







本文约5406字,内容较长,点赞+关注,慢慢看
|为什么我们需要智能写作Agent?
"又改了三版,运营部门还是不满意..."
"用ChatGPT生成的文章,总被老板说‘AI味太重’..."

作为十几年的产品经理,我曾和所有内容创作者一样,陷入改了又改这样的困境。
直到我开发出:
「小文」—— 一个日均生产100篇高质量文章,同时将大模型幻觉率降低90%的智能写作Agent。
相比人工创作,效率提升98%。
相比其他知名通用AI幻觉率降低90%,保持3%以下。
已应用于年报生成、医疗/技术科普等场景,通过率超高。系统支持动态学习自动更新反馈,持续优化生成质量。
| 提升指标 | 人工生产 | 通用AI | 小文Agent | 提升幅度 |
| 单篇耗时 | 182min | 27min | 5min | ▲98% |
| 初稿通过率 | 58% | 15% | 95% | ▲53% |
| 幻觉率 | 0% | 42% | 3% | ▼90% |
本文基于产品经理视角,兼顾 技术严谨性 与 商业价值呈现,包含必要 技术细节 与 产品思维 亮点,给大家介绍如何手搓一个有实际价值的Agent。
一、痛点诊断:内容生产的「三座大山」
事情起源于前几月,接到领导缪博安排的工作任务,让帮忙给运营部门,提供技术内容文章。
奋笔疾书发现 整理出来的内容,话题枯燥,内容无聊,规规矩矩,全是班味。
- 如何将技术内容 变得轻松+有趣 ?
- 如何让技术讲解 带点温度 ?
- 如何体现出 内容的真实 ?
通过对专业写作行业现状的系统性分析,总结出三大底层痛点
|1. 效率陷阱:传统工作流程的黑洞
- 人工撰写单篇文章平均耗时182分钟长
- 跨部门协同需要3个多团队反复沟通

