






一.摘要
1.提出了一个加权双向特征金字塔网络(BiFPN),它可以轻松快速地进行多尺度特征融合。
2.提出了一种复合缩放方法,同时对所有主干网络、特征网络、目标定位网络和分类网络的分辨率、深度、宽度统一缩放。
3.开发了一个新的对象检测器系列D0-D7,称为EfficientDet。
目标:在可伸缩架构和高精度之间取得平衡,开发高效并适应多场景需求的目标检测网络,最终形成由主干网、特征融合网络、定位网络、分类网络构成的EfficientDet模型。
效果: COCO上55.1 AP,77M param and 410B FLOPs,模型规模缩小4-9倍,FLOPs减少了13至42倍。
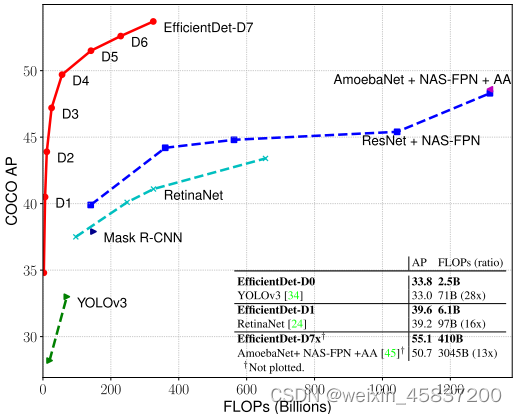
图1 EfficientDet与其他模型效率比较
从图1可以看出,在同等准确率的情况下,EfficientDet需要的FLOPs比YOLOv3减少28倍,比RetinaNet减少30倍。比基于ResNet的NAS-FPN少19倍。
二. 两个挑战
1.有效的多尺度特征融合,大多数前人工作在融合输入特征时只是简单将它们相加,然而由于不同的输入特征处于不同分辨率的特征图上,通常对融合的输出特征的贡献不相等。为此提出加权双向特征金字塔网络(BiFPN),引入可学习权重来学习不同输入特征的重要性,同时重复应用自上而下和自下而上的多尺度特征融合。
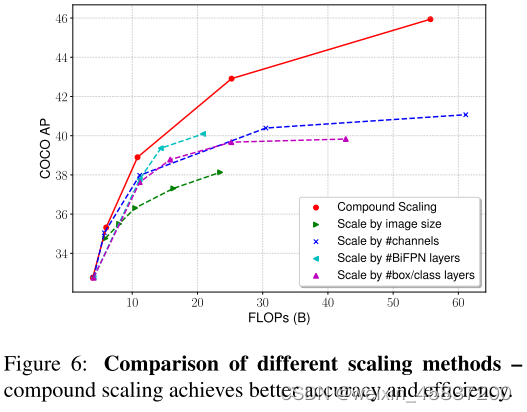
2.模型缩放,大多数前人工作依赖更大骨干网络或更大输入图像尺寸获得更高准确性,考虑准确性和效率时,放大feature network and box/class prediction network也很关键,提出一种用于对象检测的复合缩放方法,联合扩展了骨干,特征网络,框/类预测网络的分辨率/深度/宽度(resolution/depth/width for all backbone, feature network, box/class prediction network)。
三. BiFPN(高效的双向跨尺度连接和加权特征融合)
多尺度特征融合的目的是聚合不同分辨率的特征。
3.1 问题公式化
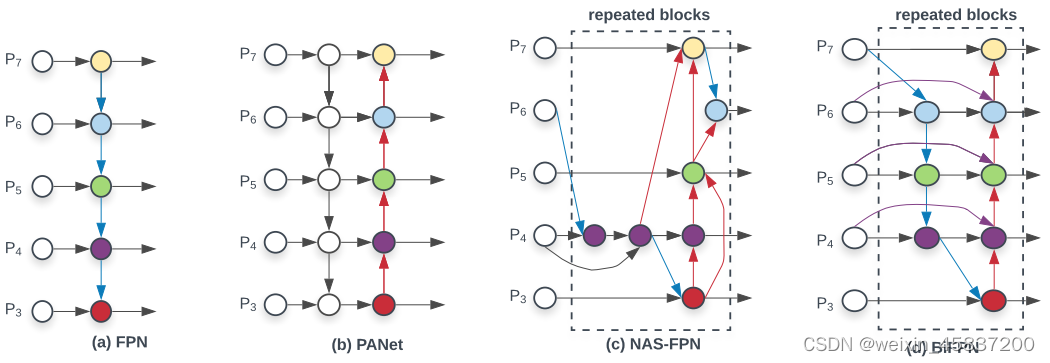
图2 多种特征网络设计
(a) FPN 引入一个自上而下的路径来融合第3级到第7级(P3-P7)的多尺度特征;
(b) PANet 在FPN之上添加了一个额外的自下而上的路径聚合网络;
(c) NAS-FPN 使用神经架构搜索来找到一个不规则的特征网络拓扑,然后重复应用相同的块;
(d) BiFPN是否具有更好的准确性和效率权衡。
...
