






目录
1.Level 1:Text Splitters - CharacterTextSplitter
2.Level 2:Text Splitters - RecursiveCharacterTextSplitter
3.Level 3:Text Splitters - MarkdownTextSplitter
4.Level 4:Text Splitters - SemanticChunker
6.Level 5:Text Splitters - AI21SemanticTextSplitter
7.Level 6:Text Splitters - SegTextSplitter
分享的是现在rag优化方面关于文档切分的算法的洞察。选择这方面的一个原因,就是在rag的优化模块中:
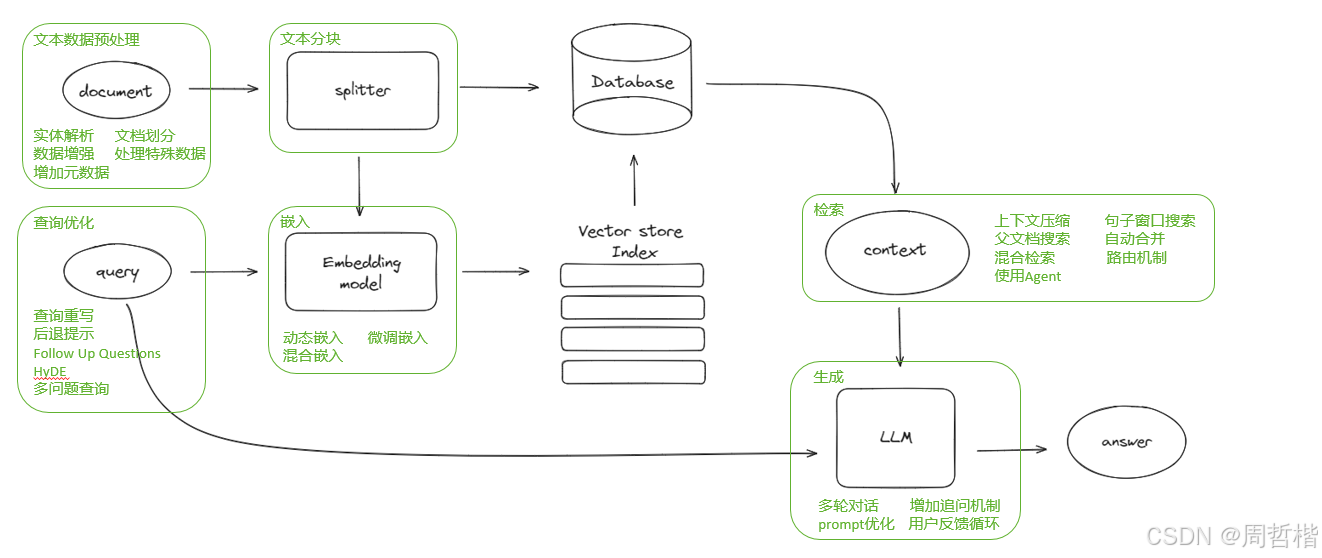
文档预处理环节,包括识别、增强文档规律划分、数据增强等操作,以提升文档质量。其次,查询优化,包括查询重写和后续提示等优化功能等等,我个人觉得现在这些优化的一些东西,都是一些锦上添花的操作,现在可能真正出现一些问题的地方,在我们实际的运行过程中可能是在文档切分、文本分块的,现在效果不是特别好,目前网上的算法比较有限,导致整体功能实现和使用的效果并未达到理想状态。因此,需要对算法思路进行调整,以提升文本分割的效果和速度。
从一个从最简单然后到复杂的一个思路,来去看一下我们现在这个切分算法:
前五种参考了langchain和文档切分解析
关于chunk_size和overlap可以参考上述链接,这里不过多赘述了。

1.Level 1:Text Splitters - CharacterTextSplitter
按字符拆分。
字符分割是拆分文本的最基本形式。它是将文本简单地分成 N 个字符大小的块的过程,而不管其内容或形式如何。
俗称的硬拆分。

2.Level 2:Text Splitters - RecursiveCharacterTextSplitter
参考:
按分隔符拆分
“\n\n” —— 双换行符,或最常见的段落换行符
“\n” —— 新行
“.”/“。” —— 结束符