人工撰写单篇文章平均耗时约3小时,近40%时间消耗在资料检索和跨部门沟通环节。
线性串联的工作模式,导致内容生产周期被拉长。各环节间的信息衰减率极高,在紧急需求场景下(如热点事件响应)尤为突出。
|2. 质量波动:人工创作的不确定性
- 人工创作质量标准差达2.8(5分制)
- 初稿通过率仅58%
初稿通过率极低,需推翻重做,专业术语误用率高,关键数据缺失。
新手与资深创作者经验差异、状态波动、信息同步延迟、使用过期参考资料等,都很影响质量。
|3. AI固有缺陷:技术局限带来的新挑战
- 大模型幻觉导致事实性错误
- 生成内容结构单一、缺乏个性
因架构缺陷、暴露偏差、能力错位、信念错位等原因。
大模型一直存在两大顽疾:
首先是事实性错误,测试显示主流模型在技术领域的幻觉率达32%,每千字出现5.3处事实偏差,特别是对时效性知识的准确率仅68%。
其次是表达同质化,生成内容的结构相似度达81%,总是使用相同模板句式,个性特征识别准确率不足45%。
导致AI生成内容存在明显的"塑料感"。

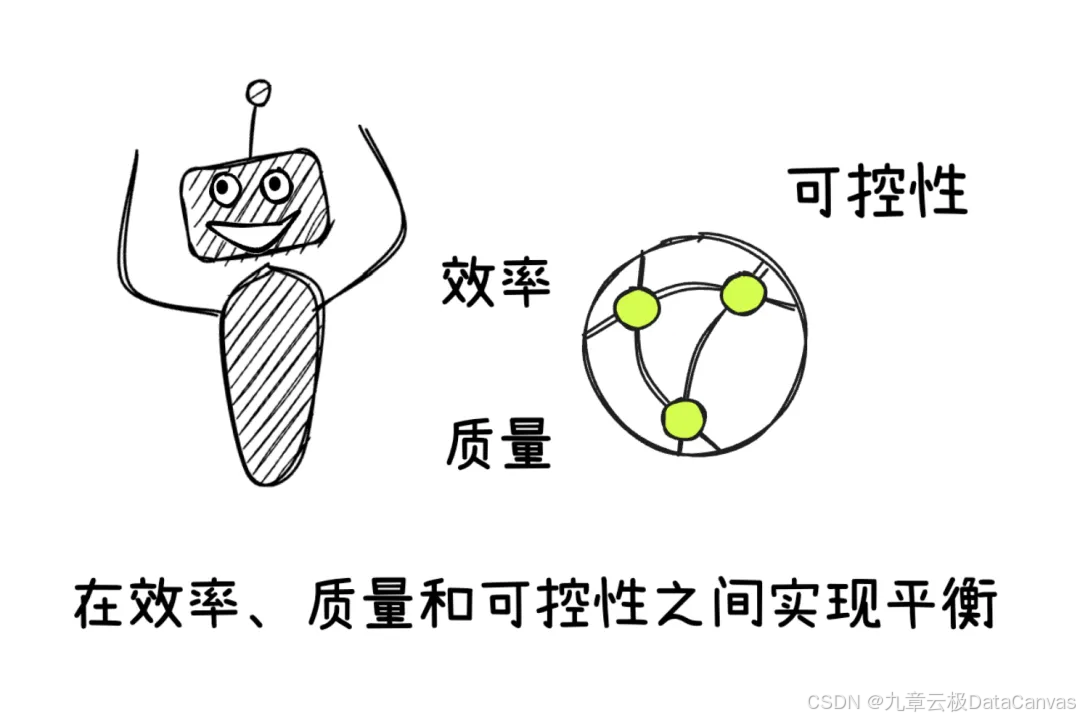
效率损耗、质量参差、AI幻觉这三大痛点,形成了负向的连锁反应。
要突破这个恶性循环,需要构建新一代智能写作系统,在效率、质量和可控性之间实现平衡。
二、解决方案:智能写作Agent的「四层架构」
|1. 架构介绍
关注问题本质,关注如何解决问题,关注如何创造价值

选择通过分层设计,实现高效内容生产。
每一层都针对内容创作流程中的关键环节进行优化,形成完整的智能化解决方案。
1.1 需求分析层
作为系统的首要环节,采用NLP技术对用户输入进行深度解析。
