










基于惯性权重和学习因子动态调整的粒子群算法matlab程序
参考文献:《基于惯性权重和学习因子动态调整的粒子群算法》
摘 要:针对传统的粒子群算法易发生早熟收敛、在寻优过程中易陷入局部最优等问题,提出了一种基于惯性权重和学习因子动态调整的粒子群算法,该算法通过改进惯性权重和学习因子参数以优化算法。随着算法的不断迭代,其惯性权重以及学习因子随着迭代次数的增加而动态优化,从而平衡其局部寻优能力与全局搜索能力。实验结果表明,改进后的算法在收敛速度以及收敛精度上比传统粒子群算法更优,能改善早熟收敛问题。
关键词:粒子群算法;动态调整;迭代;优化;惯性权重;学习因子
粒子群算法是一种经典的元启发式算法 [1],该算法由 C. Reynolds 于 1987 年对鸟类觅食行为进行模拟研究时得出,他提出如下模拟鸟群个体简单行为的 3个规则:
1)防止鸟群发生碰撞,即减少与其他粒子产生碰撞;
2)鸟群个体保持速度相近,即速度与邻近粒子尽可能相近;
3)鸟群个体朝中心靠拢,即朝粒子群中心尽可能聚拢。
其后,J. Kennedy 等基于 C. Reynolds 的研究结论,在 1995 年经过进一步研究提出了一种粒子群优化(particle swarm optimization,PSO) 算 法。该 算法对之前的算法进行了参数简化,算法原理更为简单,易于实现 [2],因此得到许多研究人员的关注,并且被应用于处理各种优化问题。例如:张鑫等 [3] 提出了一种自适应简化粒子群优化算法,按照一定规律引入分布的锁定因子,从而粒子位置的惯性权重可以通过锁定因子自适应配置,导致算法收敛速度得到了有效提高,但是仍然存在鲁棒性较弱、收敛精度较低等缺陷;王永贵等 [4] 为了增加种群的多样性,在算法中引入了动态分裂算子,以此避免陷入局部最优解,然后通过采用指数衰减的惯性权重,平衡粒子的局部以及全局的搜索;杜美君等 [5] 提出了一种基于相似度动态调整惯性权重的方法,它将更小的惯性权重值赋予靠近目前最优粒子的个体,但是算法收敛速度较慢,当处理复杂函数问题时,耗时较长。PSO 算法也存在很多的局限,在迭代时粒子群体多样性不断降低,导致算法容易陷入局部最优解、收敛速度后期变慢或者出现早熟收敛等问题。上述研究者的改进算法对增强种群多样性有很大帮助,同时有助于平衡算法局部搜索能力与全局搜索能力,在一定程度上提高了 PSO 算法的寻优精度,也加快了算法的收敛速度。
以上各算法主要针对粒子群算法在迭代过程中种群多样性降低、收敛速度较慢和寻优精度较低等问题 [6-10] 而提出改进方案,但是没有对算法的惯性权重和学习因子进行动态调整,有可能导致算法出现早熟收敛现象。针对这一问题,本文提出一种自适应的调整惯性权重和学习因子的粒子群算法,利用惯性权重和学习因子的动态改进调整,以期提高算法的性能。对比实验结果显示,改进算法具有较强的寻优能力和收敛性。
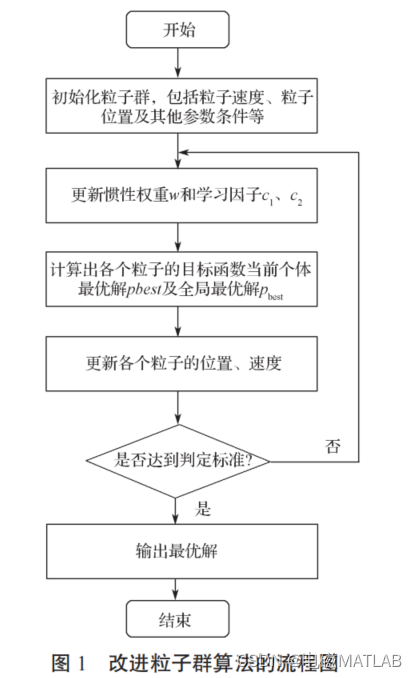
1 改进的粒子群算法
粒子群算法的速度迭代公式中有如下 3 个重要参数:惯性权重 w 和学习因子 c1、c2。惯性权重 w 影响着粒子先前的飞行速度对于当前的飞行速度的影响程度,惯性权重的选取对于平衡算法的全局搜索能力和局部搜索能力有着重要意义。在迭代过程中,要考虑算法的全局性和局部性,要采取合适的惯性权重来进行搜索。本文利用改进后的幂指函数算子,将其加入到惯性权重中,以总的迭代次数为基础,在搜索时让每个粒子扩大搜索空间,以此增大种群多样性。因此,本文采用改进惯性权重值的策略。对比实验结果表明,动态调整后的惯性权重能提高算法搜索性能,有效改善收敛状况,随着算法不断迭代,惯性权重值动态改变,表达式为

作为算法运行中的重要式子,c1 是粒子具有自我学习总结能力的体现,代表的是个体自我认知;学习因子 c2 是粒子具有向表现更好的粒子学习的本领体现,代表的是粒子的社会认知。需要设置恰当的 c1、c2 以便于粒子进行搜寻。初期要关注个体自我认识的能力,后期则应注重个体获取社会信息的能力。本文设置如下学习因子:
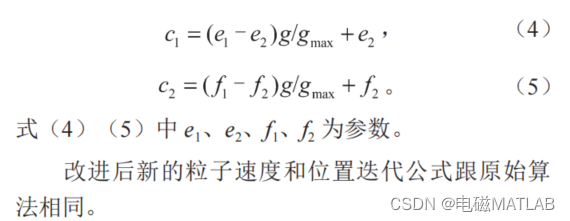
与基本粒子群算法相比较,对基于惯性权重和学习因子动态调整的粒子群算法的速度公式作出调整时,实现了算法随着迭代次数变化而动态变化,其全局搜索能力有效提高,粒子的收敛性也得到了加强。然而,当遇到一些复杂的多峰值函数曲线的寻优问题时,基于惯性权重和学习因子动态调整的粒子群算法,依然存在许多问题,收敛速度以及精度仍达不到要求等。如当受到局部阴影的作用时,输出曲线将会变得错综变幻,由于多峰值的产生,大大增加了整体寻优的难度,也可能使基本粒子群算法和改进粒子群算法显示早熟迹象,而导致产生局部极值。
2 算例

3 程序运行结果

4 matlab程序
1)主函数
clear
clc
close all
index =7;%测试函数索引
nVar = 10;%未知变量数量,维度
nPop = 200;%population size种群规模
MaxIt = 200;%最大迭代次数
VarMin = -100;%粒子取值下限
VarMax = 100;%粒子取值上限
Vmin = -10;%粒子速度最小值
Vmax = 10;%粒子速度最大值
k = 1%实验次数
for i = 1:k
[IPSO_polbelbest,IPSO_golbelbest,IPSO_Best] = IPSO(nVar,nPop,MaxIt,VarMin,VarMax,Vmin,Vmax,index);
