






本篇博客针对FPN进行学习。
FPN
fpn网络是一种特征融合网络,全称为Feature Pyramid Networks,具有金字塔结构。
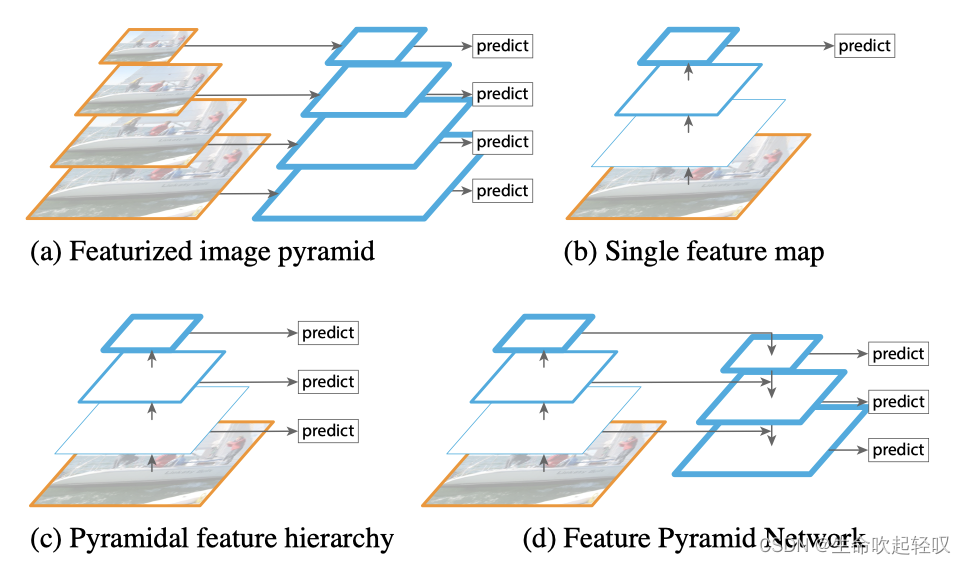
原论文给出了四种特征网络结构,特征图用蓝色轮廓线表示,较粗的轮廓线表示较强的语义特征。
(a)把一幅图缩放到不同的尺寸,然后对于每一种尺寸的图片,都依次通过算法进行预测,其效率较低。
(b)相当于之前Faster RCNN所采用的一种方式,利用backbone对图片进行处理,得到最终的特征图,最后根据它进行最终的预测,这种方式对于小目标的预测效果不佳。
©利用backbone将一张图片转化为不同的特征图,然后在不同的特征图上进行预测。
(d)即为我们所学习的FPN结构,相较于其他结构,fpn并不是在backbone生成的特征图上直接进行预测,而是将不同特征图上的特征进行融合,然后才对于融合特征图进行预测。
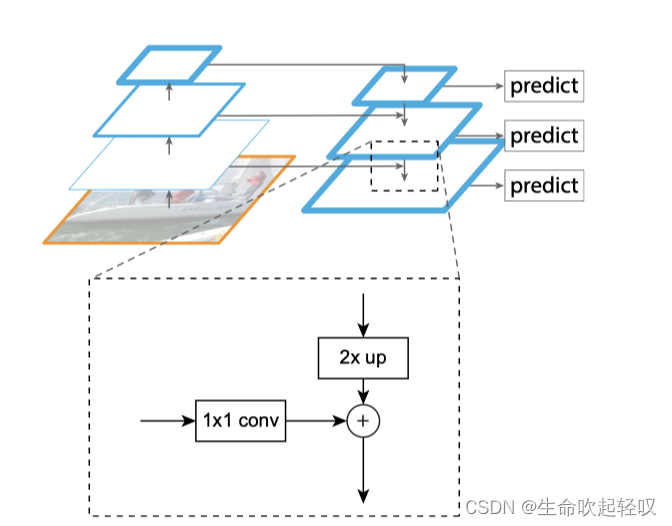
该论文利用了ConvNet特征层次的金字塔形状,同时创造了一个在所有尺度上都具有强大语义的特征金字塔。它依赖于一种结构,它将低分辨率、语义强大的特征与高分辨率、语义上弱的特征通过自顶向下的路径和横向连接相结合(如上图),其结果是一个功能金字塔,在所有级别都具有丰富的语义,并且可以根据单个的输入图像进行快速构建,这种方法,就叫Feature Pyramid Network(FPN)
自底向上的路径
Bottom-up pathway. The bottom-up pathway is the feedforward computation of the backbone ConvNet, which computes a feature hierarchy consisting of feature maps at several scales with a scaling step of 2.
