







 本文介绍了一种名为3DOPFormer的新方法,利用空间交叉注意力和反卷积技术,结合激光雷达射线方向特征,实现对多摄像头图像的3D占用感知。通过神经渲染和优化损失函数,模型在nuScenes数据集上表现出色,尤其在穿透体素的准确度上有显著提升。
本文介绍了一种名为3DOPFormer的新方法,利用空间交叉注意力和反卷积技术,结合激光雷达射线方向特征,实现对多摄像头图像的3D占用感知。通过神经渲染和优化损失函数,模型在nuScenes数据集上表现出色,尤其在穿透体素的准确度上有显著提升。
【论文笔记】3DOPFormer: 3D Occupancy Perception from Multi-Camera Images with Directional and Distance Enhancement
原文链接:https://ieeexplore.ieee.org/abstract/document/10363646
I. 引言
本文的3DOPFormer使用空间交叉注意力机制和反卷积恢复3D占用,然后基于激光雷达射线方向特征提出优化3D占用感知模型的新方法。使用神经渲染方法合成激光雷达射线方向的距离,通过最小化合成距离与原始点云距离之间的损失,使模型生成精确的占用预测。通过插值可以得到任意3D点的特征,从而预测任意分辨率下的3D场景占用。
III. 方法
A. 准备知识
本节介绍了NeRF的体积渲染公式,见神经辐射场的简单介绍。
在粗糙采样的基础上,还可进行细化采样,即根据粗糙采样的权重分布采样新的点,再将粗糙采样点与细化采样点一起用于计算渲染结果。损失函数为粗糙采样渲染结果光度损失与细化采样渲染结果光度损失的均值。
对于激光雷达距离合成,将上述渲染公式中的RGB值替换为距离即可。由于点的距离是采样得到,需要预测的仅有 σ \sigma σ,因此可改为直接预测不透明度 α \alpha α:
d ^ = ∑ i = 1 N T i α i t i T i = ∑ j = 1 i − 1 ( 1 − α j ) α i = F ( x i ) \hat{d}=\sum_{i=1}^NT_i\alpha_it_i\\T_i=\sum_{j=1}^{i-1}(1-\alpha_j)\\\alpha_i=F(x_i) d^=i=1∑NTiαitiTi=j=1∑i−1(1−αj)αi=F(xi)
