







D2HC Rmvsnet的主要成果是在保持重构精度的同时降低了内存开销,
该方法的GPU内存消耗是之前循环方法R-MVSNet[34]的19.4%。
1.网络结构
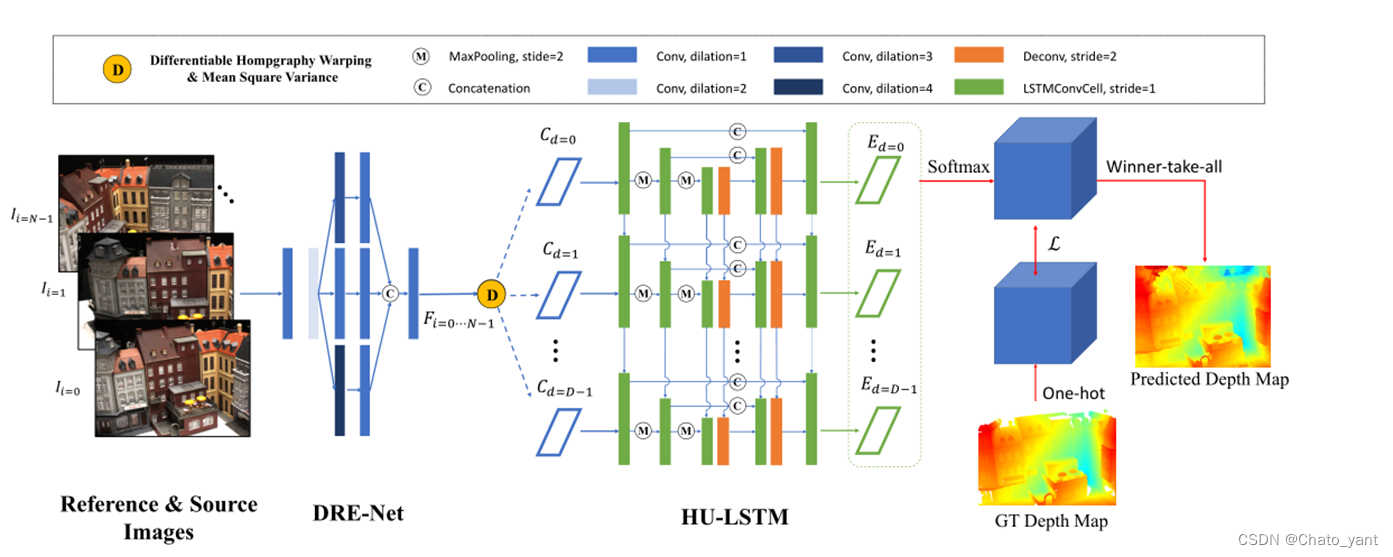
新型混合循环多视点立体网络(D2HC Rmvsnet)由两个核心模块组成:1)轻型DRENet (density Reception Expanded)模块,用于提取具有多尺度上下文信息的原始尺寸密集特征图;2)HU-LSTM (hybrid U-LSTM)模块,用于将三维匹配体正则化为预测深度图,通过LSTM和U-Net架构的耦合,有效地聚合不同尺度的信息。
2.DRE-Net
引入dilation扩大感受野更好的聚合上下文信息
我们首先使用两个常用的卷积层来总结局部像素信息,然后使用三个不同扩张比(2,3,4)的扩张卷积层来提取多尺度的上下文信息,而不影响分辨率。
参数如下:

扩张卷积dilation有间隔的进行卷积操作,使得感受野增大。示意图如下:
3.HU-LSTM
融合了
LSTM
和
Unet,每个单元命名为LSTMConvCell

4.LOSS
G 代表一个 one hot 生成的 groudtruth 在像素 x 的深度值P 是对应的深度估计概率与Rmvsnet类似

5.后处理
做了动态一致性检查:
mvsnet动态一致性检查:

本文动态一致性检查:
• 原来的不够鲁棒,固定为 1 和 0.01• 我们通过 dh - rmvnet 表示参考图像 Ii 上像素 p 的估计深度值 Di(p) 。摄像机参数用 [13] 中的 Pi = [ Mi|ti ] 表示。• 首先我们将像素 p 逆向投影到 3D 空间中,通过以下方法生成对应的 3D 点 X • 然后投影 3D 点 X ,在邻居视图 Ij 上生成投影像素 q
• 然后投影 3D 点 X ,在邻居视图 Ij 上生成投影像素 q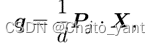 • Pj 为相邻视图 Ij 的摄像机参数, d 为距投影的深度。反过来,我们将邻近视图上估计深度为 Dj (q) 的投影像素 q 反向投影到 3D 空间中,并重投影回标记为 p ‘的参考图像( d ’是 p ‘在参考图像上的深度值)
• Pj 为相邻视图 Ij 的摄像机参数, d 为距投影的深度。反过来,我们将邻近视图上估计深度为 Dj (q) 的投影像素 q 反向投影到 3D 空间中,并重投影回标记为 p ‘的参考图像( d ’是 p ‘在参考图像上的深度值)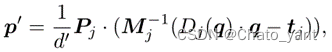 再定义:
再定义: 将所有邻居视图的匹配一致性进行聚合
将所有邻居视图的匹配一致性进行聚合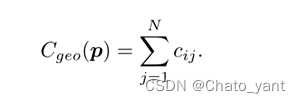
当
时选取的点的深度是合适的,不舍弃。
6.实验效果

总结:相比Rmvsnet采用了LSTM取代了GRU,在LSTM加入了Unet思想,使点云更完整。采用了新的特征提取网络DRE-Net提取特征。
作者认为,要想提高精度首先需要优化特征提取网络,要想提高完整度首先需要优化代价体正则化的部分。















 3075
3075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









