






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。当哲学课上老师问你什么是科学,什么是电的时候,不要觉得这些问题搞笑。哲学是科学之母,哲学就是追究终极问题,寻找那些不言自明只有小孩子会问的但是你却回答不出来的问题。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能让人胸中升起一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它居然给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于智能手机的视觉-惯性融合室内导航技术研究
摘要:
本文旨在通过将用户携带的智能手机收集的惯性数据与手机相机获取的视觉信息进行融合,提升第一人称室内导航和场景理解体验。我们在一个期望最大化框架中采用消失方向概念以及人工环境的正交约束,以估计人在视频帧中相对于已知室内坐标的方向。该框架允许包含有关相机旋转轴的先验信息,以提高估计精度,并从单眼视频帧中选择候选边线,估计走廊的深度和宽度,并进行场景的三维建模。我们提出的算法同时使用Kalman滤波器将基于视觉的估计方向与惯性数据结合,以改进估计并消除惯性传感器产生的显著测量漂移。我们在一个由IMU增强视频上评估了我们的视觉惯性数据融合方法的性能,视频记录了参与者完成一整圈旋转走廊的过程。我们证明了这种融合提供了几乎无漂移的即时关于人的相对方向的信息。我们能够估计走廊的深度和宽度,并从约60米一圈的旋转走廊生成一个闭环路径地图。
人类自然地利用视觉感知和导航周围世界,视觉作为主要输入方式与自我本体感觉反馈相结合。然后,他们的大脑重建被可视化场景的三维模型,使他们能够在环境中导航或探索新位置。然而,要从A点到B点旅行,必须通过地图(物理或数字)以及定位系统或用户对位置/路径的先前知识来向用户提供路径信息。随时间收集的全球导航卫星系统(GNSS)数据提供了定位和路径信息。然而,在室内场所,如建筑物内部或隧道等地方,通常无法获得GNSS信号,或者信号非常微弱。为了在GNSS信号不可用的区域估计准确的定位,已经使用惯性测量单元(IMUs)的数据进行相对航向和方向检测。
