






传输类型
HTRANS[1:0]信号用于指示当前的传输类型,一共有四种类型:
- IDLE
- 没有数据传输,其它的控制信号和地址信号因此也就不起作用。
- BUSY
- 没有数据需要传输。
- 这个信号可以在突发传输中(什么是突发传输后面讲,因为官方文档也是这个顺序,如果这一部分看不懂的,先硬着头皮看完,然后等看完后面的突发传输再回过头来再看一遍),用来插入空闲的CYCLE,表示主机在忙,也就是说传输还在继续,但是处于暂停状态。
- 在不指定突发长度的情况下,在最后一拍用BUSY去传输,来表明这是Burst的最后一笔,这一鸡肋的机制被AXI的LAST信号完美替代。
- 实际上BUSY这个状态很少见,在CORTEX-M系列基本上不会有这个BUSY状态,在大部分情况下都是使用NONSEQ和SEQ传输类型,因此可以暂时不去掌握该类型
- NONSEQ
- 需要传输数据。
- 可能是发一笔数据(Single传输),也可能是Burst传输的第一笔transfer(在这里transfer指的是突发传输的一次读或者一次写,或者就是Single传输)。
- 地址和其它控制信息和之前的传输没有关系!只取决于这次transfer本身。
- SEQ
- 需要传输数据。
- 用在突发传输中,代表连续的传输。
- 地址需要增加(除非上一笔transfer是BUSY transfer)。
- 其它的控制信号保持不变。
4-beat 突发传输
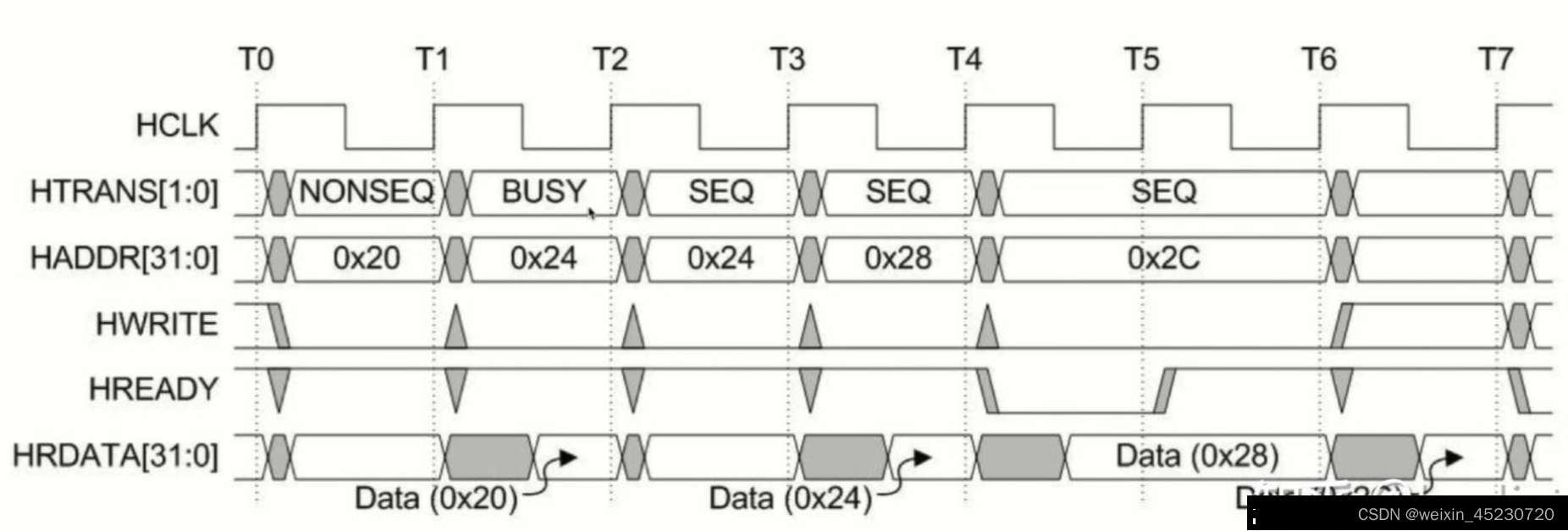
可以看到这次的时序图和之前最简单的传输相比,增加了一个HTRANS信号,实际上是之前没有画出来,大家可以思考一下最简单的传输中HTRANS信号应该是怎么变化的?
由上图可以知道,这是一次突发读操作,实际上是4拍有效读:
- T0->T1:突发传输的第一笔Transfer,因此HTRANS应该为NONSEQ,HADDR为0x20代表起始地址.
- T1->T2:突发传输的第二笔Transfer(伪),因为HTRANS为BUSY,可能是因为主机忙碌没有空去读,所以插入了这样一拍,HADDR增加0x4,HRDATA返回了0x20地址的数据,这一拍没有发生数据传输。
- T2->T3:突发传输的第二笔Transfer(真),由于上一拍是BUSY,所以HADDR的地址不需要增加。HTRANS应该是SEQ。
- T3->T4:和上一拍差不多,第三笔Transfer。
- T4->T5:最后一拍读,由于Slave不能完成数据传输,因此将HREADY拉低,这一拍相当于wait state。
- T5->T6:最后一拍读,HREADY拉高,说明这拍主机可以将控制信号等信息发给从机。
- T6->T7:从机返回最后一拍读的数据。
带锁传输(locked transfers)
如果主机想发起一次带锁的访问,那么就需要HMASTERLOCK信号。至于什么是“锁”,请自行学习操作系统相关的知识(想做SoC的朋友一定要认真学操作系统和体系结构这两门课啊!)。
简单理解就是在多主机可以访问一个从机的情况下,需要确保这个时间段只有该主机对其进行访问,避免数据出现错误,如图3所示。(想象一下,主机2去写个数据,还没有写完主机1就去读同样的地址的数据,就拿到了旧的值,这样就不符合预期了,很多汇编指令有原子操作指令,从底层来看就需要硬件的机制来帮忙)。

