









摘要三维生成近年来成为计算机图形学领域的研究热点。随着更多高效的三维表示和优质的生成模型的出现,人们不断追求创建越来越高质量和多样化的三维模型。本篇综述将介绍三维生成领域三维表示与生成方法。具体来说,本文首先将介绍作为三维生成支柱的三维表示方法。其次,本文还将介绍不同类型的生成方法,包括原生三维生成方法、基于优化的生成方法与多视角视图生成。一、简介3D生成方法在技术上主要包括3D表示方法、3D生成方法、3D数据集。3D表示方法是3D生成任务中最重要的部分,决定了模型的生成速度与应用范围。3D生成方法基于用户输入的图片或文本信息,通过优化或直接生成,得到目标物体的3D表示模型。本文将围绕3D表示方法与3D生成方法展开介绍。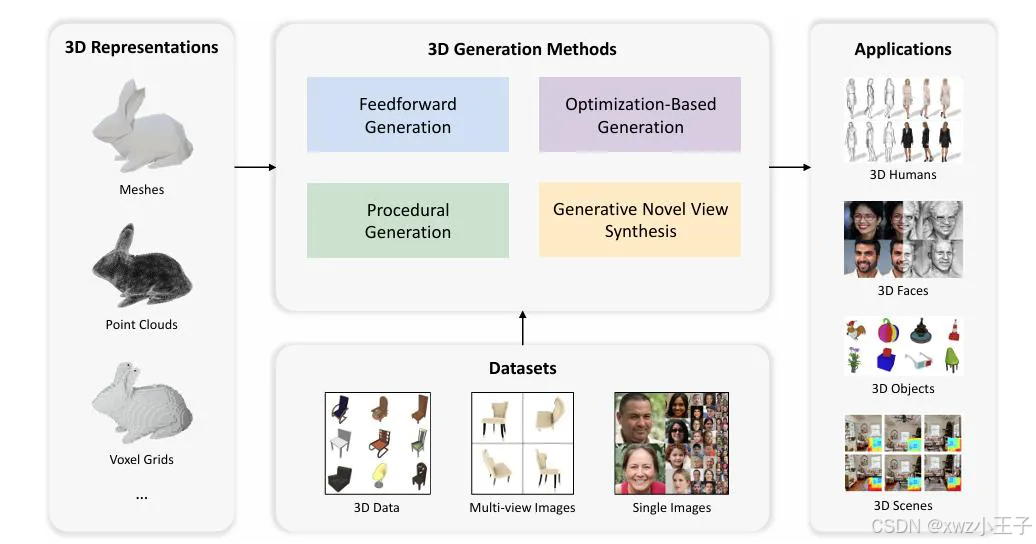
图1 3D生成技术路线二、3D表示方法如何表示3D几何数据对于生成3D内容的速度和质量至关重要。当前的3D表示通常分为两类,即显式和隐式表示。在生成过程中,一些算法可以直接监督3D几何形状,而另一部分算法则利用3D模型渲染出的2D图片监督3D形状。1.显式表示显式表示通常是指对3D对象的几何形状或结构的直接表示。它涉及明确定义对象的表面或体积表示,例如通过使用点云、体素网格或Mesh。显式表示的优点是它能够实现更精确的几何控制和多尺度编辑。1.1点云点云是欧几里德空间中表示三维环境中离散点的非结构化元素集合。这些点可以具有其他属性,如颜色和法线,在某些情况下,深度和法线贴图可以被视为点云表示的特定实例。点云通常直接从深度传感器获得,使其广泛应用于与3D场景理解相关的各种任务中。然而,尽管点云易于获取,但由于其不规则性,点云给传统的二维神经网络带来了挑战,使其难以有效处理。此外,点云的断开和非结构化性质在底层几何方面引入了模糊性。考虑到这些局限性,只有Point-E方法[1]采用点云作为3D表示,并通过固定点的数量来生成粗略的形状。点云的效果极大地取决于其中点的数量,在构建高分辨率形状时需要大量的点,从而导致GPU显存的大量消耗。1.2 MeshMesh是计算机视觉和图形学中常用的一种的3D表示。Mesh由顶点、边和面组成,在内存使用和扩展性方面具有很大优势。Mesh只对对象的表面进行编码,使与体素网格相比对显存需求较少。与点云相比,Mesh提供了明确的连接信息,便于几何变换,还可以方便地对纹理进行表征。最近,已经有工作实现了可微Mesh渲染方法[2,3],使Mesh能够光栅化以进行基于梯度的优化,更新Mesh的参数。然而,由于不规则的数据结构以及预测顶点位置和拓扑信息的复杂性,使用和生成3D网格也会带来一些挑战。到目前为止,还没有直接优化Mesh的基于文本的3D生成方法。现有的解决方案通常涉及通过曲面重建技术(用于点状表示)或等值面提取技术(用于隐式表示)将中间表示转换为Mesh。2. 隐式表示隐式表示涉及构建一个描述3D空间属性的映射函数,通过数学公式或神经网络描述3D物体的形状和颜色。与侧重于物体表面的显式表示相反,隐式表示可以表示完整的3D物体。隐式表示可以以任意分辨率渲染3D场景或对象并且在显存占用方面具有明显优势。2.1 NeRFNeRF(神经辐射场)是一种新兴的神经渲染方法,在复杂场景的新颖视图合成方面取得了较好的进展,被大量基于优化的3D生成工作[3,4]采用。NeRF由两个主要组件组成,包括体积射线跟踪器和多层感知器(MLP)。尽管它在渲染输出方面可能很慢,NeRF通常用作AIGC-3D应用程序中的全局表示。在渲染一个像素时,NeRF会投射一条光线,将其经过所有采样点的颜色累积起来,得到最终这一像素的颜色。NeRF的渲染过程决定了其渲染速度较慢,导致其在训练时会消耗大量时间。2.2 3D Gaussian3D Gaussian(3D高斯分布)[5]是当前综合性能最强的表示方法,它具有高效的渲染能力和灵活性,在3D重建和生成任务中得到了广泛的应用。3D Gaussian将对象表示为由其位置、协方差、颜色和不透明度四个参数表示的各向异性高斯分布的集合。在训练过程模型通过更新这些参数可以同时对形状、纹理与颜色进行优化。在渲染过程中,这些3D Gaussian被投影到相机的成像平面上,得到的2D Gaussian分布被分配给各个图块。3D高斯分布在文本到3D领域得到了大量应用[6-8]。虽然3D高斯分布提供了一种快速收敛的解决办法,但初始化对生成结果的影响较大,并且可能表现出不稳定的优化。因此,在基于优化的生成方法中,如[6,7]中观察到的,可能出现多视角一致性较差的问题。三、3D生成方法当前3D生成方法主要分为原生3D生成方法与基于2D先验的生成方法。原生3D生成方法直接在3D数据集上进行训练,但这些方法受到数据集的制约,3D数据集存在样本数量少、获取成本高、存储需求大等问题,导致原生3D方法的效果始终欠佳。目前主流的方法是基于2D先验的3D生成方法,如图6所示,这种方法通常采用2D生成模型,如Stable Diffusion[3]作为监督,通过3D模型渲染出的2D图片计算损失。本文将围绕基于2D先验的生成方法进行阐述。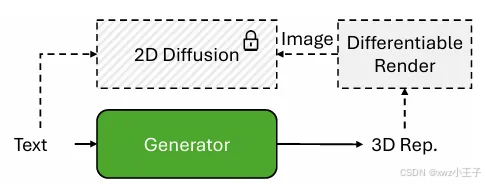
