







前言: NeurIPS2018上的通过X -Transform对无序的点进行卷积的方法
论文地址:【here】
补充材料地址:【here】
代码地址:【here】
PointCNN: Convolution On X -Transformed Points
引言
点云和2D图像值不一样,第一,它是无序的,第二,它有空间位置信息
作者用以下四幅图来阐释:
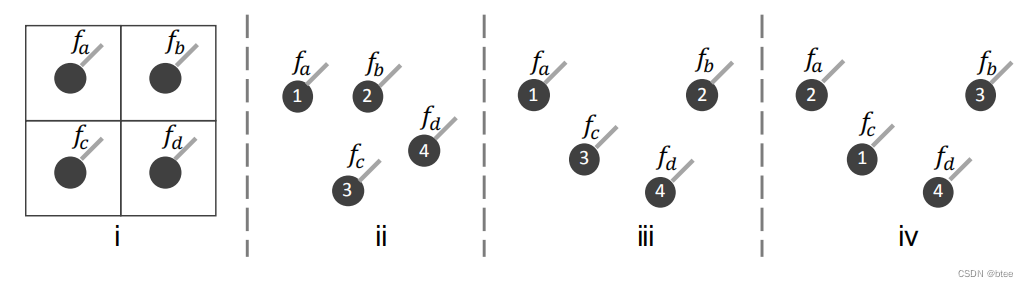
图(i)即展示了2D卷积的邻域点来聚合特征的过程,比如2 * 2的卷积,则可以通过找到嵌入的固定位置并滑动来进行卷积,具体可以用这个公式表示:
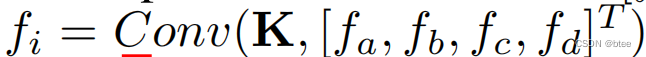
然而,如果要类比到3D点云的卷积的话,图ii,iii,iv应该是按下式表示进行卷积
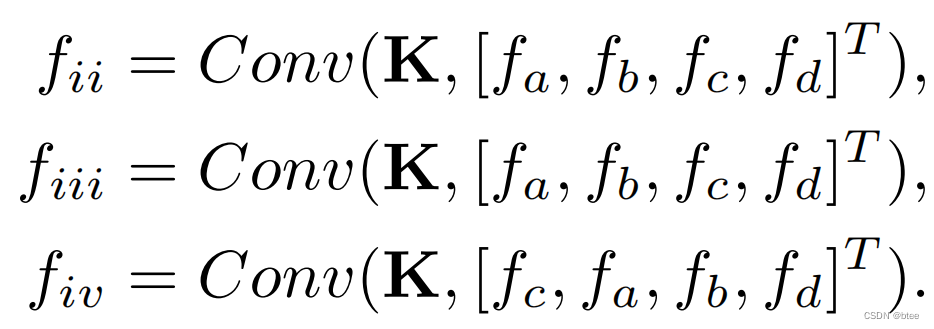
其中,卷积结果的fii=fiii的,而卷积结果fiii是不等于fiv的(由于卷积是有序的,因此打乱abcd的顺序得到的结果肯定不一样)
但是我们再分析这个点云的分布,我们可以直觉上看到ii(下图左一)的卷积得到的特征应该与iii不一样(下图中间),这是由于二者点的空间位置分布不一样;而iii(下图中间)的卷积应该与iv(下图右一)卷积的结果是一样的,因为尽管他们排序的1234不同,即顺序不同,但是他们每个点的空间位置信息和特征都是对应相同的
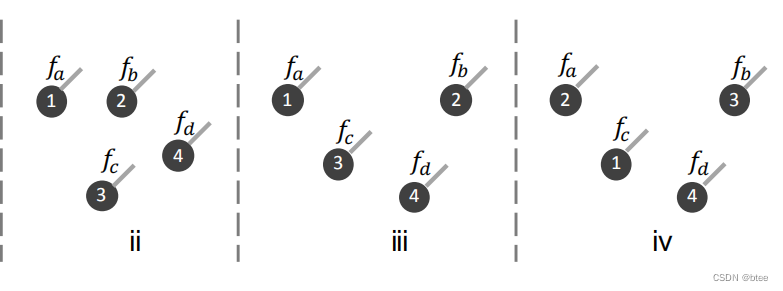
所以作者得出结论,传统的卷积是不适合无序点进行聚合特征的,这样会导致形状信息(空间位置信息)丢失,并由于排序的不同造成误差
This example illustrates that a direct convolution results in deserting shape information (i.e., fii ≡ fiii), while retaining variance to the ordering (i.e., fiii = fiv)
因此,作者为了解决这个问题,提出了一种K * K 的transform来适应无序点卷积,即在卷积之前用这种X-transform先进行“排序”(即赋予权重再进行传播),再进行有序的卷积
Our aim is to use it to simultaneously weight and permute the input features, and subsequently apply a typical convolution on the transformed features.