[PSO_polbelbest,PSO_golbelbest,PSO_Best] = PSO(nVar,nPop,MaxIt,VarMin,VarMax,Vmin,Vmax,index);
IPSO_average(i,:) = IPSO_golbelbest;
PSO_average(i,:) = PSO_golbelbest;
end
semilogy(IPSO_Best,'--k', 'LineWidth', 2);
hold on;
semilogy(PSO_Best,'-.r', 'LineWidth', 2);
hold on;
legend('改进PSO','传统PSO');
xlabel('迭代次数');
ylabel('适应度');
2)子函数
function y=fun(x,index)
% x代表参数,index代表测试的函数的选择
% 该测试函数为通用测试函数,可以移植
% 目录
% 函数名 位置 最优值
% 1.Sphere 0 0
% 2.Camel 多个
% 3.Rosenbrock
switch index
case 1 %Sphere函数
xx=x(1);
yy=x(2);
y=(xx+2*yy-7)^2+(2*xx+yy-5)^2;
case 2 %
xx=x(1);
yy=x(2);
y=20*exp(-0.2*sqrt((xx^2+yy^2)/2))+exp((cos(2*pi*xx)+cos(2*pi*yy))/2)-exp(1)-20;
case 3 %Rosenbrock函数
y=0;
for i=2:length(x)
y=y+100*(x(i)-x(i-1)^2)^2+(x(i-1)-1)^2;
end
case 4 %Ackley函数
a = 20; b = 0.2; c = 2*pi;
s1 = 0; s2 = 0;
for i=1:length(x)
s1 = s1+x(i)^2;
s2 = s2+cos(c*x(i));
end
y = -a*exp(-b*sqrt(1/length(x)*s1))-exp(1/length(x)*s2)+a+exp(1);
case 5 %Rastrigin函数
s = 0;
for j = 1:length(x)
s = s+(x(j)^2-10*cos(2*pi*x(j)));
end
y = 10*length(x)+s;
case 6 %Griewank函数
fr = 4000;
s = 0;
p = 1;
for j = 1:length(x); s = s+x(j)^2; end
for j = 1:length(x); p = p*cos(x(j)/sqrt(j)); end
y = s/fr-p+1;
case 7 %Shubert函数
s1 = 0;
s2 = 0;
for i = 1:5
s1 = s1+i*cos((i+1)*x(1)+i);
s2 = s2+i*cos((i+1)*x(2)+i);
end
y = s1*s2;
case 8 %beale函数
y = (1.5-x(1)*(1-x(2)))^2+(2.25-x(1)*(1-x(2)^2))^2+(2.625-x(1)*(1-x(2)^3))^2;
case 9 %Schwefel函数
s = sum(-x.*sin(sqrt(abs(x))));
y = 418.9829*length(x)+s;
case 10 %Schaffer函数
temp=x(1)^2+x(2)^2;
y=0.5-(sin(sqrt(temp))^2-0.5)/(1+0.001*temp)^2;
otherwise
disp('no such function, please choose another');
endfunction [outputArg1,outputArg2] = untitled2(inputArg1,inputArg2)
%UNTITLED2 此处显示有关此函数的摘要
% 此处显示详细说明
outputArg1 = inputArg1;
outputArg2 = inputArg2;
end
function [IPSO_polbelbest,IPSO_golbelbest,IPSO_Best] = IPSO(nVar,nPop,MaxIt,VarMin,VarMax,Vmin,Vmax,index)
empty_individual.Position = [];
empty_individual.Cost = [];
pop = repmat(empty_individual, nPop, 1);
VarSize = [1 nVar];
pBestSol.Cost = inf;
BestCosts = zeros(MaxIt,1);
for i=1:nPop%种群位置、速度、适应度初始化
pop(i).Position = unifrnd(VarMin, VarMax, VarSize);
pop(i).Velocity = unifrnd(Vmin, Vmax, VarSize);
pop(i).Cost = fun(pop(i).Position,index);
if pop(i).Cost < pBestSol.Cost
pBestSol = pop(i);%个体适应度最佳
end
end
gBestSol = pBestSol;
