






0. 论文信息
标题:MambaPlace:Text-to-Point-Cloud Cross-Modal Place Recognition with Attention Mamba Mechanisms
作者:Tianyi Shang, Zhenyu Li, Wenhao Pei, Pengjie Xu, ZhaoJun Deng, Fanchen Kong
机构:Qilu University of Technology
原文链接:https://arxiv.org/abs/2408.15740
代码链接:https://github.com/nuozimiaowu/MambaPlace/tree/main
1. 摘要
视觉语言位置识别(VLVPR)通过结合来自图像的自然语言描述来增强机器人定位性能。VLVPR利用语言信息指导机器人位置匹配,克服了单纯依靠视觉的限制。多模态融合的本质在于挖掘不同模态之间的互补信息。然而,一般的融合方法依赖于传统的神经架构,并且不能很好地捕捉跨模态交互的动态,尤其是在存在复杂的模态内和模态间相关性的情况下。为此,本文提出了一种新的由粗到细、端到端连通的跨模态地点识别框架,称为MambaPlace。在粗略定位阶段,文本描述和3D点云分别由预训练的T5和实例编码器编码。然后使用文本注意力Mamba (TAM)和点云Mamba (PCM)进行处理,以进行数据增强和对齐。在随后的精细定位阶段,文本描述和3D点云的特征通过级联交叉注意Mamba (CCAM)进行交叉模态融合和进一步增强。最后,我们从融合的文本点云特征预测位置偏移,实现最精确的定位。大量实验表明,与现有方法相比,MambaPlace在KITTI360Pose数据集上实现了更高的定位精度。
2. 引言
在未来的智慧城市中,自动驾驶汽车、无人机和智能物流系统需要在有效进行路径规划之前,根据人类语言的描述进行准确定位。传统的单模态视觉位置识别(VPR)方法依赖相机或雷达从二维图像或点云中提取特征,然后从数据库中检索对应的位置。然而,这些方法在人机交互方面效率低下,且在季节变化和视角变化等条件下缺乏准确性。相比之下,文本到点云的定位方法无需用户接近目标位置即可实现准确定位,且不受自然环境变化的影响。这种方法为GPS和传统视觉方法不可靠的场景(如极端天气条件和大规模遮挡)提供了更优的解决方案。文本到点云的定位面临几个挑战:1)模糊的描述可能对应于点云地图中的多个潜在区域;2)同一区域内不同位置的语言描述可能非常相似,使得精确位置回归成为一大挑战。为了解决这些问题,开创性工作Text2Pos基于KITTI360数据集为不同空间位置生成了多个描述,从而创建了基础的KITTI360Pose数据集。随后,他们提出了首个两阶段语言到点云的定位框架:在粗定位阶段,将大规模点云分割成块并与文本对齐;在精确定位阶段,采用文本和点云融合来实现每个候选区域内的精确定位。然而,Text2Pos主要关注块内的描述,忽略了语言与点云之间的全局空间关系。为了克服这一局限,Wang等人引入了关系增强Transformer(RET)来建立点云与文本之间的关系[1],在精确定位阶段利用交叉注意力来增强多模态融合。最近,Text2loc[2]采用了预训练的T5模型,并在粗定位阶段引入了对比学习机制。在重新定位阶段,他们采用了无需匹配的回归方法,显著提高了性能。
然而,以往的研究并未彻底解决几个关键问题。在Text2loc中,虽然语言信息采用了先进的T5模型进行表示,但点云特征提取仅依赖于基本的注意力机制。这种方法无法充分捕捉更复杂且信息丰富的点云的精细特征,导致对比学习期间语义空间的不平衡。
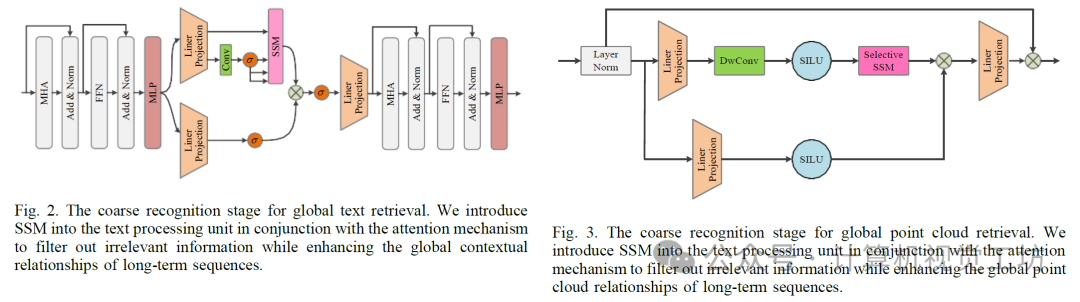
我们的目标是使用理论上统一的机制来解决这些挑战。Mamba模型引起了我们的兴趣。这种基于选择性状态空间模型(SSM)的时变架构被视为Transformer的轻量级替代方案。但我们尤其对其出色的长序列建模能力感到好奇。在粗处理阶段,处理点云数据时,我们采用纯选择性SSM基础的点云Mamba模块替换原始的自注意力模块,该模块有效捕捉点云中远距点之间的关系并增强相对位置关系。
3. 效果展示
左图介绍:我们提出了MambaPlace,这是一种利用文本描述进行城市规模地点定位的解决方案。当给定代表环境的点云以及描述某个地点的文本查询时,MambaPlace能够在地图上识别出指定地点的最可能位置。右图介绍:在KITTI360Pose测试集上的定位性能表明,所提出的MambaPlace实现方案在所有顶部搜索数量上均一致优于现有方法。值得注意的是,在5米范围内的查询中,其文本定位性能超越了当前所有最优水平(SOTA)结果。