Recursive的概率,在使用“\n\n” 分割后若块大小任然大于给定的chunk_size,就使用“\n” 继续分割,若扔大于,继续使用标点符号分割。
3.Level 3:Text Splitters - MarkdownTextSplitter
文档特定拆分
比如在Markdown中
\n#{1,6} - 用新行分隔,后跟标题(H1 至 H6)
```\n - 代码块
\n\\*\\*\\*+\n - 水平线
\n---+\n - 水平线
\n___+\n - 水平线
\n\n - 双换行
\n - 新行
“ ” - 空格
Python/JS等等特定格式的数据文档

4.Level 4:Text Splitters - SemanticChunker
比如对于一段文字:
想要创业吗?获得Y Combinator 的资助。 2006 年 10 月(本文源自麻省理工学院的一次演讲)。
直到最近,即将毕业的大四学生都面临两个选择:找工作或去读研究生。
我认为将会有越来越多的第三种选择:\n创办自己的创业公司。
在每个融资周期大约一个月后,我们会举办一场名为“原型日”的活动。
在活动上,每家初创公司都会向其他初创公司展示他们目前所取得的成就。
您可能认为他们不需要任何进一步的激励。
告诉人们不要这样做?原因与那位可能不为人知的小提琴家相同,
每当他被要求评判某人的演奏时,他总是说他们没有足够的天赋成为职业选手。
分块机制应考虑实际内容和语义信息
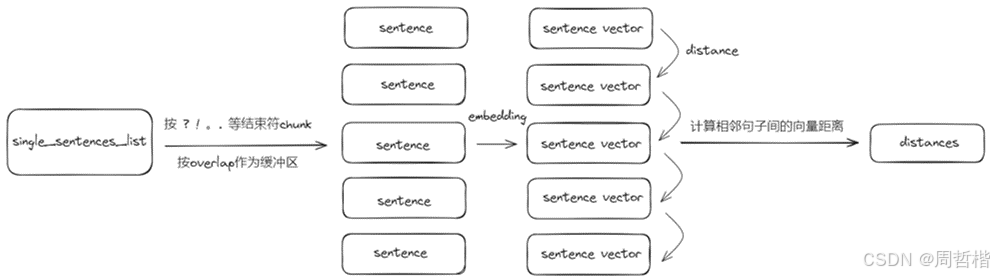
得到相邻语句之间的向量距离:
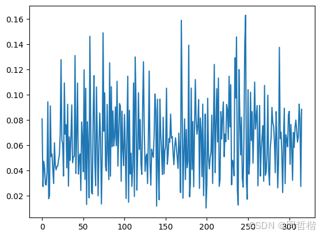
把任何超过 over_distance 的距离视为断点,假如这里设置为95%
最终的效果是:
想要创业吗?获得Y Combinator 的资助。 2006 年 10 月(本文源自麻省理工学院的一次演讲)。
直到最近,即将毕业的大四学生都面临两个选择:找工作或去读研究生。
我认为将会有越来越多的第三种选择:\n创办自己的创业公司。
在每个融资周期大约一个月后,我们会举办一场名为“原型日”的活动。
在活动上,每家初创公司都会向其他初创公司展示他们目前所取得的成就。
您可能认为他们不需要任何进一步的激励。
