






**PID/LQR/MPC自行总结使用**
自学控制相关知识,已经一年多了,现在回头看看还是有很多模糊不明确的地方,准备借此机会进行总结一下,第一次写博客,如果错误和不合理之处,请批评指正。
1.pid
包括三部分:kp,ki,kd
kp:比例系数,可迅速反映系统的当前基本误差,从而减小误差,但无法消除稳态误差,比例过大会造成系统不稳定。
ki:积分系数,反映系统在一个周期内的累计误差,只要系统内存在误差,积分作用就会一直发挥作用,输出控制量对系统进行控制,积分作用太强则会使得系统超调加大,系统振荡。
kd:微分系数,反映系统误差的变化率,具有预见性,可以减小超调,提高系统的稳定性,加快系统的动态响应,但会放大噪声。
频域表达式为:
G
(
s
)
=
K
p
+
K
i
/
s
+
K
d
∗
s
.
G(s) = Kp+Ki/s+Kd*s\,.
G(s)=Kp+Ki/s+Kd∗s.
时域表达式为:
u
(
t
)
=
K
p
∗
e
(
t
)
+
K
i
∗
∫
0
t
e
(
t
)
d
t
+
K
d
∗
d
e
(
t
)
d
t
.
u(t) =Kp*e(t)+Ki* \int_0^t e(t)dt\,+Kd*\frac{de(t)}{dt}.
u(t)=Kp∗e(t)+Ki∗∫0te(t)dt+Kd∗dtde(t).
离散化后为:
u
(
k
)
=
u
(
k
−
1
)
+
(
K
p
+
K
i
∗
T
+
K
d
T
)
∗
e
(
k
)
−
(
K
p
+
2
K
d
T
)
)
∗
e
(
k
−
1
)
+
K
d
T
∗
e
(
k
−
2
)
u(k) =u(k-1)+(Kp+Ki*T+\frac{Kd}{T})*e(k)-(Kp+\frac{2Kd}{T}))*e(k-1)+\frac{Kd}{T}*e(k-2)
u(k)=u(k−1)+(Kp+Ki∗T+TKd)∗e(k)−(Kp+T2Kd))∗e(k−1)+TKd∗e(k−2)
其中,T为控制器的计算周期,即dt。
比例系数为:Kp
积分系数为:Ki= KpT/Ti
微分系数为:Kd= KpTd/T
参考资料:
https://www.cnblogs.com/qsyll0916/p/8580211.html
https://blog.csdn.net/yunddun/article/details/107720644
2.LQR
在基本控制理论的基础上,进一步设计一个代价函数,用于优化控制量,代价函数一般设置为系统达到稳定状态以及状态偏差最小,和控制量较小。研究对象为以状态空间方程形式给出的线性系统。
J
=
1
2
∫
0
∞
x
T
Q
x
+
u
T
R
u
d
t
.
J=\frac{1}{2} \int_0^\infty x^TQx+u^TRudt\,.
J=21∫0∞xTQx+uTRudt.
代价函数一般要保证为正值,所以使用转置乘以本身,即达到平方的效果
Q,R分别为状态权重矩阵和控制权重矩阵。
Q半正定矩阵,R为正定矩阵。
LQR求解:
令
u
=
−
K
x
u=-Kx
u=−Kx
代入代价函数:
J
=
1
2
∫
0
∞
x
T
(
Q
+
K
T
R
K
)
x
d
t
.
J=\frac{1}{2} \int_0^\infty x^T(Q+K^TRK)xdt\,.
J=21∫0∞xT(Q+KTRK)xdt.
假设存在一个常量矩阵P使得:
d
d
t
(
x
T
P
x
)
=
−
x
T
(
Q
+
K
T
R
K
)
x
.
(
i
f
)
\frac{d}{dt} (x^TPx)=-x^T(Q+K^TRK)x. (if)
dtd(xTPx)=−xT(Q+KTRK)x.(if)
反代回原代价函数可得;
J
=
−
1
2
∫
0
∞
d
d
t
(
x
T
P
x
)
d
t
.
J=-\frac{1}{2} \int_0^\infty \frac{d}{dt} (x^TPx)dt\,.
J=−21∫0∞dtd(xTPx)dt.
解上式可得:
J
=
1
2
(
x
(
0
)
T
P
x
(
0
)
)
,
.
J=\frac{1}{2} (x(0)^TPx(0)),.
J=21(x(0)TPx(0)),.
微分展开if式左侧并移项得:
x
˙
T
P
x
+
x
T
P
x
˙
+
x
T
Q
x
+
x
T
K
T
R
K
x
=
0
\dot{x}^TPx+x^TP\dot{x}+x^TQx+x^TK^TRKx=0
x˙TPx+xTPx˙+xTQx+xTKTRKx=0
中间省略一系列推导过程可得:
A
T
P
+
P
A
+
Q
−
P
B
R
−
