







- CUHK&Tencent&HKUST TVCG2024
- https://github.com/AILab-CVC/Make-Your-Video
- 问题引入
- text&motion stucture(例如深度图序列) guided video generation;
- methods
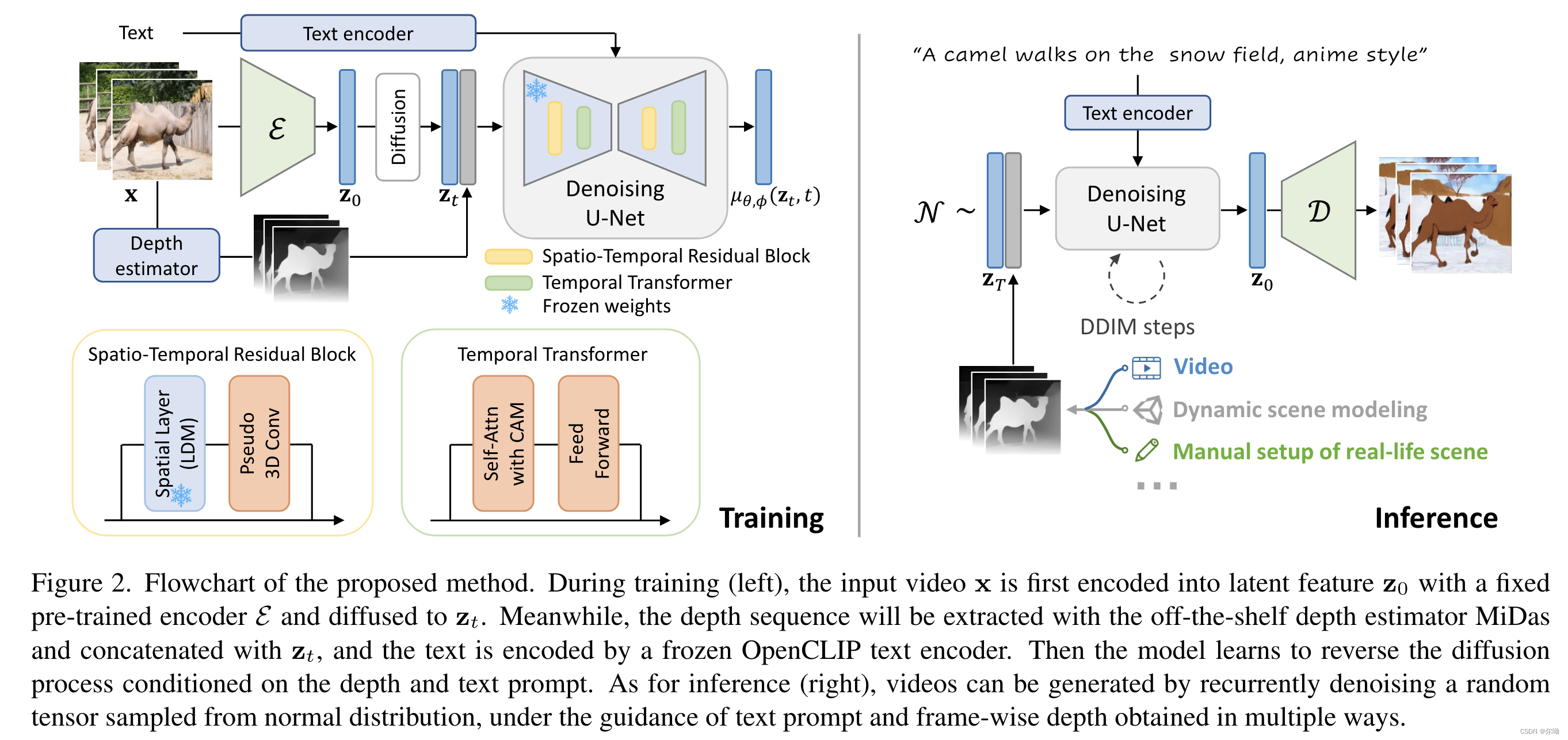
- text控制:cross attn;
- depth控制:和noised latents concat都一起作为输入;
- 时序模块:spatial-temporal residual block&temporal transformer,在训练的时候只训练新加入的时序模块;
- 在生成长视频的时候质量显著下降:Temporal Masking for Longer Video Synthesis,temporal attention的计算: F t = A t t e n t i o n ( Q t , K t , V t ) = s o f t m a x ( Q t K t T d + M ) V t F_t = Attention(Q_t,K_t,V_t)=softmax(\frac{Q_tK_t^T}{\sqrt{d}} + M)V_t Ft=Attention(Qt,Kt,Vt)=softmax(dQtKtT+M)Vt,其中 M M M是一个下三角矩阵 M i , j = 0 i f i > j e l s e − ∞ M_{i,j}=0\ if\ i > j\ else\ -\infty Mi,j=0 if i>j else −∞;
- 实验
- 使用stable-diffusion-depth加入新的时序模块;
- 数据使用webvid-10M;















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