图2 基于2D先验的3D生成方法1. 基于2D先验的3D生成方法在文本到3D生成领域,受文本到StableDiffusion模型成功的启发,研究人员越来越多地转向基于优化的方法[7]。这些方法避开了对大规模文本3D数据集的需求。Dreamfusion[3]引入了一种名为分数蒸馏采样(SDS)的关键技术。SDS利用StableDiffusion先验作为评分函数来指导NeRF模型的优化。∇𝜃𝐿𝑆𝐷𝑆(𝜃)=𝐸𝑡,𝜖[𝑤(𝑡)(𝜀̂(𝑥𝑡,𝑡,𝑦)−𝜀)𝜕𝑔(𝜃,𝑐)𝜕𝜃]上式中𝜖̂为StableDiffusion的预测噪声,𝑡为随机去噪时间步,𝜀为加入的随机噪声,通过对NeRF参数𝜃求导可以据此更新模型的参数,实现对形状和颜色的控制。尽管它很受欢迎,但实验表明SDS经常遇到多视角不一致的问题,且生成结果表面过于平滑,训练耗时较长。下面将简述几种不同的改进方式。1.1 基于3D Gaussian的3D生成其中一种改进方法是使用3D Gaussian替换NeRF模型,与NeRF相比,其显存占用更低且收敛速度更快。DreamGaussian[7]在球体内采用了一种采样方法并使用SDS损失优化3D高斯分布。这一方法定期加密点以添加细节并提取Mesh,通过局部查询密度和细化从3D高斯分布中提取的UV空间增强纹理细节。然而,DreamGaussian同样面临着由于2D SDS监督的模糊性快速收敛导致的多视角不一致的问题。为了解决这个问题,GSGEN[10]和GaussianDreamer[6]引入Gaussian的初始化方法。GaussianDreamer使用Shap-E[11]初始化,而GSGEN从Point-E[1]初始化。在颜色与纹理优化阶段,GSGEN提出一个高斯稠密化方法,填补高斯的空缺,从而形成更完整且连续的几何形状结构。1.2 基于多视角生成模型的3D生成为解决单视图重建方法的一致性问题,人们提出使用多视角生成模型替代StableDiffusion作为监督,利用单张图片预测其它视角的图片以提高3D生成的一致性。Zero123[12]应用3D数据来微调预训练的2D扩散模型,从而能够生成基于单个输入图片的新视角图片。这项工作表明,StableDiffusion本身包含了大量3D知识,可以通过多视图微调来提取出来。在此基础上,One-2-3-45[13]利用Zero123生成多个视图。然后,它连接了一个重建模型,在短短45秒内从单个图像生成3D Mesh。这种方法相比依赖2D先验的优化方法在3D生成的速度和效果上均有显著提升。虽然Zero123中新生成的视图与给定的视图一致,但生成的新视图一致性仍然欠佳。SyncDreamer[14]、MVDream[15]都能够同时生成多个视角的图片,并在不同视角间进行信息交换以确保一致性。Wonder3D[16]引入了一种法线模式,并对多视角Stble Diffusion模型进行了微调,令其能够跨视角同时输出RGB和法线贴图。[1] A. Nichol, H. Jun, P. Dhariwal, P. Mishkin, and M. Chen, “Point-e: A system for generating 3d point clouds from complex prompts,” arXiv preprint arXiv:2212.08751, 2022.[2] J. Hasselgren, J. Munkberg, J. Lehtinen, M. Aittala, and S. Laine, “Appearance-driven automatic 3d model simplification.” in EGSR (DL), 2021, pp. 85–97.[3] J. Munkberg, J. Hasselgren, T. Shen, J. Gao, W. Chen, A. Evans, T. Müller, and S. Fidler, “Extracting triangular 3d models, materials, and lighting from images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8280–8290[3] Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In ICLR, 2023.