Resize通常是用于分辨率匹配的上采样或下采样操作,Conv通常是用于特征处理的卷积操作。eg输入分辨率640*640,分辨率为80*80。
3.2 Cross-Scale Connections(跨尺度连接)
跨尺度连接原因:传统自上而下的PN受到单向信息流的限制。
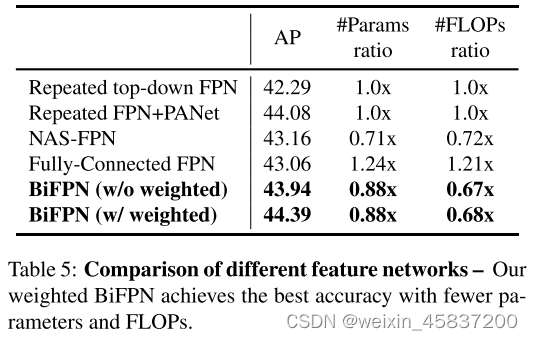
NAS-FPN 采用神经架构搜索来搜索更好的跨尺度特征网络拓扑,但在搜索过程中需要数千个GPU小时,并且发现的网络是不规则的,难以解释或修改,PANet比FPN和NAS-FPN实现了更好的准确性(accuray),但需要更多的 parameters 和 computations 。
方法:
1. 删除那些只有一条输入边的节点(只有一条输入边而没有进行特征融合,那么它对融合不同特征的特征网络的贡献就很小)
2.在原输入节点到输出节点之间,如果它们在同一水平上,增加一条额外的边(以便在不增加太多成本的情况下融合更多的特征)。
3.将每个双向(自上而下和自下而上)路径作为一个特征网络层,并多次重复同一层以实现更高级别的特征融合。
3.3 加权特征融合
老方法:当融合具有不同分辨率的特征时,常见的方法是首先将它们调整为相同的分辨率,然后将它们相加。一视同仁地对待所有输入特征。
缺点:由于不同的输入特征具有不同的分辨率,因此它们通常对输出特征的贡献不相等。
新方法:每个输入增加一个额外的权重,让网络学习每个输入特征的重要性。
是可学习的权重,可以是标量、向量、张量,由于标量权重是无界的,它可能会导致训练不稳定。因此,我们采用权重归一化来限制每个权重的值范围。
