







「写在前面」
学习一个软件最好的方法就是啃它的官方文档。本着自己学习、分享他人的态度,分享官方文档的中文教程。软件可能随时更新,建议配合官方文档一起阅读。推荐先按顺序阅读往期内容:
文献篇:
1.文献阅读:Squidpy: 一个可扩展的空间组学分析框架
教程篇:
1.squidpy 教程 1:在 AnnData 和 Squidpy 中导入空间数据
2.squidpy 教程 2:ImageContainer 对象
3.squidpy 教程 3:使用 Napari 进行交互式可视化
目录
-
1 导入包和数据 -
2 3D 邻域富集分析 -
3 具有空间自相关统计的空间变化基因
官网教程:
https://squidpy.readthedocs.io/en/stable/notebooks/tutorials/tutorial_merfish.html
本教程展示了如何将 Squidpy 应用于 Merfish 数据的分析。
此处使用的数据来自 Moffitt et al., 2018。我们提供了一个预处理的数据子集,以 anndata.AnnData 格式。有关如何预处理的详细信息,请参阅原始文献。
1 导入包和数据
要在本地运行此教程,请使用此 environment.yml 创建一个 conda 环境 conda env create -f environment.yml <https://github.com/scverse/squidpy_notebooks/blob/main/environment.yml>
import scanpy as sc
import squidpy as sq
sc.logging.print_header()
print(f"squidpy=={sq.__version__}")
# load the pre-processed dataset
adata = sq.datasets.merfish()
adata
## scanpy==1.9.2 anndata==0.8.0 umap==0.5.3 numpy==1.21.0 scipy==1.9.3 pandas==1.5.1 scikit-learn==1.1.3 statsmodels==0.13.2 python-igraph==0.10.2 pynndescent==0.5.7 squidpy==1.2.2
该数据集由来自小鼠下丘脑视前区的连续切片组成。它代表了如何在 Squidpy 中使用 3D 空间数据的一个有趣的例子。让我们从可视化开始:我们可以使用 scanpy.pl.embedding() 可视化 3D stack of slides:
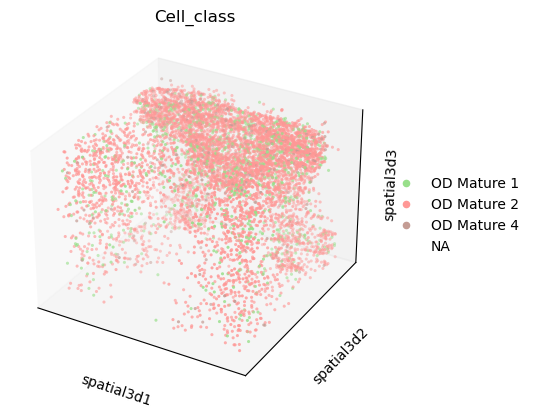
sc.pl.embedding(adata, basis="spatial3d", projection="3d", color="Cell_class")

或者使用 squidpy.pl.spatial_stratter() 可视化单个 slide。此处 slide identifier 存储在 adata.obs["Bregma"] 中,请参阅原始论文中的定义。
sq.pl.spatial_scatter(
adata[adata.obs.Bregma == -9], shape=None, color="Cell_class", size=1
)

2 3D 邻域富集分析
重要的是要考虑是应该对单个切片的 3D 空间坐标还是 2D 坐标执行分析。使用空间图的函数已经可以支持 3D 坐标,但重要的是要考虑 z-stack 坐标与 x、y 坐标的单位度量相同。让我们从邻域富集分数开始。您可以在 Building spatial neighbors graph 的文档中阅读更多关于该函数的内容。首先,我们需要使用 squidpy.gr.spatial_nodghbors() 来计算 neighbor graph。如果我们想计算三维坐标空间上的 neighbor graph,我们需要指定spatial_key="spatial3d"。然后我们可以使用 squidpy.gr.nhood_enrichment() 来计算分数,并使用 squidpy.gr.nhood_enrichment() 将其可视化。
sq.gr.spatial_neighbors(adata, coord_type="generic", spatial_key="spatial3d")
sq.gr.nhood_enrichment(adata, cluster_key="Cell_class")
sq.pl.nhood_enrichment(
adata, cluster_key="Cell_class", method="single", cmap="inferno", vmin=-50, vmax=100
)

