






PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation 论文精读与代码实现
收录期刊会议与级别:CVPR(CCF-A)
日期:2017年
作者:Charles R. Qi等
单位:Stanford University
论文链接: PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
一、写作背景
当前研究都无法直接对点云数据进行直接处理,都需要先对3D点云数据进行间接的处理后在进行分类或者分割任务,这不仅会导致数据量变得庞大还会引入负面的issue。针对这个问题,作者提出了一种全新的可直接输入3D点云数据进行训练的网络模型–pointNet。作者通过理论分析和实验证明该网络具有良好的性能和鲁棒性。
二、实验难点
1.要实现直接输入3D点云数据首先要考虑的是如何消除网络对点云顺序的敏感性,换句话说网络应该具备输入点云数据排序不变性,即点云数据的输入顺序并不影响模型的结果。
2.点云数据还具备置换不变性,即简单的平移旋转并不应该影响模型的输出结果。
三、解决方法
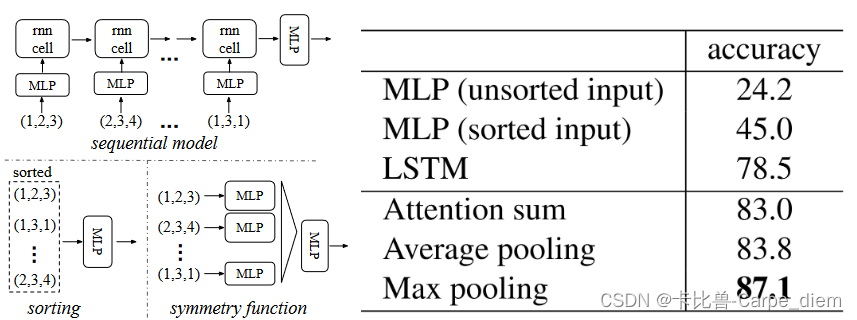
1.作者使用对称函数(symmetry function)来解决输入数据的无序性。作者在文中分别分析了三种(对点集进行排序,使用rnn网络模型,使用对称函数)解决输入数据的无序性问题。并分析各方法的优劣。
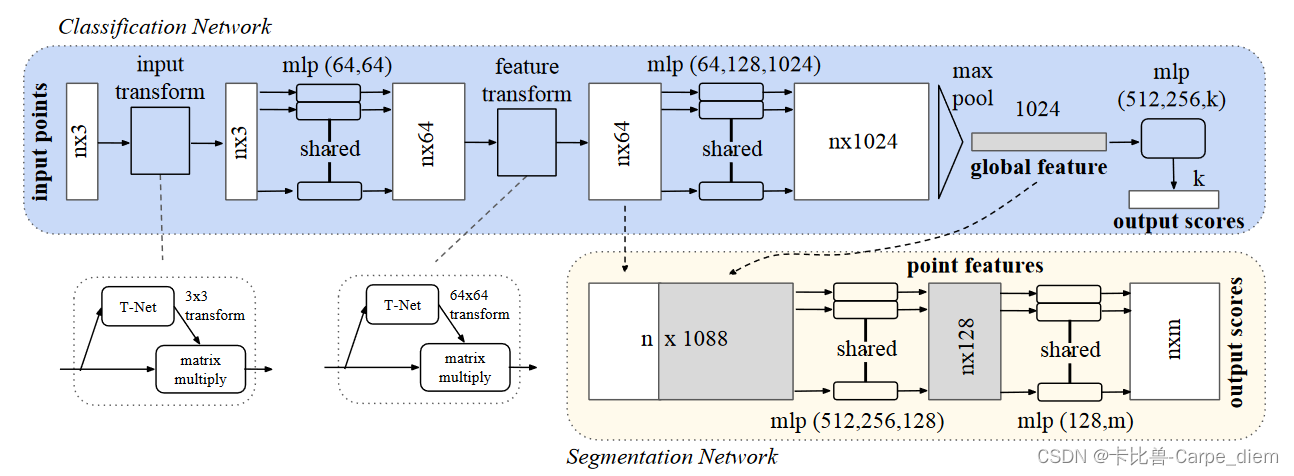
2.为解决网络对输入数据的置换不变性,作者设计了一种联合校准网络(Joint alignment network),由独立于点的特征提取、最大池化和全连接层等基本模块组成。作者分别实现了对输入数据和深层特征的校准(对齐到规范空间)。以下是代码和网络结构图:

class STN3d(nn.Module):
def __init__(self):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0] # max返回两个值,一个是values,一个是indices x-->(batch_size, num_points, num_features)
#这里应该是对dim=1在num_points上进行max吧?
# x = torch.max(x, 1, keepdim=True)[0] # max返回两个值,一个是values,一个是indices x-->(batch_size, num_points, num_features)
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.array([1,0,0,0,1,0,0,0,1]).astype(np.float32))).view(1,9).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
class STNkd(nn.Module):
def __init__(self, k=64):
super(STNkd, self).__init__()
self.conv1 = torch.nn.Conv1d(k, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k*k)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.k = k
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.eye(self.k).flatten().astype(np.float32))).view(1,self.k*self.k).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.k, self.k)
return x
对于特征对齐转换网络,高维度会导致难以优化,因此作者在softmax 训练损失中添加了一个正则化项,如下:

