







调优算法
LLaMA-Factory 支持多种调优算法,包括: Full Parameter Fine-tuning 、 Freeze 、 LoRA 、 Galore 、 BAdam 。
1.Full Parameter Fine-tuning
全参微调指的是在训练过程中对于预训练模型的所有权重都进行更新,但其对显存的要求是巨大的。
如果您需要进行全参微调,请将 finetuning_type 设置为 full 。
下面是一个例子:
### examples/train_full/llama3_full_sft_ds3..yaml
# ...
finetuning_type: full
# ...
# 如果需要使用deepspeed:
deepspeed: examples/deepspeed/ds_z3_config.json
2.Freeze
Freeze(冻结微调)指的是在训练过程中只对模型的小部分权重进行更新,这样可以降低对显存的要求。
如果您需要进行冻结微调,请将 finetuning_type 设置为 freeze 并且设置相关参数, 例如冻结的层数 freeze_trainable_layers 、可训练的模块名称 freeze_trainable_modules 等。
以下是一个例子:
...
### method
stage: sft
do_train: true
finetuning_type: freeze
freeze_trainable_layers: 8
freeze_trainable_modules: all
...
| 参数名称 | 类型 | 介绍 |
|---|---|---|
| freeze_trainable_layers | int | 可训练层的数量。正数表示最后 n 层被设置为可训练的,负数表示前 n 层被设置为可训练的。默认值为 2 |
| freeze_trainable_modules | str | 可训练层的名称。使用 all 来指定所有模块。默认值为 all |
