任务可以使用两种信息源,图本身的结构或节点属性。KGs没有节点或谓词属性,所以使用的方法完全基于图结构。节点或实体s的节点邻域表示为Γ(s),是与s直接相邻的节点的集合。
三种网络接近度测量方法:
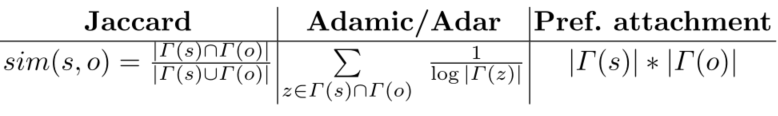
第一个度量是著名的Jaccard集相似性度量。
第二个度量的基础是公共特征(节点)的权重应该小于不常见特征。
第三个认为,一个节点获得一条新边的概率与它当前的边数成正比。
在本文中,使用随着时间推移的接近性分数作为图演化的度量。通过将实体之间的接近度得分作为时间序列数据,我们可以评估它们的语义何时发生显著变化。
CPD是在时间序列数据中寻找突变点的问题。CPD考虑一个时间序列S,即S = {x1, x2,…, xl},其中xi是一个数据向量,表示时间戳i(1 ≤ i ≤ l)的时间序列的值。本例中,为每一个谓词r创建一个时间序列Sr。对于给定的Sr,每个条目xi表示一个向量,其中包含节点之间的相似性分数,这些节点在某个时间戳i上通过标记为r的边连接。
SpliMe
SpliMe在实体和/或谓词级别上包含事实的时间范围。SpliMe的核心是一个转换函数f: T→T’,它接受一个TKG并返回一个新的TKG,其中在实体和/或谓词级别(部分)包含了时间范围。然后重复应用f,直到满足停止准则。初步研究表明,应用于谓词时效果最好。因此,本文将重点讨论关于谓词的结果。已经为f开发了几种不同的实现,分为时间戳、分割和合并方法。在接下来的部分中,我们将对每种方法进行深入的解释。此外,为每种方法提供了一种算法。由于篇幅限制,本文仅给出基于cpd的高效分割方法的算法。
时间戳: 将TKG中每个时间事实转换为一组事实,每个时间戳对应一个事实。
分割: 添加两个新谓词r1,r2与原来的谓词组成新的谓词集,对于五元组(s,p,o,b,e)若b,e不在时间t范围内,则更新r1,r2。否则,事实就分成了
{(s, r1, o, b, t), (s, r2, o, t, e)}。
在形式上,参数化分裂是通过函数 f: (T, cp, ct) →T’ 来完成的,它给出一个TKG T,分裂条件cp选择一个谓词,而条件ct选择一个时间戳,映射到一个新的TKG T’。这里的挑战在于如何定义有效的cp和ct。
对于cp,在我们的实验评估中产生良好性能的一般方法是选择出现次数最多的谓词,即:

对于ct,有两种检测方法:时间和计数
tf,tl表示谓词r中关联的第一个和最后一个时间戳。
时间方法拆分一个事实,在t=(tf,tl)/2时包含r。
count方法选择一个时间点,该时间点在分割的两边产生最平衡的三元组数目。这是通过计算在特定时间戳之前或之后有多少事实结束来完成的。在形式上,count函数可以写成:
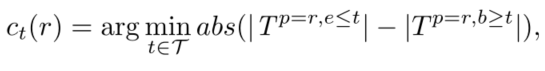
引入了基于CPD的高效分割,两步过程来确定如何放置分割点:
一:将网络邻近度测度应用于TKG计算每个谓词的特征向量,在每个时间戳上,创建一个时间序列Sr,每个条目表示图中由r连接的节点对之间的接近分数向量,条目的序列表示谓词是如何随时间演变的。
二:将这些向量输入CPD算法。分割点被放置在CPD算法识别变更点的时间戳上。
为克服信息的稀缺性,我们不考虑实体是主体还是客体,签名是通过将TKG切割成代表不同(谓词,时间戳)组合的子图来创建的。

函数fscore计算实体对在给定子图Sr,t上的接近分数。设pairsr表示谓词r的实体对集合,对每个谓词r,我们为每个时间戳计算pairsr中每对谓词的接近度得分,并将结果添加到签名向量中。
如何将CPD应用于签名向量。由于给定谓词的变更点的数量是未知的,因此必须使用复杂度惩罚或剩余值来确定分割/变更点的最佳数量。在实验评估中,我们采用了自底向上的分割算法,并结合残差E范围[1,100]取决于被转换的数据。一个高E残差在重建数据时留有更多的余地,需要更少的改变点。反之亦然,一个低值E意味着更多的改变点。为了确保发现的变化点不依赖于签名的大小,我们在将所有签名传递到CPD算法之前对它们进行了规格化。上图算法1。包含两个函数,一个用于计算给定谓词的签名向量,另一个用于使用这些签名计算分割点并应用他们。申请cpd和申请分割程序不包括在内。
分割过程:首先,创建一个字典或哈希集,对于每个时间戳(在第2行),它将跟踪给定谓词的所有拆分点。在第3行和第7行之间,循环遍历所有谓词,把KG(4)计算签名使用fscore(第5行)。在最后一行的循环执行CPD(第6行)。一旦所有的谓词已处理,我们将发现分割点TKG和谓词集(第8行)。一套新的TKG和谓词返回在第9行
签名创建过程:在第13行,我们循环遍历KG中的所有时间戳。在每个循环中,我们只选择在给定时间戳下有效的事实(第14行)。然后循环遍历所有这些事实,计算由其组成的实体的接近度得分(第16行),并将该得分添加到签名向量(第17行)。因为我们对节点接近度随时间的演化进行了建模,所以签名向量中每个条目的位置必须是一致的。因此,我们假设在签名中添加一个(s,o)对总是在同一个索引处。
合并: 分割方法可以看作是自顶向下的方法,提出一种自底向上的方法。在一个TKG四元组上,合并属于同一个原始谓词并在时间上是后续的谓词。定义两个函数,lp返回TKG中的谓词源,lt返回时间。
实验
数据集:Wikidata12k,YAGO11k,ICEWS14。
基线:1.Vanilla基线。这种方法从TKG中去除所有的时间范围,将其转换为静态KG。
2.Random基线,它以统一的方式在谓词和时间戳之间随机应用分割。
结果:

















 1831
1831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