其中A是转换矩阵,I是单位矩阵。
四、网络代码实现
class STN3d(nn.Module):
def __init__(self):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0] # max返回两个值,一个是values,一个是indices x-->(batch_size, num_points, num_features)
#这里应该是对dim=1在num_points上进行max吧?
# x = torch.max(x, 1, keepdim=True)[0] # max返回两个值,一个是values,一个是indices x-->(batch_size, num_points, num_features)
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.array([1,0,0,0,1,0,0,0,1]).astype(np.float32))).view(1,9).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
class STNkd(nn.Module):
def __init__(self, k=64):
super(STNkd, self).__init__()
self.conv1 = torch.nn.Conv1d(k, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k*k)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
self.k = k
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.eye(self.k).flatten().astype(np.float32))).view(1,self.k*self.k).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, self.k, self.k)
return x
class PointNetfeat(nn.Module):
def __init__(self, global_feat = True, feature_transform = False):
super(PointNetfeat, self).__init__()
self.stn = STN3d()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feat = global_feat
self.feature_transform = feature_transform
if self.feature_transform:
self.fstn = STNkd(k=64)
def forward(self, x):
n_pts = x.size()[2]
trans = self.stn(x)
x = x.transpose(2, 1)
x = torch.bmm(x, trans)
x = x.transpose(2, 1)
x = F.relu(self.bn1(self.conv1(x)))
if self.feature_transform:
trans_feat = self.fstn(x)
x = x.transpose(2,1)
x = torch.bmm(x, trans_feat)
x = x.transpose(2,1)
else:
trans_feat = None
pointfeat = x
x = F.relu(self.bn2(self.conv2(x)))
x = self.bn3(self.conv3(x))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
if self.global_feat:
return x, trans, trans_feat
else:
x = x.view(-1, 1024, 1).repeat(1, 1, n_pts)
return torch.cat([x, pointfeat], 1), trans, trans_feat
class PointNetCls(nn.Module):
def __init__(self, k=2, feature_transform=False):
super(PointNetCls, self).__init__()
self.feature_transform = feature_transform
self.feat = PointNetfeat(global_feat=True, feature_transform=feature_transform)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k)
self.dropout = nn.Dropout(p=0.3)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
def forward(self, x):
x, trans, trans_feat = self.feat(x)
x = F.relu(self.bn1(self.fc1(x)))
x = F.relu(self.bn2(self.dropout(self.fc2(x))))
x = self.fc3(x)
return F.log_softmax(x, dim=1), trans, trans_feat
class PointNetDenseCls(nn.Module):
def __init__(self, k = 2, feature_transform=False):
super(PointNetDenseCls, self).__init__()
self.k = k
self.feature_transform=feature_transform
self.feat = PointNetfeat(global_feat=False, feature_transform=feature_transform)
self.conv1 = torch.nn.Conv1d(1088, 512, 1)
self.conv2 = torch.nn.Conv1d(512, 256, 1)
self.conv3 = torch.nn.Conv1d(256, 128, 1)
self.conv4 = torch.nn.Conv1d(128, self.k, 1)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
def forward(self, x):
batchsize = x.size()[0]
n_pts = x.size()[2]
x, trans, trans_feat = self.feat(x)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.conv4(x)
x = x.transpose(2,1).contiguous()
x = F.log_softmax(x.view(-1,self.k), dim=-1)
x = x.view(batchsize, n_pts, self.k)
return x, trans, trans_feat
def feature_transform_regularizer(trans):
d = trans.size()[1]
batchsize = trans.size()[0]
I = torch.eye(d)[None, :, :]
if trans.is_cuda:
I = I.cuda()
loss = torch.mean(torch.norm(torch.bmm(trans, trans.transpose(2,1)) - I, dim=(1,2)))
return loss
五、理论分析
1.神经网络对连续函数的逼近能力:连续函数的好处是输入数据的微小的扰动不会对输出结果有明显的影响。作者通过证明表明只要最大池化部分的神经元足够多那么pointNet的前向传播函数可以近似的看成是连续函数。