在上图的左半部分,我们看出有一条从图像到特征图的自底向上的路径,它由backbone ConvNet的前馈计算,它计算由几个比例的特征映射组成的特征层次结构,为了符合不同特征图能够合并的要求,特征图的大小都为2的整数倍,即特征层次结构的缩放步长为2。如图为例,最底层的特征图如果为2828,那么上一层的特征图就为1414,顶层特征图为7*7。
通常有很多图层产生相同大小的输出图,我们说这些图层处于相同的网络阶段。对于我们的特征金字塔,我们为每个阶段定义一个金字塔等级。我们选择每个阶段的最后一层的输出作为我们的特征地图的参考集,我们将丰富它来创建我们的金字塔。这种选择是自然的,因为每个阶段的最深层应具有最强大的特征。
自上而下的路径和横向连接
该网络结构对于不同的特征图进行融合,上面已经说明,该结构使用横向连接和自顶向下的路径,通过添加合并。通过向上采样可以在空间较粗糙但在语义上较强,处于较高金字塔等级的特征图上提取出更高分辨率的特征。这些特征随后通过横向连接得到增强,底层的特征图具有较低级别的语义,但因为其被二次抽样的次数更少,因此它的激活更本地化。
The bottom-up feature map is of lower-level semantics, but its activations are more accurately localized as it was subsampled fewer times.
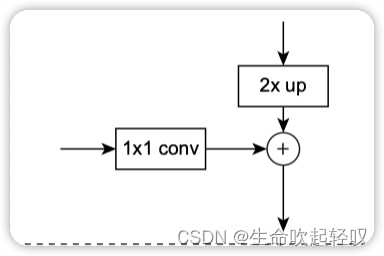
在连接过程中,对于每一层的特征图,都会使用一个11的卷积层处理,以减少信道维度,调整backbone上不同特征图的channel,保证相同(原论文中11卷积核的数量为256,即最终得到特征图的channel都为256)。紧接着对上一层的特征图进行二倍的上采样。例如顶层特征图大小为77,经过放大后,变成了1414的特征图,刚好就可以和下一层的特征图经过卷积后的shape是相同的,因此就可以进行add操作。同理,新生成的特征图经过二倍放大后再和下一层进行add操作,以此类推。