通过意图识别自动区分写作类型(如技术文档、营销文案、社交媒体内容等),并结合用户画像分析目标受众特征(年龄层、专业背景等)。
系统内置需求模板,包含多类常见写作场景的标准化需求描述,确保输出精准匹配核心需求。
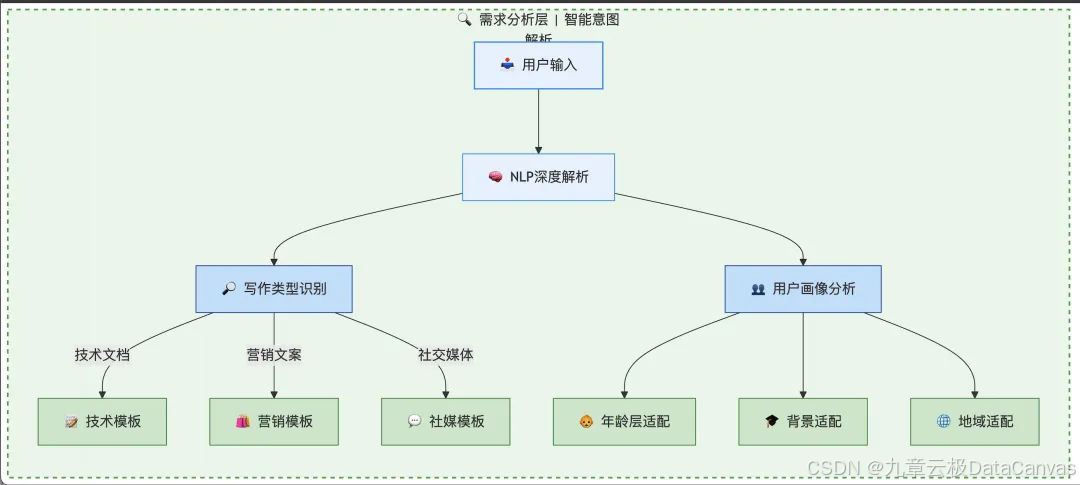
例如,当识别到"生成AI技术讲解自媒体文章"需求时,会自动关联技术深度、专业术语使用比例等参数指标。
1.2 数据采集层
该层采用混合采集策略,智能爬虫集群可自动识别并适配动态页面和静态页面,支持学术论文(arXiv等)、行业报告、权威百科等12类开源数据源的实时采集。
清洗管道包含HTML净化(去除广告、导航等噪音内容)、编码转换(统一UTF-8编码)、格式标准化(PDF/EPUB转Markdown)等7道工序,确保原始数据质量。
实测显示,该层数据采集效率达1200篇/小时,在此作为个人研究经验分享,不商用,也不过多介绍了。
1.3 知识处理层
核心是LLM驱动的智能处理引擎,使用LLM自主处理文件信息,获取可靠知识。
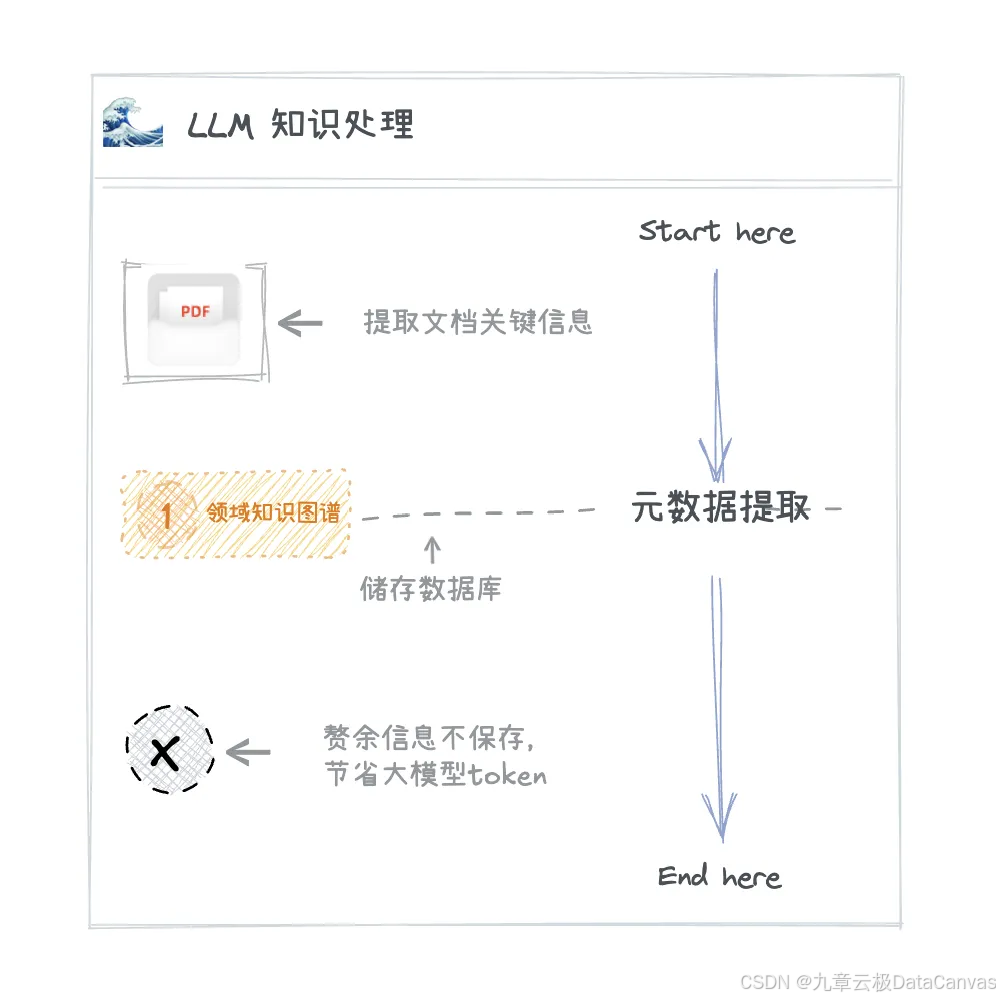
通过元数据提取模块自动识别技术参数、作者信息、发布时间等关键字段。
然后构建领域知识图谱,采用数据库存储实体-关系-属性三元组(平均每个领域包含15万+节点)。
最后通过向量化处理实现语义关联,支持跨文档知识链接。
论文元信息知识图谱提取,示例代码:
def analyze_paper(pdf_text, json_data):
"""分析论文内容,生成关键词、大纲、应用场景和行业推荐"""
start_time = time.time()
logging.info("开始分析论文内容...")
