







Real-Time 3D Occupancy Prediction via Geometric-Semantic Disentanglement
原文链接:https://arxiv.org/abs/2407.13155
简介:通过分析现有方法的速度和存储消耗,本文发现同时实现高精度和高速度的挑战来自几何和语义的强耦合。本文提出混合BEV-体素表达的几何-语义双分支网络(GSDBN)(模型上解耦),其中BEV分支包括BEV时间融合模块和UNet解码器,以提取密集语义特征;体素分支则使用大核重参数化3D卷积细化稀疏3D体素并减小计算。此外,还提出BEV-体素提升模块,将BEV特征投影到体素空间进行融合。本文还提出**几何-语义解耦学习(GSDL)**策略(训练上解耦),初始使用真实深度学习带精确几何的语义,后逐渐融入预测深度,使模型预测几何。本文的模型为GSD-Occ,能达到sota性能和实时速度。
1. 整体结构
几何-语义解耦的占用预测器(GSD-Occ)如图所示,包括图像编码器、2D到3D视图变换、几何-语义双分支网络、几何-语义解耦学习策略。
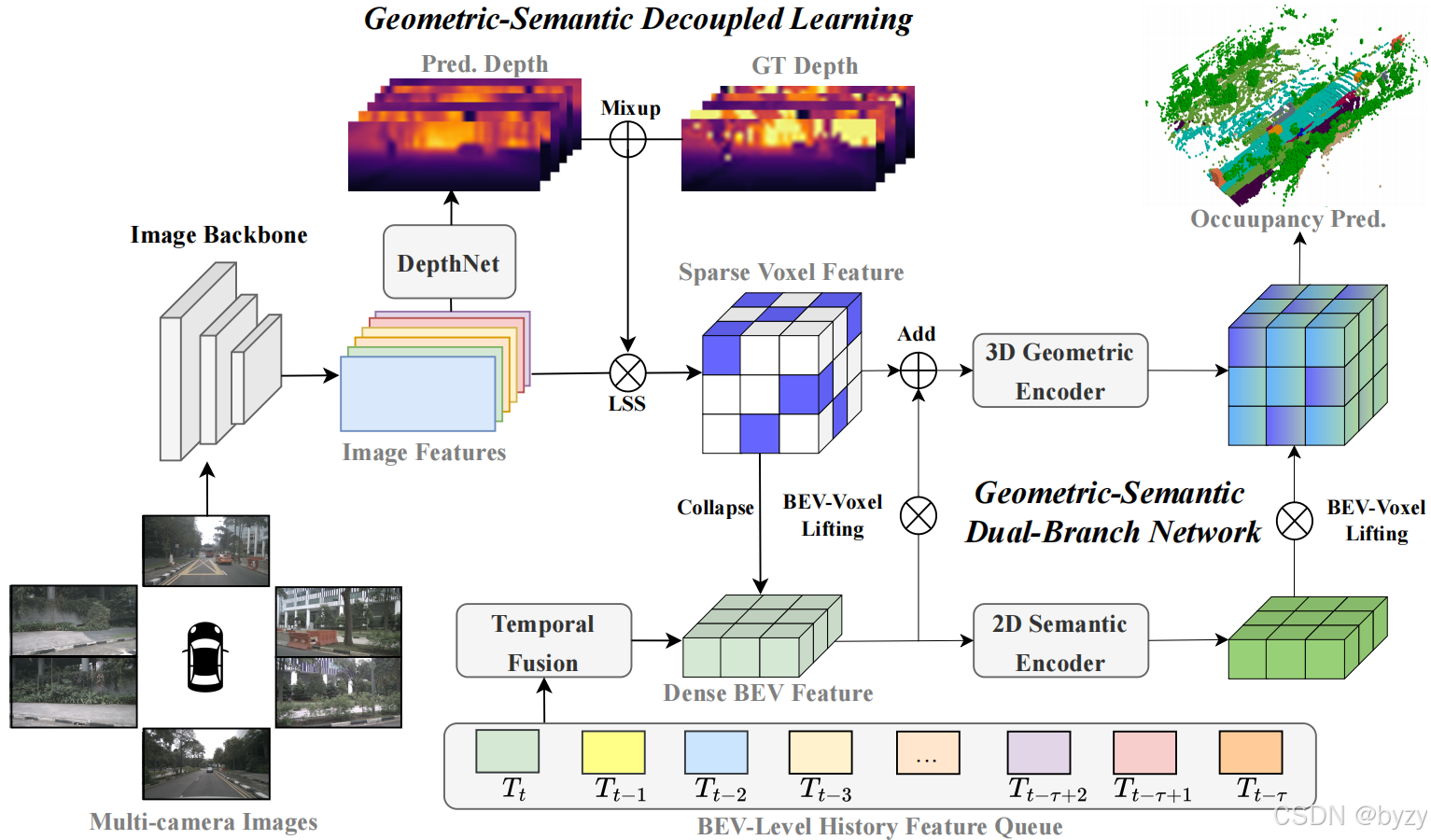
图像编码器:给定第 t t t帧的环视图像 I t = { I i , t ∈ R H × W × 3 } i = 1 N c I_t=\{I_{i,t}\in\mathbb R^{H\times W\times 3}\}_{i=1}^{N_c} It={
Ii,t∈RH×W×3}i=1Nc,使用预训练的主干提取图像特征 F = { F i ∈ R C F × H F × W F } i = 1 N c F=\{F_i\in\mathbb R^{C_F\times H_F\times W_F}\}_{i=1}^{N_c} F={
Fi∈RCF×HF×WF}i=1Nc。 N c N_c Nc为视图数量。
2D到3D视图变换:使用带深度监督的显式视图变换方法,将2D图像特征 F F F转化为体素表达。首先将 F F F送入深度网络预测深度分布 D = { D i ∈ R D b i n × H F × W F } D=\{D_i\in\mathbb R^{D_{bin}\times H_F\times W_F}\} D={ Di∈RDbin×HF×WF},其中 D b i n D_{bin} Dbin为深度区间数。伪点云特征 P ∈ R N c D b i n H F W F × C F P\in\mathbb R^{N_cD_{bin}H_FW_F\times C_F} P∈RNcDbinHFWF×CF可由外积 F ⊗ D F\otimes D F⊗D得到。最后使用体素池化得到体素特征 V ∈ R C F × X 2 × Y 2 × Z 2 V\in\mathbb R^{C_F\times \frac X2\times \frac Y2\times \frac Z2}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