然而,IMU的数据容易产生大量漂移和失真,通常是由于累积误差引起的。由于与时间积分,加速度计数据中的恒定误差(无论多么小)导致速度中的线性误差和位置估计中的二次误差增长。此外,由于加速度计数据是以本地设备坐标给出的,因此需要除去其中的重力分量以计算位移,而没有准确的姿态(角度)估计是无法实现的。陀螺仪测量可以被积分以产生短时间内可靠的角度估计,但对长时间会产生漂移。姿态速率中的恒定误差导致方位的线性误差,速度中的二次误差和位置中的三次误差增长。为了校正陀螺仪测量,可以利用从加速度计估计的重力分量计算的偏航和俯仰角度。然而,加速度计对短时间内的振动和其他非重力加速度敏感。
一、技术原理与框架
视觉-惯性导航系统(VINS)通过融合智能手机摄像头获取的视觉信息与IMU(惯性测量单元)的惯性数据,实现无源环境下的6自由度位姿估计。其核心在于利用两类传感器的互补性:
- 视觉传感器:提供丰富的环境特征信息(如ORB、SIFT特征点),但受光照变化、运动模糊和纹理缺失影响较大,且输出频率较低(通常30 Hz)。
- 惯性传感器:包括加速度计(测量三轴线性加速度)和陀螺仪(测量角速度),数据频率高(100-200 Hz),可捕捉快速运动,但存在累积误差。两者的融合通过紧耦合或松耦合算法实现,前者直接融合原始数据,后者分层处理后再融合。

技术框架分为以下模块:
- 初始化:解决尺度不确定性(单目视觉)和传感器外参标定问题。例如,通过IMU预积分对齐视觉与惯性数据,利用闭式解估计初始速度、重力方向和偏置。
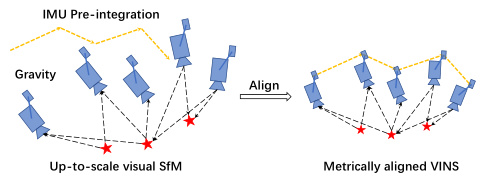
- 前端处理:视觉特征提取(ORB/SURF算法)、匹配(RANSAC优化),以及IMU预积分计算相邻帧间的运动增量。
- 状态估计:基于滤波(如MSCKF)或优化(如BA)方法,最小化视觉重投影误差和IMU动力学误差。
- 地图构建:稀疏/稠密地图生成(VI-SLAM),支持回环检测以消除累积误差。
二、智能手机硬件特性与数据处理
1. 传感器特性与限制
智能手机IMU包含以下组件:
- 加速度计:测量范围±5 g,噪声密度80 μg/√Hz,非线性误差±0.1% FS。
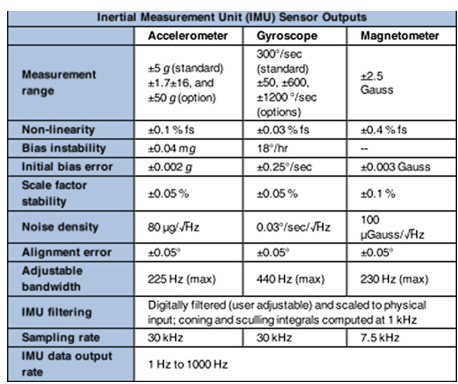
- 陀螺仪:角速度范围±300°/s,偏置不稳定性18°/h,噪声密度0.03°/s/√Hz。
- 磁力计:辅助方向校准,但易受金属干扰。
硬件限制:
- 算力约束:手机处理器算力有限(如70-130亿参数模型部署),需轻量化算法(如LARVIO)。

- 内存与功耗:内存融合技术(如SWAP)可能牺牲实时性,需平衡计算负载与能耗。
2. 视觉数据处理流程
- 预处理:去畸变(径向/切向畸变校正)、降噪(低通滤波)。
- 特征提取与匹配:ORB算法兼顾效率与鲁棒性,Hamming距离匹配结合RANSAC剔除异常值。
- 运动估计:通过本质矩阵分解或PnP求解相对位姿,结合IMU预积分提高频率。