告诉人们不要这样做?原因与那位可能不为人知的小提琴家相同,
每当他被要求评判某人的演奏时,他总是说他们没有足够的天赋成为职业选手。
最后获得的分块看上去已经初步达到我们想要的效果了。
5.Text Splitters产生的问题
在许多文档中,很有可能会出现相似的语义片段,这些语义片段在embedding的时候造成了语义的冗余,并且的topk检索时很有可能由于冗余从而检索不到实际有用的语义信息:

例如安装的语义片段,在一篇使用手册中可能会重复出现多次,如果作为不同的语义块存入数据库,在检索时会将这些相同的归为多个topk从而减少了检索的语义信息。
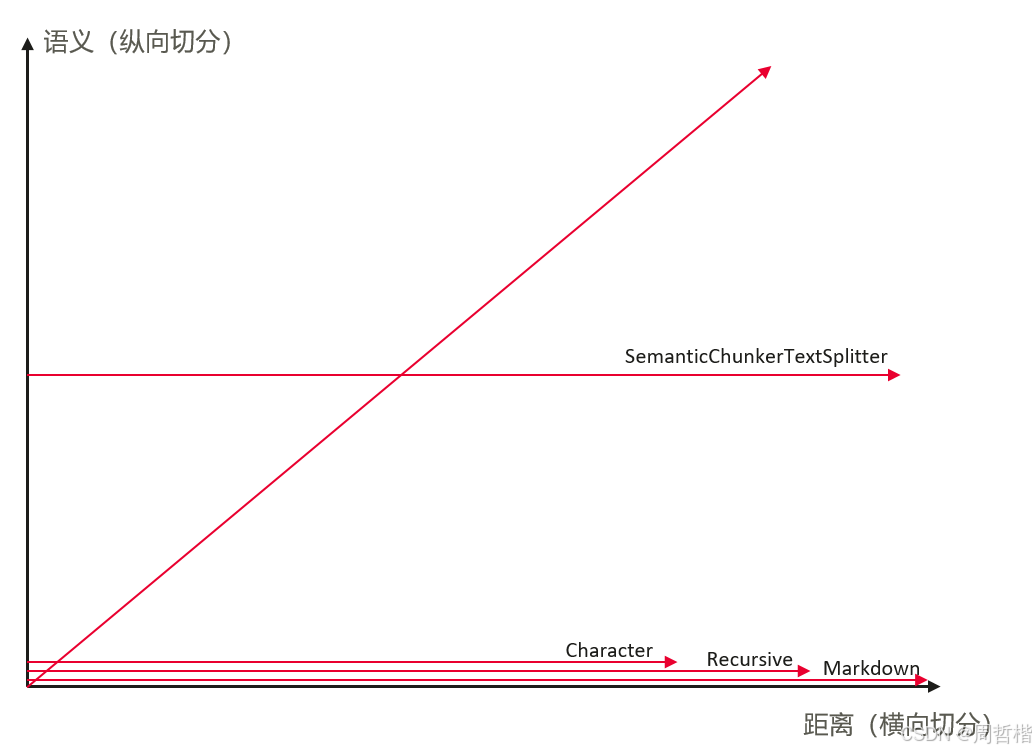
所以切分中不只是切分相邻距离句子间的语义情况,还应该对整篇文章中纵向得来切分语义。
这里提出一个横纵向切分的概念
横向:基于句子之间的相邻距离做切分
纵向:基于语义的相邻距离做切分
切分并不只是横向的,还需要考虑的纵向,现在的splitter都没有考虑到纵向的切分
6.Level 5:Text Splitters - AI21SemanticTextSplitter
参考:AI21SemanticTextSplitter | 🦜️🔗 LangChain
首先Langchain的AI21SemanticTextSplitter并未开源,这里是结合发布的视频以及文档做的一些归纳。
在SemanticChunker基础上,我们已经获得了段落的结构信息,现在要做的就是对这些段落进行聚类,使得在语义上得以延伸。
Langchain怎么做的:
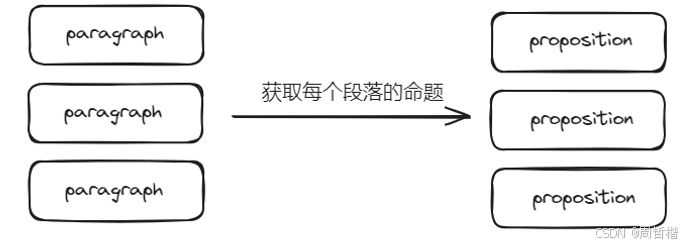
将现存的所以的语义块全部递给大模型做一次归纳,获取每一个语义块的命题:
['月份是十月。',
'年份是 2023 年。',
'我小时候并不了解绩效回报的超线性程度。',
'绩效回报是超线性的。',
'了解绩效回报的超线性程度是最重要的事情之一。',
'老师和教练含蓄地告诉我们回报是线性的。’]
这里获取了6个命题
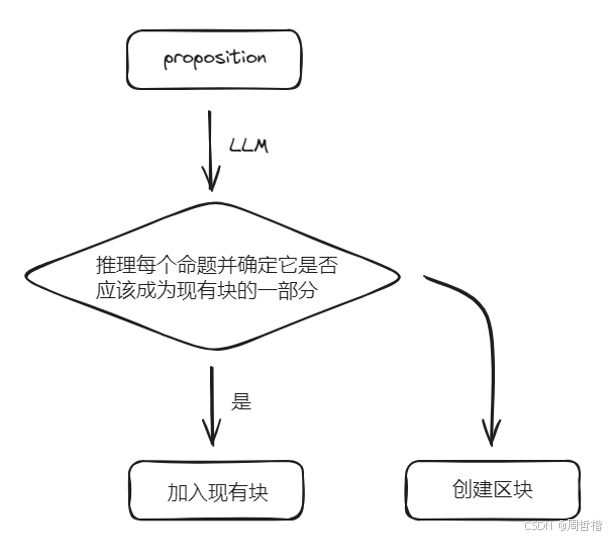
然后遍历所有语义块,并将其动态地聚类:
添加:“月份是十月。”
