







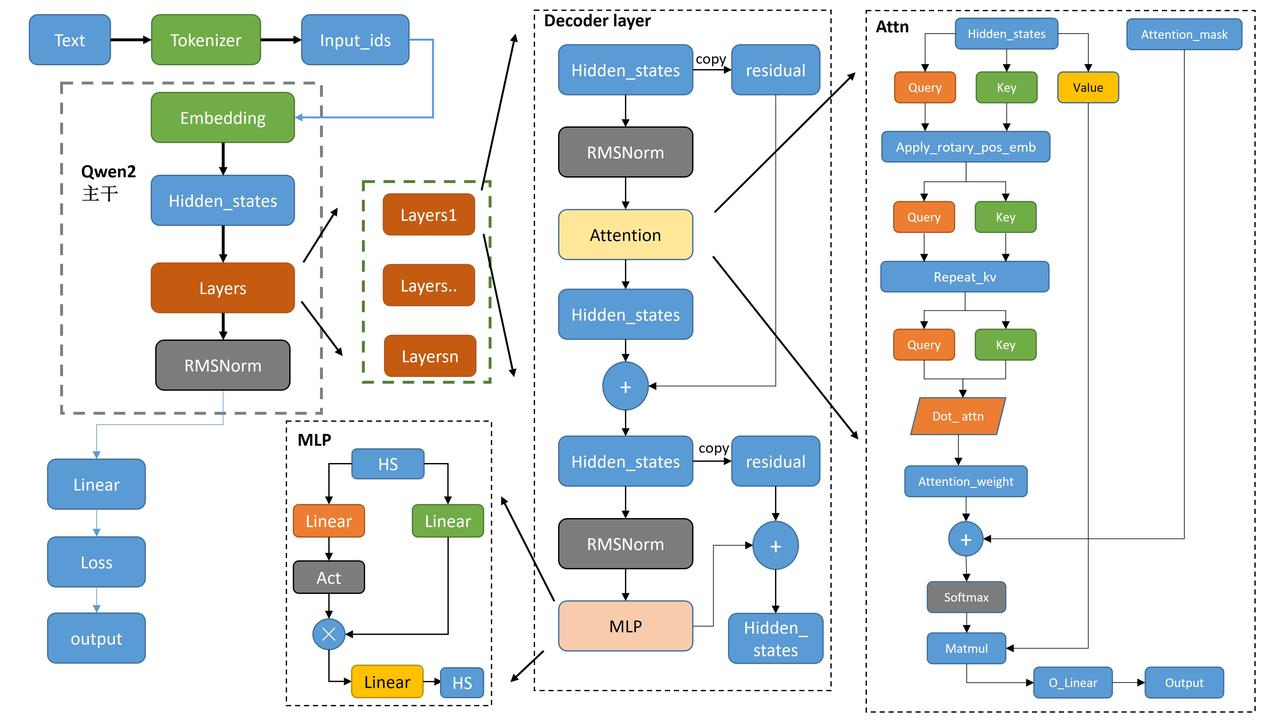
-
左侧部分 (Qwen2 部分):
- 文本输入通过 Tokenizer 编码为 Input_ids,之后输入到 Embedding 层。
- Embedding 输出经过 Hidden_states,然后传递给多个 Layers 层。每个 Layer 层通过 RMSNorm 进行正则化处理。
- Layers 的输出会进入右侧的 Decoder layer。
-
Decoder Layer (解码层):
- Hidden_states 经过 RMSNorm 正则化后,传递给 Attention 模块。
- 在 Attention 模块内,输入分为 Query、Key 和 Value,用于注意力机制的计算。
- 经过 Attention 后的输出再经过另一个 RMSNorm 处理,并通过 MLP(多层感知器)进一步处理。
- 每一步都有残差连接(Residual),保证信息流动不会丢失。
-
Attention 机制 (右侧部分):
- Hidden_states 分别生成 Query、Key 和 Value,并应用 Rotary positional embedding 进行位置编码。
- 这些编码后的 Query、Key 和 Value 经过注意力计算,生成 Attention_weight。
- Attention_weight 通过 Softmax 归一化,并与 Value 相乘(Matmul),最后输出为 O_Linear。
-
MLP 模块:
- MLP 由两层线性层(Linear)和激活函数(Act)组成。它负责进一步的特征提取。
-
输出层:
- 最后,通过线性层计算 Loss,并生成最终的 Output。
基于 PyTorch 和 HuggingFace Transformers 库的 Qwen2 模型实现。代码结构的简要说明:
1. 导入部分:
- 导入了相关的 PyTorch 模块(如
nn,torch.nn.functional,torch.utils.checkpoint等)。 - 从 HuggingFace 的
transformers库中导入了通用的模型工具和实用函数。
2. 核心常量和配置:
_CHECKPOINT_FOR_DOC和_CONFIG_FOR_DOC:定义文档中用于引用的检查点和配置。QWEN2_PRETRAINED_MODEL_ARCHIVE_LIST:列出预训练模型的名称。
3. 辅助函数:
_get_unpad_data:用于处理未填充的数据。rotate_half和apply_rotary_pos_emb:用于处理旋转位置嵌入(Rotary Position Embedding)的辅助函数。
4. 核心组件类:
Qwen2RMSNorm:Qwen2 版本的 RMS 正则化层,类似于T5LayerNorm。Qwen2RotaryEmbedding:处理旋转位置嵌入(Rotary Position Embedding)的类。Qwen2MLP:多层感知器(MLP),用于模型中的全连接层。Qwen2Attention:注意力机制的实现,支持普通多头注意力机制和滑动窗口注意力。Qwen2FlashAttention2和Qwen2SdpaAttention:两种注意力机制的变体,分别是基于 Flash Attention 和 SDPA 的实现。Qwen2DecoderLayer:Qwen2 解码器层,结合注意力机制和 MLP。Qwen2PreTrainedModel:继承自PreTrainedModel,提供模型的基本功能和初始化。
5. Qwen2 模型类:
Qwen2Model:基础 Qwen2 模型,由多个解码器层组成,处理输入嵌入、注意力掩码和位置编码。Qwen2ForCausalLM:用于自回归生成任务的 Qwen2 模型,添加了语言模型头部(linear 层)。Qwen2ForSequenceClassification:用于序列分类任务的 Qwen2 模型,使用最后一个 token 的隐藏状态进行分类。
6. 模型文档说明:
- 添加了文档说明,解释如何使用这些模型,以及输入和输出的格式。
7. 前向传播逻辑:
forward函数是每个模型的核心方法,负责计算前向传播并输出结果。- 模型通过输入的
input_ids或inputs_embeds进行处理,并返回隐藏状态、注意力权重、缓存的键值对等。
8. 训练相关功能:
- 支持梯度检查点(
gradient_checkpointing)以节省内存。 - 支持缓存键值对(
past_key_values)以加速自回归生成任务。
9. 损失函数:
- 对于分类任务,使用交叉熵损失(
CrossEntropyLoss)。 - 对于回归任务,使用均方误差损失(
MSELoss)。
10. 模型初始化和权重加载:
- 使用
post_init来初始化权重。 - 提供了方法来获取和设置模型的输入嵌入层和输出层(
get_input_embeddings和get_output_embeddings)。
源码阅读部分:
Qwen2Model的__init__函数
def __init__(self, config: Qwen2Config):
# 调用父类的构造函数并传递配置
super().__init__(config)
# 获取填充token的索引
self.padding_idx = config.pad_token_id
# 设置词汇表大小
self.vocab_size = config.vocab_size
# 初始化嵌入层,输入为词汇表大小,输出为隐藏层大小,忽略填充token
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
