







Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers
原文链接:https://arxiv.org/abs/2312.09147
简介:目前单图像重建的流行方法是生成模型(包括基于分数蒸馏采样的方法和3D扩散模型),但其训练和优化的时间较长。本文提出通过前馈推断的单视图重建方法,能有效生成3D模型。方法使用两个基于Transformer的网络,即点解码器和三平面解码器,使用混合三平面-高斯中间表达重建3D物体。这种混合表达能比隐式表达有更快的渲染速度,且比显式表达有更高的渲染质量。点解码器从单图像生成点云,为三平面解码器提供显式表达,以查询每个点的高斯特征。这样的设计解决了直接回归3D高斯属性的困难。最后,3D高斯被MLP解码,并通过溅射进行快速渲染。
0. 概述
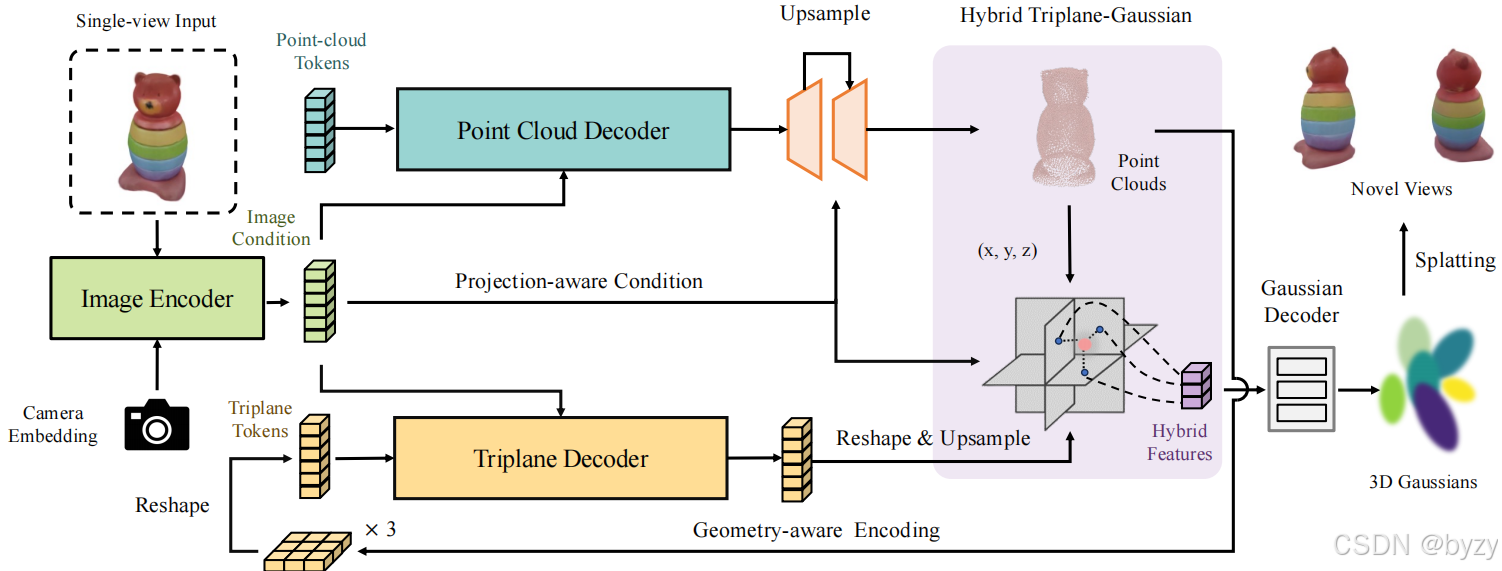
本文引入混合3D表达,将显式的点云几何和隐式的三平面特征组合,从而实现不牺牲质量的高效渲染。使用基于Transformer的点云解码器从图像特征预测粗糙点,并上采样为密集点云。随后,三平面解码器将点和图像特征转化为三平面特征。最后,混合三平面-高斯特征使用点云、三平面与投影的图像特征,生成混合特征解码3D高斯属性。最后,通过可微溅射,可高效地、端到端地在大型、未知物体类别的数据集上训练模型。
1. 混合三平面-高斯
直接在现有的点云重建或生成模型中加入其它3D高斯属性,直接预测3D高斯是不可行的。这可能是3D高斯离散、非结构化和高维的特性阻碍了学习。本文使用三平面-高斯这一混合3D表达,能实现高质量、快速和可泛化的渲染。
混合表达包括提供显式几何的点云
P
∈
R
N
×
3
P\in\mathbb R^{N\times 3}
P∈RN×3和编码隐式特征场的三平面
T
∈
R
3
×
C
×
H
×
W
T\in\mathbb R^{3\times C\times H\times W}
T∈R3×C×H×W,可从其中解码3D高斯属性。三平面
T
T
T包含了三个轴对齐的正交特征平面
{
T
x
y
,
T
x
z
,
T
y
z
}
\{T_{xy},T_{xz},T_{yz}\}
{Txy,Txz,Tyz}。对任一位置
x
x
x,可通过投影到三平面上并使用三线性插值从三平面查询相应的特征向量:
f
t
=
i
n
t
e
r
p
(
T
x
y
,
p
x
y
)
⊕
i
n
t
e
r
p
(
T
x
z
,
p
x
z
)
⊕
i
n
t
e
r
p
(
T
y
z
,
p
y
z
)
f_t=interp(T_{xy},p_{xy})\oplus interp(T_{xz},p_{xz})\oplus interp(T_{yz},p_{yz})
ft=interp(Txy,pxy)⊕interp(Txz,pxz)⊕interp(Tyz,pyz)
其中interp为三线性插值, ⊕ \oplus ⊕为拼接(concat)操作, p p p为投影的位置。