[4] J. Zhu and P. Zhuang, “Hifa: High-fidelity text-to-3d with advanced diffusion guidance,” arXiv preprint arXiv:2305.18766, 2023.[5] B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,” ACM Transactions on Graphics, vol. 42, no. 4, pp. 1–14, 2023.[6] T. Yi, J. Fang, J. Wang, G. Wu, L. Xie, X. Zhang, W. Liu, Q. Tian, and X. Wang, “Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models,” in CVPR, 2024.[7] J. Tang, J. Ren, H. Zhou, Z. Liu, and G. Zeng, “Dreamgaussian: Generative gaussian splatting for efficient 3d content creation,” arXiv preprint arXiv:2309.16653, 2023.[8] J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, and Z. Liu, “Lgm: Large multi-view gaussian model for high-resolution 3d content creation,” arXiv preprint arXiv:2402.05054, 2024.[9] H. Wang, X. Du, J. Li, R. A. Yeh, and G. Shakhnarovich, “Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12619–12629.[10] Z. Chen, F. Wang, and H. Liu, “Text-to-3d using gaussian splatting,” arXiv preprint arXiv:2309.16585, 2023[11] H. Jun and A. Nichol, “Shap-e: Generating conditional 3d implicit functions,” arXiv preprint arXiv:2305.02463, 2023.[12] R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. Vondrick, “Zero-1-to-3: Zero-shot one image to 3d object,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9298–9309.[13] M. Liu, C. Xu, H. Jin, L. Chen, M. Varma T, Z. Xu, and H. Su, “One-2 3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization,” Advances in Neural Information Processing Systems, vol. 36, 2024.[14] Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Sync dreamer: Generating multiview-consistent images from a single view image. ICLR, 2024.[15] Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation. ICLR, 2024.[16] Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion. arXiv preprint arXiv:2310.15008, 2023.

















02-28
 3459
3459
3459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