for it=1:MaxIt
for i=1:nPop
w = 1+(1-0.7).*(it.^2)/(MaxIt^2);
c1 = (1-0.7).*it/MaxIt+0.7;
c2 = (1-0.7).*it/MaxIt+0.7;
%速度更新
pop(i).Velocity = w.*pop(i).Velocity+c1.*rand(VarSize).*(pBestSol.Position-pop(i).Position)+c2.*rand(VarSize).*(gBestSol.Position-pop(i).Position);
%速度边界处理
pop(i).Velocity = max(pop(i).Velocity, Vmin);
pop(i).Velocity = min(pop(i).Velocity, Vmax);
%位置更新
pop(i).Position = pop(i).Position+pop(i).Velocity;
%位置边界处理
pop(i).Position = max(pop(i).Position, VarMin);
pop(i).Position = min(pop(i).Position, VarMax);
%适应度值更新
pop(i).Cost = fun(pop(i).Position,index);
%更新局部最优
if pop(i).Cost < pBestSol.Cost
pBestSol = pop(i);
%更新全局最优
if pBestSol.Cost < gBestSol.Cost
gBestSol = pBestSol;
end
end
BestCosts(it) = gBestSol.Cost;
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCosts(it))]);
end
end
IPSO_polbelbest = pBestSol;
IPSO_golbelbest = gBestSol;
IPSO_Best = BestCosts;
end
function [PSO_polbelbest,PSO_golbelbest,PSO_Best] = PSO(nVar,nPop,MaxIt,VarMin,VarMax,Vmin,Vmax,index)
w = 1;
c1 = 1.5;
c2 = 1.7;
empty_individual.Position = [];
empty_individual.Cost = [];
pop = repmat(empty_individual, nPop, 1);
VarSize = [1 nVar];
pBestSol.Cost = inf;
BestCosts = zeros(MaxIt,1);
for i=1:nPop%种群位置、速度、适应度初始化
pop(i).Position = unifrnd(VarMin, VarMax, VarSize);
pop(i).Velocity = unifrnd(Vmin, Vmax, VarSize);
pop(i).Cost = fun(pop(i).Position,index);
if pop(i).Cost < pBestSol.Cost
pBestSol = pop(i);%个体适应度最佳
end
end
gBestSol = pBestSol;
for it=1:MaxIt
for i=1:nPop
%速度更新
pop(i).Velocity = w.*pop(i).Velocity+c1.*rand(VarSize).*(pBestSol.Position-pop(i).Position)+c2.*rand(VarSize).*(gBestSol.Position-pop(i).Position);
%速度边界处理
pop(i).Velocity = max(pop(i).Velocity, Vmin);
pop(i).Velocity = min(pop(i).Velocity, Vmax);
%位置更新
pop(i).Position = pop(i).Position+pop(i).Velocity;
%位置边界处理
pop(i).Position = max(pop(i).Position, VarMin);
pop(i).Position = min(pop(i).Position, VarMax);
%适应度值更新
pop(i).Cost = fun(pop(i).Position,index);
%更新局部最优
if pop(i).Cost < pBestSol.Cost
pBestSol = pop(i);
%更新全局最优
if pBestSol.Cost < gBestSol.Cost
gBestSol = pBestSol;
end
end
BestCosts(it) = gBestSol.Cost;
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCosts(it))]);
end
end
PSO_polbelbest = pBestSol;
PSO_golbelbest = gBestSol;
PSO_Best = BestCosts;
end
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











