






论文链接:https://opendrivelab.com/e2ead/AD23Challenge/Track_3_NVOCC.pdf?=&linkId=100000205404832
github地址:https://github.com/NVlabs/FB-BEV
一:模型机构设计:
1.基于3D检测方法(FB-BEV);
2.Forward Projection(参考LSS)+
Backward Projection(参考BEVFormer)
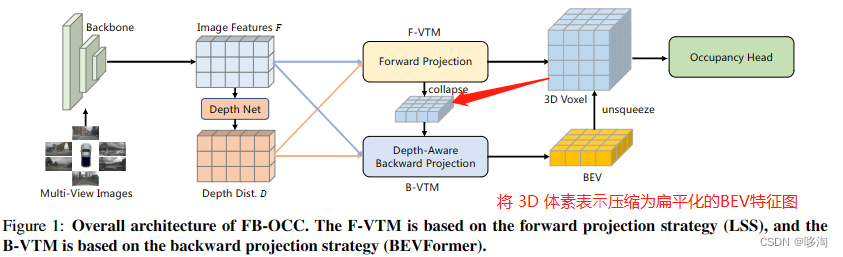
Forward Projection:
1)使用前向投影来生成3D体素表示
2)将 3D 体素表⽰压缩为扁平化的BEV特征图
3)最后将 3D 体素表⽰和优化的 BEV 表⽰的融合特征输⼊到后续任务头中
前向投影总结:相对原来的LSS是投影到BEV空间中,这里是投影到3D体素空间中
Backward Projection:
1)3D体素表⽰压缩为BEV表示,从⽽结合更强的语义
2)利⽤了投影阶段的深度分布,能够更精确地建模投影关系
后向投影总结:灵感来源于BEVFormer,
1.与使⽤随机初始化参数作为 BEV 查询的 BEVFormer 不同,采用1);
2.在推理阶段使用了深度分布,从而保证了更加精确的
最后获得3D体素表示和优化后的BEV表示后,
通过扩展BEV特征的过程将他们组合起来,
从而产生最终的3D体素表示
图一图二中展示了体素编码器和占用预测头
二:损失函数:
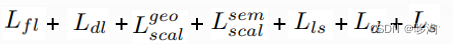
Lfl :距离感知焦距损失函数
Ldl:语义分割深度分析损失函数
Lgeo scal/Lsem scal:
来自MonoScene的亲和力损失函数
Lls:lovasz-softmax损失函数
Ld:深度监督损失
Ls :2D语义损失
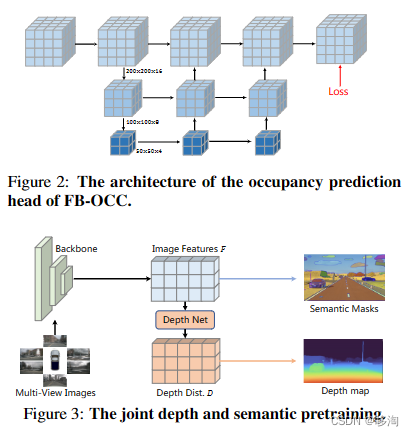
三:扩大模型和预训练:
1)作者花了大段时间介绍大模型的过拟合的劣势还有计算复杂度的问题,综合评比下来,选用了1B参数的backbone,interimage-H;
2)此模型用于nuScenes中直接应用会有严重的过度拟合,利用比赛提供的public data做与训练
3)在Object365数据集上进行2D检测任务的与训练,用于增强模型的语义感知能力
4)为了增加深度感知,和减轻模型过度偏向深度信息的风险,导致语义丢失,在nuScenes数据集上进行深度估计的预训练,用来增强模型的几何感知能力
5)考虑到nuScenes数据集不提供2D图像语义标签,使用SAM模型生成
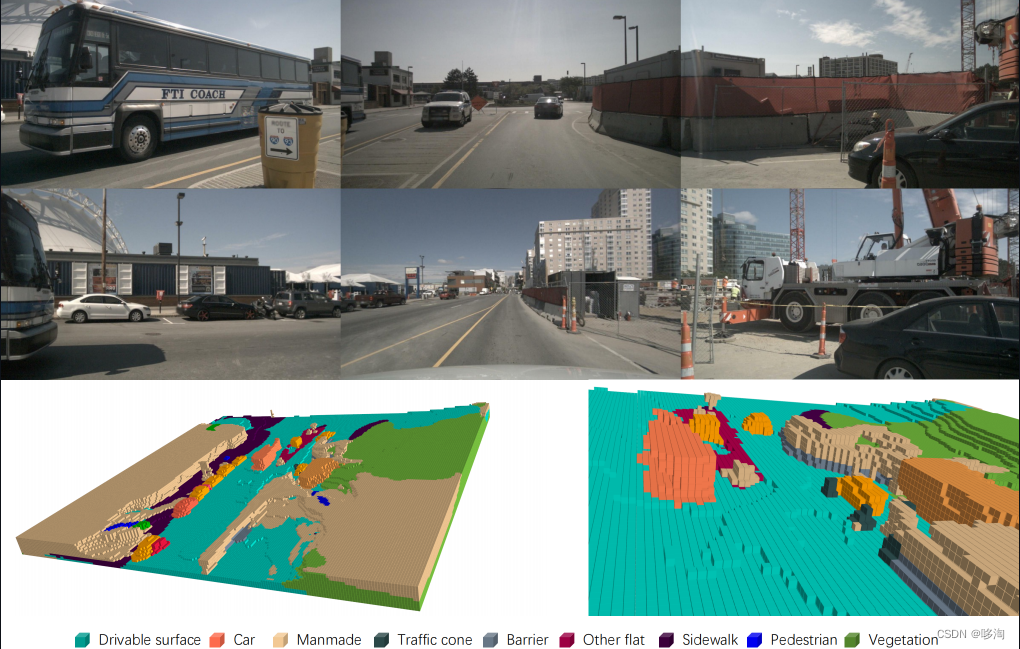
四:实验结果:
见图5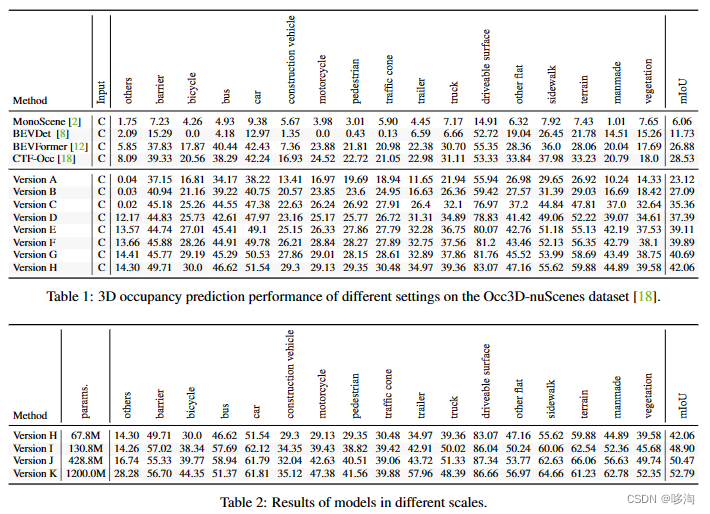
字数限制,暂且分享这多么,欢迎相互沟通学习















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