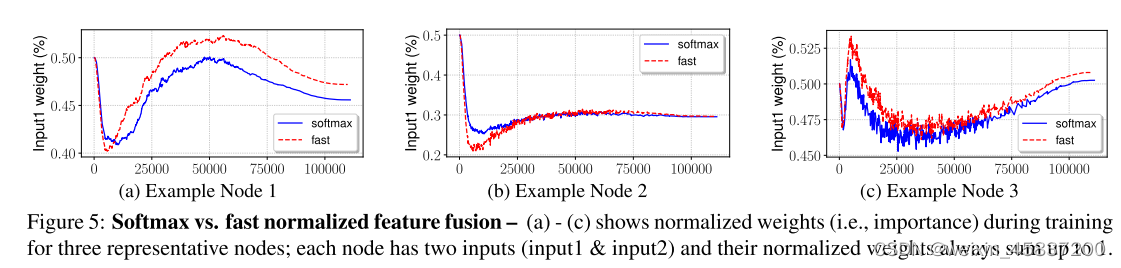
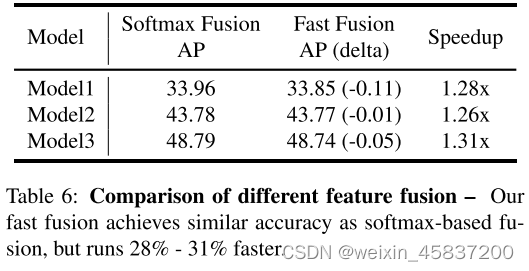
基于Softmax的融合: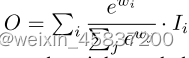 ,对每个权重应用softmax,这样所有权重都被归一化为一个概率,其值范围从0到1,表示每个输入的重要性。但是额外的softmax会导致GPU硬件的显着放缓。为了最小化额外的延迟成本,我们进一步提出了一种快速融合方法。
,对每个权重应用softmax,这样所有权重都被归一化为一个概率,其值范围从0到1,表示每个输入的重要性。但是额外的softmax会导致GPU硬件的显着放缓。为了最小化额外的延迟成本,我们进一步提出了一种快速融合方法。
快速归一化融合: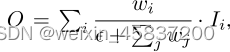 其中通过在每个wi之后应用Relu来确保wi ≥ 0,并且= 0.0001是一个小值以避免数值不稳定性。使得每个归一化权重在0和1之间。
其中通过在每个wi之后应用Relu来确保wi ≥ 0,并且= 0.0001是一个小值以避免数值不稳定性。使得每个归一化权重在0和1之间。

为了进一步提高效率,我们使用depthwise separable convolution进行特征融合,并在每次卷积后添加批量归一化和激活。
四.EfficientDet
以efficientnet为backbone,从中获取3-7级特征{P3,P4,P5,P6,P7},重复BiFPN,将融合的特征馈送至分类预测网络。分类和回归的权重在所有级别的特征中共享。
