【Python】科研代码学习:五 Data Collator,Datasets
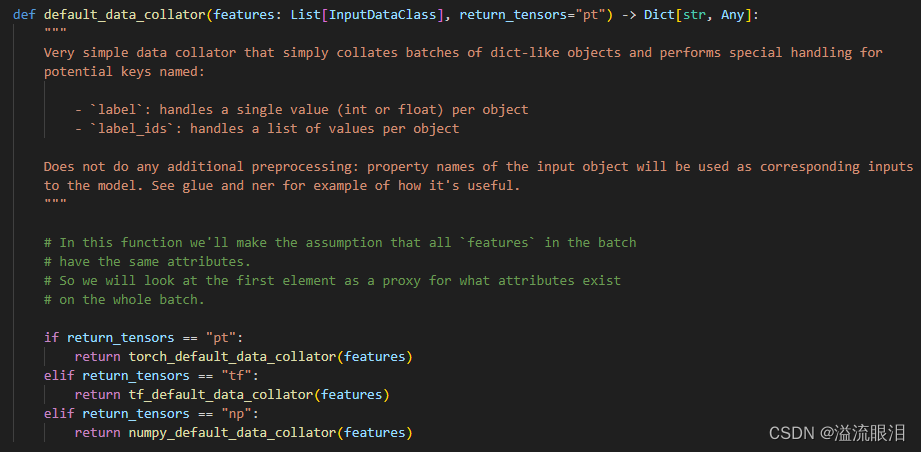
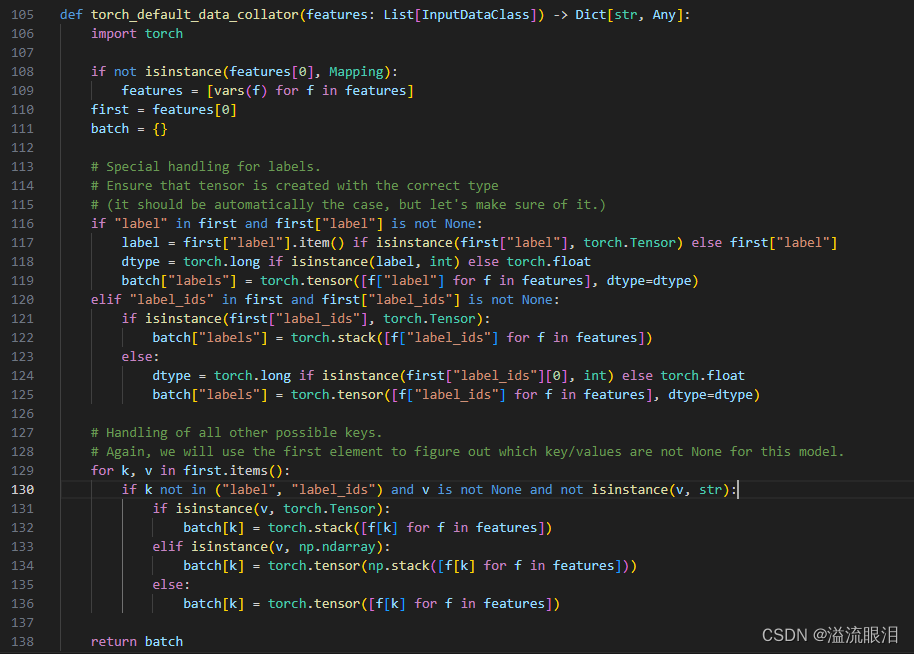
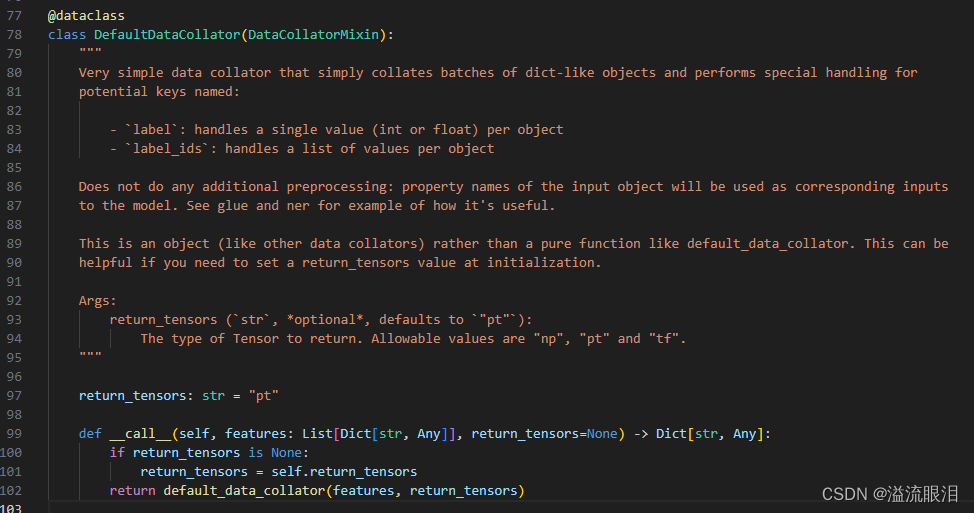
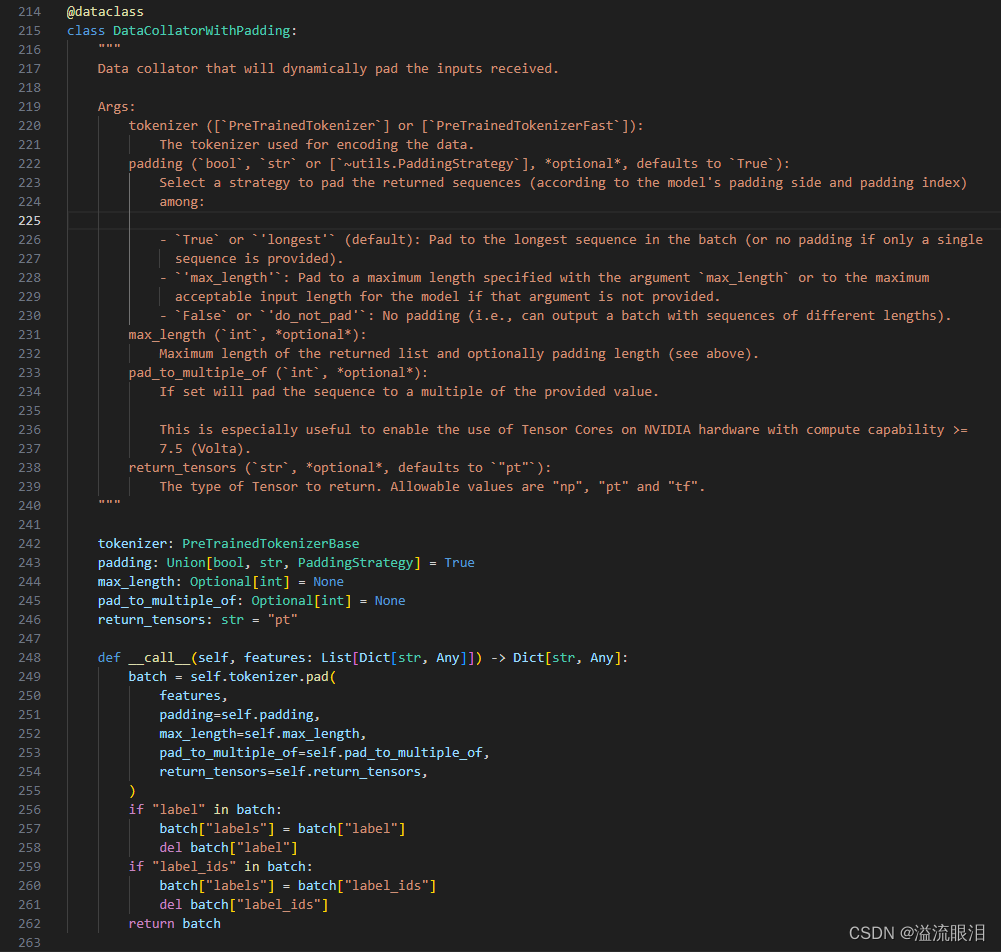
HF官网API:Data Collator Transformers源码阅读:transformers data_collator小记 提到输入训练集/验证集数据 ,就基本绕不开 Data Collator批处理(Batch) ,并转换成 train_dataset 和 eval_dataset 相同的数据类型 为了让它工作顺利,可能会做一些处理(padding / random masking) 但是我发现,在 Datasets 的一些API中,或者单独使用 Data Collator 的情况很少啊其作用主要是 给 Trainer 的初始化创建提供了一个 Data Collator,让 Trainer 在训练和评估的时候会自己去对数据进行批处理或特殊处理 下面看一下 Data Collator 里面的东西吧。 首先,它是一个方法,首先InputDataClass = NewType("InputDataClass", Any)pytorch / tensorflow / numpy 中的一个版本,大部分都是使用 pt 发现,首先他把 features 也就是输入通过 vars() 转成了字典 处理了标签 ,也就是 label 或 label_ids类型转换 ,输出打包为 Dict[str, Any] 上面是一个函数,这里是一个类(需要实例化) 如果不知道 Padding的,可以看一下后面的补充知识 这里看一下源码和参数含义tokenizer,以及 padding 策略。其他过程和上述 DefaultDataCollator 差不多。 知乎:LLM padding 细节 简单来说就是,输入经过词嵌入后,产生的 List[int] 词嵌入数组长度不一致,很难进行并行处理把所有数组长度统一到其中最长的那个数组长度 ,也就是其中添加 tokenizer.pad_token 即可。tokenizer(prompts, return_tensors="pt", padding=True) ,其中 attention_mask 中的 0 表示 padding 但是 padding 会增加无用字符,浪费训练资源,所以还有其他不用 padding 的训练方式。 其他的技术细节请参考上述知乎链接。 