






本文作者来自韩国NAVER/LINE Vision
Abstract
先前基于深度学习的线段检测(LSD)受到庞大的模型尺寸和高计算成本的困扰,这限制了它们在计算资源受限的环境中进行实时推断。在本文中,我们提出了一种适用于资源受限环境的实时轻量级线段检测器,称为Mobile LSD(M-LSD)。我们通过最小化骨干网络并消除先前方法中常见的用于线段预测的典型多模块过程,设计了一种极其高效的LSD架构。为了保持与轻量级网络的竞争性能,我们提出了新颖的训练方案:线段分段(SoL)增强、匹配和几何损失。SoL增强将线段分成多个子部分,在训练过程中用于提供辅助线段数据。此外,匹配和几何损失允许模型捕捉额外的几何线索。与之前最佳的实时LSD方法TP-LSD-Lite相比,我们的模型(M-LSD-tiny)在模型尺寸方面只有2.5%的大小,并且在GPU上的推理速度增加了130.5%。此外,我们的模型在最新的Android和iPhone移动设备上分别以56.8 FPS和48.6 FPS的速度运行。据我们所知,这是首个可用于移动设备的实时深度LSD。
1. Introduction
线段和交叉点是低级视觉中至关重要的视觉特征,它们为高级视觉任务提供了基本信息,如姿态估计(Přibyl,Zemčı́k和Čadı́k 2017; Xu等,2016年),运动结构(Bartoli和Sturm 2005; Micusik和Wildenauer 2017年),三维重建(Denis,Elder和Estrada 2008; Faugeras等,1992年),图像匹配(Xue等,2017年),线框到图像的转换(Xue,Zhou和Huang 2019年)和图像矫正(Xue等,2019b年)。此外,在像移动设备或嵌入式设备等资源受限的平台上执行这些视觉任务的需求不断增长,这使得实时线段检测(LSD)成为一项重要但具有挑战性的任务。困难在于在找到最佳精度和资源效率的折衷方案以实现实时推理时,计算能力和模型尺寸有限。
随着深度神经网络的出现,基于深度学习的LSD架构采用了模型来学习线段的各种几何线索,并证明了性能的改进。如图2所示,我们总结了多种使用深度学习模型进行LSD的策略。自顶向下策略(Xue等,2019a)首先使用吸引场地图检测线段区域,然后将这些区域压缩成线段进行预测。相反,自底向上策略首先检测交叉点,然后将它们排列成线段,最后使用额外的分类器(Zhou,Qi和Ma 2019; Xue等,2020年; Zhang等,2019年)或合并算法(Huang和Gao 2019年; 黄等,2018年)验证线段。最近,(Huang等,2020年)提出了Tri-Points(TP)表示法,用于更简单地进行线预测,而无需耗时的线段建议和验证步骤。
尽管先前利用深度网络的努力取得了显著的成就,但在资源受限平台上进行LSD的实时推理仍然受到限制。已经尝试过提供实时LSD(Huang等,2020年; 孟等,2020年; Xue等,2020年),但它们仍然依赖于服务器级GPU。这主要是因为所使用的模型利用了重型骨干网络,例如扩张的基于ResNet50的FPN(Zhang等,2019年),堆叠的沙漏网络(Meng等,2020年; Huang等,2020年)和有孔残差U-net(Xue等,2019a)。这些模型需要大内存和高计算能力。此外,如图2所示,线预测过程包括多个模块,包括线段建议(Xue等,2019a; Zhang等,2019年; Zhou,Qi和Ma 2019; Xue等,2020年),线验证网络(Zhang等,2019; Zhou,Qi和Ma 2019; Xue等,2020年)和卷积混合模块(Huang等,2020年,2018年)。随着模型尺寸和线预测模块数量的增加,LSD的整体推理速度可能会变慢,如图2b所示,同时需要更高的计算。因此,计算成本的增加使得在资源受限平台上部署LSD变得困难。