4. 主要贡献
我们的主要贡献如下:
• 开发了点云Mamba(PCM),利用纯SSM增强点云中大规模空间信息的特征表示。
• 设计了文本注意力Mamba(TAM),用于捕捉句内和句间关系的上下文细节,从而增强位置关键词与目标关键词之间的关系。
• 提出了级联交叉注意力Mamba(CCAM),以促进多模态特征的多尺度融合并有效管理语义信息,从而准确预测最终定位偏移量,提高定位准确性。
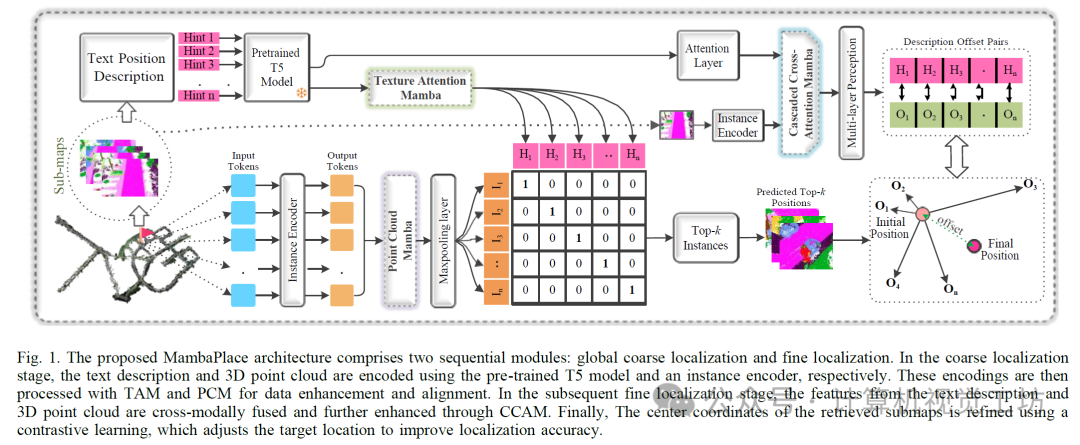
5. 方法
我们将整个过程分为两个连续的端到端阶段:全局粗定位和精细定位,如图2所示。给定一个地点的描述,MambaPlace的任务是识别出可能包含指定地点的前k个候选单元格。MambaPlace的目标是,在精细定位阶段识别出可能包含指定地点的前k个候选单元格,并在粗定位阶段确定选定候选单元格内的确切位置。
6. 实验结果

7. 总结 & 未来工作
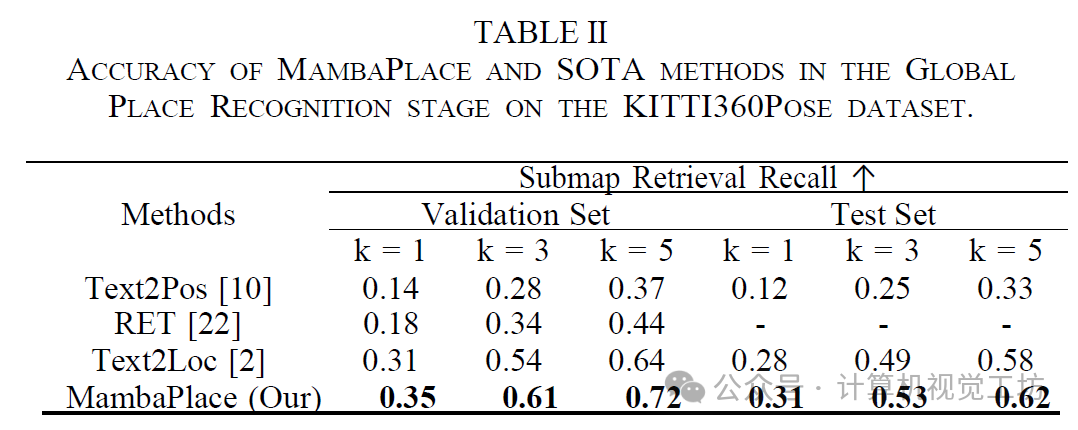
我们提出了MambaPlace,这是首个基于注意力Mamba机制的文本到点云位置识别框架的方法。我们分别为文本、点云和跨模态特征开发了三种不同的专业注意力Mamba模块。这些模块旨在加强数据类内部及数据类之间的长期依赖性。在粗略定位阶段,我们引入了文本注意力Mamba(TAM)和点云Mamba(PCM),以增强文本编码和点云编码分支的特征表示。在精细定位阶段,我们提出了级联交叉注意力Mamba(CCAM),以整合这两种模态,从而提高文本引导的点云子图检索性能。我们证明,在考虑前10个检索位置的情况下,我们的由粗到精的方法能够准确地将89%的文本查询定位到距离查询位置15米以内的范围内,这超过了当前最先进的TextLoc方法,其定位准确率为86%。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~



















 2087
2087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









