








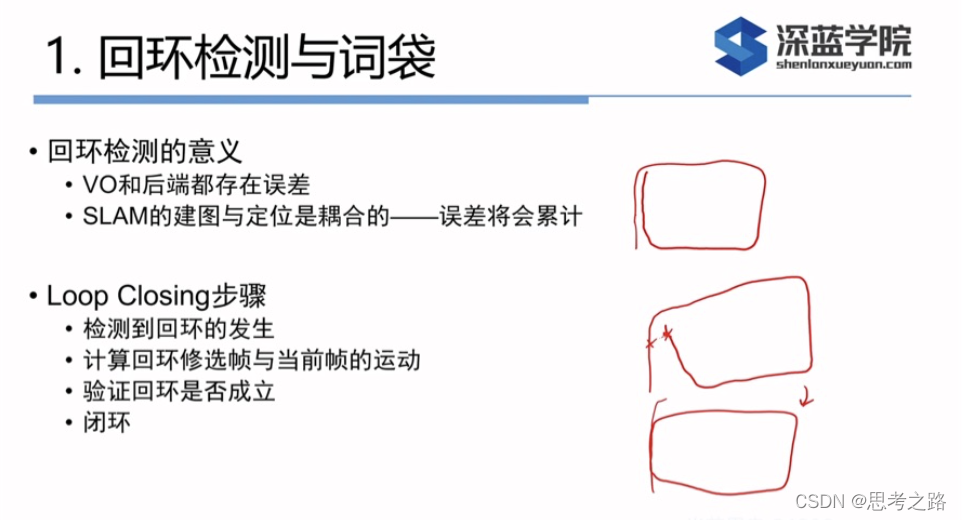
回环检测的意义:前端提供特征点的提取和轨迹,地图的初始化,后端负责优化这些数据。如果像里程计一样只考虑相邻时间上的关键帧,那么误差就会出现累积,无法构建全局一致的轨迹和地图。但是,回环检测模块能够给出除了相邻帧的一些时间更久远的约束,相机经过同一个地方,采集到了相似的数据。而回环检测的关键就是如何有效的检测出相机经过同一个地方,如果能够成功的检测到,就可以为后端的位姿图提供更多的数据,使之得到更好的估计,得到全局一致的估计。
假阳性:感知偏差 假阴性:感知变异
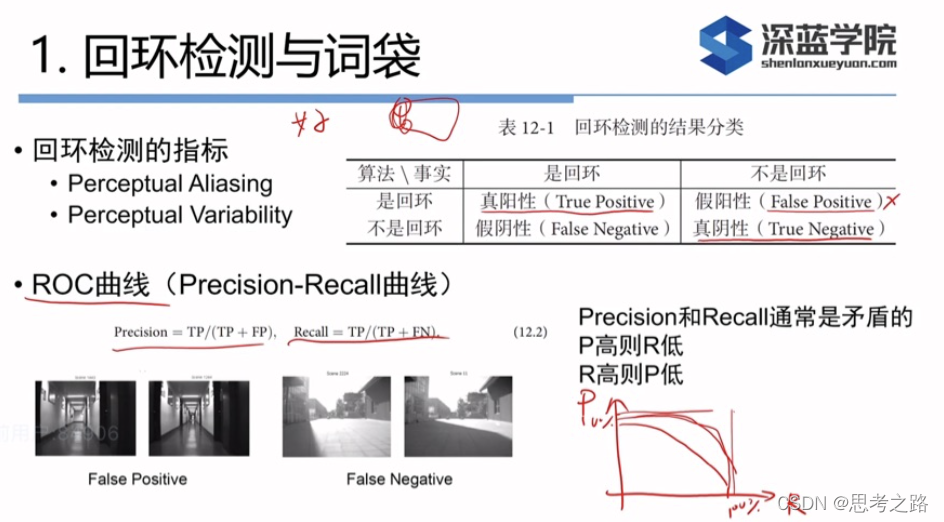
算法需要设置参数,当某个阈值提高时,算法更为严格,检测出更少的回环,使准确率下降,反之,选择宽松的配置,检测出的回环数量将增加,得到更高的召回率,但可能其中混有不是回环的情况,导致准确率下降。
在SLAM中,我们对准确率要求高,召回率则宽容一些,由于假阳性的回环将在后端的位姿图中添加错误的边,会导致优化算法给出完全错误的结果。相比之下,召回率低一些,顶多有部分的回环没有检测出来,地图可能会受一些累积误差的影响,然而只需一两次的回环就可以消除了,所以我们在选择回环检测算法时,更倾向于把参数设置的更严格,或者检测之后在加上回环验证。
在词袋中,可以使用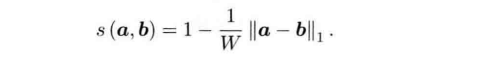 来度量图像之间的相似程度。当a,b 两个向量完全一样时,将的到1;完全相反时(a为0的地方b为1)得到0.这样就定义了两个描述向量相似性,也定义了图像之间的形似性。其中a,b向量代表的是图像中某个特征(单词)的有无。
来度量图像之间的相似程度。当a,b 两个向量完全一样时,将的到1;完全相反时(a为0的地方b为1)得到0.这样就定义了两个描述向量相似性,也定义了图像之间的形似性。其中a,b向量代表的是图像中某个特征(单词)的有无。