这里是2D点在平面上的特征采样,应该是双线性插值。
3D高斯解码器。对点云
P
P
P中的给定位置
x
∈
R
3
x\in\mathbb R^3
x∈R3,从三平面查询特征
f
f
f并使用MLP
ϕ
g
\phi_g
ϕg从点云解码3D高斯。3D高斯的属性包括不透明度
α
\alpha
α,各向异性协方差(由尺度
s
s
s和旋转
q
q
q表示),以及球面谐波(SH)系数
s
h
sh
sh:
(
Δ
x
′
,
α
,
s
,
q
,
s
h
)
=
ϕ
g
(
x
,
f
)
(\Delta x',\alpha,s,q,sh)=\phi_g(x,f)
(Δx′,α,s,q,sh)=ϕg(x,f)
由于表面点不是最优的3D高斯表达,还额外预测小的位置偏移量 Δ x \Delta x Δx。最终位置为 x = x + Δ x x=x+\Delta x x=x+Δx。
参考PC2模型,本文还额外为查询的三平面特征 f t f_t ft附加投影的图像特征 f l f_l fl,作为上式的 f f f。给定相机姿态 π \pi π和点云 P P P,局部投影特征可通过投影函数 P \mathcal P P得到: f l = P ( π , P ) f_l=\mathcal P(\pi,P) fl=P(π,P)。为考虑点云的自遮挡问题,通过点的栅格化实现投影。局部特征包括RGB颜色、DINOv2的特征、掩膜和相应于掩膜区域的2D距离变换。这种投影感知的条件可提高输入视角下的纹理质量。
渲染。基于上述表达,可使用高斯溅射渲染方法进行任意视角的图像渲染。
2. 从单视图图像重建
本文使用两个基于Transformer的解码器,分别从图像重建点云 P P P和三平面 T T T。在点云的上采样过程中,同样使用了投影的图像特征,从而促进初始点云的重建。
图像编码器。使用预训练的、基于ViT的模型(如DINOv2)获取逐patch的特征token。使用自适应层归一化(adaLN)和相机特征来调制DINOv2特征。最后,基于每个归一化层后的相机特征,使用MLP预测缩放和偏移量。相机调制层可使图像特征感知视角,从而更好地指导点云网络和三平面网络。
个人理解:根据图示可推测相机特征为“相机嵌入”即相机参数的编码,使用该特征预测adaLN的 γ \gamma γ和 β \beta β进行归一化。
Transformer主干。使用特征token { f i } p \{f_i\}_p {fi}p和 { f i } t \{f_i\}_t {fi}t分别作为点云和三平面的隐token。这些隐token从可学习位置编码初始化,并输入Transformer块。每个Transformer块包括自注意力、交叉注意力和前馈网络。交叉注意力由视角增强的图像token指导。
点云解码器。点云反映了物体的粗糙几何,3D高斯可基于点云位置生成。使用图像条件,从点云token(可学习位置编码)中解码点云,每个隐token视为一个点。为节省计算和存储资源,仅解码2048个点。