三、多源数据融合算法
1. 主流融合方法
| 方法 | 特点 | 适用场景 |
|---|---|---|
| 扩展卡尔曼滤波(EKF) | 线性化非线性模型,计算效率高,但精度受限(如MSCKF) | 实时性要求高的移动端应用 |
| 非线性优化(BA) | 全局优化精度高,计算量大(如VINS-Mono),需滑动窗口限制状态变量数量 | 高精度定位与建图 |
| 粒子滤波(PF) | 处理非高斯噪声,适合复杂动态环境,但资源消耗大 | 多目标跟踪与动态场景 |
2. 融合策略对比
- 紧耦合:直接融合视觉特征点与IMU原始数据,精度高但计算复杂(如VINS-Fusion)。
- 松耦合:视觉和IMU独立计算位姿后融合(如互补滤波),适合资源受限设备。
四、典型应用场景与性能评估
1. 场景挑战与解决方案
- 弱纹理环境:采用直接法(如LSD-SLAM)或引入深度学习特征。
- 动态遮挡:结合语义分割剔除动态物体(如DROID-SLAM)。
- 快速运动:IMU辅助运动预测,减少视觉跟踪丢失。
2. 精度评估指标
| 指标 | 定义 | 典型值 |
|---|---|---|
| 均方根误差(RMSE) | 估计位置与实际位置的欧氏距离标准差 | VINS-Mono:0.1-0.3 m |
| 平均定位误差(ALE) | 所有测试点的平均误差 | UWB融合系统:0.07 m |
| 累积误差(SLAM) | 长时间运行后的位置漂移量 | VI-SLAM:<1% 路径长度 |
| 实时性(FPS) | 每秒处理帧数 | 手机端优化后:20-30 FPS |
3. 与其他技术对比
| 技术 | 精度 | 基础设施依赖 | 适用场景 |
|---|---|---|---|
| VINS | 0.1-1 m | 无 | 动态环境、无标定 |
| UWB | 0.3-0.5 m | 需部署基站 | 工厂、仓储 |
| WiFi指纹 | 3-5 m | 需信号地图 | 商场、机场 |
| 蓝牙信标 | 1-3 m | 需部署信标 | 室内导航 |
五、挑战与未来方向
- 硬件限制:手机IMU精度低(零偏稳定性差)、算力有限,需算法轻量化与硬件协同优化。
- 动态环境:多目标交互场景下的鲁棒性提升,如融合语义信息。
- 大规模部署:地图复用与增量式建图技术,减少重复计算。
- 深度学习融合:端到端位姿估计(如CNN-LSTM)、自适应特征提取。
六、结论
视觉-惯性融合技术为室内导航提供了无需外部基础设施的高效解决方案,尤其在AR/VR、机器人导航等领域潜力显著。未来研究需在算法效率、动态环境适应性和多模态融合(如结合UWB/WiFi)方面进一步突破,以满足智能手机端的大规模应用需求。