1
B
T
P
=
0
A^TP+PA+Q-PBR^-1B^TP=0
ATP+PA+Q−PBR−1BTP=0
A,B,Q,R都已知,可以解出上述Riccati方程
利用matlab即可求解:K = lqr(A,B,Q,R)
参考资料:
https://www.cnblogs.com/niulang/p/9066759.html
https://blog.csdn.net/gophae/article/details/101981600
https://blog.csdn.net/zhouyy858/article/details/107606500
3.MPC
与LQR一样,MPC也是进行优化,它们的目标函数都是多个优化目标乘以不同的权重然后进行求和得到,区别在于,在同一控制周期内,LQR只计算一次,而MPC则是一个滚动优化的过程,在每一个采样周期内计算得到一组控制序列,但是只是将第一个控制的值发给控制器。
MPC是一种基于模型的闭环优化控制策略。主要包括预测模型,滚动优化,反馈校正三个部分。其优点在于具有显式处理约束的能力这是因为:将约束加到未来的输入,输出或者状态量上,就可以改变模型对于系统未来动态行为的预测,且可以将约束放在一个在线求解的二次规划或者非线性规划问题中。
3.1.预测模型
预测模型要根据具体的工程背景来表示,目前用的较多的是状态空间模型。
一般我们得到的都是连续空间模型,需要将其进行离散化,得到离散状态下的状态空间方程。
x
(
k
+
1
)
=
A
(
T
)
x
(
k
)
+
B
(
T
)
u
(
k
)
.
x(k+1) =A(T)x(k)+B(T)u(k).
x(k+1)=A(T)x(k)+B(T)u(k).
其中:
A
(
T
)
=
T
A
+
I
.
A(T) = TA+I.
A(T)=TA+I.
B
(
T
)
=
T
B
.
B(T) = TB.
B(T)=TB.
建立新的状态方程为:
ξ
(
k
)
=
[
x
(
k
)
,
u
(
k
−
1
)
]
T
.
\xi(k) = [x(k),u(k-1)]^T.
ξ(k)=[x(k),u(k−1)]T.
ξ
(
k
+
1
)
=
A
~
ξ
(
k
)
+
B
~
Δ
u
(
k
)
\xi(k+1) = \tilde{A}\xi(k)+ \tilde{B}\Delta u(k)
ξ(k+1)=A~ξ(k)+B~Δu(k)
A
~
=
[
A
B
0
(
N
u
,
N
x
)
I
(
N
u
)
]
\tilde{A}=\begin{bmatrix} A & B \\ \\ 0(Nu,Nx) & I(Nu) \end{bmatrix}
A~=⎣⎡A0(Nu,Nx)BI(Nu)⎦⎤
B
~
=
[
B
I
(
N
u
)
]
\tilde{B}=\begin{bmatrix} B \\ \\ I(Nu) \end{bmatrix}
B~=⎣⎡BI(Nu)⎦⎤
Nx为状态量的个数
Nu为控制量的个数
此处这么添加应该是为了状态空间方程维度的一致性,便于后续控制
针对此系统可以得知未来系统p步的状态和输出,可以依靠上述方程计算得出。令系统方程为:
Y
(
k
)
=
S
ξ
(
k
)
+
S
u
Δ
u
(
k
)
.
Y(k) =S_\xi(k)+S_u\Delta u(k).
Y(k)=Sξ(k)+SuΔu(k).
则一步一步推算可得:


在此基础上构建代价函数可得:
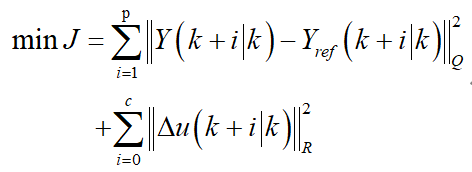
在此基础上添加控制量和状态量等约束,就可以通过计算机来求解,得到未来k步可能需要的控制增量:

取控制增量的第一项作为实际的控制增量,再根据上一步的控制输入u(k-1)即可得到当前步的实际控制输入:
u
(
k
)
=
u
(
k
−
1
)
+
Δ
u
(
k
)
u(k)=u(k-1)+\Delta u(k)
u(k)=u(k−1)+Δu(k)
参考资料:
https://blog.csdn.net/u013914471/article/details/83824490
Torque Coordinated Control of Four In-Wheel Motor Independent-Drive Vehicles With Consideration of the Safety and Economy
https://zhuanlan.zhihu.com/p/99409532

















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