最后的实现如下,这个X-transform采用矩阵乘法进行实现
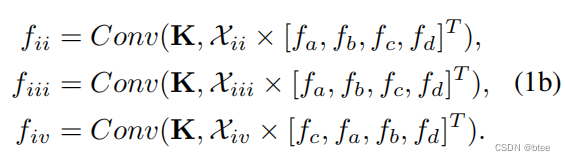
方法
卷积的结构应该是找采样点,聚合邻点,下采样的层级结构,这里的点云架构也是如此
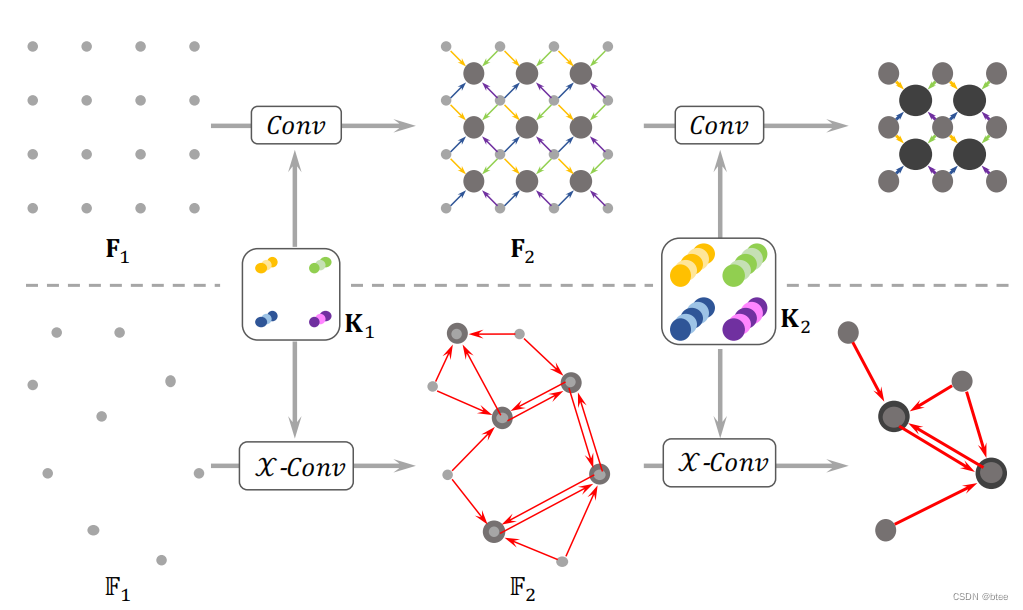
首先找采样点,这里作者采用了两种方式,第一是随机采样,用于分类任务,第二种是最远点采样,用于分割任务
(找邻点这里作者没有特别强调指出,由于邻点数固定,我这里将它视作KNNsearching)
具体实现
作者通过一个6行的代码表进行说明,(我觉得这个表解释得很清楚,因此就对着这个表进行说明)
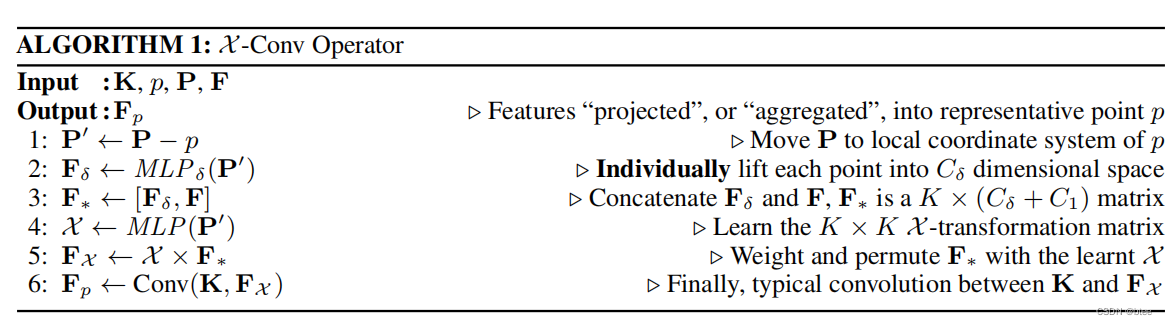
第一行:将邻点的绝对位置(x,y,z)变成相对位置(δx,δy,δz)
第二行:将每个点的相对位置特征进行MLP,将空间位置特征投影到一个更高的维度
这里作者给出的投影意义是:因为接下来要将相对位置特征和点的上一层特征进行concat,所以要将特征投影到(更高更抽象维的)同一表示空间中去