我们可以使用 scanpy.pl.embedding() 可视化一些 co-enriched clusters。我们将设置 na_colors=(1,1,1,0) 以使其他 observations 透明,以便更好地可视化 z-stacks 中感兴趣的 clusters。
sc.pl.embedding(
adata,
basis="spatial3d",
groups=["OD Mature 1", "OD Mature 2", "OD Mature 4"],
na_color=(1, 1, 1, 0),
projection="3d",
color="Cell_class",
)
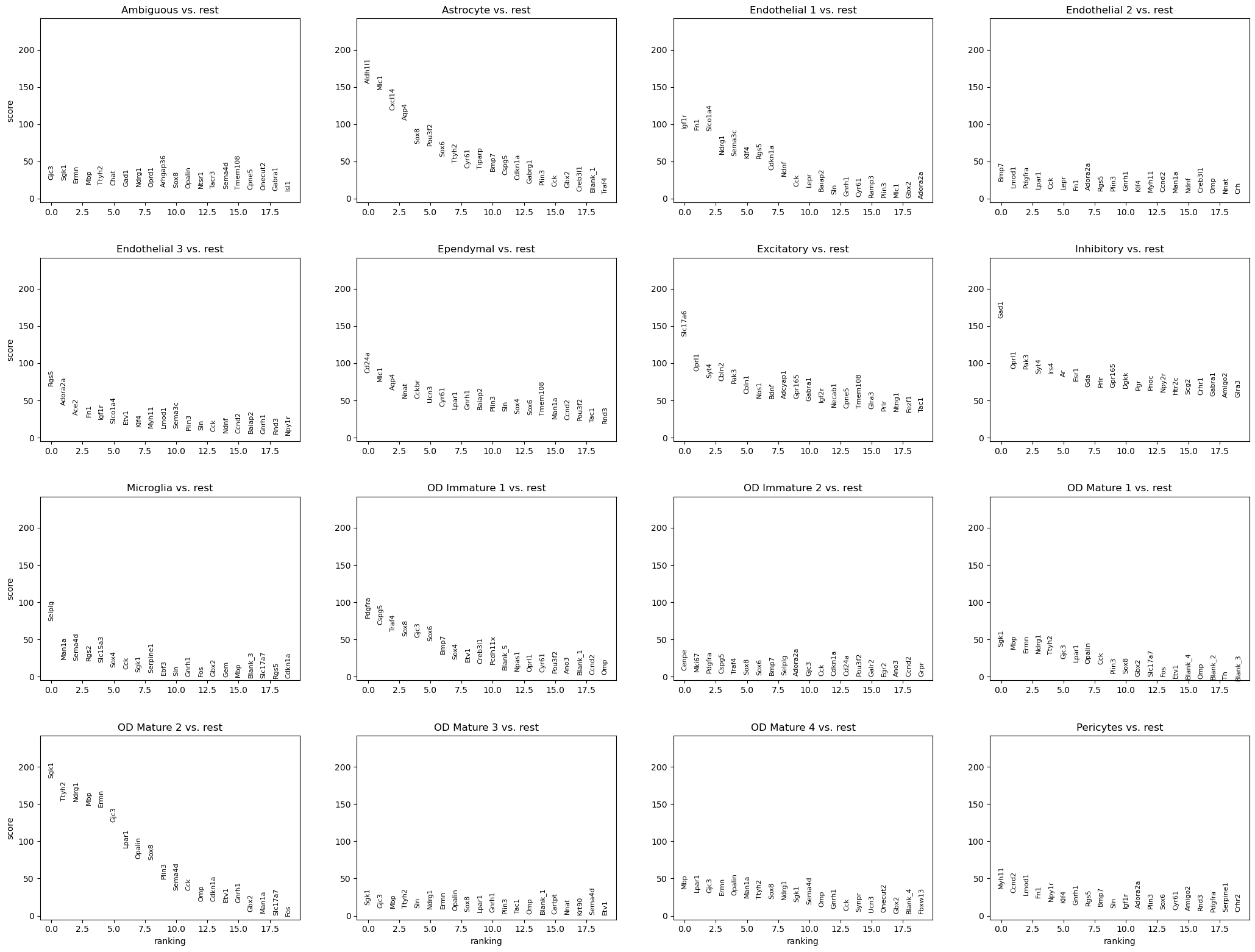
我们还可以在 3D 坐标中可视化基因表达。让我们使用 scanpy.tl.rank_genes_groups() 执行差异表达测试并可视化结果
sc.tl.rank_genes_groups(adata, groupby="Cell_class")
sc.pl.rank_genes_groups(adata, groupby="Cell_class")
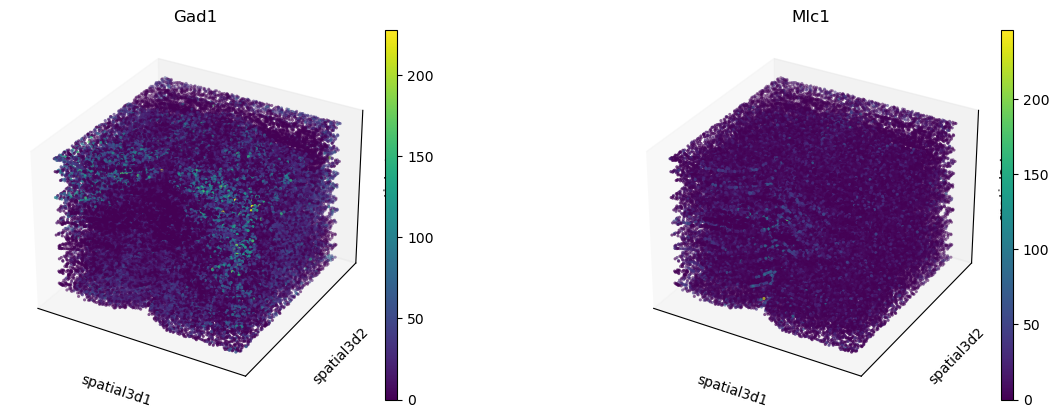
以及 3D 表达。
sc.pl.embedding(adata, basis="spatial3d", projection="3d", color=["Gad1", "Mlc1"])
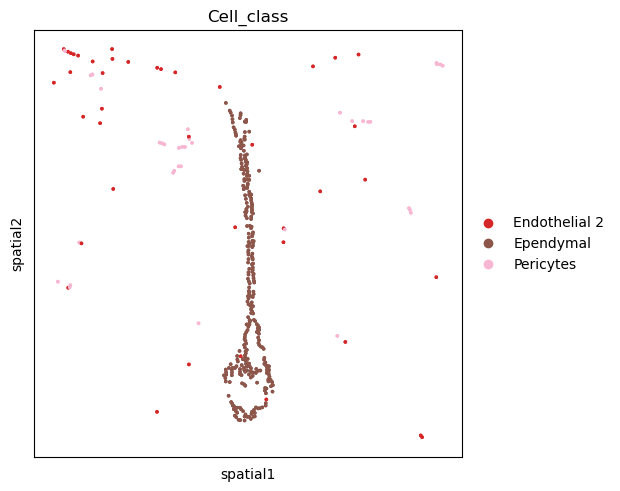
如果应在单个切片上执行相同的分析,则建议将感兴趣的样本复制到新的 anndata.AnnData 中并将其用作标准 2D 空间数据对象。
adata_slice = adata[adata.obs.Bregma == -9].copy()