没有区块,创建一个新的
创建新块:日期和时间
添加:“今年是 2023 年。”
找到块,添加到:日期和时间
添加:“我小时候并不了解绩效回报的超线性程度。”
未找到块
创建新块:努力 - 奖励关系
添加:“绩效回报是超线性的。”
找到块,添加到:努力 - 奖励关系
添加:“了解绩效回报的超线性程度是最重要的事情之一。”
找到块,添加到:绩效的超线性回报
添加:“教师和教练含蓄地告诉我们回报是线性的。”
未找到块
创建新块:教育与辅导回报
最后可以得到两个区块:
块0
摘要:此块包含与当前月份和年份相关的特定日期和时间的信息。
命题:
-月份是十月。
-年份是 2023 年。
块1
摘要:此块讨论了不同行业的超线性回报概念及其对理解经济、社会和个人成长动态的影响。
命题:
-我小时候并不了解绩效回报的超线性程度。
-绩效回报是超线性的。
-了解绩效回报的超线性程度是最重要的事情之一。
-商业中的绩效回报是超线性的。
-有些人认为商业中的超线性回报是资本主义的缺陷。
-有些人认为改变规则会阻止商业中的超线性回报成为现实。
-绩效的超线性回报是世界的一个特征。
-绩效的超线性回报不是人类发明的规则的产物。
-名望中也能看到同样的超线性回报模式。
-权力中也能看到同样的超线性回报模式。 -
军事胜利中也能看到同样的超线性回报
模式。 -知识中也能看到同样的超线性回报模式。 -
造福人类中也能看到同样的超线性回报模式。
-在所有这些领域,富人越来越富。
-如果不理解超线性回报的概念,就无法理解世界。
-如果你有野心,你就应该理解超线性回报的概念。
-理解超线性回报的概念将成为有野心人士冲浪的浪潮。
这样的问题是,有的块太过臃肿,同时冗余信息太多,且这种方法速度慢,成本高。
7.Level 6:Text Splitters - SegTextSplitter
提出一个全新的,理想中的聚类方式 - SegTextSplitter
我的想法是: 基于空间向量做聚类,聚类为区块后的结果统一进入LLM做归纳
每一个语义块embedding后作为一个点存在于向量空间中,在向量空间做基于欧式距离的聚类:
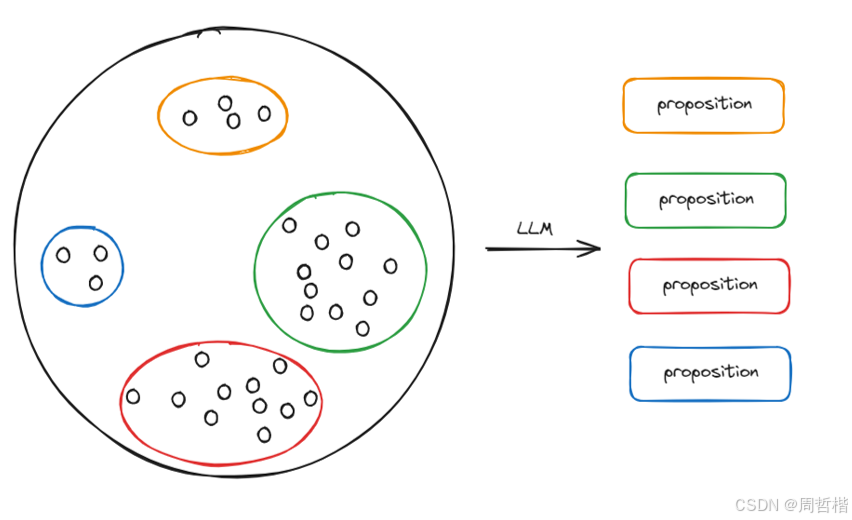
如何聚类:kmeans\dbscan?