接下来,我们来介绍字典的生成,以及如何利用字典实际的计算两幅图像间的相似性。
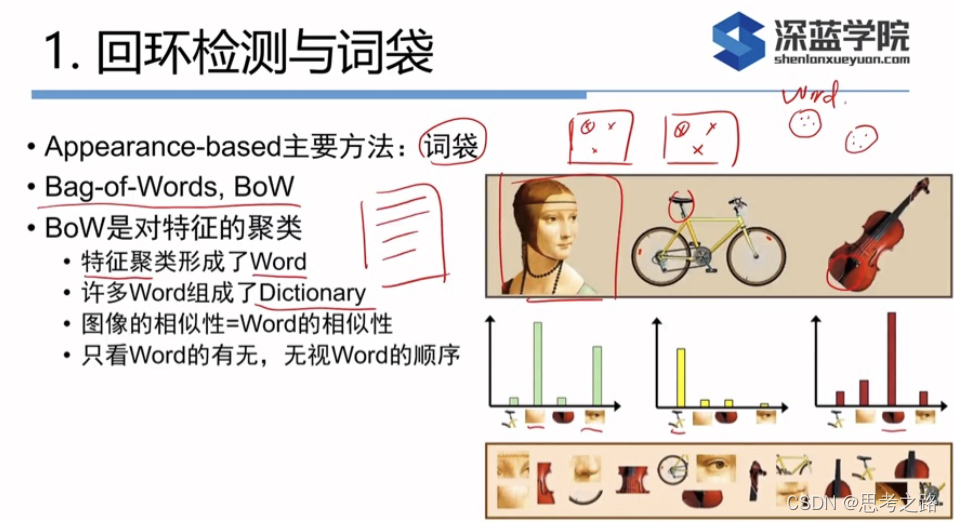
单词不是从单幅图像上得到的,而是某一类特征的组合,字典的生成类似一个聚类。
假设我们对大量的图像提取了特征点,例如有N个,现在找一个有K个单词的字典,每个单词可以看作局部相邻特征点的集合。

K-means需要指定聚类数量和随机选取中心点使得每次聚类结果不相同,涉及效率上的问题。随后有层次聚类,K-means++等算法弥补不足。
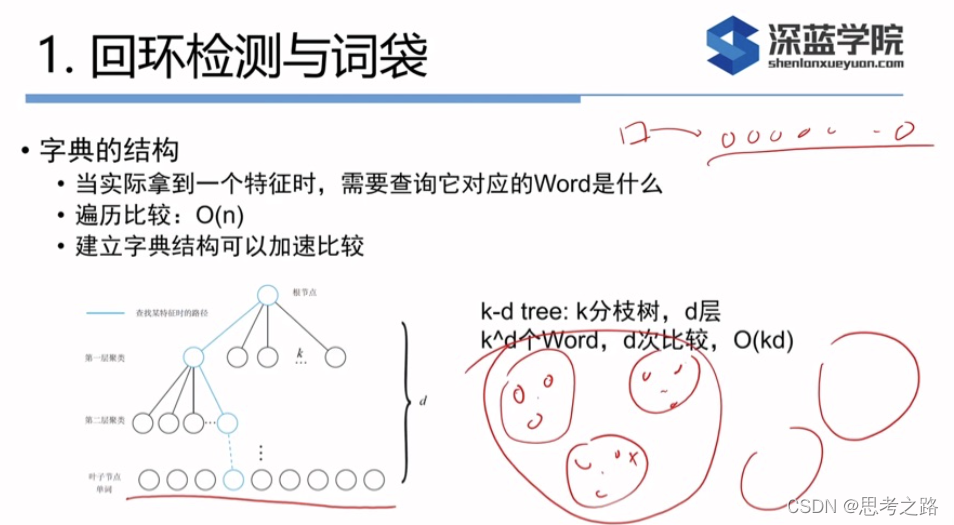
通过层次聚类,最终在叶子层构建了单词,而树结构中的中间节点仅快速查找时使用。着一个k分支,d深度的树,可以容纳
k
d
k_d
kd个单词,在查找某个给定的特征对应 的单词时只需要将它与每个中间节点的聚类中心作比较(d次),即可找到最后的单词,保证了对数级别的查找效率。
实例:训练字典
安装BoW库,使用10幅图像训练一个小字典。
#include "DBoW3/DBoW3.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <boost/format.hpp>
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
boost::format fmt_other("../data/%d.png");
//十张图像训练字典
int main(int argc, char**argv)
{
cout << "reading images....." << endl;
vector<Mat> images;
for(int i = 0; i< 10; i++)
{
images.push_back(imread((fmt_other % i ).str(), 0));