However, the local coordinates are of a different dimensionality and representation than the associated features. To address this issue, we first lift the coordinates into a higher dimensional and more abstract representation
第三行:将投影后的相对位置特征与这个点对应的上一层特征进行特征concat
第四行:用这个相对位置特征得到一个K * K的注意力矩阵,这里的指的是需要进行卷积的点的数量,由于只对邻点进行卷积,所以K也表示包括自己的邻点数
第五行:用这个注意力矩阵(K * K) 乘上原本的特征矩阵(K * C),得到一个新的特征矩阵(K * C)
第六行:将新的特征矩阵进行传统卷积
这里的transforrmer矩阵的矩阵乘法很有新意(第四五行),这里作者没有对这个结果进行可视化(我觉得应该要有个可视化看一下),然而这里我不解的是,MLP的输入明明只是当前邻点和中心点的相对位置关系,没有邻点和邻点之间的相对位置关系,这样的reweight和permute的依据在哪…
所以我就大胆猜测这里MLP通过对空间的相对位置学出了K个权重,应该这K个权重是差不多平均的(因为没有信息区分这个邻点与其他K个邻点之间有什么关系),但是离得近的邻点总体权重大,离的远的邻点总体权重小
当然之前我也觉得这里的MLP完了之后应该有个softmax,但softmax总和为1,不符合上面近点总体权重大,远点总体权重小的猜想,所以这里没有softmax也正常
(因为代码也是tensorflow实现的,没有跑代码仅仅是想法)
最后的网络设计
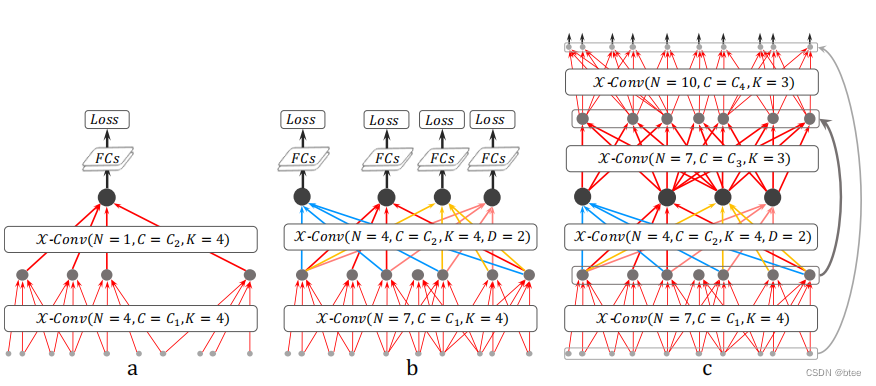
实验
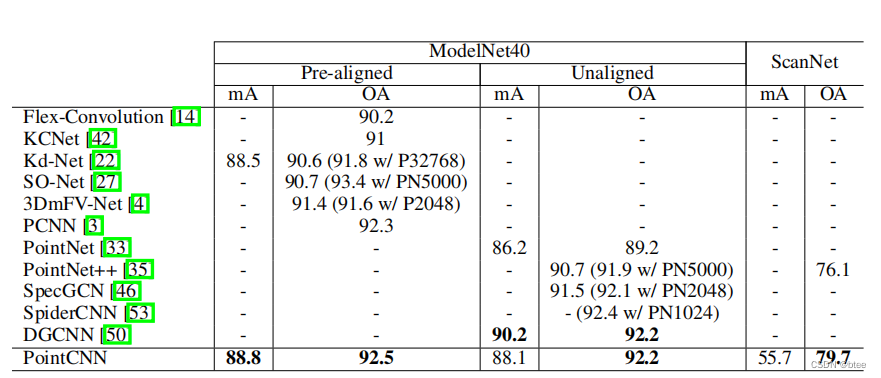
分类任务
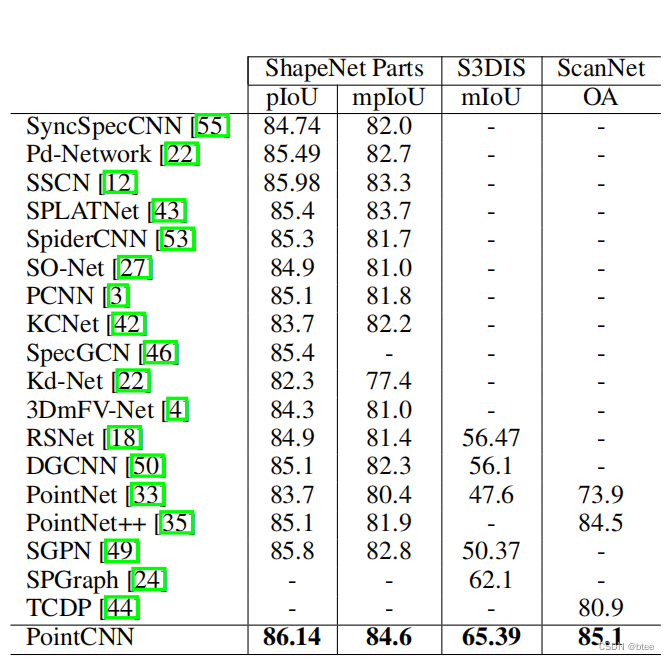
分割任务
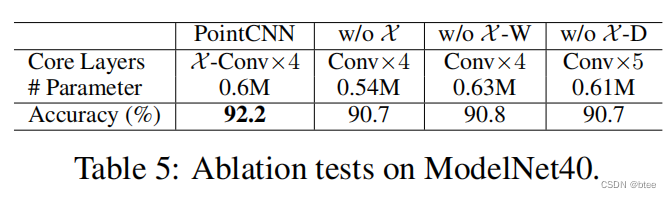
作者还在分类数据集上进行了消融实验,发现没有x-transform的方法,效果差了不少
总结
在transformer没火的那个时代,这篇文章可以说是相当超前了,包括卷积的有序性与点云的无序性和空间位置特征的分析也很透彻,当然现在对transfomer去做下去的话可以有更多不同的玩法














 3638
3638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