其中 F F F为3D占用感知模型(见后文)。
B. 概述
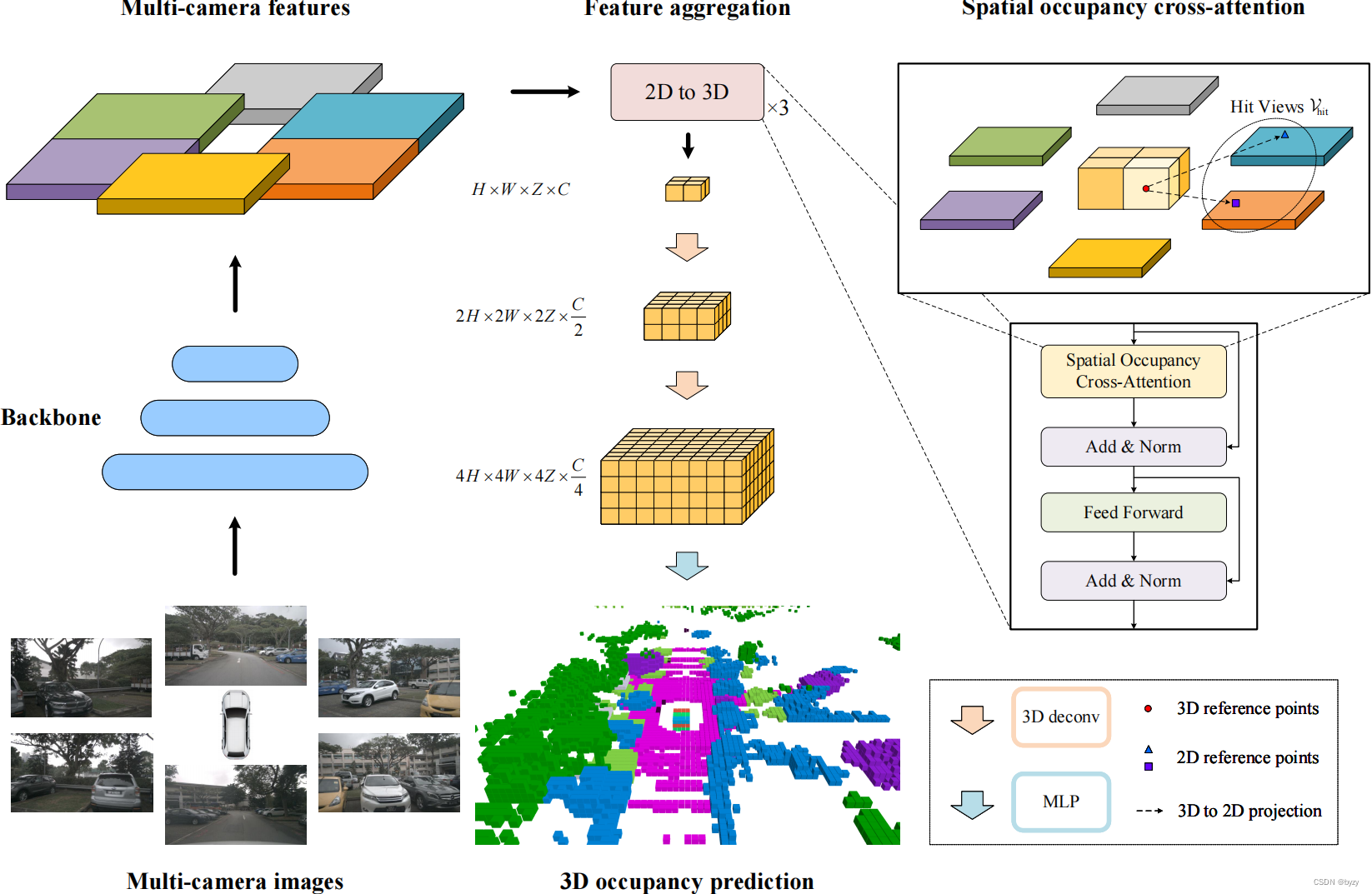
如上图所示,首先用主干网络提取图像特征,并使用空间注意力提升到3D空间得到 V i ∈ R H × W × Z × C V_i\in\mathbb{R}^{H\times W\times Z\times C} Vi∈RH×W×Z×C,并使用3D反卷积得到更高分辨率的3D体素特征。最后,使用MLP预测3D占用结果。
C. 3D占用感知查询
定义可学习参数 Q ∈ R H × W × Z × C Q\in\mathbb{R}^{H\times W\times Z\times C} Q∈RH×W×Z×C(与初始3D体素 V i V_i Vi大小相同)。位于网格 p = ( x , y , z ) p=(x,y,z) p=(x,y,z)处的查询为 Q p ∈ R C Q_p\in\mathbb{R}^C Qp∈RC。
D. 空间占用交叉注意力
本文使用可变形注意力以减小计算,其中3D体素查询与2D图像特征中的相应区域的特征交互。
首先将查询 Q p Q_p Qp投影到图像上,采样附近的图像特征,然后按下式得到 V i V_i Vi:
S O C A ( Q p , F ) = 1 ∣ V h i t ∣ ∑ i ∈ V h i t D A ( Q p , P ( p , i ) , F i ) D A ( q , p , x ) = ∑ i ′ = 1 N h e a d W i ′ ∑ j ′ = 1 N k e y A i ′ j ′ W i ′ ′ x ( p + Δ p i ′ j ′ ) SOCA(Q_p,F)=\frac{1}{|\mathcal{V}_{hit}|}\sum_{i\in\mathcal{V}_{hit}}DA(Q_p,\mathcal{P}(p,i),F^i)\\DA(q,p,x)=\sum_{i'=1}^{N_{head}}W_{i'}\sum_{j'=1}^{N_{key}}A_{i'j'}W'_{i'}x(p+\Delta p_{i'j'}) SOCA(Qp,F)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