| freeze_extra_modules[非必须] | str | 除了隐藏层外可以被训练的模块名称,被指定的模块将会被设置为可训练的。使用逗号分隔多个模块。默认值为 None |
3.LoRA
如果您需要进行 LoRA 微调,请将 finetuning_type 设置为 lora 并且设置相关参数。 下面是一个例子:
...
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
lora_rank: 8
lora_alpha: 16
lora_dropout: 0.1
...
| 参数名称 | 类型 | 介绍 |
|---|---|---|
| additional_target[非必须] | [str,] | 除 LoRA 层之外设置为可训练并保存在最终检查点中的模块名称。使用逗号分隔多个模块。默认值为 None |
| lora_alpha[非必须] | int | LoRA 缩放系数。一般情况下为 lora_rank * 2, 默认值为 None |
| lora_dropout | float | LoRA 微调中的 dropout 率。默认值为 0 |
| lora_rank | int | LoRA 微调的本征维数 r, r 越大可训练的参数越多。默认值为 8 |
| lora_target | str | 应用 LoRA 方法的模块名称。使用逗号分隔多个模块,使用 all 指定所有模块。默认值为 all |
| loraplus_lr_ratio[非必须] | float | LoRA + 学习率比例(λ = ηB/ηA)。 ηA, ηB 分别是 adapter matrices A 与 B 的学习率。LoRA+ 的理想取值与所选择的模型和任务有关。默认值为 None |
| loraplus_lr_embedding[非必须] | float | LoRA + 嵌入层的学习率, 默认值为 1e-6 |