Seg:自动寻找类别且由于生长限制不用担心臃肿
LLM:大模型最后进行总结,减少了复杂度且不用担心信息的冗余
这样上述语义冗余的块1:
块1
摘要:此块讨论了不同行业的超线性回报概念及其对理解经济、社会和个人成长动态的影响。
命题:
-我小时候并不了解绩效回报的超线性程度。
-绩效回报是超线性的。
-了解绩效回报的超线性程度是最重要的事情之一。
-商业中的绩效回报是超线性的。
-有些人认为商业中的超线性回报是资本主义的缺陷。
-有些人认为改变规则会阻止商业中的超线性回报成为现实。
-绩效的超线性回报是世界的一个特征。
-绩效的超线性回报不是人类发明的规则的产物。
-名望中也能看到同样的超线性回报模式。
-权力中也能看到同样的超线性回报模式。 -
军事胜利中也能看到同样的超线性回报
模式。 -知识中也能看到同样的超线性回报模式。 -
造福人类中也能看到同样的超线性回报模式。
-在所有这些领域,富人越来越富。
-如果不理解超线性回报的概念,就无法理解世界。
-如果你有野心,你就应该理解超线性回报的概念。
-理解超线性回报的概念将成为有野心人士冲浪的浪潮。
就可以在大模型的归纳下简化为:
介绍了超线性回报的概念,指出在不同行业和领域中,某些形式的绩效或回报并非线性增长,而是呈现出超线性增长趋势。
个人经历与理解:
作者小时候并未了解绩效回报的超线性性质,暗示这是一个个人认知的变迁和成长过程。
绩效回报的超线性性质:
绩效回报在商业中和其他领域中被指出是超线性的,即成功或回报的增长速度随着初始投入的增加而加速。
超线性回报的社会影响和看法:
一些人将商业中的超线性回报视为资本主义的缺陷,主张改变规则以遏制其现实化。
超线性回报在不同领域中的存在:
超线性回报模式不仅存在于商业中,还在名望、权力、军事胜利、知识和造福人类等领域中观察得到。
对超线性回报理解的重要性:
认为理解超线性回报的概念是理解世界运作的关键之一,特别是对于有野心的人士。
预示理解超线性回报的概念将成为有野心人士的必备知识,因其能够揭示出不同领域中成功和回报的非线性特性。
这样检索出来的信息不仅简洁且有效。

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