# 初始化解码器层列表,包含num_hidden_layers个Qwen2DecoderLayer
self.layers = nn.ModuleList(
[Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)
# 设置注意力机制的实现方式
self._attn_implementation = config._attn_implementation
# 初始化RMS正则化层,用于正则化隐藏状态
self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 是否启用梯度检查点,以节省内存,默认关闭
self.gradient_checkpointing = False
# 调用后续的初始化过程,通常是权重初始化
self.post_init()
下面这个博客中已经讲的很清楚了
https://blog.csdn.net/qq_37021523/article/details/138901191
https://zhuanlan.zhihu.com/p/695112177
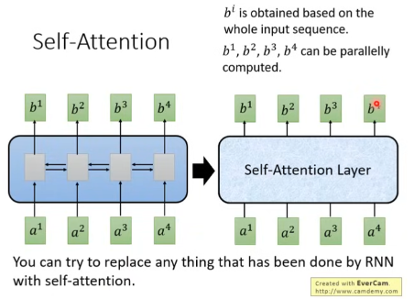
Transformer具体干了啥↓
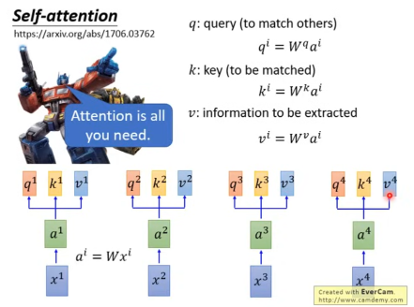
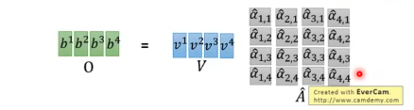
接下来是拿每一个query q 去对每个 key k 做attention
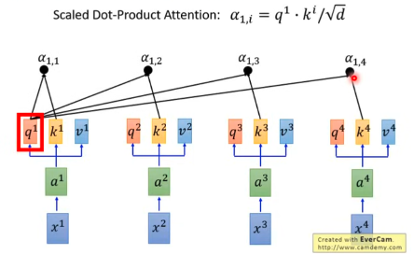
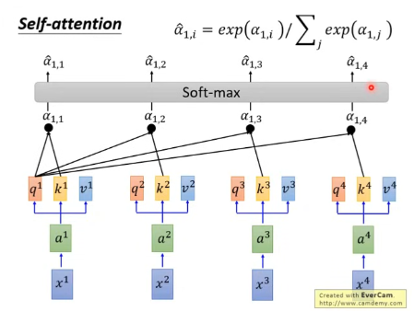
得到b1
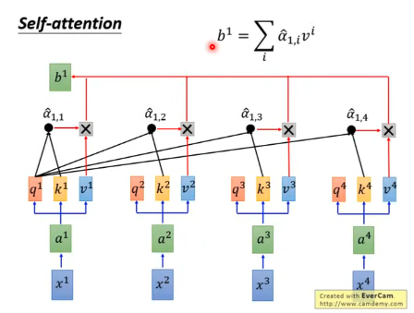
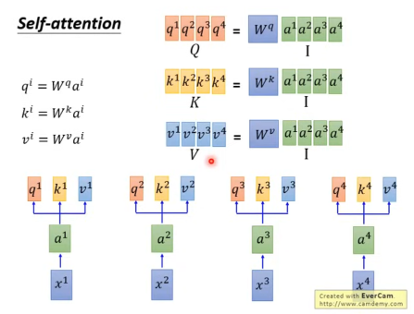
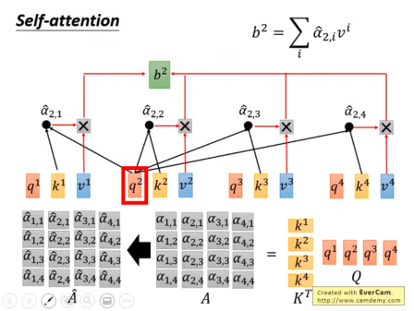
在上图中,
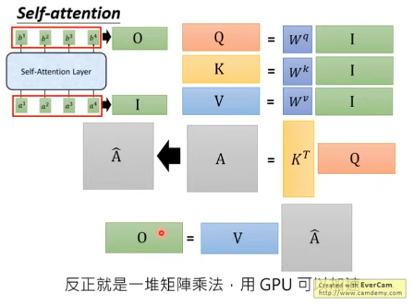
Multi-head Self-attention
不同的head关注点不一样
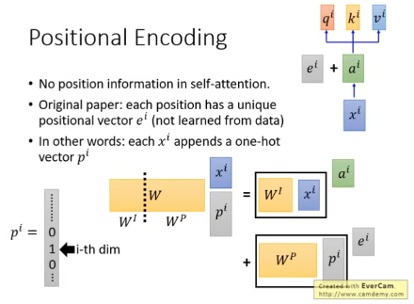
No position information in self-attention, e^i代表的是位置的信息。
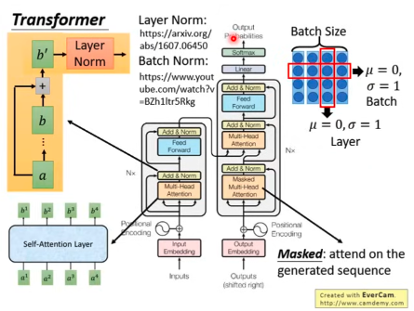
图片来自:https://www.youtube.com/watch?v=ugWDIIOHtPA&t=4s&ab_channel=Hung-yiLee


















 6065
6065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