}
cout << "detecting ORB features..." << endl;
Ptr<Feature2D> detector = ORB::create();
vector<Mat> descriptors;
for(Mat &image:images) {
vector<KeyPoint> keypoint;
Mat descriptor;
detector->detectAndCompute(image, Mat(), keypoint, descriptor);
descriptors.push_back(descriptor);
}
cout << "create vocalulary..." << endl;
DBoW3::Vocabulary vocab;
vocab.create(descriptors);
cout << "vocabulary info:" << vocab << endl;
vocab.save("vocabulary.yaml");
cout << "done" << endl;
return 0;
}
运行结果:在对应的目录下生成yaml文件。

由运行结果可以看到:分支数量K是10, 深度L是5, 单词数量4487,Weightting 是权重,Scoring 是评分;
评分由下部分计算:
假设从一幅图像中 提取了N个特征,找到这N个特征对应的单词后,我们就相当于有了该图像单词列表中的分布,或者是置放图。就是有无的意思。但我们希望对单词的区分性或和重要性加以评估,给他们不同的权值以达到更好的效果。
TF-IDF是文档检索中常用的一种加权方式,也可用于BoW中
TF:某个单词在一幅图像中出现的频率高,则它的区分度就高;
IDF:某个单词在字典中出现的频率越低,分类图像时区分度越高;
在建立字典时就可以计算IDF:统计某个也子结点Wi中特征数量相对于所有特征数量的比率.