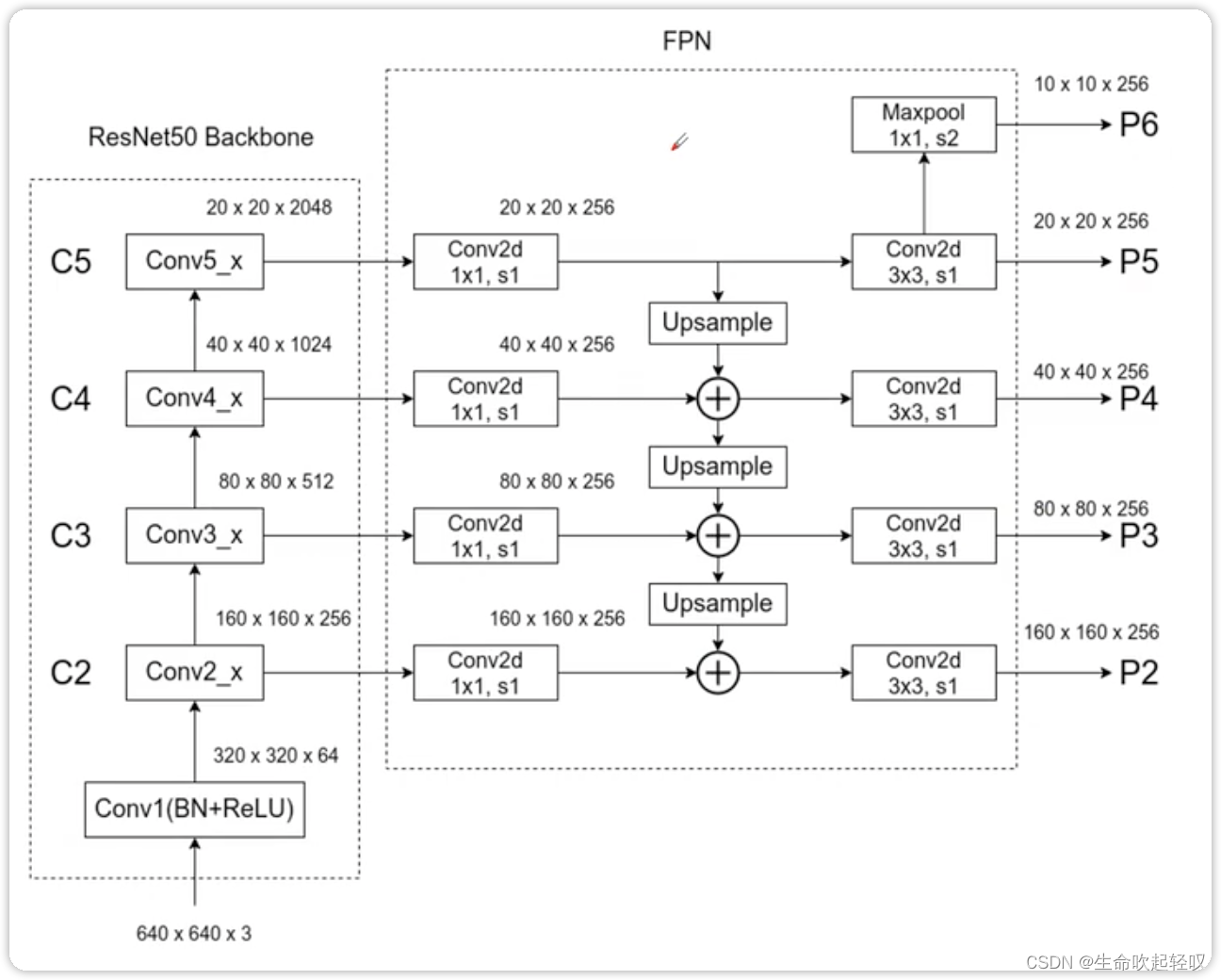
如上图所示,有一个6406403的RGB3通道图像,通过ResNet50 Backbone生成C2,C3,C4,C5不同大小的特征图(从下往上依次为2倍大小),然后对这些特征图使用1*1的卷积层来调整channel。C5在卷积之后,进行上采样与C4进行融合,然后继续上采样,与C3进行融合…这就是自上而下的路径和横向连接。
在得到新的特征图之后,再接上3*3的卷积层,得到P2,P3,P4,P5,对于P5进行下采样得到P6(最大池化)。注意的是,P6只用于RPN部分,RPN在生成proposal时会在P2-P6进行预测,而Fast-RCNN只在P2-P5进行预测,P6不在其中使用。也就是说,我们通过RPN在P2-P6上预测proposal,然后将proposal映射到P2-P5上,最后通过Fast-RCNN部分得到最终的预测结果。
由于我们生成了不同层次的特征图,因此我们可以在不同预测特征层上分别针对不同尺度的目标进行预测。例如P2是底层的特征层,因此会保留更多底层的细节信息,所以适合预测小型目标,生成32*32,比例为1:2,1:1,2:1的anchor;越往上,预测的目标也就越大。
不仅如此,经过作者实验,针对不同的预测特征层,RPN和Fast RCNN的权重可以共享,不仅减小了网络的参数,其效果也没有明显变化。
以上就是FPN的理论结构及部分细节。















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









