









一、Bug算法简介
Bug 算法是一种基于追踪障碍物的路径规划算法,它模拟了一种昆虫寻找巢穴的行为,因此得名Bug算法。Bug算法的基本思路是:当机器人遇到障碍物时,他会沿着障碍物的边缘行走,直到到达目标点。该算法可以分为两个主要步骤:表示空间中的点和算法实现。
在Bug算法中,空间被表示为二维网格,其中每个单元格可以是空的,包含障碍物或表示起点和终点。每个单元格可以表示一个网格点,该点的坐标可以用(x,y)表示。通过搜索算法,机器人可以在此网格中寻找路径,并移动到相应的点。Bug算法可以分为两个主要阶段:接近目标(Approach Phase)和沿障碍物行走(Follow Boundary Phase)。
(1)接近目标
在接近阶段,机器人按直线行驶到目标点,如果遇到障碍物,则计算机器人到目标点的距离,然后自动开始沿着障碍物行走,直到到达目标点或绕过障碍物。
(2)沿障碍物行走
在Bug算法中,移动机器人沿连接目标点和 起点的最短直线前进,在遇到障碍物时采用边缘 跟踪的方法绕过障碍物,然后再次沿直线前进。 Bug算法在移动机器人未知环境导航中是经典通 用的算法。需求的存储容量小。如果在机器人起 点和目标终点间存在可行路径的话,那么这种纯 粹的应激式算法肯定会完成路径规划,保证算法 的全局收敛。 Bug算法在寻找两点间可行路径上并不能保 证最优。标准的算法是在起点和终点的直线方向 上产生,遇到障碍物时沿相同的方向绕行。这种 算法能保证寻找到一条安全路径,但并不保证能 迅速到达目标终点,如下图所示:
Bug算法由两种模式来共同保证全局收敛: 趋向目标模式(Moving toward the Goal)和边线 沿走模式(Boundary Following)。开始时移动机 器人执行“趋向目标”模式,遇到障碍物时转向 “边线沿走”模式。
(3)Bug1算法
在Bug1算法中,机器人被假定为搭载接触传感器并能获取精确位置,且能测量两点之间的距离:

(4)Bug2算法
在Bug2算法中,机器人遇到障碍物后,机器人沿障碍物边界运动,直到找到起始点连接的直线上比初始接触障碍物点距目标更近的点。若机器人再次遇到原来的出发点,则没有通往目标的路径。

参考文献:
[1]康亮,赵春霞,郭剑辉.未知环境下基于三次螺线Bug算法的移动机器人路径规划[J].工程图学学报, 2010(1):9.DOI:10.3969/j.issn.1003-0158.2010.01.006.
[2]赵文瑜.基于Bug算法的移动机器人路径规划研究[J].无线互联科技, 2020, 17(6):2.DOI:CNKI:SUN:WXHK.0.2020-06-050.
二、部分代码
import numpy as np
import matplotlib.pyplot as plt
show_animation = True
class BugPlanner:
def __init__(self, start_x, start_y, goal_x, goal_y, obs_x, obs_y):
self.goal_x = goal_x
self.goal_y = goal_y
self.obs_x = obs_x
self.obs_y = obs_y
self.r_x = [start_x]
self.r_y = [start_y]
self.out_x = []
self.out_y = []
for o_x, o_y in zip(obs_x, obs_y):
for add_x, add_y in zip([1, 0, -1, -1, -1, 0, 1, 1],
[1, 1, 1, 0, -1, -1, -1, 0]):
cand_x, cand_y = o_x+add_x, o_y+add_y
valid_point = True
for _x, _y in zip(obs_x, obs_y):
if cand_x == _x and cand_y == _y:
valid_point = False
break
if valid_point:
self.out_x.append(cand_x), self.out_y.append(cand_y)
def mov_normal(self):
return self.r_x[-1] + np.sign(self.goal_x - self.r_x[-1]), \
self.r_y[-1] + np.sign(self.goal_y - self.r_y[-1])三、部分结果
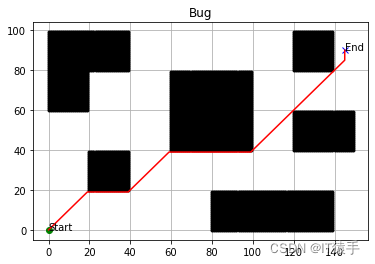
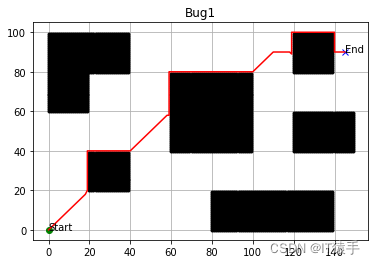

四、完整Python代码
见下方名片

















 1642
1642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