IDF部分:假设所有的特征 数量为n, wi数量为ni, 那么该单词的IDF为:
I
D
F
i
=
l
o
g
n
n
i
IDF_i = log \frac{n}{n_i}
IDFi=lognin
TF部分:某个特征在单幅图像中出现的频率。假设图像A中单词wi出现了ni次,而一共出现的次数为n次,那么TF为
I
D
F
i
=
n
i
n
IDF_i = \frac{n_i}{n}
IDFi=nni;
于是wi的权重等与TF和IDF:
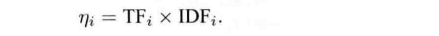
考虑权重后,可以对某幅图像A,它的特征点可对应到许多个单词,组成它的BoW,如下:A的计算;
由于相似的特征可能落在同一个类中,因此实际的
v
A
v_A
vA中存在大量的0。我们通过词袋用单个向量
v
A
v_A
vA描述了一幅图像A。这个向量是一个稀疏向量,它的非零部分指示了图像A中含有那些单词,而这部分的值为TF-IDF的值。

实例:相似度的计算
对十幅图像生成了字典,使用字典生成词袋并比较他们的差异。
实例代码:
#include "DBoW3/DBoW3.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
//根据训练的字典计算相似评分
int main(int argc, char **argv)
{
cout << "reading database" << endl;
DBoW3::Vocabulary vocab("./vocabulary.yaml");
if (vocab.empty()) {
cerr << "Vocabulary does not exist." << endl;
return 1;
}
cout << "reading images... " << endl;
vector<Mat> images;
for (int i = 0; i < 10; i++) {
string path = "../data/" + to_string(i + 1) + ".png";
images.push_back(imread(path));
}
cout << "detecting ORB features ... " << endl;
Ptr<Feature2D> detector = ORB::create();
vector<Mat> descriptors;
for (Mat &image:images) {
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute(image, Mat(), keypoints, descriptor);
descriptors.push_back(descriptor);
}
//方法一:通过图片间的比较看形似程度
cout << "comparing iamge whith images" << endl;
for(int i = 0; i < images.size(); i++) {
DBoW3::BowVector v1;
vocab.transform(descriptors[i], v1);
for(int j = i; j < images.size(); j++){
DBoW3::BowVector v2;
vocab.transform(descriptors[j], v2);
double score = vocab.score(v1, v2);