| use_rslora | bool | 是否使用秩稳定 LoRA(Rank-Stabilized LoRA),默认值为 False。 |
| use_dora | bool | 是否使用权重分解 LoRA(Weight-Decomposed LoRA),默认值为 False |
| pissa_init | bool | 是否初始化 PiSSA 适配器,默认值为 False |
| pissa_iter | int | PiSSA 中 FSVD 执行的迭代步数。使用 -1 将其禁用,默认值为 16 |
| pissa_convert | bool | 是否将 PiSSA 适配器转换为正常的 LoRA 适配器,默认值为 False |
| create_new_adapter | bool | 是否创建一个具有随机初始化权重的新适配器,默认值为 False |
1.LoRA+
在 LoRA 中,适配器矩阵 A 和 B 的学习率相同。
可以通过设置 loraplus_lr_radio 来调整学习率比例。
在 LoRA+ 中,
适配器矩阵 A 的学习率 ηA 即为优化器学习率。
适配器矩阵 B 的学习率 ηB 为 λ * ηA
其中, λ 为 loraplus_lr_ratio 的值
2.rsLoRA
LoRA 通过添加低秩适配器进行微调,然而 lora_rank 的增大往往会导致梯度塌陷,使得训练变得不稳定。
因为过大的参数空间可能使得模型在学习过程中变得不稳定,导致反向传播时梯度的计算变得极其微小。
这使得在使用较大的 lora_rank 进行 LoRA 微调时较难取得令人满意的效果。
rsLoRA(Rank-Stabilized LoRA) 通过修改缩放因子使得模型训练更加稳定。使用 rsLoRA时,需要将 use_rslora 设置为 True 并设置所需要的 lora_rank