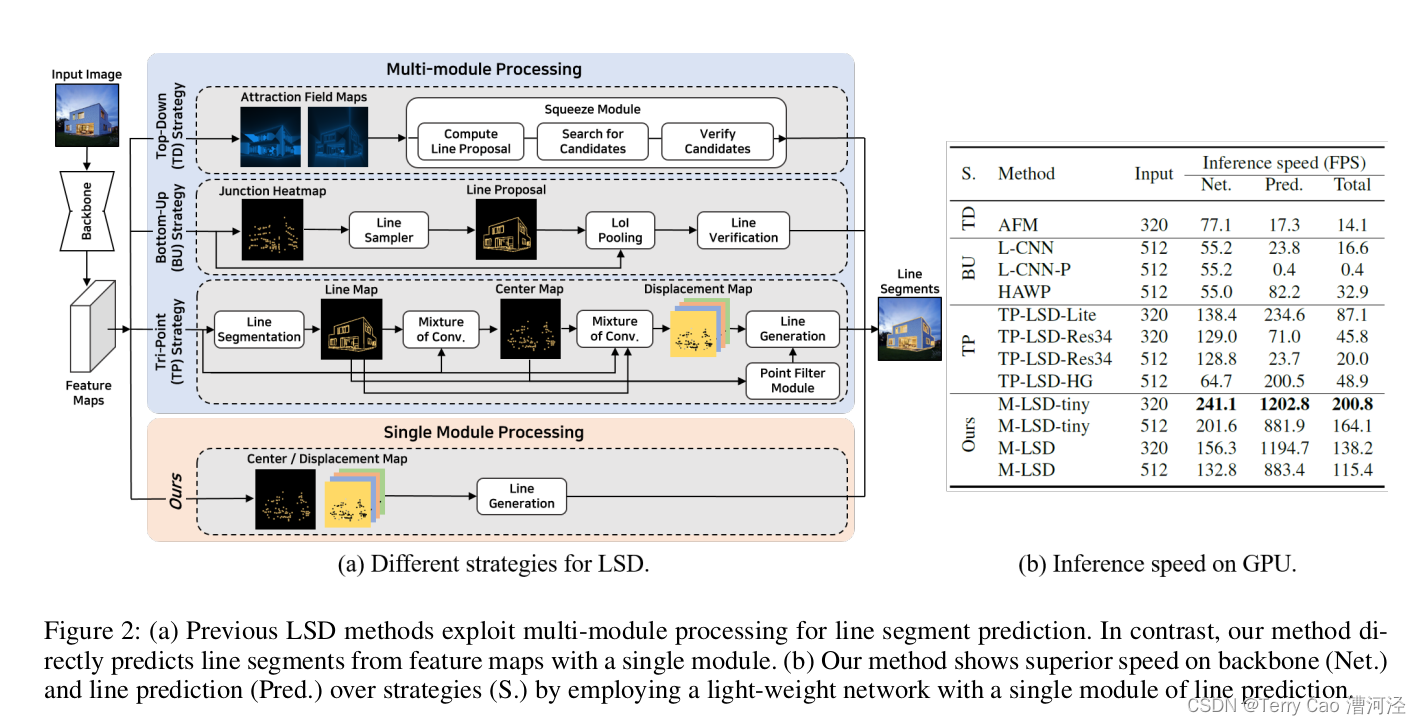
在本文中,我们提出了一种适用于资源受限环境的实时轻量级LSD,名为Mobile LSD(M-LSD)。对于网络,我们设计了一个显著高效的架构,只使用一个模块来预测线段。通过最小化网络尺寸并消除先前方法中的多模块过程,M-LSD非常轻便且快速。为了即使使用轻量级网络也能保持竞争性能,我们提出了新颖的训练方案:SoL增强、匹配和几何损失。SoL增强将线段分成子部分,进而在训练阶段提供增强线段数据。匹配和几何损失通过提供额外的几何信息,包括线段之间的关系、交叉点和线段分割、长度和度数回归,
2. 相关工作
深度线段检测。
对基于深度学习的LSD进行了积极的研究。在基于交叉点的方法中,DWP(Huang等,2018年)包括两个并行分支来预测线和交叉点热图,然后进行合并处理。PPGNet(Zhang等,2019年)和L-CNN(Zhou,Qi和Ma 2019年)利用基于交叉点的线段表示,并使用额外的分类器来验证一对点是否属于同一条线段。另一种方法使用密集预测。AFM(Xue等,2019a年)预测包含代表相关线段的2-D投影向量的吸引场地图,然后通过一个压缩模块恢复线段。HAWP(Xue等,2020年)被提出作为AFM和L-CNN的混合模型。最近,(Huang等,2020年)设计了TP线表示法,以消除先前方法中发现的额外分类器或启发式后处理,并提出了具有两个分支的TP-LSD网络:TP提取和线段分割分支。其他方法包括使用变压器(Xu等,2021年)或Hough变换与深度网络(Lin等,2020年)。然而,通常观察到上述多模块过程限制了现有的LSD在资源受限环境中的运行。
实时目标检测器。
实时目标检测一直是基于深度学习的目标检测的重要任务。早期提出的目标检测器,如RCNN系列(Girshick等,2014年; Girshick 2015年; Ren等,2015年),包括两阶段架构:在第一阶段生成提议,然后在第二阶段对提议进行分类。这些两阶段检测器通常推理速度较慢,并且在优化上存在困难。为了解决这个问题,提出了一阶段检测器,如YOLO系列(Redmon等,2016年; Redmon和Farhadi 2017, 2018年)和SSD(Liu等,2016年),通过减小骨干网络的尺寸并将两阶段过程简化为一阶段来实现GPU实时推理。这种一阶段架构已经被进一步研究和改进,以在移动设备上实时运行(Howard等,2017年; Sandler等,2018年; 王,李和Ling 2018年; 李等,2018年)。受从两阶段到一阶段架构在目标检测中的过渡的启发,我们认为先前LSD中复杂的多模块处理可以被忽略。我们通过一个单模块简化线预测过程,以获得更快的推理速度,并通过高效的训练策略(SoL增强、匹配和几何损失)提高性能。















 9956
9956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