2.证明点云物体的分类和分割只受关键点云(critical points)的影响,即存在临界点集(critical point)和瓶颈点集(bottleneck point)只要输入的点云数据在这个范围内输出结果就不会有太大的波动。
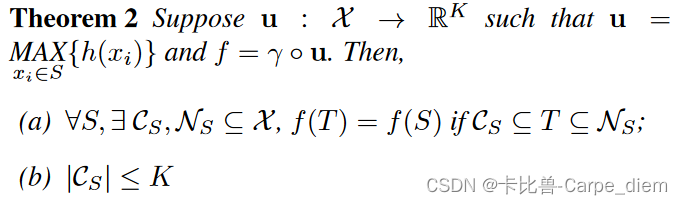
六、实验与结果分析
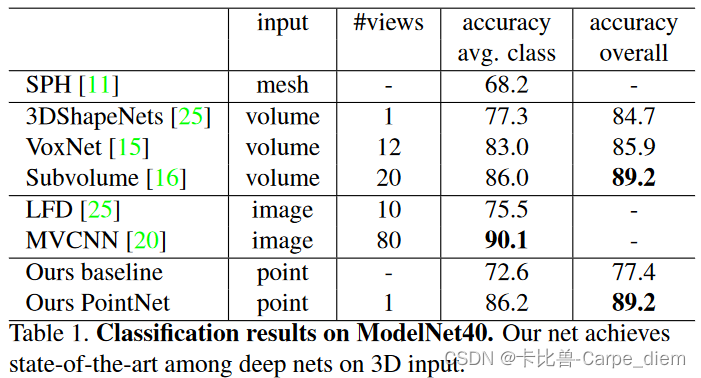
1.分别进行了分类,局部分割和全景分割三个任务的实验,使用的数据集分别为:ModelNet40,ShapeNet part data set和Stanford 3D semantic parsing data set。
(1)ModelNet40:
(2)ShapeNet part data set
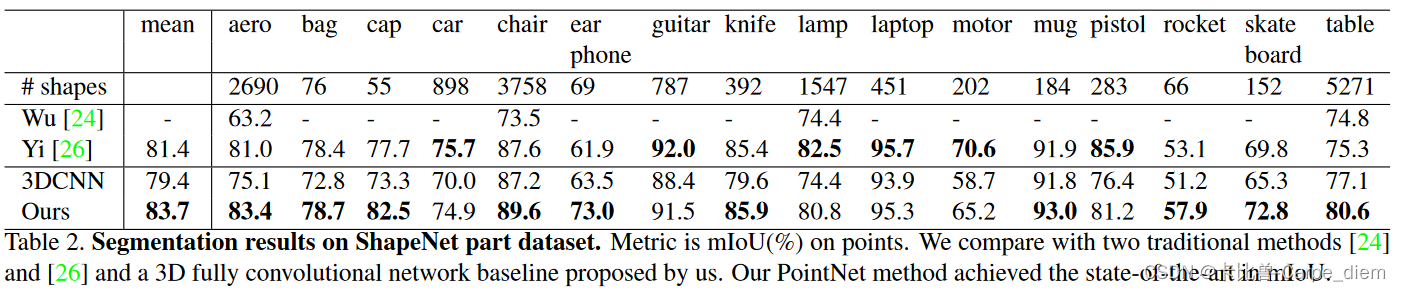
(3)Stanford 3D semantic parsing data set
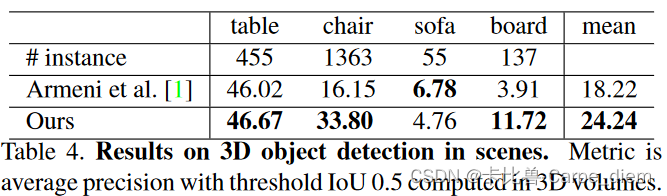
2.同时作者还对网络结构模块的有效性进行了实验:与其他有序不变方法的比较,输入和特征转换的有效性以及鲁棒性测试
3.作者对pointNet的输出进行了可视化,我们可以直观地看到临界点集 CS 和上界形状 NS 的一些结果,进一步验证了模型存在临界点集和瓶颈点集。

4.最后作者对模型的大小和推理速度进行了对比分析,以下是分析结果:
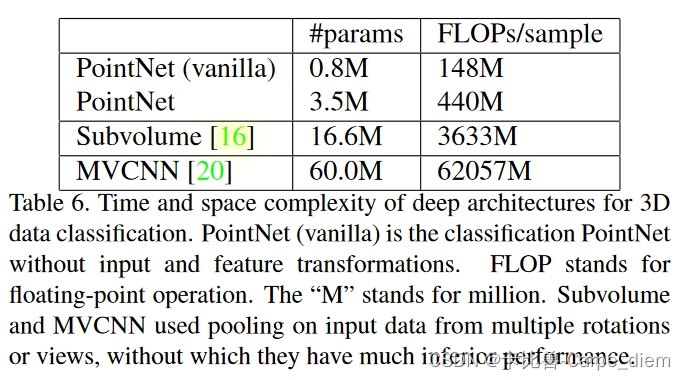















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