sq.gr.spatial_neighbors(adata_slice, coord_type="generic")
sq.gr.nhood_enrichment(adata, cluster_key="Cell_class")
sq.pl.spatial_scatter(
adata_slice,
color="Cell_class",
shape=None,
groups=[
"Ependymal",
"Pericytes",
"Endothelial 2",
],
size=10,
)
3 具有空间自相关统计的空间变化基因
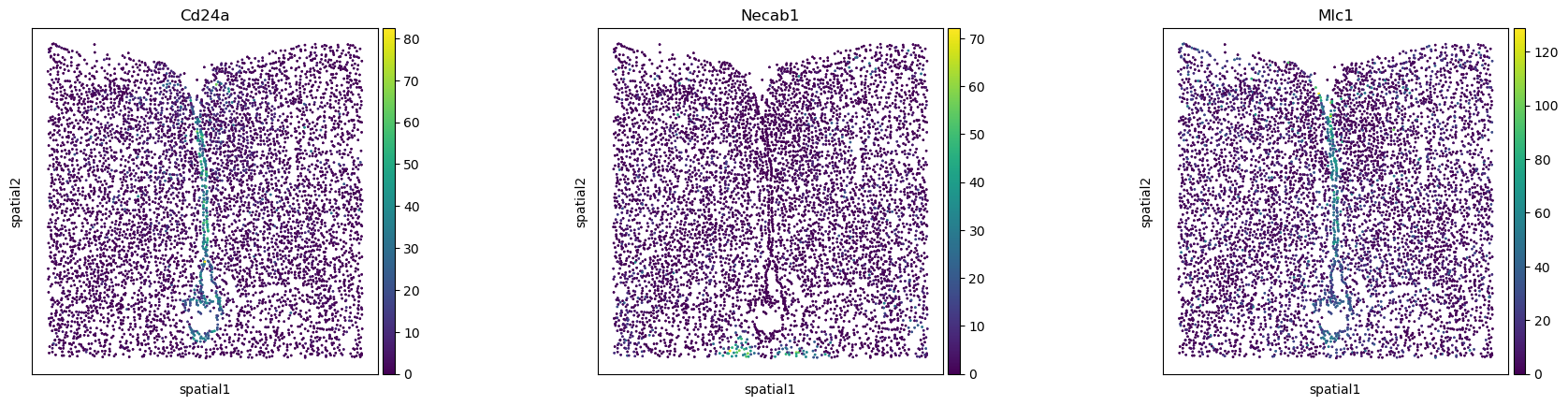
使用 Squidpy,我们可以研究基因表达的空间变异性。这是仅支持 2D 数据的函数示例。squidpy.gr.spatial_autocorr() 方便地包装了两个空间自相关统计:Moran’s I and Geary’s C。它们提供基因表达空间变异程度的评分。计算每个基因的统计量和 p 值,并执行 FDR 校正。出于本教程的目的,我们来计算 Moran’s I 分数。结果存储在 adata.uns['moranI'] 中,我们可以使用 squidpy.pl.spatial_scatter() 可视化选定的基因。
sq.gr.spatial_autocorr(adata_slice, mode="moran")
adata_slice.uns["moranI"].head()
sq.pl.spatial_scatter(
adata_slice, shape=None, color=["Cd24a", "Necab1", "Mlc1"], size=3
)

本文由 mdnice 多平台发布


















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