针对不同任务,也提供了不同的 Data Collator,看一眼吧:DataCollatorForTokenClassification:给token分类的DataCollatorForSeq2Seq:给s2s任务的DataCollatorForLanguageModeling:给LM用的,mlm 参数给 MLM任务使用DataCollatorForWholeWordMask:给LM用的,(used for language modeling that masks entire words)DataCollatorForPermutationLanguageModeling:给(permutation language modeling)用的 HF官网API:Datasets transformers 库里的,而这个是在 Datasets 库的从 HF 中加载与上传数据集,给 Audio,CV,NLP任务用途的。 它比较简单,最主要的方法也就是下面这个 来看一下源码path :数据集的名字 (请去HF中查找)或本地路径 (json, csv, text等格式)或数据集脚本 ( dataset script,一个py文件)split:默认 None,不划分训练集和测试集,最终直接返回一个 DatasetDict 。若指定 train / test / validation(这个真难找,图片在下方),则返回 Dataset 类型。data_dir:设置保存路径。 看一下例子: from datasets import load_dataset
ds = load_dataset( 'rotten_tomatoes' , split= 'train' )
data_files = { 'train' : 'train.csv' , 'test' : 'test.csv' }
ds = load_dataset( 'namespace/your_dataset_name' , data_files= data_files)
通过本地加载数据集,通过 csv / json / loading_script 加载 from datasets import load_dataset
ds = load_dataset( 'csv' , data_files= 'path/to/local/my_dataset.csv' )
from datasets import load_dataset
ds = load_dataset( 'json' , data_files= 'path/to/local/my_dataset.json' )
from datasets import load_dataset
ds = load_dataset( 'path/to/local/loading_script/loading_script.py' , split= 'train' )
如果通过自动下载后,可以使用下面方法来设置数据存储到本地目录save_to_disk 存到本地后,需要使用 load_from_disk 加载 dataset. save_to_disk( dataset_dict_path= './data/ChnSentiCorp' )
