







 该专栏为热销专栏榜 第1名
该专栏为热销专栏榜 第1名
摘要
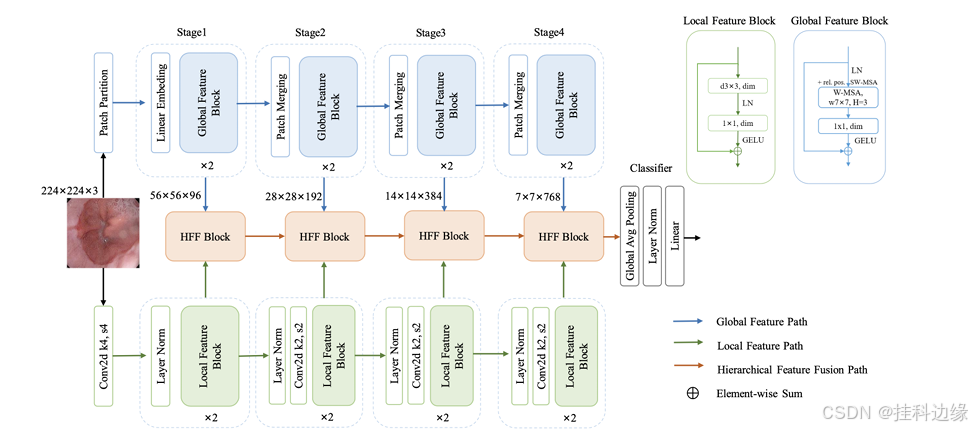
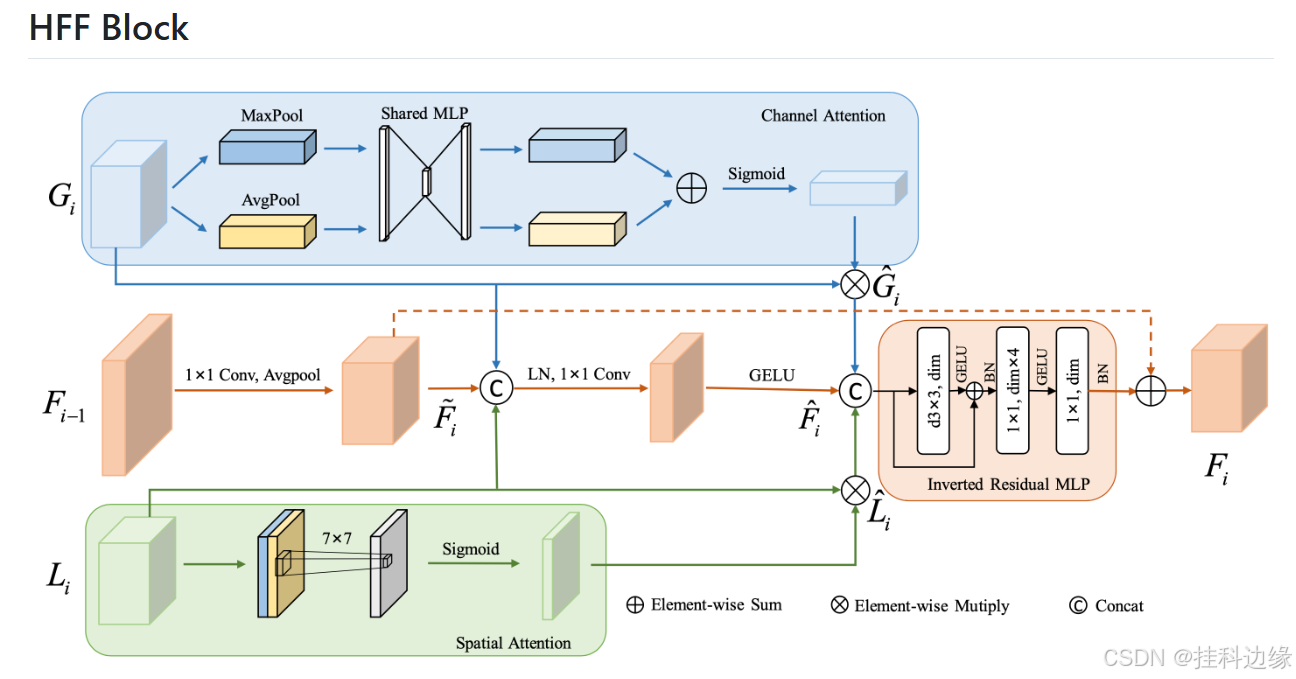
在卷积神经网络的推动下,医学图像分类得到了迅速发展网络(CNN)。作者提出了一种三分支分层多尺度特征融合网络结构作为一种新的医学图像分类方法被称为HiFuse。它可以融合Transformer和CNN来自多尺度层次结构,不破坏各自的建模,因此从而提高各种医学图像的分类精度。一个并行的局部层次结构设计了全局特征块,有效地提取局部特征和全局表示在各种语义尺度下,具有在不同尺度下建模的灵活性和线性计算能力与图像大小相关的复杂性。此外,还提出了一种自适应分层特征融合块(HFF块)设计为综合利用在不同层次上获得的特征。这个HFF块包含空间注意、通道注意、剩余倒转MLP和adap快捷方式主动融合各分支各尺度特征间的语义信息。
理论介绍
HiFuse 模型设计三分支并行架构:局部分支(CNN 提取细节)、全局分支(Transformer 关注整体特征)、融合分支(HFF Block 进行多尺度特征融合):
- 局部分支(Local Block):使用 3×3 深度卷积提取局部信息。
- 全局分支(Global Block):采用 Swin Transformer 提取全局信息。
- 融合分支(HFF Block):包括通道注意力、空间注意力、残差 MLP、快捷连接,自适应融合各层次信息。
下图摘自论文
理论详解可以参考链接:论文地址
代码可在这个链接找到:代码地址
下文都是手把手教程,跟着操作即可添加成功

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 77
77

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