根据图示,“图像条件”是图像编码器的输出,应该用于交叉注意力中。
投影感知调节的点上采样。由于新视图合成的质量受高斯数量的影响,本文使用带有两步Snowflake点反卷积(SPD)的提升模块密集化点云,得到16384个点。Snowflake使用从输入点云中提取的全局形状编码和点特征,以预测上采样点的偏移量。本文还通过PC2模型中的投影感知条件,为SPD的全局形状编码引入局部图像特征,使生成的点云与输入图像对齐。
带几何感知编码的三平面解码器。基于初始点云和图像,三平面解码器输出隐式特征场,从中可通过位置查询解码3D高斯属性。除了可学习位置编码外,还将点云编码加入初始位置编码,实现更好的几何感知。具体来说,点同样增加了输入图像的投影特征,并送入带有局部池化的浅层PointNet,并正交投影到三平面上。投影到同一token位置的特征被均值池化,并加上位置编码。
3. 训练
使用2D渲染损失和3D点云监督:
L
=
λ
c
L
C
D
+
λ
e
L
E
M
D
+
1
N
∑
i
=
1
N
(
L
M
S
E
+
λ
m
L
M
A
S
K
+
λ
s
L
S
S
I
M
+
λ
l
L
L
P
I
P
S
)
L=\lambda_cL_{CD}+\lambda_eL_{EMD}+\frac1N\sum_{i=1}^N(L_{MSE}+\lambda_mL_{MASK}+\lambda_sL_{SSIM}+\lambda_lL_{LPIPS})
L=λcLCD+λeLEMD+N1i=1∑N(LMSE+λmLMASK+λsLSSIM+λlLLPIPS)
其中 L C D L_{CD} LCD为Chamfer距离(CD), L E M D L_{EMD} LEMD为推土机距离(EMD)。为训练三平面解码器和3D高斯解码器,使用渲染损失,包括逐像素的MSE损失 L M S E = ∥ I − I ^ ∥ 2 2 L_{MSE}=\|I-\hat I\|_2^2 LMSE=∥I−I^∥22,掩膜损失 L M A S K = ∥ M − M ^ ∥ 2 2 L_{MASK}=\|M-\hat M\|_2^2 LMASK=∥M−M^∥22,SSIM损失 L S S I M L_{SSIM} LSSIM和感知损失 L L P I P S L_{LPIPS} LLPIPS。
CD和EMD应该是预测点云和真实点云之间的损失。实验部分提到,对于缺乏3D模型的数据集,可使用高斯溅射方法得到伪点云作为监督。
实施细节:三平面解码器的token数量为 3 × 32 × 32 3\times32\times32 3×32×32。训练时分两阶段:首先使用CD损失和EMD损失训练点云解码器,随后固定点云解码器,训练三平面解码器和高斯解码器。实验表明,几何感知编码可减轻分开训练造成的点云与隐式特征场不对齐的问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