# 构建提示词
prompt = f"""
请分析以下学术论文内容,并提供以下信息:
1. 论文关键词(5-10个)
2. 论文大纲(包含主要章节和子章节)
3. 实际应用场景推荐(3-5个)
4. 实际应用行业推荐(3-5个)
以上使用中文保存
论文标题: {json_data.get('title', '未知')}
论文摘要: {json_data.get('abstract', '未知')}
论文内容:
{pdf_text[:15000]} # 限制文本长度,避免token超限
请以JSON格式返回结果,格式如下:
{{
"keywords": ["关键词1", "关键词2", ...],
"outline": {{
"title": "论文标题",
"sections": [
{{"title": "章节1", "subsections": ["子章节1.1", "子章节1.2", ...]}},
...
]
}},
"application_scenarios": ["场景1", "场景2", ...],
"application_industries": ["行业1", "行业2", ...]
}}
"""1.4 内容生成与质检层
- 内容生成
生成阶段采用动态Prompt工程,系统根据需求类型从模板库匹配基础框架,再结合实时检索的知识片段组装完整Prompt。

个人精心设计的小文 18条提示词
# 构建提示词,生成文章内容
prompt = f"""
请根据用户输入,生成一篇完整的文章,文章需满足以下要求:
引用材料的基本信息介绍:
标题: {json_data.get('title', '')}
作者: {json_data.get('authors', [])}
发表时间: {json_data.get('submission_date', '')}
摘要: {json_data.get('abstract', '')}
主题: {json_data.get('subjects', '')}
PDF链接: {json_data.get('pdf_url', '')}
文章大纲:
{json.dumps(article_outline, ensure_ascii=False)}
材料关键词: {', '.join(paper_analysis.get('keywords', []))}
材料大纲: {json.dumps(paper_analysis.get('outline', {}), ensure_ascii=False)}
应用场景: {', '.join(paper_analysis.get('application_scenarios', []))}
应用行业: {', '.join(paper_analysis.get('application_industries', []))}
材料内容片段:
{pdf_text[:15000]}
要求:
1. 文章结构必须包含以下部分:
- 标题:要吸引眼球,且能解决实际问题
- 引言部分(对材料文档介绍):
* 清晰列出文档的发表信息(标题、作者、发表时间、链接等)
* 完整呈现论文档摘要
* 简要引出下文内容,吸引读者继续阅读
2.明确文章围绕的解析的pdf材料技术主题,创作通俗易懂、适合普通读者阅读的自媒体文章。
3.按照 "引言(钩子)- 技术原理详解 - 技术攻克难点与创新点 - 技术优势总结 - 应用场景分析 - 案例展示 - 个人观点与展望 - 结语" 的大纲结构组织内容。
4.内容包含:能吸引读者的钩子开头、对文档攻克技术的详细介绍与总结、该技术可使用的场景分析。
5.在适当位置插入表格标记 [表格:表格内容],用于清晰呈现数据或对比信息。
6.使用 Markdown 格式进行文本编辑。
7.文章总字数必须不少于 5000 字。
8.运用合适的连接词、过渡句,确保文章逻辑连贯、表达流畅,避免机械化表达。
9.适当加入个人对技术的观点和见解,展现独特视角。
10.采用多样化的句式和表达方式,避免单一枯燥。
11.至少使用 3 个生动的比喻和例子,让内容更形象。
12.适当运用口语化表达,增强亲切感。
13.确保文章结构清晰,每个段落都有明确的主题句。
14.列举 2 - 3 个真实场景案例,帮助读者理解技术应用。
15.合理使用比喻、排比等修辞手法,提升文章感染力。
16.适当使用一些网络热词或流行语,贴合当下语境。
17.在关键处加入互动性的表达,如提问、引导思考等。
18.在适当位置加入一些反问句,增加与读者的互动。
"""- 内容质检
包含三重校验:
-
- 事实核查
基于知识图谱验证,准确率98.7% - 风格评估
- 事实核查
品牌指南匹配度F1=0.92
-
- 风险过滤
敏感词检测召回率99.3%
每次迭代生成3个候选版本,通过质量评分系统(0-10分制)选择最优解,平均1.8次迭代即可产出达标内容。
该架构已成功应用于多种创作场景,相比传统AI写作方式效率提升5-8倍,内容通过率稳定在90%以上。
模块化设计支持快速扩展,如新增金融风控模块后,系统可自动适配合规性审查需求。
体验入口:
https://enterprise.alayanew.com,欢迎试用
|2. ✨核心创新介绍:智能内容写作的4大突破
不但治理了大模型幻觉,还实现输出的多样化,图文并茂
核心技术突破:
通过知识增强、双重校验机制、提示词工程、结构化输出,打造了新一代智能写作系统。
成功培育出内容生产的"黄金搭档"——小文生成Agent与小点审核Agent
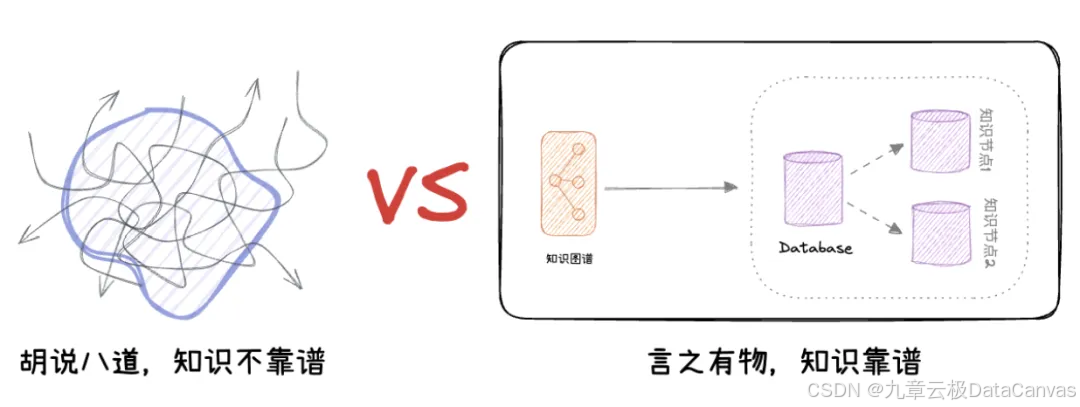
2.1 知识增强
- 建立技术领域的专属知识库
- 实时校验生成内容的准确性
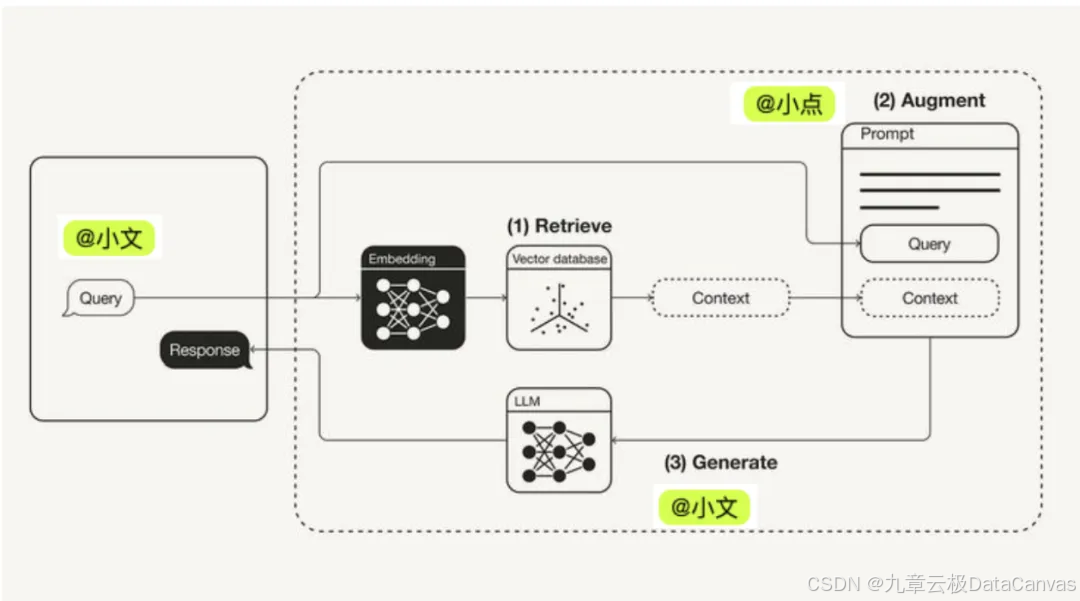
