







前言
本篇是量化系列的第一篇文章。《量化十万个为什么》系列旨在讨论一些自己心中的疑问,并且通过尝试解答这些问题来提升自己对于市场的认知水平。
PS:博主水平很辣鸡,请大家轻喷,多多指教!
一、为什么提这个问题?
某天在看MACD的时候,突然注意到,实际上不同股票价格的MACD_BAR的值相差很多。举个例子:
600519.SH(贵州茅台) 和 601988.SH (中国银行)这两只股票的MACD 如下图所示:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import copy
tmp_factor_dic = copy.copy(factor_reader.ReadFactorMySql(start_date = '20180101',end_date = '20201231',factor_list = ['MACD'],
stock_name = '600519.SH', factor_type = 'DayBar'))
tmp_factor_dic2 = copy.copy(factor_reader.ReadFactorMySql(start_date = '20180101',end_date = '20201231',factor_list = ['MACD'],
stock_name = '601988.SH', factor_type = 'DayBar'))
tmp_factor_dic['MACD']['MACD_BAR'].plot()
tmp_factor_dic2['MACD']['MACD_BAR'].plot()
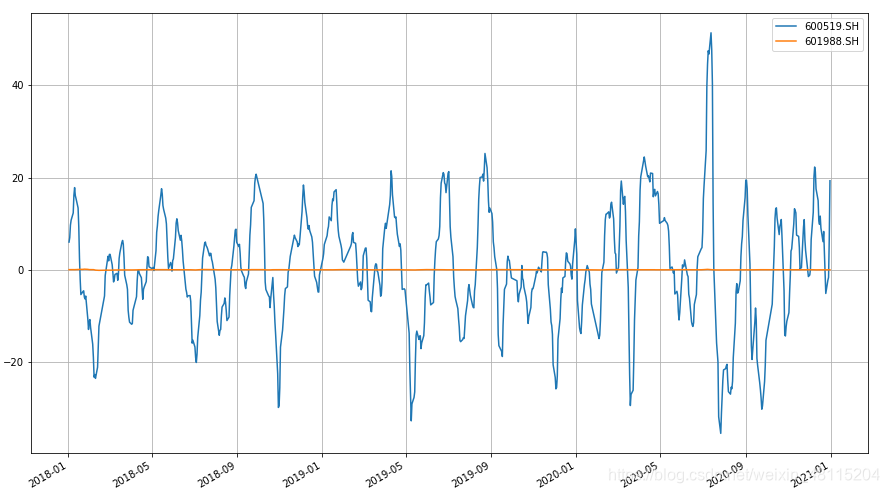
由上图可以看到,由于茅台价格绝对值较高,因子计算出来的波动较大,与之相比中国银行的MACD几乎成为了一条直线。同样联想到换手率的问题,理论上绝对换手率(成交股数/流通股数)应该是不需要进行中性化的,但是在实际观察中,似乎在某一段时间内,换手率高的便一直高?这其中和行业或者市值,是否有相关性呢?因此来探究一下。
二、分析
我们选取2018年至2020年的股票数据,对每天市场的换手率求rank,然后以申万一级作为标准
# 先获取交易日历
trading_date_lst = assistant.ReturnTradingCalendar(start_date = '20180101',end_date = '20201231')
# 然后对每一天的换手率求rank
total_df = pd.DataFrame()
for today_date in trading_date_lst:
today_daybar = assistant.ReadDayBar(start_date=today_date,end_date=today_date)
tmp_df = copy.copy(today_daybar[['StockName','Date','TurnoverRate']])
tmp_df['Tr_Rank'] = today_daybar['TurnoverRate'].rank().astype(int)