cout << "image" << i << "vs image" << j << ":" << score << endl << "---------------------"<< endl;;
}
cout << endl;
}
//通过图片间的比较看形似程度
cout << "comparing iamge whith images" << endl;
for(int i = 0; i < images.size(); i++) {
DBoW3::BowVector v1;
vocab.transform(descriptors[i], v1);
for(int j = i; j < images.size(); j++){
DBoW3::BowVector v2;
vocab.transform(descriptors[j], v2);
double score = vocab.score(v1, v2);
cout << "image" << i << "vs image" << j << ":" << score << "\t";
}
cout << endl;
}
//方法二:图像与数据库间的比较
cout << "comparing images with database " << endl;
DBoW3::Database db(vocab, false, 0);
for(int i = 0; i < descriptors.size(); i++)
db.add(descriptors[i]);
cout << "database info:" << db << endl;
for(int i = 0; i < descriptors.size(); i++) {
DBoW3::QueryResults ret;
db.query(descriptors[i], ret, 4);
cout << "searching for image" << i << "returns" << ret << endl << endl;
}
cout << "done." << endl;
}

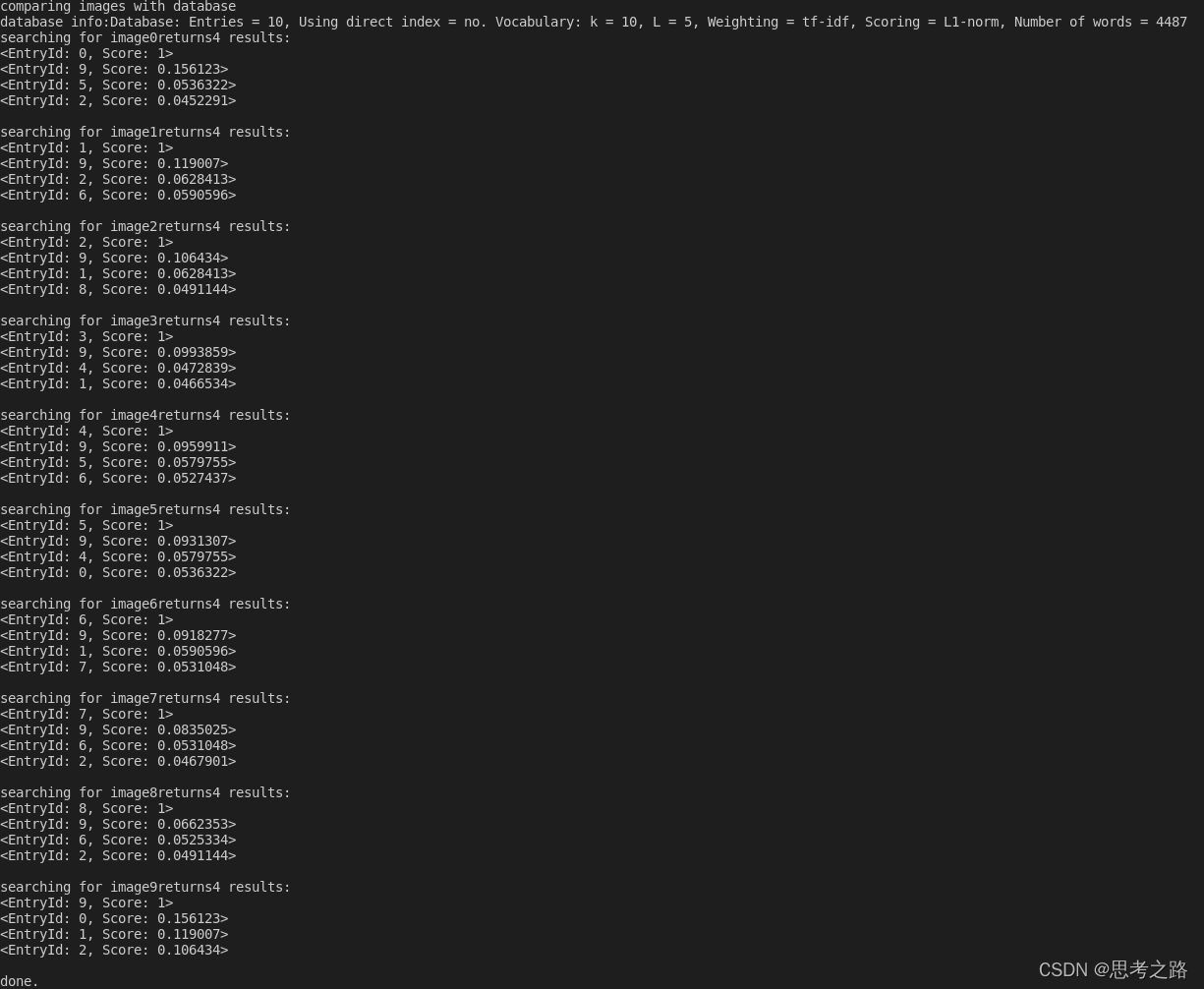
使用第二种方法,在数据库查询时,DBoW对上面的分数进行排序,给出最相似的结果。可以看出图1和图10最相似,但肉眼看相似度在百分之80以上,而实验结果却是无关图像的相似度约为百分之2, 相似图像的相似度约为百分之5,没有那么明显是不是训练的数据不够多,字典的规模不够大呢?
实例:增加字典规模: 对应的数据集没有给出,若是想要看数据集对形似性的影响,寻找相关的数据集放到对应的目录即可;
#include "DBoW3/DBoW3.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
string dataset_dir = argv[1];
ifstream fin ( dataset_dir+"/associate.txt" );
if ( !fin )
{
cout<<"please generate the associate file called associate.txt!"<<endl;
return 1;
}
vector<string> rgb_files, depth_files;
vector<double> rgb_times, depth_times;
while ( !fin.eof() )
{