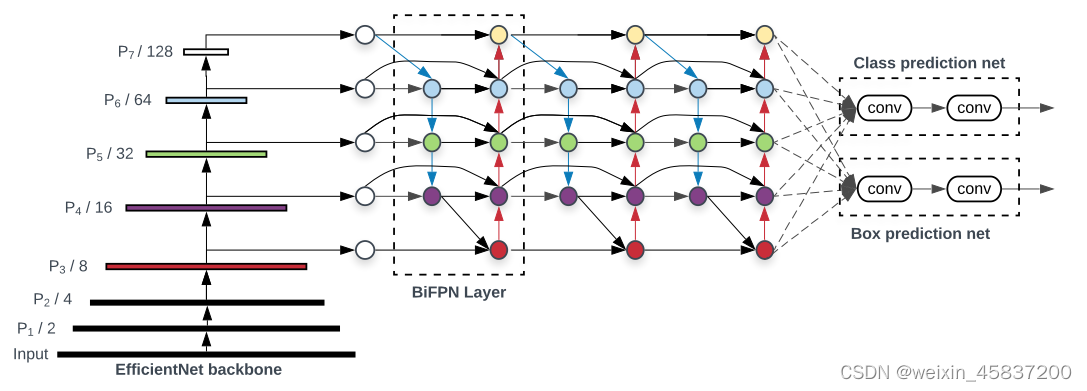
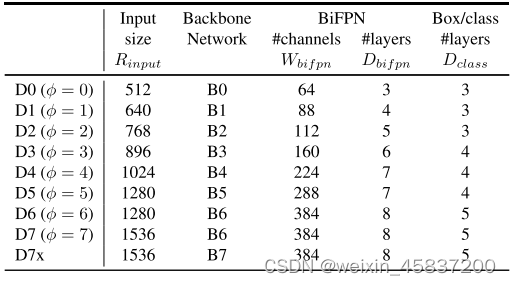
对于主干网络,采用EfficientNet-B0~EfficientNet-B6作为基准参照。
对于BiFPN网络,其宽度和深度的缩放公式如下:
,
(4-1)
其中 表示网络宽度(通道数),
表示网络深度(层数),参数1.35是通过对参数列表
{1.2,1.25,1.3,1.35,1.4,1.45}做网格搜索得到的最佳值。φ是缩放因子。
对于定位和分类网络,采用的缩放方法如下面公式所示:
(4-2)
输入图像分辨率的缩放如公式所示:
(4-3)
根据公式(4-1)(4-2)(4-3),用一个系数φ可以完成对整个EfficientDet网络的缩放,例如φ=0得到模型EfficientDet-D0,φ=7得到模型EfficientDet-D7。
表4.1 EfficientDet系列模型参数
五. 实验
表1 EfficientDet performance on COCO
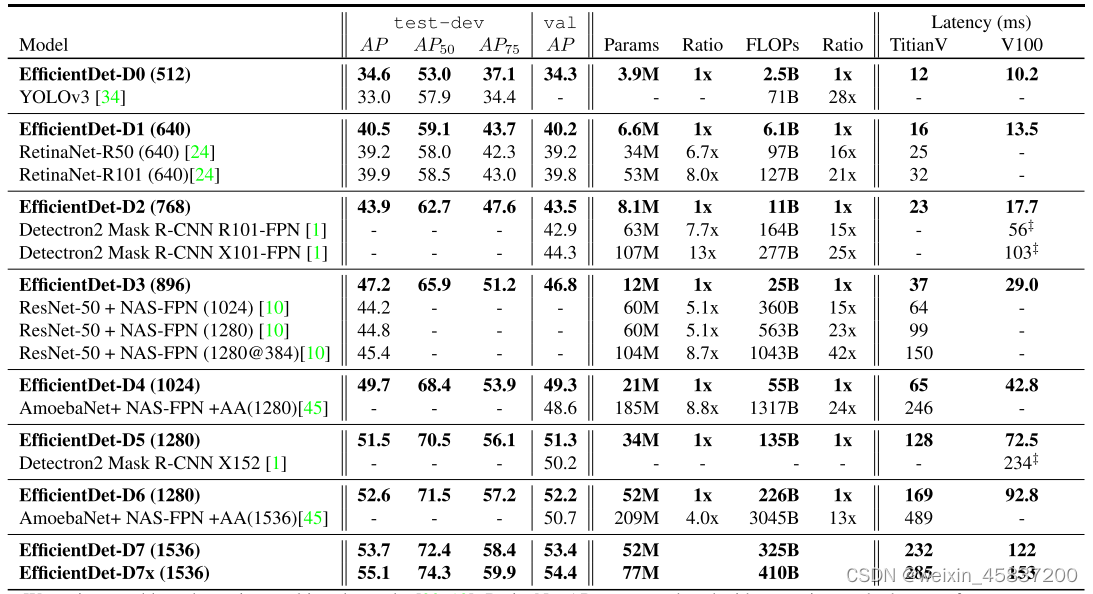
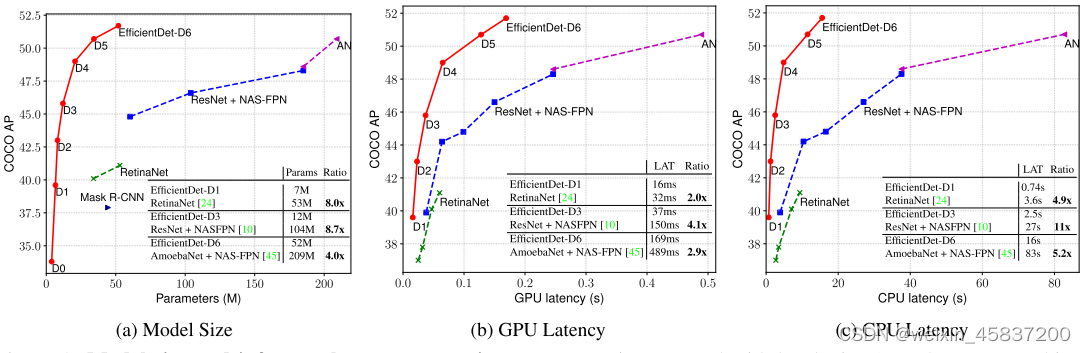
图1 Model size and inference latency comparison



















 8899
8899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