dataset = load_from_disk( './data/ChnSentiCorp' )
HuggingFace学习笔记(3) 数据集工具datasets dataset = dataset['train'] 可以直接获得其中的训练子集Dataset 内核和 pandas.dataframe 差不多索引 :ds[i] 取出第 i 条记录排序 :sorted_ds = ds.sort("colum_name")打乱 :shuffled_ds = ds.shuffle(seed=42)采样 :ds.select([0,10,11,...]) 表示拿出哪些记录训练测试集拆分 :ds.train_test_split(test_size=0.1),即9:1拆成训练集与测试集重命名列 :ds.rename_column('bef', 'aft')删除列 :ds.remove_columns(['colum_name'])过滤 :dataset.filter(func)def func ( data) :
return data[ 'text' ] . startswith( '非常不错' )
11)遍历修改 :new_ds = ds.map(func),这个比较常用 def f ( data) :
data[ 'text' ] = 'My sentence: ' + data[ 'text' ]
return data
12)批处理加速 :filter()、map()两个函数都支持批处理加速num_proc 表示使用的进程数。 maped_datatset = dataset. map ( function= f,
batched= True ,
batch_size= 1000 ,
num_proc= 4 )








 本文介绍了DataCollator在PyTorch和Transformer库中的角色,特别是DefaultDataCollator和DataCollatorWithPadding,它们在训练集中进行数据批处理、填充和标签处理。此外,还讨论了Padding的作用以及Datasets库在数据加载和处理中的功能,包括load_dataset函数和各种任务特定的DataCollator实现。
本文介绍了DataCollator在PyTorch和Transformer库中的角色,特别是DefaultDataCollator和DataCollatorWithPadding,它们在训练集中进行数据批处理、填充和标签处理。此外,还讨论了Padding的作用以及Datasets库在数据加载和处理中的功能,包括load_dataset函数和各种任务特定的DataCollator实现。


















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









