







- Alibaba&南京大学&复旦大学
- https://fudan-generative-vision.github.io/champ/#/代码开源
- related works:16, 43(skeleton),36,47(semantic),18,56(dense motion flows),9, 24,35, 40, 44, 45(gan),14, 39,11, 18, 18, 43, 52(diffusion-based)
- 问题引入
- 问题基本定义:输入参考人体图片和一段视频,视频描述了运动序列,输出的是参考人根据视频序列进行运动的视频;
- methods
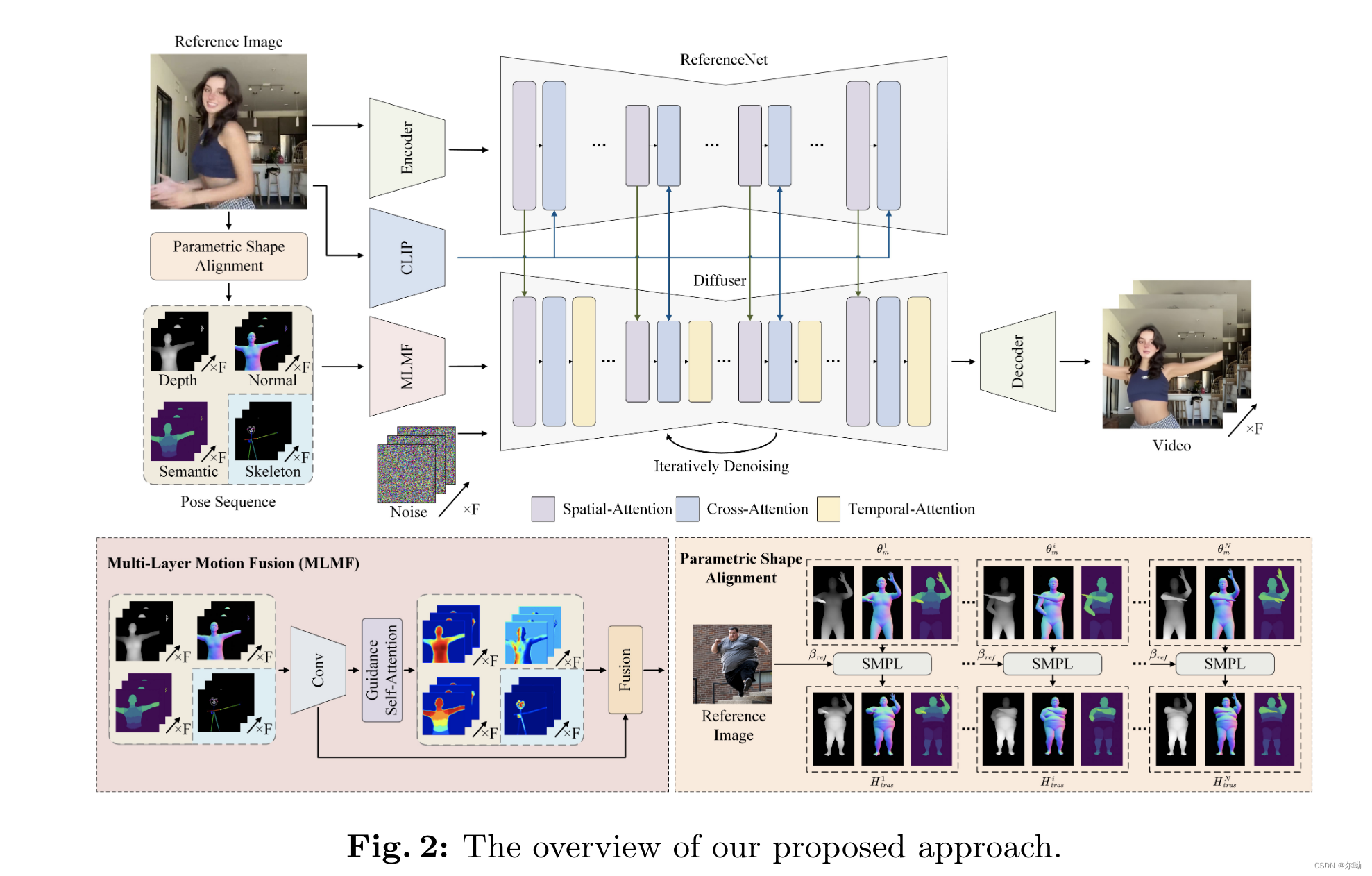
- 整体框架:本文提出了SMPL模型来提取pose和shape信息,之后这些信息作为LDM模型的输入指导信息,具体如下图所示;
- SMPL model:参数化的表示人体,其中pose表示在空间 θ ∈ R 24 × 3 × 3 \theta\in\mathbb{R}^{24\times3\times3} θ∈R24×3×3,shape表示在空间 β ∈ R 10 \beta\in\mathbb{R}^{10} β∈R10,融合两个参数空间,就可以生成一个人体的3d网格表示 M ∈ R 3 × N M\in\mathbb{R}^{3\times N} M∈R3×N,其中 N = 6890 N=6890 N=6890表示定点个数,定点权重 W ∈ R N × k W\in\mathbb{R}^{N\times k} W∈RN×k表示顶点和关节之间的关系;
- 给出参考图片 I r e f I_{ref} Iref和一段视频 I 1 : N I^{1:N} I1:N,使用模型4D-Humans得到SMPL表示, H r e f , H 1 : N H_{ref},H^{1:N} Href,H1:N,之后得到对应的人体网格表示,从而可以从网格中提取对应的深度图、法向量图和semantic;
- 因为要生成的事参考图片的视频,所以SMPL表示是 H t r a n s i = S M P L ( β r e f , θ m i ) H^i_{trans}=SMPL(\beta_{ref},\theta_m^i) Htransi=SMPL(βref,θmi),其中 i i i表示帧序号,表示融合参考图片的shape参数空间和第 i i i帧的pose参数空间;
- 除了上面三种条件(depth,semantic,normal)以外还加入了skeleton来增强对面部表情和手部动作的表示;
- 四种guidence的监督方式,分别有各自的guidence网络 F i ( ⋅ , θ i ) F^i(\cdot,\theta^i) Fi(⋅,θi),在对条件进行编码之后将得到的结果进行加和 y = ∑ i = 1 N F i ( ⋅ , θ i ) y = \sum_{i = 1}^NF^i(\cdot,\theta^i) y=∑i=1NFi(⋅,θi),作为最后的guidance和noise latent结合作为网络的输入;
- 实验
- 数据:从各个平台上收集的5000段视频;
- 训练:两阶段,8卡A100















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