📚2 运行结果
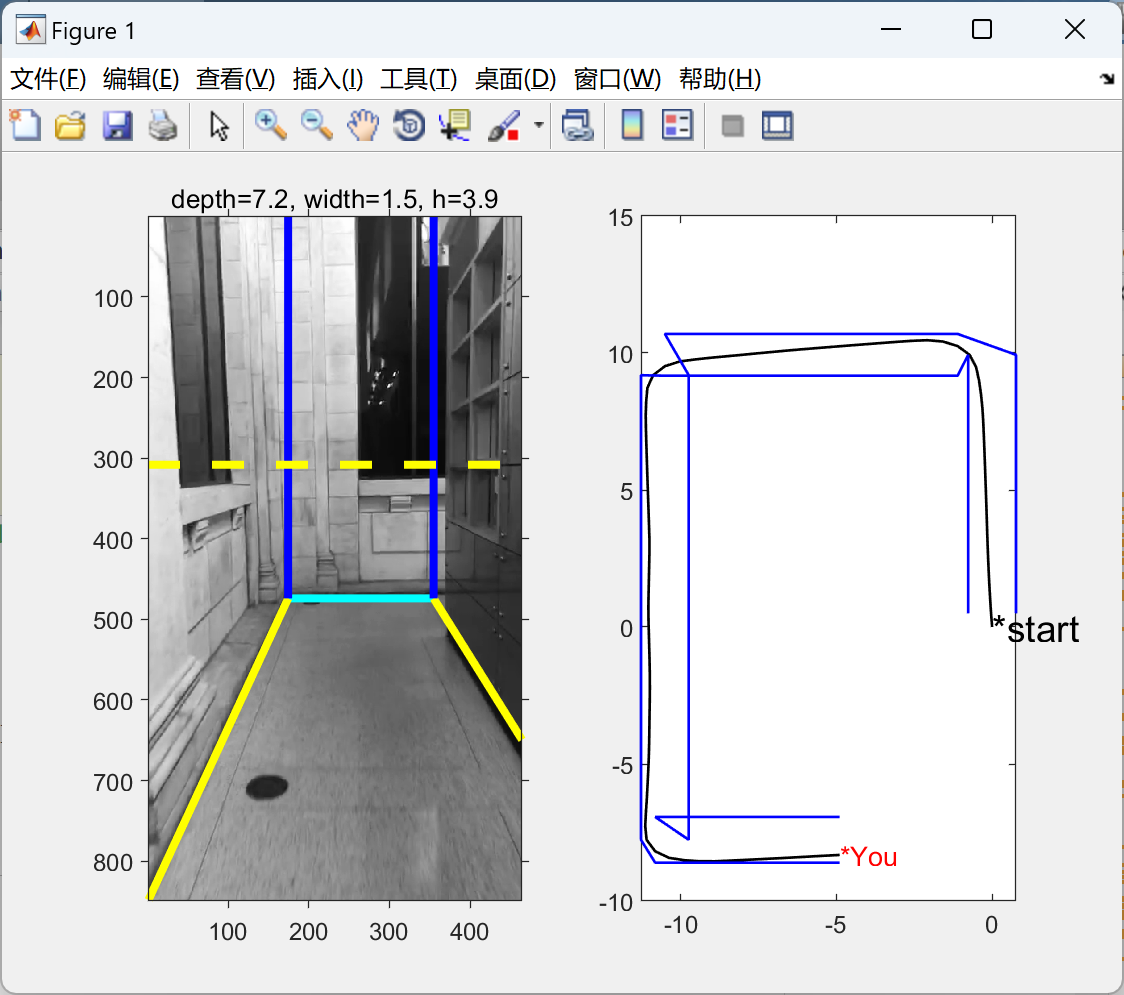
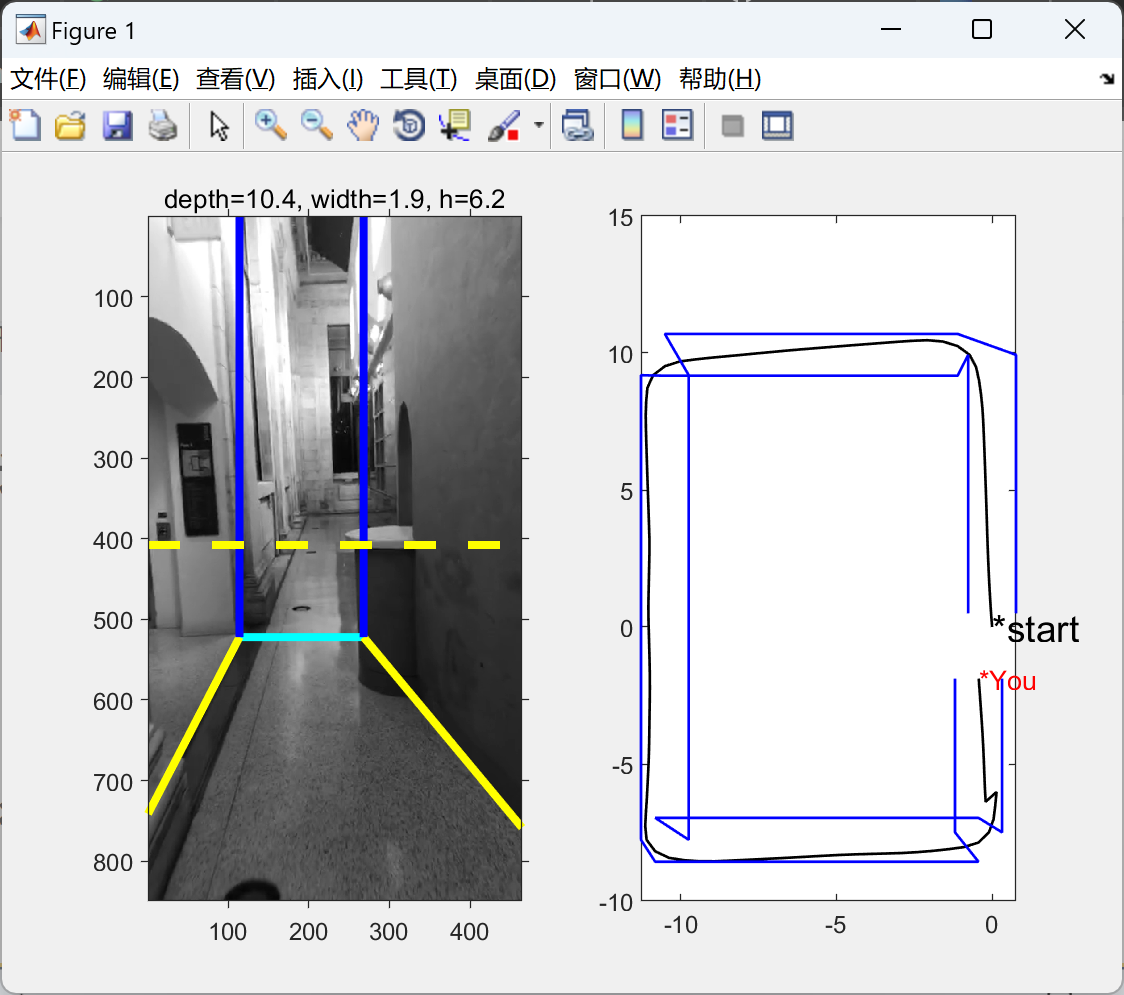
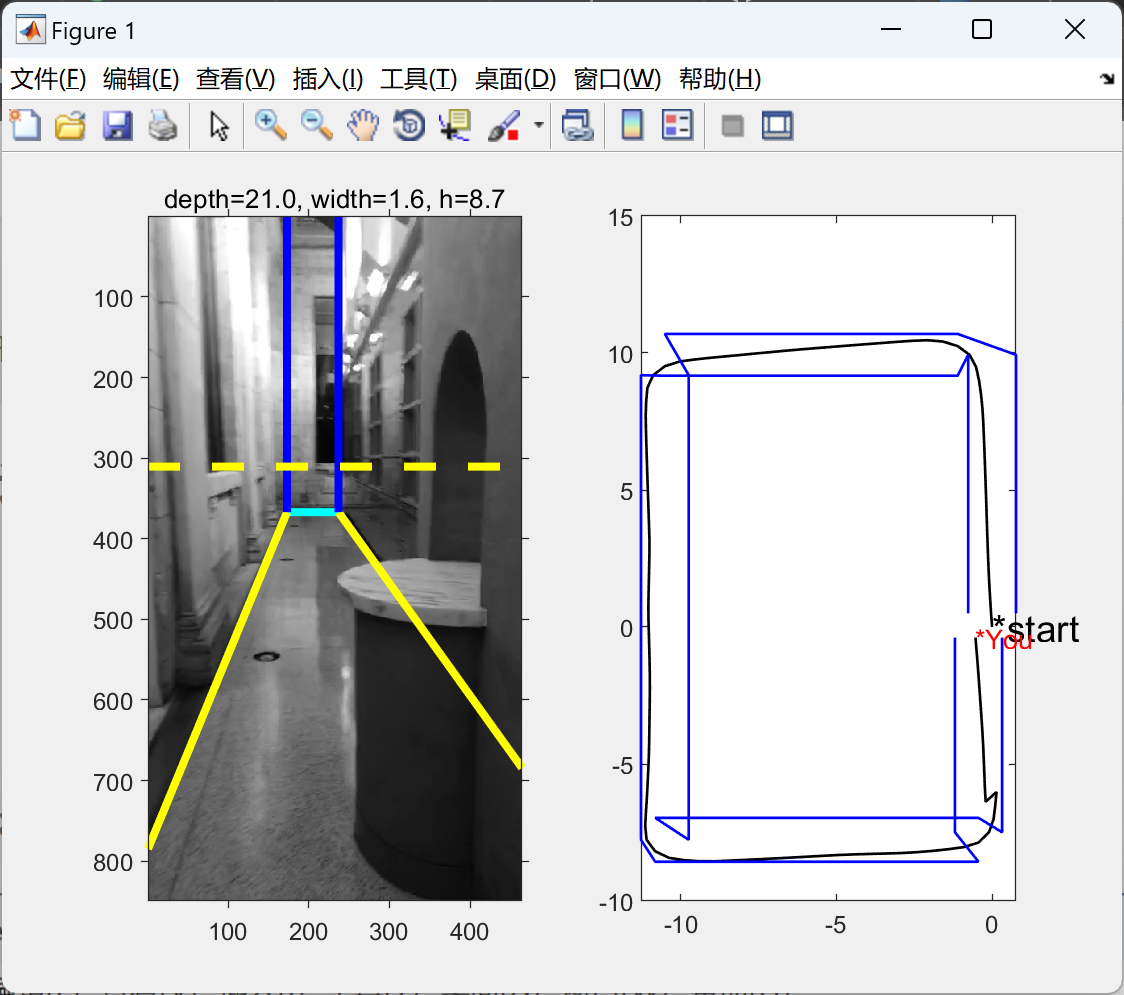
部分代码:
%% Read Entire Video %%%%
mov = VideoReader('sample_video\aclab_video_TF.mp4'); %WIN_20170508_13_45_27_Pro
i=0;
while hasFrame(mov)
i=i+1;
vid = rgb2gray(readFrame(mov));
video(:,:,i)=vid;
end
%% Synchonize IMU and Video
video=video(:,:,1:size(video,3)/339:end); %obtain this number from csv file
%% Read IMU data %%%
showfig = 0;
l_start = 1;
l_end = 339; %size(video,3); obtain this number from csv file
frq=30;
filename='sample_video\aclab_data_TF.csv';
[data_IMU,data_lables,t] = iPhone_IMU_reading(filename,frq,l_start,l_end,showfig);
%%%Acceleration & Gravity data
x_g = data_IMU(:,5)*9.81; % X gravity * g
y_g = data_IMU(:,6)*9.81; % Y gravity * g
z_g = data_IMU(:,7)*9.81; % Z gravity * g
acc_x=data_IMU(:,2)*9.81; % X acceleration * g
acc_y=data_IMU(:,3)*9.81; % Y acceleration * g
acc_z=data_IMU(:,4)*9.81; % Z acceleration * g
%%%The 3 attitudes reported by iPhone
AttPitch = data_IMU(:,12); %rotation over x axis