同样的,我们看传输协议,如图3所示。可以看到是一个读操作一个写操作,HMASTERLOCK为高说明这是带锁的操作,也就是希望这两个操作之间不希望被BUS的Interconnect打断!
以图5为例,slave3可以被多个Master访问,假设Master0发起了读又发起了写,没有原子操作的支持的话,假设Master1也发起了读,我们本质上是希望Master1读到Master0写到slave3的数据,但是Master1的读很可能位于Master0的写之前,这样就不符合我们的预期了。流程如下:
- Master0读Slave0
- Master1读Slave0(读到的还是之前的值,不是Master0新写的值!)
- Master0写Slave0
因此就需要HMASTERLOCK的支持。他保证了这两笔是原子的,中间不会有任何的操作。这样就非常的赛高啊,完美实现了我们的需求。流程如下:
- Master0读Slave0紧接着Master0写Slave0(这是一个整体,不能被打断)
- Master1读Slave0
此外在原子操作的下一拍,通常插入一个IDLE,代表原子操作结束了。如图2的第三拍所示。

还有一点需要注意,大部分Slave实际上不需要实现HMASTERLOCK信号,因为大部分Slave不会被多个Master所访问。只有能够被多个Master访问的Slave,才需要HMASTERLOCK信号,如多端口Memory Controller,就必须要实现HMASTERLOCK信号的机制。
传输大小就不再介绍了参看AHB协议介绍
burst传输(重点)
突发(burst)将多个传输(Transfer)作为一个单元(有时候可以叫Transaction)进行执行,而不是独立地处理每次Transfer,核心思想是将多次Transfer看做一个整体。对于主机而言,一次下发,即可实现连续的写或者连续的读。
我们重新看一下图2,这就是一次突发读。共有4个beat(4次Transfer)。对于主机而言,只要下发一次命令,给个起始地址,给个突发传输的类型,给个Size。就不用管后续的东西了,剩下的Interconnect会帮助主机完成。
突发传输本质上有四种类型:
- SINGLE
- 突发长度为1,也可以理解成不是突发传输。
- HTRANS可以是IDLE或者NONSEQ。
- INCR
- 非定长。
- 不可以跨越1KByte的边界(因为AHB规定不同的Slave最小粒度为1KB,因此跨越1KB可能访问到别的Slave去)。
- INCRx
- 定长,可以是4、8、16笔transfer。
- 不可以跨越1KByte的边界。
- WRAPx
- 回环(主要用于cacheline,具体的后面说),可以是4、8、16笔transfer。