rsLoRA(Rank-Stabilized LoRA)是一种改进的LoRA(Low-Rank Adapters)方法,旨在解决LoRA在高秩适配器时学习效率低下的问题。
LoRA的问题
在 LoRA 中,适配器通过在预训练模型的特定层添加低秩矩阵乘积来实现参数高效微调。适配器的计算形式如下:
x o u t = ( W + γ r B A ) x i n + b x_{out}=(W+\gamma_rBA)x_{in}+b xout=(W+γrBA)xin+b
一般 γ r \gamma_r γr 被设置为 α / r \alpha/r α/r。这种设置会导致随着秩的增加(尤其是高秩情况),学习过程变慢,从而限制了 LoRA 在实践中的应用,通常只限于非常低的秩。
rsLoRA方法
作者提出了一种新的缩放因子,称为 rank-stabilized LoRA(rsLoRA),它通过将适配器除以秩的平方根来解决上述问题。具体来说,新的缩放因子为:
γ r = α / r γ_r=α/\sqrt {r} γr=α/r
这种改进的缩放因子可以避免梯度崩溃,使得在高秩适配器时也能保持良好的学习性能。实验结果
作者通过一系列实验验证了rsLoRA方法的有效性。实验的主要内容包括:
- 不同秩的比较:
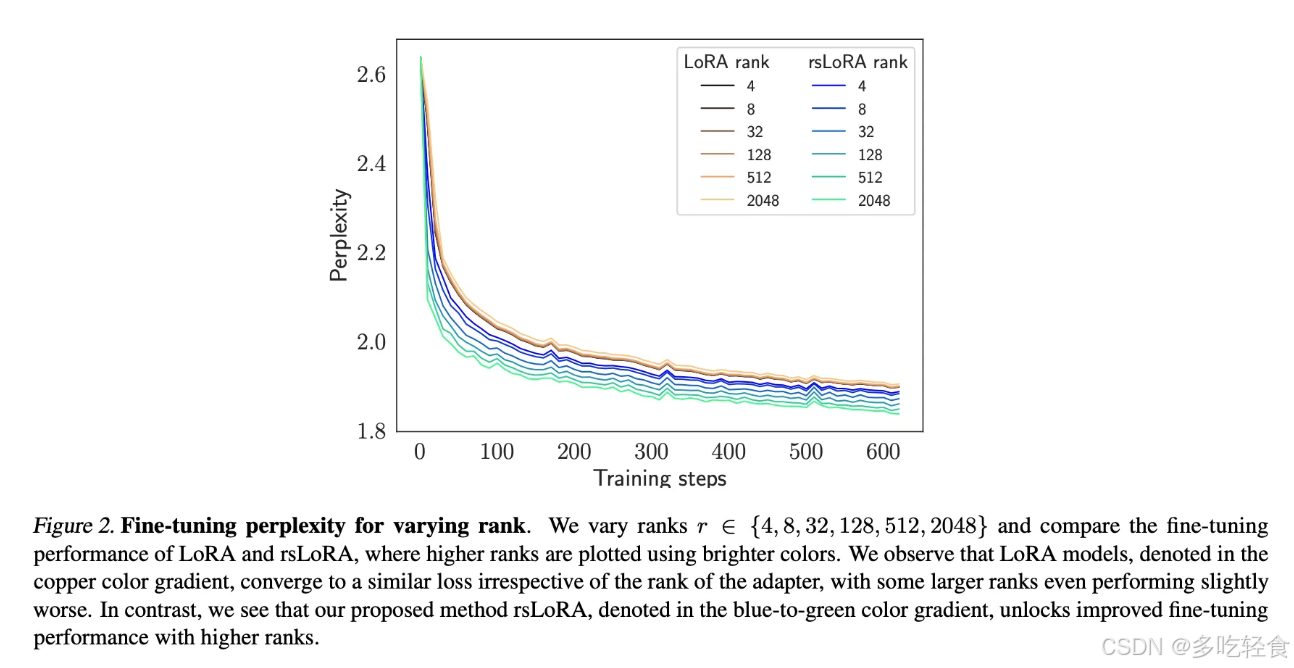
作者比较了LoRA和rsLoRA在不同秩(4, 8, 32, 128, 512, 2048)下的性能。实验结果表明,LoRA在不同秩下的性能差异不大,而 rsLoRA 在高秩下能够实现更好的性能。
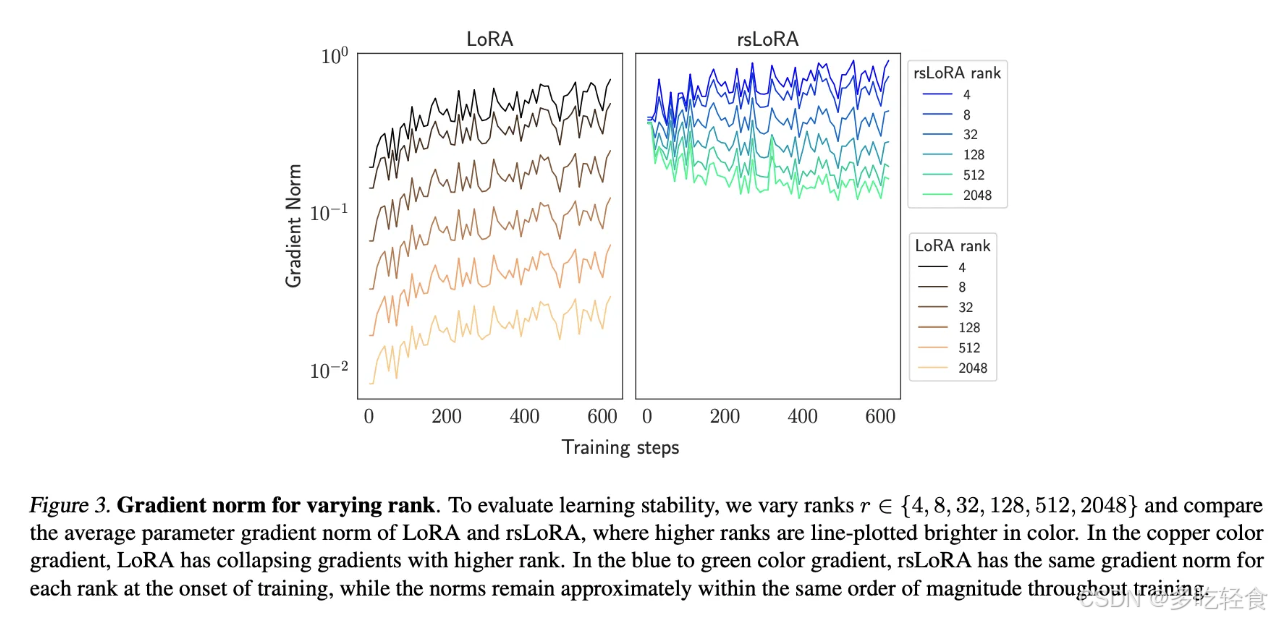
- 梯度范数的稳定性:
作者跟踪了训练过程中的平均参数梯度范数,以评估学习过程的稳定性。实验结果显示,LoRA在高秩适配器时梯度范数会崩溃,而 rsLoRA 则能够保持稳定的梯度范数。
- 不同模型、数据集和优化器的泛化性:
为了验证rsLoRA方法的泛化性,作者在不同的模型(如GPT-J)、数据集(如GSM8k)和优化器(如Adafactor)上进行了实验。实验结果表明,rsLoRA在这些不同的设置下都能取得稳定的性能提升。
结论
论文得出结论,通过使用rsLoRA方法,可以在不增加推理计算成本的情况下,通过增加训练计算资源来提高微调性能。这为在有限的内存预算下实现最佳的微调性能提供了一种新的方法。
3.DoRA
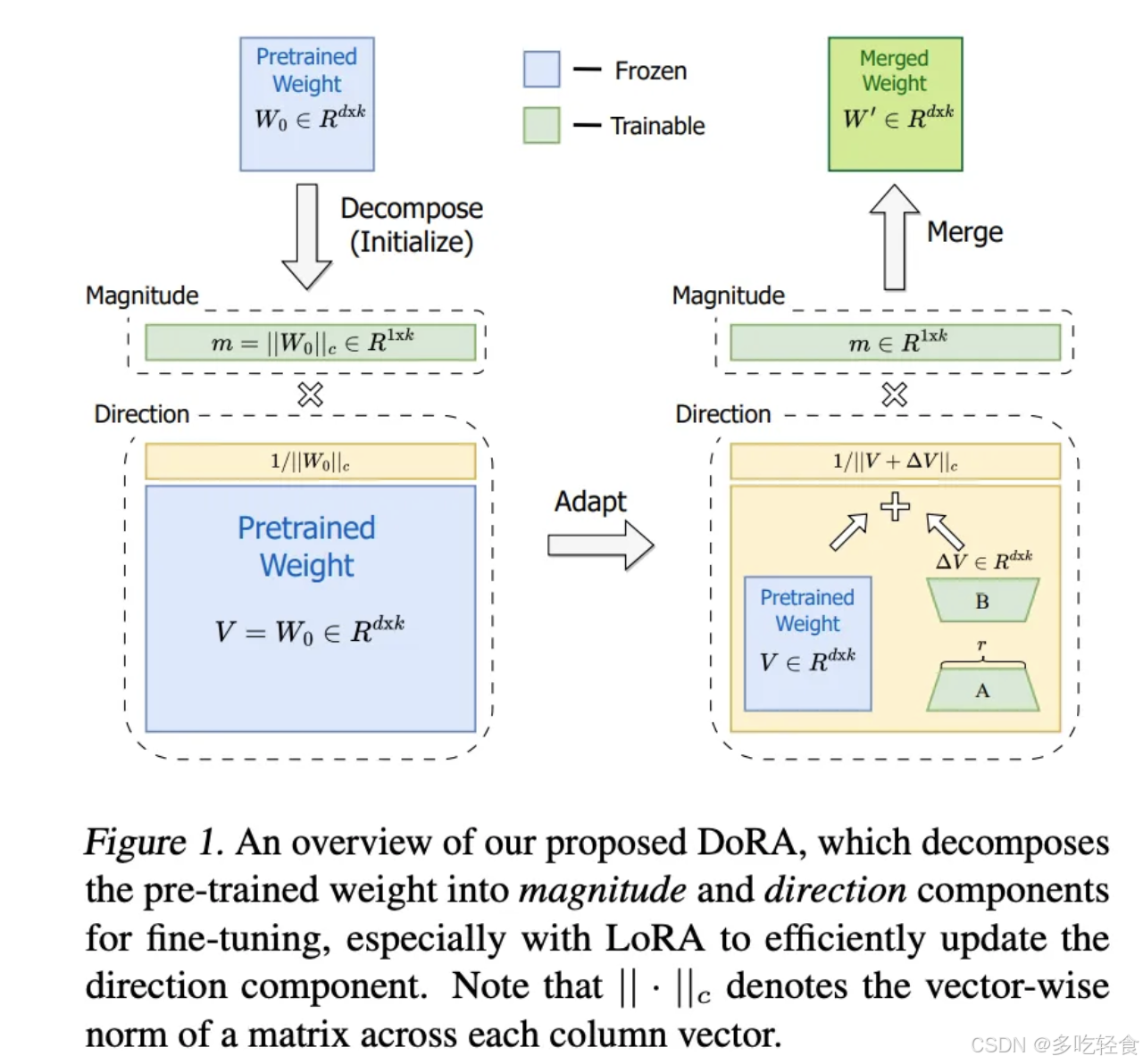
DoRA(Weight-Decomposed Low-Rank Adaptation) 提出尽管 LoRA 大幅度降低了推理成本,但是这种方式取得的性能与全量微调仍然有一些差距
DoRA 将权重矩阵分解为大小与单位方向矩阵的乘积,并进一步微调二者(对方向矩阵则进一步使用 LoRA 分解),从而实现 LoRA 与 Full Fine-tuning 之间的平衡
如果您需要使用 DoRA,请将 use_dora 设置为 True
DoRA是一种新的模型微调方法,于2024年初由微软研究院提出。让我系统地分析一下:
- 基本原理:
- DoRA的核心思想是将模型权重分解为 方向(direction) 和 范围(range) 两个组件
- 在微调过程中,只更新范围参数,保持方向不变
- 这种方法可以在保持预训练模型知识的同时,有效适应下游任务
- 工作机制:
- 将每个线性层的权重矩阵 W 分解为:
- 方向矩阵 D (归一化的权重向量,方向的单位向量)
- 范围矩阵 R (标量值)
- W = D * R,其中 D 保持固定,只优化 R
- 这种分解使得模型能够 保留预训练时学到的方向信息,同时通过调整范围来适应新任务
- 使用判断标准:
当遇到以下情况时,可以考虑使用DoRA:
- 计算资源受限:
- 没有足够的GPU资源进行全参数微调
- 需要快速部署多个任务版本
- 数据特点:
- 领域特定数据量较少
- 任务与预训练分布有一定差异,但不是完全不同
- 任务需求:
- 需要保持模型的通用能力
- 对推理速度有要求
- 需要频繁切换不同任务
- DoRA的优势:
- 参数效率高:只需更新很小部分参数
- 训练速度快:比全参数微调更快
- 内存占用低:不需要存储完整的微调模型
- 保持基础能力:不会严重影响预训练获得的知识
- 潜在局限:
- 可能不适用于与预训练差异极大的任务
- 在某些极端场景下,可能需要更激进的适应方法
- 与 LoRA 对比
性能优势:
- 效果表现:
- DoRA 通常比 LoRA 取得更好的性能表现
- 在相同 rank 设置下,DoRA 能达到更高的准确率
- 特别是在低rank情况下(如 rank=4 或 8),DoRA 的优势更明显
- 稳定性:
- DoRA 的训练过程比 LoRA 更稳定
- 对学习率等超参数的敏感度较低
- 不容易出现训练崩溃的情况
计算资源对比:
- 训练开销:
- DoRA和LoRA的训练开销相近
- 两者都显著低于全参数微调
- DoRA额外需要计算方向矩阵的归一化,但开销可忽略
- 内存占用:
- 两者的内存占用基本相当
- 都具有较低的存储需求
- 合并参数后的模型大小相同
实验
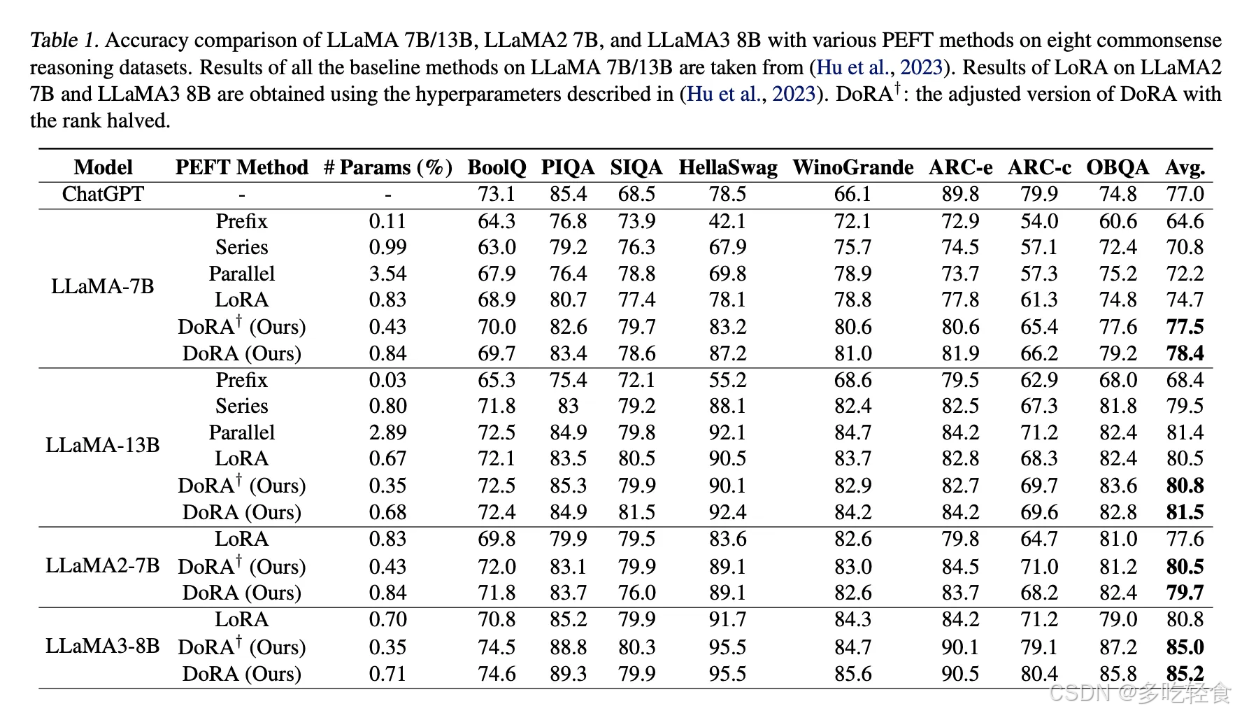
- 常识推理:
- DoRA 在 LLaMA 模型上显著优于 LoRA。
- 采用减半秩的 DoRA(DoRA†)仍优于 LoRA,突显其高效性。
- 图像/视频-文本理解:
- 在 VL-BART 上,DoRA 在图像和视频-文本任务中均优于 LoRA。
- 视觉指令微调:
- 在 LLaVA-1.5-7B 的视觉指令微调任务中,DoRA 表现优于 LoRA 和 FT。
- 与其他 LoRA 变种的兼容性:
- DoRA 与 VeRA兼容,组合使用(DVoRA)表现优于 VeRA 和LoRA。
适用场景推荐:
- 选择 DoRA:
- 对模型性能有较高要求
- 有足够的工程能力实现
- 任务对稳定性要求高
- 需要在低 rank 下获得好的效果