string rgb_time, rgb_file, depth_time, depth_file;
fin>>rgb_time>>rgb_file>>depth_time>>depth_file;
rgb_times.push_back ( atof ( rgb_time.c_str() ) );
depth_times.push_back ( atof ( depth_time.c_str() ) );
rgb_files.push_back ( dataset_dir+"/"+rgb_file );
depth_files.push_back ( dataset_dir+"/"+depth_file );
if ( fin.good() == false )
break;
}
fin.close();
cout<<"generating features ... "<<endl;
vector<Mat> descriptors;
Ptr< Feature2D > detector = ORB::create();
int index = 1;
for ( string rgb_file:rgb_files )
{
Mat image = imread(rgb_file);
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
cout<<"extracting features from image " << index++ <<endl;
}
cout<<"extract total "<<descriptors.size()*500<<" features."<<endl;
// create vocabulary
cout<<"creating vocabulary, please wait ... "<<endl;
DBoW3::Vocabulary vocab;
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;
vocab.save( "vocab_larger.yml.gz" );
cout<<"done"<<endl;
return 0;
}
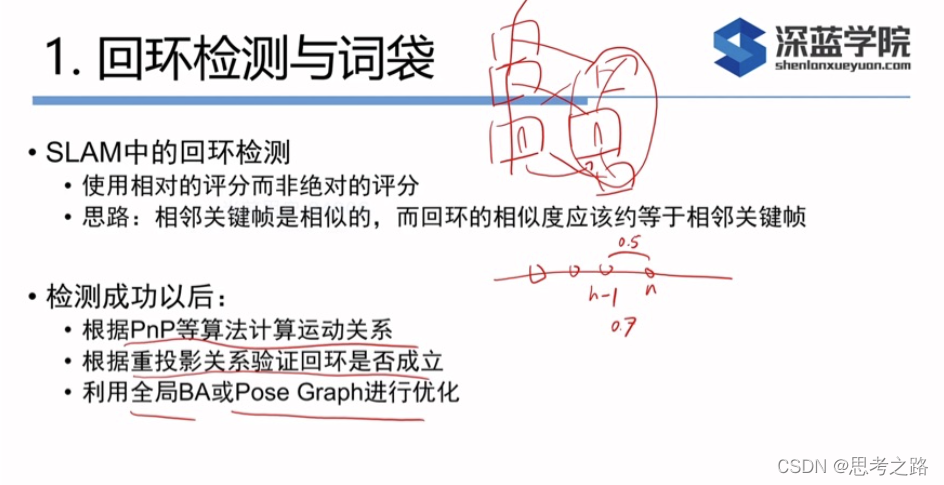
相似性评分的处理:两幅图像的绝对大小不好,例如:有些环境外观本就很相似,有些环境各个地方都有很大的不同。考虑这些情况,我们先取一个先验相似度
s
(
v
t
,
v
t
−
Δ
t
)
s(v_t, v_{t-\Delta t})
s(vt,vt−Δt),它表示某时刻关键帧图像与上一时刻的关键帧的相似性。。然后,其他的分值都参考这个值进行归一化:
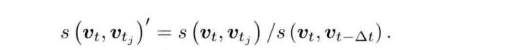
也就是说:如果当前帧与之前某个关键帧的相似读超过当前帧与上一个关键帧相似度的3倍,就可能存在循环。

稠密深度估计中,不同之处在与,我们无法把每个像素都当成特征点计算描述子。因此稠密深度古籍中,匹配环节很很重要,如何确定第一幅图中的像素在其他图中的位置,需要使用到极线搜索,块匹配技术。然后就可以像三角册量一样计算他们的深度,不同的是,需要通过对此三角测量让深度估计收敛,而不是使用一次。我们希望深度估计随着测量的增加从一个非常不确定的量,逐渐收敛到一个稳定的值——深度滤波器
相比与双目和RGB-D来说,单目测到的深度并不可靠,深度比较弱。