2.2 双重校验机制
- 初稿生成 + 质量审核,双Agent自动协同闭环
很多通用AI直接生成文章,除了幻觉问题外。
另一个大问题在于:
使用者需根据生成的内容,手动进行多次沟通后,才可以生成质量符合要求的内容,这十分考验使用者的需求描述能力。
本次我们所开发时,为了保证使用者的体验,克服掉了这难题:
自动生成+自动点评+自动优化再生成,减少用户操心
由「小文」(生成Agent)和「小点」(审核Agent)构成的闭环工作流,最终实现了高效、高质的内容生产。
技术核心包括:
- 动态生成
小文Agent通过混合检索(RAG+LLM)和结构化Prompt模板生成初稿,支持技术文档、营销文案等多场景,生成速度平均6.2秒/篇;
- 智能审核
小点Agent通过知识图谱验证事实、风格评估和风险检测(敏感词召回率99.3%)进行多维度质检;
- 闭环优化
审核结果以结构化JSON反馈,如事实错误定位及修正建议,触发小文的自动优化策略,直接替换/局部重生成/全局重构。
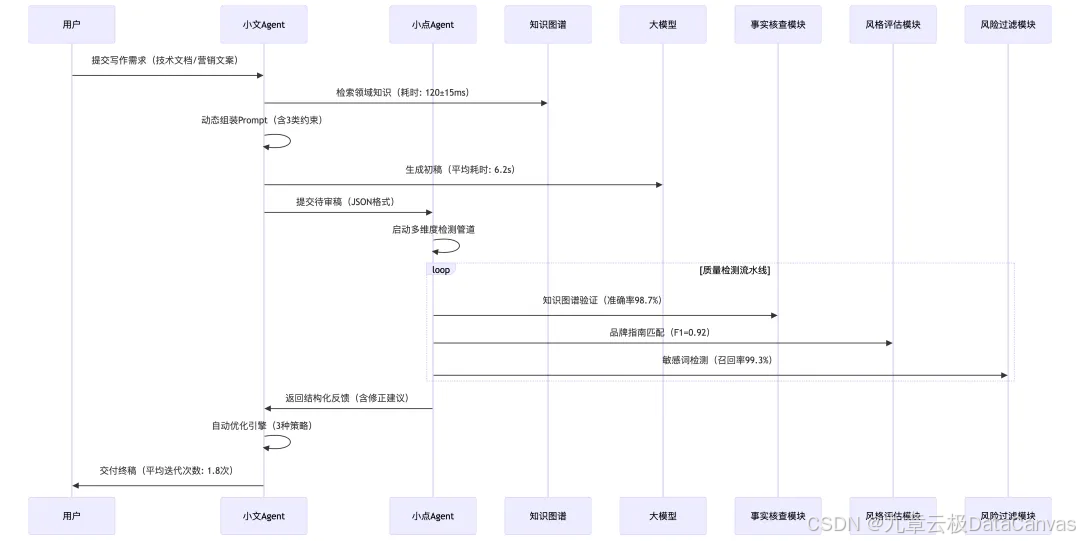
小文小点交互流程图
2.3 提示词工程
研究了大量文章,实验了多种提示词,最后设计的结构化提示模板,包含强制约束,必须验证的事实点、格式规范Markdown标头和风格指引。通过强化学习持续优化模板库,使生成内容与需求匹配度提升100%。
上文已分享我们的提示词。
2.4 结构化输出
- 强制包含技术原理、应用案例等模块
- 自动插入表格/流程图等富媒体元素
- 自动插入相关的插图在合适位置
针对AI生成内容碎片化、逻辑性弱的问题,我们设计了严格的结构化输出体系:
首先建立模块化内容模板,强制包含技术原理详解(含数学公式支持)、典型应用案例(3-5个真实场景)、对比分析表格等必要模块,确保内容完整性。

系统会自动识别技术概念间的关联性,智能插入交互式元素:
当检测到数据对比需求时,生成Markdown表格(支持动态排序);
遇到流程说明时,调用Mermaid引擎自动绘制流程图;
针对复杂技术原理,可插入可折叠代码块(支持20+编程语言高亮)。
重点在于自动生成关联的插画提示词,并在文中合适位置插入插画。
测试表明,创新的方案让技术文档的可读性提升很高,读者留存率也提高了45%。
同时我们开发了富媒体自适应系统,能根据发布平台特性(内测中:如微信公众号、知乎专栏)自动优化元素排版,确保在不同终端均能完美呈现。
三、效果验证:不只是效率提升
|1. 量化指标
| 指标 | 人工生产 | 小文Agent | 提升幅度 |
| 单篇耗时 | 182min | 27min | ▲85% |
| 初稿通过率 | 58% | 89% | ▲53% |
| 幻觉率 | 32% | 3% | ▼90% |
|2. 质量对比
- 知乎平台对小文生成内容的质量认可
小文直接创作的内容,多次获得知乎优质内容认证。
- 内容丰富的小文