- Cacheline访问,critical word first(关键词优先)。
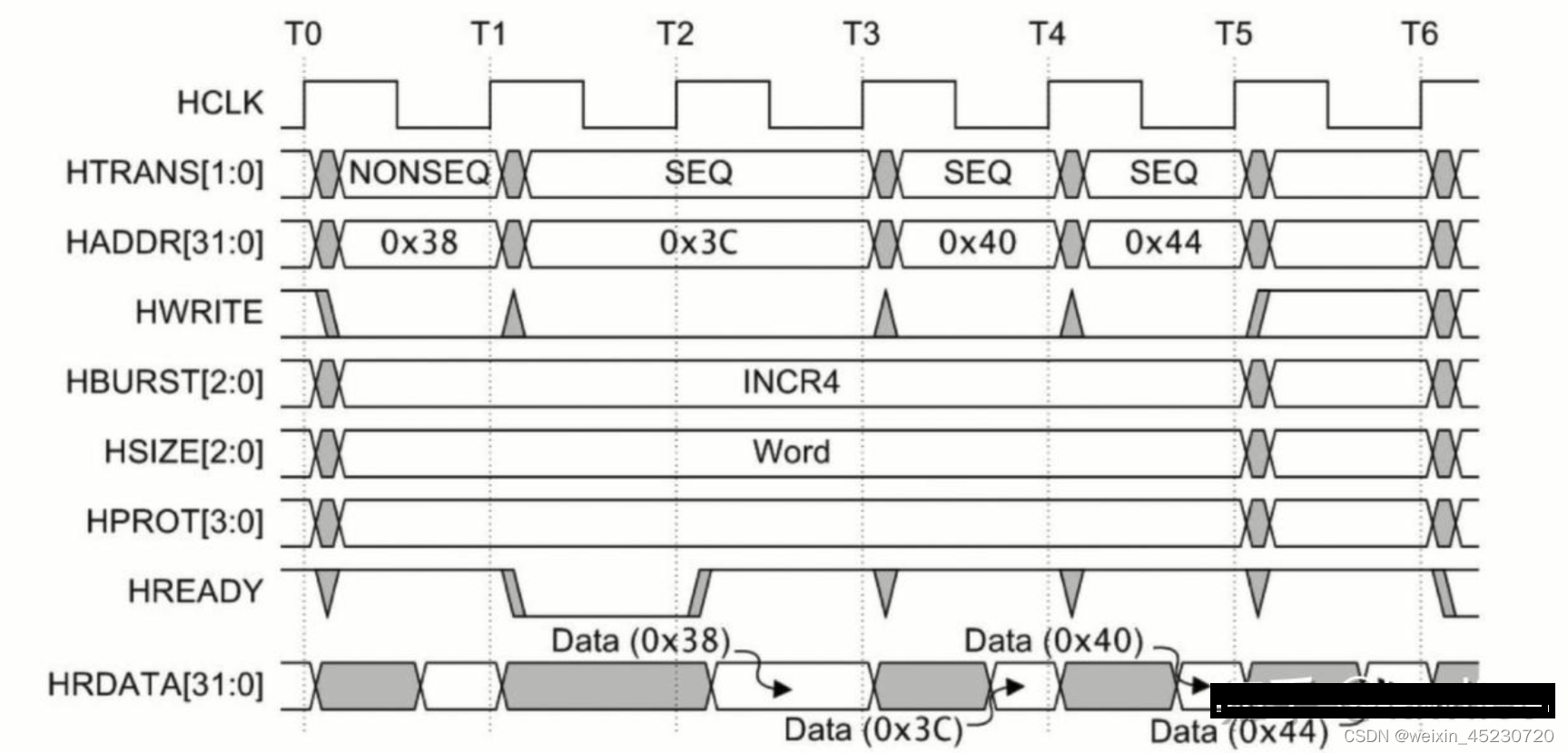
首先看一下INCR4的例子,如下图所示:
- 总共是4笔Transfer(因为HBURST为INCR4)
- HADDR每次增加0x4(因为HSZIE为Word,即代表32Bit)
- HTRANS,第一笔为NONSEQ,后面的为SEQ
可以看到有了突发传输,主机只需要给个地址,给个HBURST类型,给个HSIZE,就可以坐等4组数据的返回了!并且突发读是流水线的,理论上最快只需要N+1个Cycle(N为transfer次数)。
再思考一下:突发读或者突发写,和流水线形式的SINGLE TRANSFER是一样快的嘛?为什么?
再看一下WRAP8的例子,如下图所示:
- 总共是8次Transfer(因为HBURST是WRAP8)
- 地址每次增加4(因为HSIZE为Word,即代表32Bit)
- 地址不总是增加,从0x90开始,也就是critcal-word,增加到0x9c以后跳回了0x80
- 为什么这么算呢?这是由WRAP8和HSIZE共同决定的,HSIZE决定了每次地址增加0x4,而8个0x4就是0x20,也就是0x20为一组。0x90则属于第五组(0x80~0x9C之间),因此地址是这样变化的(看一下图9,从中间开始增加,然后返回起点继续写)

突发读或者突发写,和流水线形式的SINGLE TRANSFER是一样快的嘛?为什么?
表面上来看,没什么区别。理论上都是N+1个Cycle。但是这是针对一拍可以回数的紧耦合SRAM而言的,如果访问的是DDR呢?
- 如果是突发传输,你只需要下发一次命令,DDR Controller可以帮你计算好,你总共需要读多少数据,比如每一拍是32Bit,突发长度是4,DDR控制器只要对DDR发一次命令即可,一次性读回128Bit的数据
- 如果是Single transfer,DDR Controller可不知道你下一笔传输的地址和这笔传输的地址只差了0x4,DDR Controller完全可能把你的第一次single transfer下发出去,然后又下发第二次,然后又下发第三次,然后...由于DDR的读取时序没有那么简单,不是完全的流水式的,因此这中间就可以阻塞很多个周期。
- 所以!突发传输和流水线的Single transfer是不一样的!能用突发传输就用突发传输,不要用多次Single Transfer。
参考 AMBA学习 - 知乎














 1569
1569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









