







 本文介绍了一种结合物体运动和摄像机运动控制的深度学习方法,使用Fourier嵌入和多层感知器处理摄像机移动,通过temporal和spatial注意力机制增强一致性。实验在MSRVTT和AnimalKingdom数据集上评估了模型性能,关注视频质量、框与对象一致性以及摄像机和对象运动的同步.
本文介绍了一种结合物体运动和摄像机运动控制的深度学习方法,使用Fourier嵌入和多层感知器处理摄像机移动,通过temporal和spatial注意力机制增强一致性。实验在MSRVTT和AnimalKingdom数据集上评估了模型性能,关注视频质量、框与对象一致性以及摄像机和对象运动的同步.
同时支持object movement和camera movement
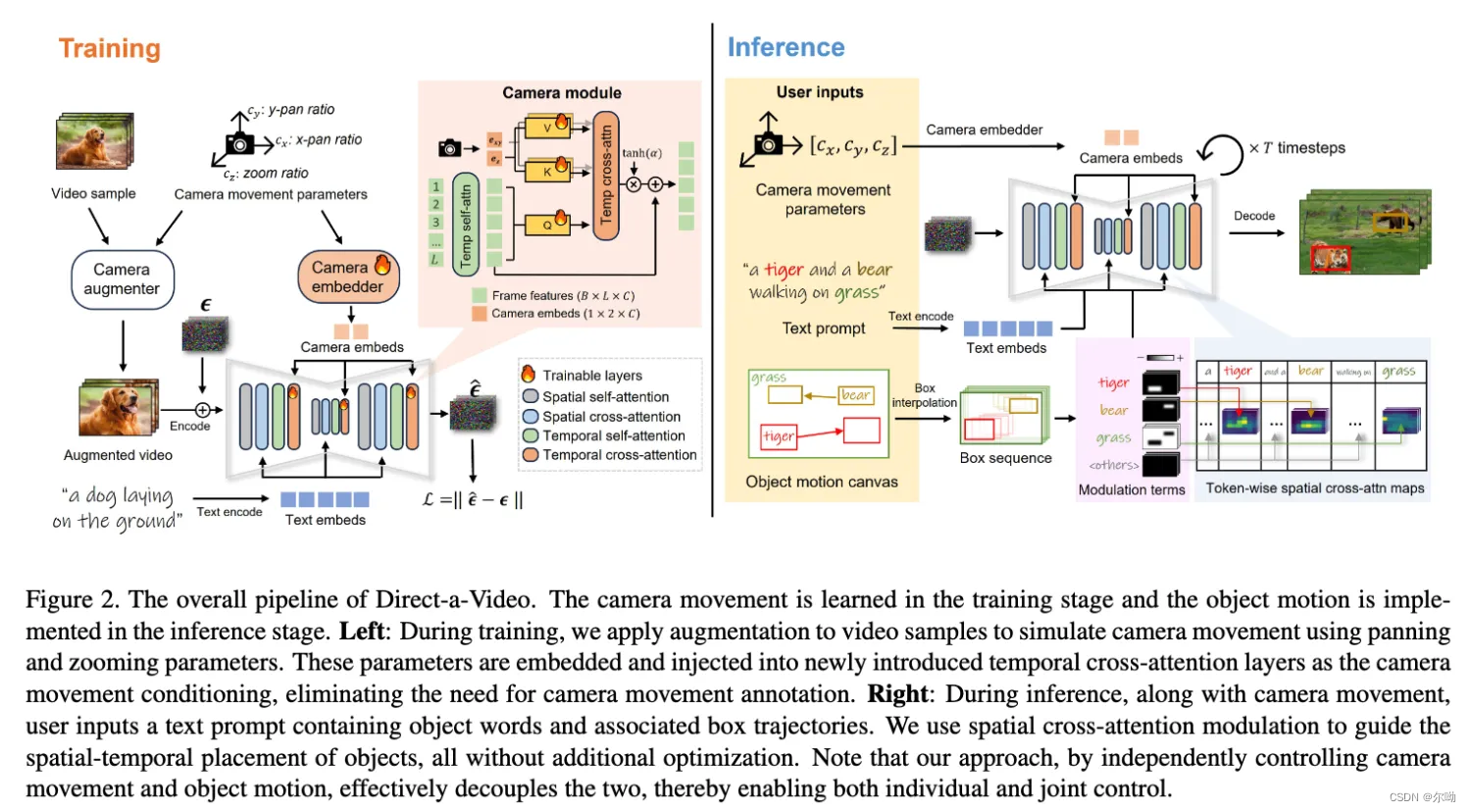
- camera movement control
a. 需要训练
b. 分为两个平移和一个zoom in的量 c c a m = [ c x , c y , c z ] c_{cam}=[c_x,c_y,c_z] ccam=[cx,cy,cz],使用的数据是生成的数据MovieShot, c c a m c_{cam} ccam会经过camera embedder,包含Fourier embedder和两个MLP得到 e x y = M L P x y ( F ( [ c x , c y ] ) ) , e z = M L P z ( F ( c z ) ) e_{xy}=MLP_{xy}(F([c_x,c_y])),e_z=MLP_z(F(c_z)) exy=MLPxy(F([cx,cy])),ez=MLPz(F(cz))
c. 之后通过新添加一个temporal cross attention层来integrate F = F + t a n h ( α ) ⋅ T e m p C r o s s A t t n ( F , e c a m ) , T e m p C r o s s A t t n ( F , e c a m ) = S o f t m a x ( Q [ K x y , K z ] T d ) [ V x y , V z ] F=F+tanh(\alpha)\cdot TempCrossAttn(F,e_{cam}),TempCrossAttn(F,e_{cam})=Softmax(\frac{Q[K_{xy},K_z]^T}{\sqrt{d}})[V_{xy},V_z] F=F+tanh(α)⋅TempCrossAttn(F,ecam),TempCrossAttn(F,ecam)=Softmax(dQ[Kxy,Kz]T)[Vxy,Vz] - object movement control
a. 不需要训练
b. user提供起点和终点框以及中间的路径,通过插值可以得到一系列的框;
c. 通过修改spatial cross-attention C r o s s A t t n M o d u l a t e ( Q , K , V ) = S o f t m a x ( Q K T + λ S d ) V CrossAttnModulate(Q,K,V)=Softmax(\frac{QK^T+\lambda S}{\sqrt{d}})V CrossAttnModulate(Q,K,V)=Softmax(dQKT+λS)V
d. 有两种修改
ⅰ. Attention amplification.,现在针对object n和frame k的bbox ,增加该区域的attention值
ⅱ. Attention suppression. - 实验
a. 基础模型是ali
b. camera control的数据是MovieShot
c. metrics
ⅰ. 评价生成视频的质量:2048 videos from MSRVTT [61] for camera movement task and 800 videos from AnimalKingdom [40] for object motion task.
ⅱ. box和obejct的一致性:CLIP image-text similarity
ⅲ. camera and object motion alignment















 8040
8040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