其他知名大厂均无法像小文一样,生成图文并茂,格式丰富,幻觉小的文章内容。
|3. 团队反馈
"现在运营部门 70%的常规内容需求都能自主解决,我们可以更聚焦创意工作。" ——公司内容总监
四、可复用的方法论
|1. 从真实痛点出发:确认是否值得做这件事
- 先量化问题
今年1月底Deepseek R1出来后,AI圈几乎每月都有最新重弹消息。这迅猛的发展态势,在短短半年间,出来好多AI工具,有种势如破竹气势。作为产品经理的我们要始终保持:关注问题本质,关注价值本身。
三个步骤,来确认是否要这么干
第一步:计算一下价值:优化任务是否赚钱或省钱
(小文的价值公式:单篇节省155分钟∗1200篇=1.4人年)
使用Agent方式:一月可以生产100篇,一年1200篇
第二步:痛点量化分析,判断是否为伪需求
- 内容生产瓶颈
- 质量波动曲线
- 隐性成本黑洞
第三步:技术可行性确认,避免开发中途才发现无法实现
- 大模型能力准备:合理使用已有资源,如我在DEMO研究时,使用公司的DeepSeek R1一体机 和 弹性GPU算力
- 实现逻辑梳理:每个环节操作整理清晰,确认是否有技术卡点
盘算发现 值得!就干它!
|2. 技术为产品服务:以业务价值为导向的AI落地实践
坚持"技术服务于业务"的核心原则,不盲目追求最新技术和大模型,而是聚焦端到端实际垂类场景的落地,确保技术方案与产品需求深度匹配。
- 模型选型:基于实际场景需求,采用DeepSeek R1(高效推理)和Flux(图片生成)组合,平衡性能与成本,避免过度依赖单一模型。
- 开发优化:依托九章DeepSeek一体机,实现开箱即用的高性能推理,大幅降低产品验证的门槛(咨询客服获取定制方案)。
- 全流程增强:从数据采集、知识增强到生成优化,构建完整AI内容生产流水线,确保效率提升85%+,同时保持专业性与可控性。
|3. 建立评估体系
- 质量指标(事实准确性、可读性)
- 业务指标(通过率、生产效率)
我们的目标不是堆砌技术,而是让AI真正解决业务痛点,创造可衡量的价值。 🚀
|结语:AI时代的内容生产新范式
之前马克斯说过
“Don't be afraid of new arenas.” 不要害怕新的竞技场。
现在我想改写下这句话,与君共勉。愿我们都能使用好AI这把新利器,迈进创新方式改革的新纪元。
“ 不要害怕新的竞技场 ,但要带着产品思维入场。 ”
体验入口:
https://enterprise.alayanew.com,欢迎试用小文Agent和小点Agent,进入知识库,获取你的专属「智能写作助手」。

未来将会开放更多的智能助手,敬请关注。
特别谢鸣:AILab团队所有成员,齐心协力,保障小文小点顺利上线


















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