单个像素的亮度没有区分性,可以取p1周围wxw的小块,然后在极线上也取很多同样大小的小块进行比较,就可以在一定程度上提高区分性——块匹配,在这个过程中假设不同图像间整个小块的灰度值不变。
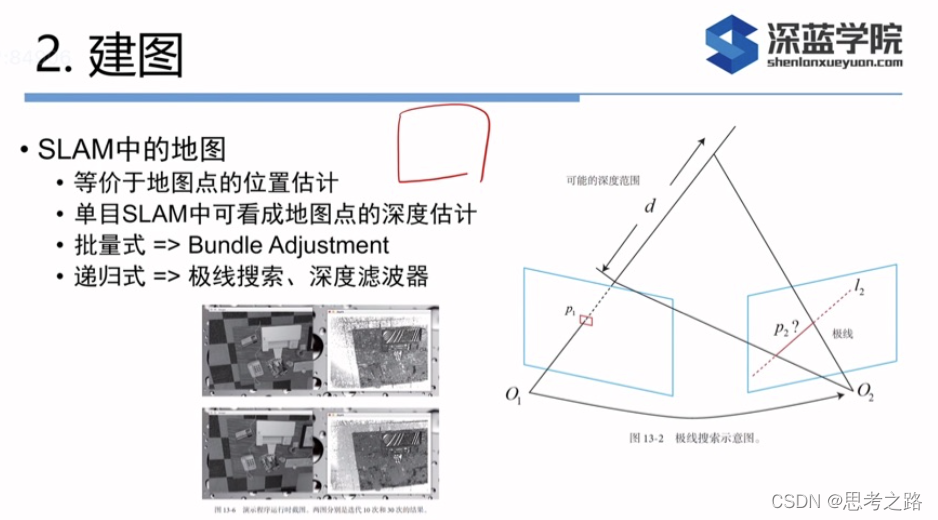
特征点法中,可以通过特征匹配找到相机2中对应的p2位置,但现在没有描述子,所以只能在极线上搜索和p1长的很像的点。感觉像回环检测,回环检测是通过词袋来解决的,但这里没有特征,所以只能采用其他方法。

对SSD和NCC去均值后,结果更可靠。

高斯分布的深度滤波器
对像素点深度的估计,本身可以建模成一个状态估计问题,于是就有滤波器, 非线性优化两种求解思路。虽然非线性优化效果好,但是SlAM的实时性要求高,前端已经占据了不少的计算量,建图还是采用计算量较少的滤波器方法。
对深度的分布假设存在若干种不同的做法。一种是假设深度服从高斯分布,得到卡尔曼式的方法; 另一种是均匀-高斯混合分布的假设。
我们来推导高斯分布的深度滤波器:设某个像素点的深度d服从高斯分布:
P
(
d
)
P(d)
P(d)=
N
(
μ
N( \mu
N(μ,
σ
2
\sigma^2
σ2)
每当新的数据到来时,我们都会观测到它的深度。同样,假设这次观测的分布也是一个高斯分布: P ( d o b s ) = N ( μ o b s P(d_{obs} ) = N (\mu_{obs} P(dobs)=N(μobs, σ o b s 2 ) \sigma_{obs}^2) σobs2)
我们的问题是:如何根据观测的信息更新原先的d的分布。这是一个信息融合问题。我们知道两个高斯分布的乘以依然是一个高斯分布。融合后的高斯分布为: μ f u s e = σ o b s 2 μ + σ 2 μ o b s σ 2 + σ o b s 2 \mu_{fuse} = \frac{\sigma_{obs}^2 \mu + \sigma^2 \mu_{obs}}{\sigma^2 + \sigma_{obs}^2} μfuse=σ2+σobs2σobs2μ+σ2μobs, σ f u s e 2 = σ 2 σ o b s 2 σ 2 + σ o b s 2 \sigma_{fuse}^2 = \frac{\sigma^2 \sigma_{obs}^2}{\sigma^2 + \sigma_{obs}^2} σfuse2=σ2+σobs2σ2σobs2
由于只有观测没有运动方程,所以深度仅用信息融合部分,而无需像完整的卡尔曼那样进行预测和更新。不过虽然融合的方法简单,但是仍有问题:如何确定我们观测到的深度的分布,即如何计算
μ
o
b
s
\mu_{obs}
μobs,
σ
o
b
s
\sigma_{obs}
σobs
关于
μ
o
b
s
\mu_{obs}
μobs,
σ
o
b
s
\sigma_{obs}
σobs的计算可以考虑几何不确定性和光度不确定性。这个暂考虑几何关系带来的不确定性质。现在,假设通过极线搜索和块匹配确定了参考帧某个像素在当前帧的投影位置。这个位置对深度的不确定性有多大?
估计稠密深度的完整过程:
- 假设所有的像素的深度满足某个初始的高斯分布。
- 当新数据产生时,通过极线搜索和块匹配确定投像素点的投影位置。
- 根据几何关系来计算三角化后的深度不确定性。
- 将当前观测融合进上一次的估计中。若收敛则停止计算,否则返回第二步。
















 3011
3011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