- 选择 LoRA:
- 需要快速实验和部署
- 使用现有工具链
- 对实现简单度有要求
- 已有成熟的LoRA实践经验
总结:
DoRA缩小了LoRA和FT之间的差距,提供了一种参数高效的微调方法,其学习能力接近于FT。DoRA在多个任务和模型架构中表现出持续改进,且无额外的推理开销。未来工作将探索DoRA在音频等其他领域的适用性。
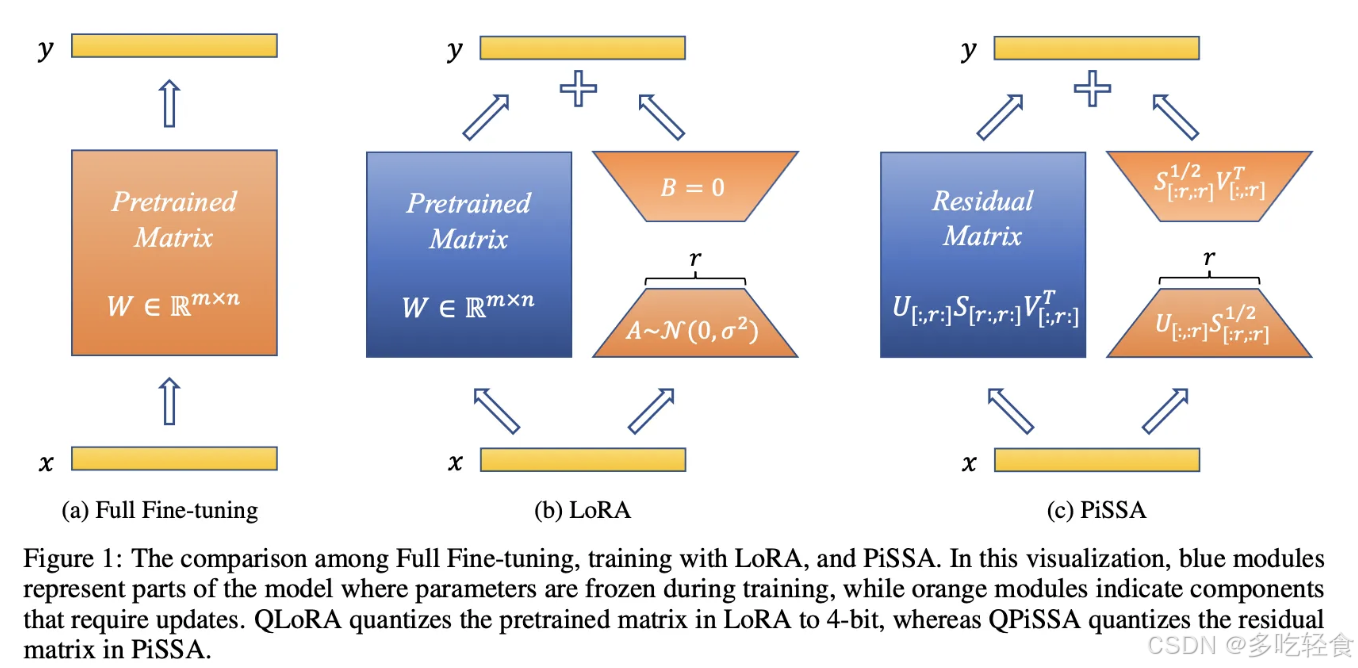
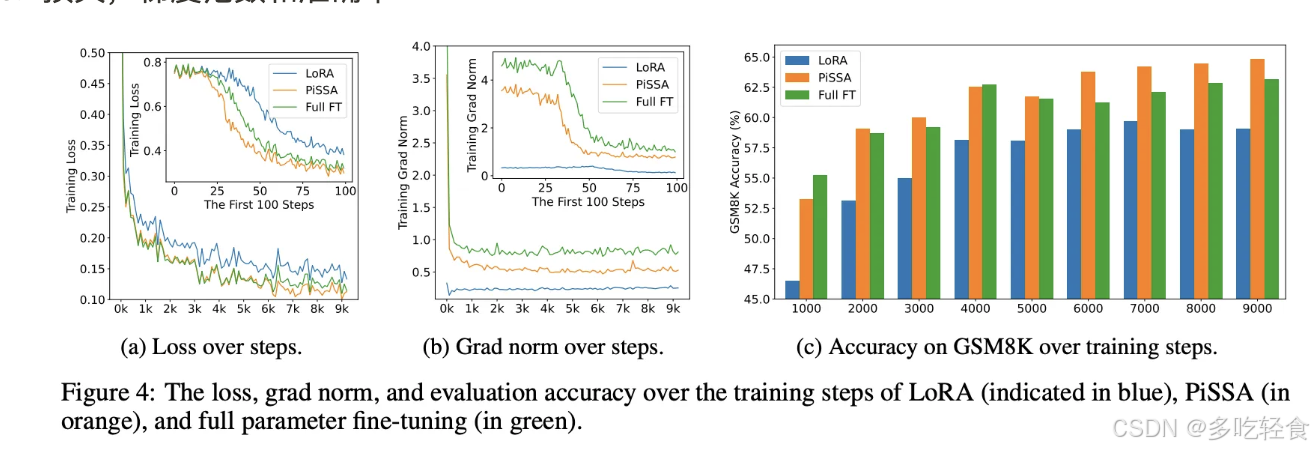
4.PiSSA
在 LoRA 中,适配器矩阵 A 由 kaiming_uniform 初始化,而适配器矩阵 B 则全初始化为0。
这导致一开始的输入并不会改变模型输出并且使得梯度较小,收敛较慢。
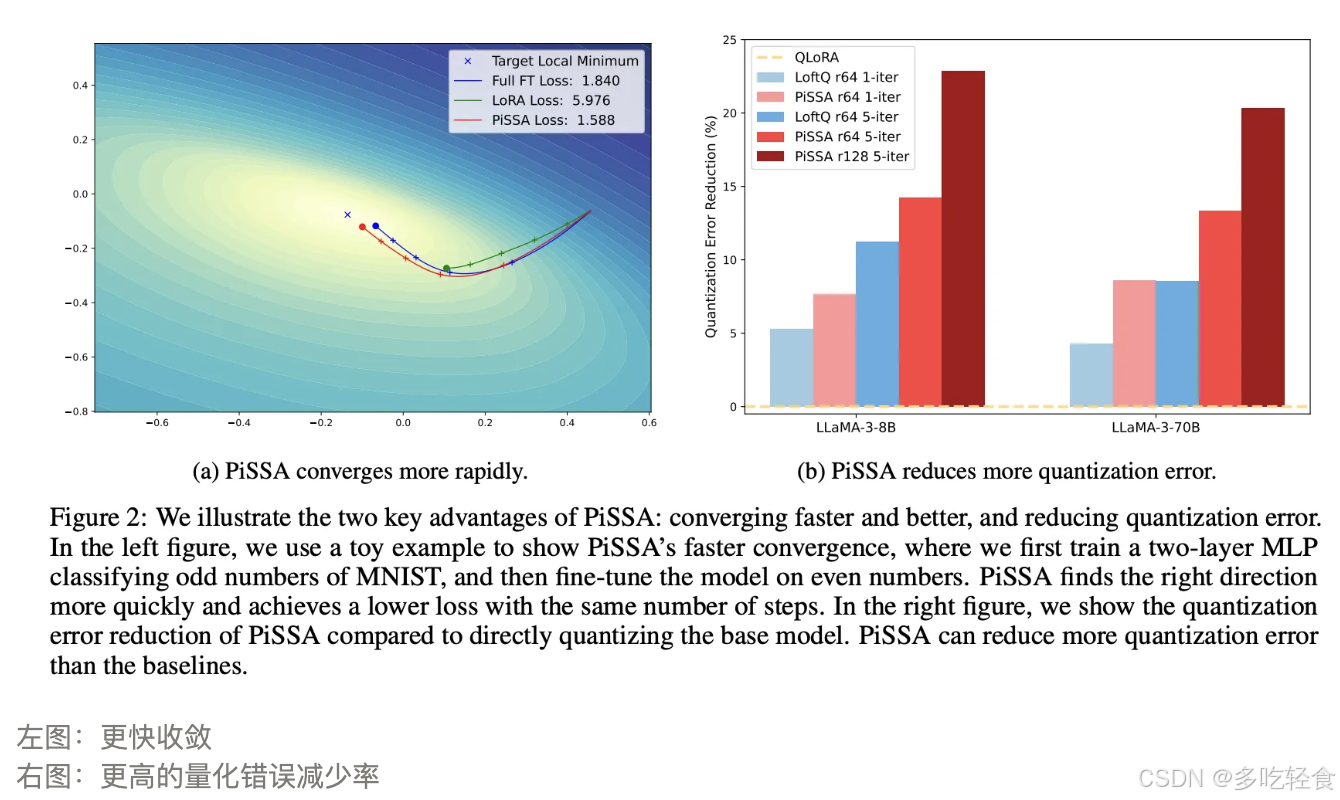
PiSSA 通过奇异值分解直接分解原权重矩阵进行初始化,其优势在于它可以更快更好地收敛。
如果您需要使用 PiSSA,请将 pissa_init 设置为 True 。
PiSSA 的核心思想是利用矩阵 W 的前 r 个最大奇异值及其对应的奇异向量初始化 A 和 B ,而残差奇异值和奇异向量则用于初始化 Wres。在微调过程中,Wres 保持不变,而A和B则被更新。与 LoRA 方法相比,PiSSA 在微调开始时就能更好地近似全参数微调的结果,因为它改变了模型中最重要的部分,而“冻结”了那些“噪声”部分。
原理
更好的初始化
左图:更快收敛
右图:更高的量化错误减少率
LoRA 方法
LoRA通过两个小矩阵 A 和 B 的乘积来近似这个变化,其中 A 用高斯噪声初始化,B 初始化为零。
PiSSA
PiSSA的核心思想是对模型中的权重矩阵W进行奇异值分解(SVD)。SVD是一种将矩阵分解为奇异向量和奇异值的方法,形式为 W = U Σ V ∗ W = UΣV* W=UΣV∗
矩阵 W 的分解