total_df = total_df.append(tmp_df)
# 获取申万分类的数据
industry_df = assistant.GetSW_Industry_DataFrame(till_date='20201231')
industry_lst = list(set(industry_df['IndustryName']))
# 计算每一天,每个行业的rank均值
saving_dic = {}
trading_date_lst.name = 'Date'
for industry_name in industry_lst:
# 获取每一个行业的DataFrame
one_industry_df = industry_df[industry_df['IndustryName'] == industry_name]
total_merge_df = pd.DataFrame(columns=trading_date_lst)
for stock_name in one_industry_df['StockName']:
try:
one_stock_df = copy.copy((total_df.loc[[int(stock_name[0:6])]][['Date','Tr_Rank']]).reset_index(drop=True))
except:
continue
one_stock_df['Date'] = one_stock_df['Date'].astype(str)
one_stock_df = one_stock_df.T
one_stock_df.columns = one_stock_df.loc['Date']
tmp_df = one_stock_df.loc[['Tr_Rank']]
tmp_df.index = [stock_name]
total_merge_df = total_merge_df.append(tmp_df)
industry_rank_se = total_merge_df.fillna(0).sum()/(len(total_merge_df) - total_merge_df.isnull().sum())
# 最后把结果存起来
saving_dic.update({industry_name:industry_rank_se})
我们取银行和计算机两个行业
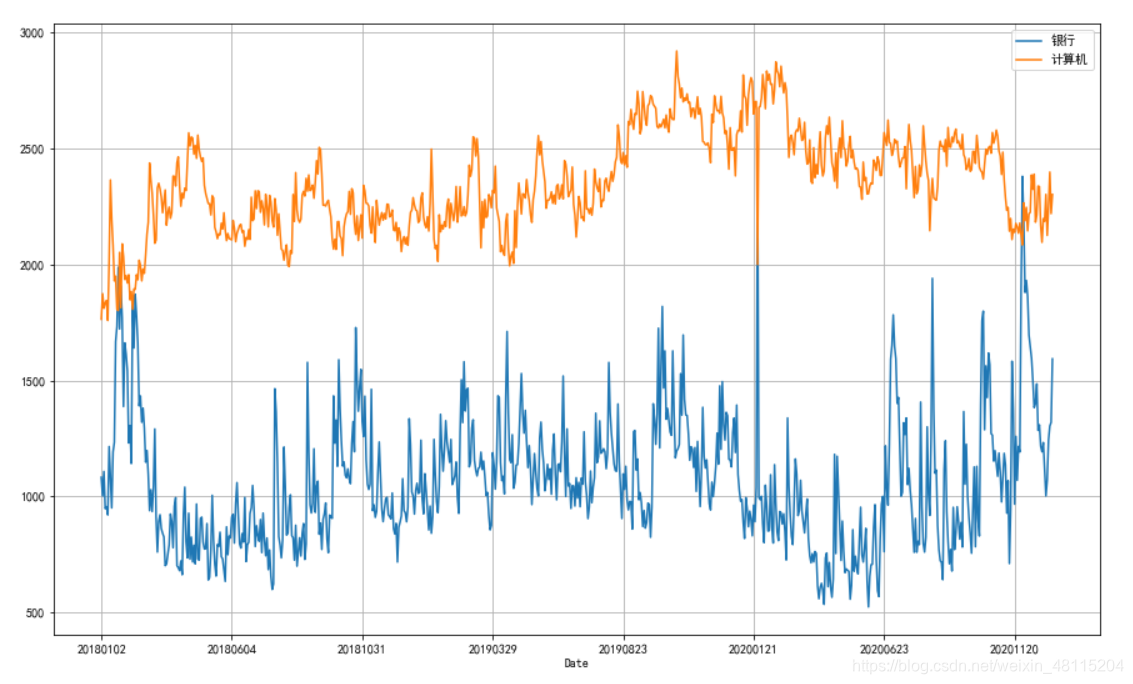
可以明显看到,绝大多数的情况下,银行的换手率要显著低于计算机,因此在使用换手率这个因子的时候,要做一下行业中性化,会比较好一点?
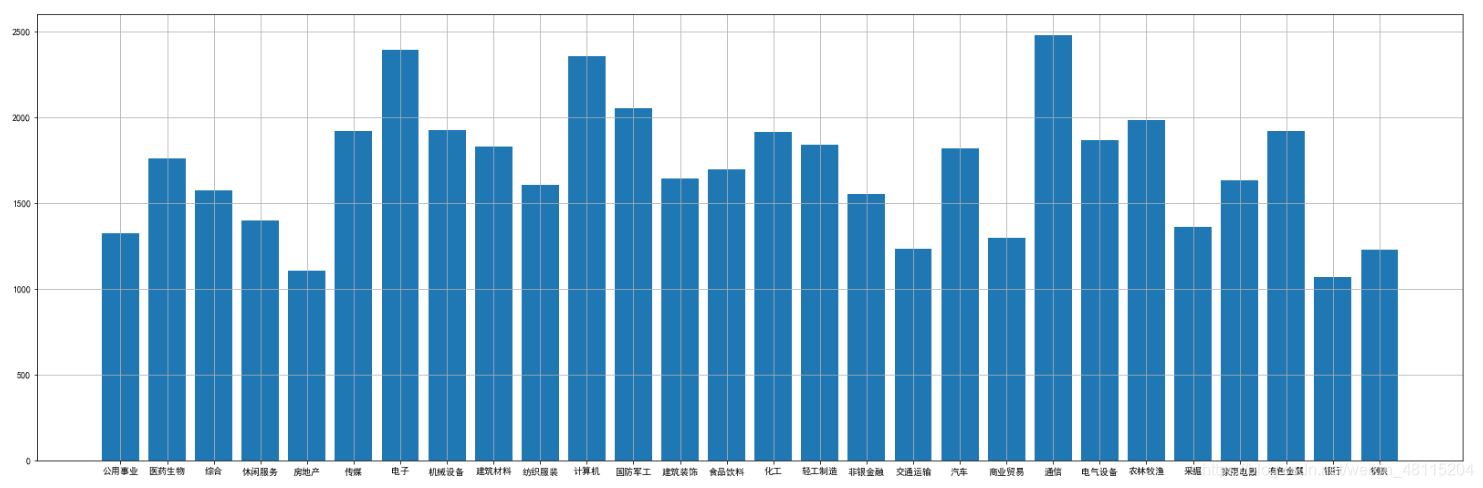
换手率rank的均值如下图
总结
由上面的分析可以看出,单单绝对数值的换手率在实践中还是很容易出现行业偏好的问题,比如说取换手率大于5%的情况,则更容易取到计算机股,而更不容易取到银行股。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