AttYaw = data_IMU(:,13); %rotation over z axis
AttYaw = ThetaCorrect(AttYaw);
AttRoll = data_IMU(:,14); %rotation over y axis
%%%Angle computed by integration of gyro measurement
x_gyro = data_IMU(:,15);
y_gyro = data_IMU(:,16);
z_gyro = data_IMU(:,17);
delta_t = [t(1) ; t(2:end) - t(1:end-1)];
pitch_gyro = cumsum(x_gyro.*delta_t,1);
roll_gyro = cumsum(y_gyro.*delta_t,1);
yaw_gyro = cumsum(z_gyro.*delta_t,1);
%%%Angle computed by geometry of gravity
pitch_g = atan2(y_g , z_g) + pi;
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
A. Farnoosh, M. Nabian, P. Closas and S. Ostadabbas, "First-person indoor navigation via vision-inertial data fusion," 2018 IEEE/ION Position, Location and Navigation Symposium (PLANS), Monterey, CA, USA, 2018, pp. 1213-1222, doi: 10.1109/PLANS.2018.8373507. keywords: {Estimation;Cameras;Three-dimensional displays;Accelerometers;Indoor navigation;Simultaneous localization and mapping;Computer vision;Data fusion;Expectation maximization algorithm;In-door navigation;Simultaneous localization and mapping (SLAM)},



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