PiSSA 将矩阵 W 分解为一个主成分矩阵 W_pri 和一个残差矩阵 W_res。主成分矩阵 W_pri 具有较低的秩,可以表示为两个较小的可训练矩阵 A 和 B 的乘积,而残差矩阵 W_res 包含了其他的所有信息。
初始化 A 和 B
PiSSA 使用 W 的前 r 个最大奇异值及其对应的奇异向量来初始化 A 和 B。这样,A 和 B 能够捕捉到 W 的主要特征。
残差矩阵 W_res
残差矩阵 W_res 在初始化后在微调过程中保持不变。它包含了那些不重要的、“噪声”的信息。
微调过程
在微调过程中,只有 A 和 B 会被更新,而 W_res 保持不变。这意味着 PiSSA 在微调开始时就能够很好地近似全参数微调的结果,因为它只改变了模型中最重要的部分
与 LoRA 比较
与 LoRA 相比,PiSSA 在初始化时就包含了 W 的主要特征,而 LoRA 则是从随机噪声开始,需要更多的迭代才能捕捉到这些特征。因此,PiSSA 能够更快地收敛,并且在最终性能上也更好。
兼容性与优势:
PiSSA 与 LoRA 具有相同的架构,因此它继承了 LoRA 的许多优势,如参数效率和与量化技术的兼容性。此外,PiSSA 还能够显著减少量化误差,提高了微调性能。
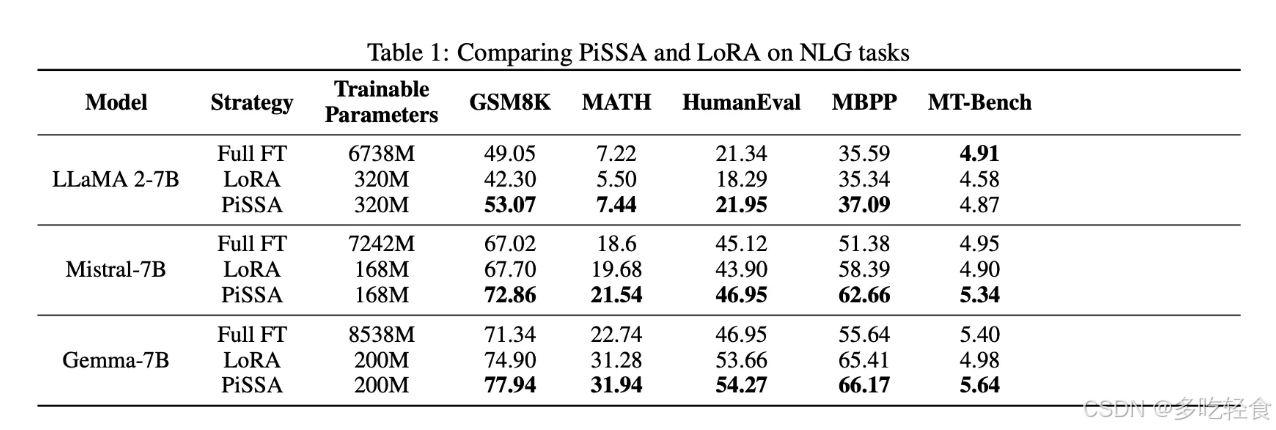
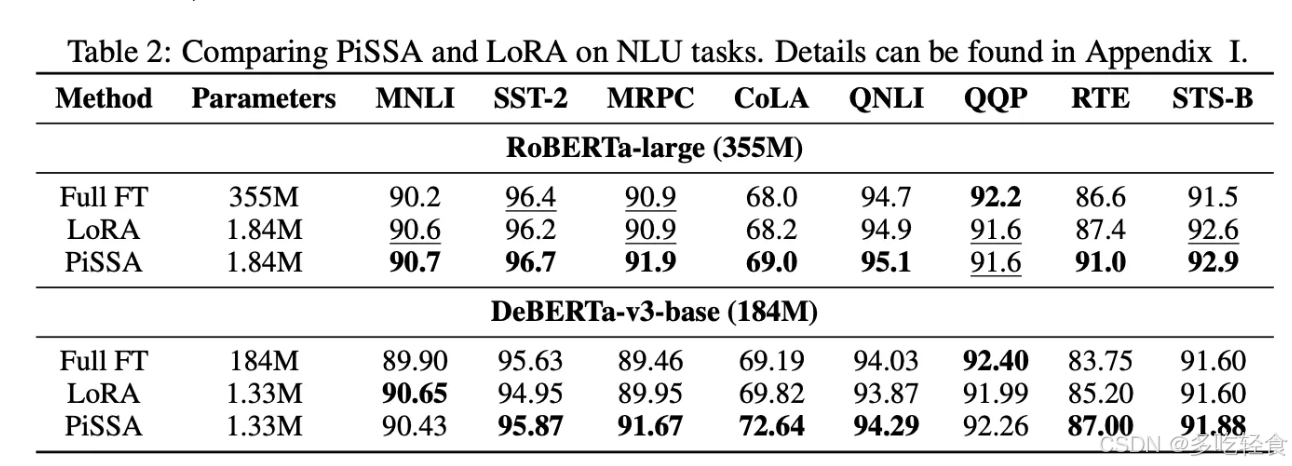
实验
- 使用AdamW优化器进行训练。
批量大小为128。
学习率为2e-5。
使用余弦退火调度和3%的预热比率。
所有实验都在NVIDIA A800-SXM4(80G) GPU上进行。
NLG 任务中,同参数量情况下,显著高于 LoRA
NLU 任务中,同参数仍然高于 LoRA
损失,梯度范数和准确率

















 89
89

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









