






一 本研究的创新
VLM-driven Behavior Tree for Context-aware Task Planning
- 使用VLM生成带有视觉条件节点的行为树(BT)
- 开发了一个交互式BT编辑器界面
- 采用"自我提示"(self-prompting)方式进行视觉条件检查
- 在真实咖啡厅场景中进行了验证
二 相关概念
1 有视觉条件节点的行为树(BT)
视觉条件节点(Visual Condition Node)是这篇论文提出的一个重要创新。让我来详细解释:
1. 基本概念:
- 这是一种特殊的行为树节点,可以根据机器人实时看到的场景来做出决策
- 节点中包含用自然语言描述的视觉条件,比如"桌子上是否有杯子"、"杯子里是否有液体"等
2. 工作方式:
- 生成阶段:VLM会在生成行为树时,自动加入这些视觉条件节点
- 执行阶段:
- 当机器人执行到这个节点时,会拍摄当前场景的图片
- 将图片和条件描述一起发送给VLM进行判断
- VLM返回Yes/No的结果,决定下一步行为
3. 具体例子:
论文中展示了一个处理杯子的例子(图8):
条件节点:"cup contains liquid"(杯子是否含有液体)
- 如果VLM判断有液体:机器人会先倒掉液体
- 如果VLM判断无液体:机器人直接丢弃杯子

这种设计的优势是:
灵活性:可以用自然语言描述各种视觉条件。
通用性:不需要为每种条件专门训练视觉模型。
这是因为系统使用了Vision-Language Models (VLM),特别是GPT-4V,它具有强大的零样本视觉理解能力。让我详细解释:
1. 传统方法的局限:
- 需要为每种视觉条件专门收集数据
- 需要训练特定的视觉模型
- 缺乏灵活性,增加新条件需要重新训练2. VLM方法的优势:
例如判断"杯子是否有液体":
- 传统方法:需要收集大量带/不带液体的杯子图片,训练专门的分类器
- VLM方法:直接用自然语言描述条件,VLM可以理解并判断
3. 关键技术:Self-prompting
- 系统会自动生成提示词:
- 输入:当前场景图片 + 条件描述(如"cup contains liquid")
- VLM:基于通用视觉理解能力做出判断
- 输出:Yes/No + 判断原因4. 优势:
- 零样本泛化:无需训练就能理解新的视觉条件
- 灵活性:只需修改文本描述就能更改判断条件
- 可解释性:VLM会解释其判断理由这种方法充分利用了VLM的通用视觉理解能力,避免了为每个具体任务训练专门模型的开销。
直观性:条件描述易于理解和修改
2 机器人生树
- 动作节点(Action Nodes):
- PickUp:拿起物体
- PourIntoBucket:倒入桶中
- ThrowAway:扔掉物体
- 视觉检查节点(Visual Check Nodes):
- VisualCheck:执行视觉检查
- GoalCheck:检查任务是否完成
- 控制节点(Control Nodes):
- Sequence:顺序执行
- Selector:选择执行
- Retry:重试执行
三 缺点
BT节点粒度依赖预定义动作(如PickUp),未覆盖所有机器人动作层级。
视觉条件准确性受限于VLM性能(如对轻微污渍的误判)。
需人工干预调整BT,完全自动化仍具挑战。
四 其他附录
VLM模型:
截至2025年2月,Visual Language Models (VLM) 在多个领域和评测基准上取得了显著进展。以下是一些知名的VLM模型及其在相关排名中的表现:
1.Flamingo (DeepMind): Flamingo 是一个多模态模型,能够处理图像和文本的联合输入。它在多个视觉问答(VQA)和图像描述任务中表现优异,尤其是在零样本和少样本学习场景下。
2. BLIP (Salesforce): BLIP 是一个专注于图像和文本对齐的模型,能够生成高质量的图像描述,并在视觉问答任务中表现出色。它在多个评测基准上排名靠前。
3. CLIP (OpenAI): CLIP 是一个强大的多模态模型,能够将图像和文本映射到同一个嵌入空间。虽然它主要用于图像分类和文本检索任务,但在VLM相关任务中也表现出色。
4. OFA (Unified Model for Vision and Language): OFA 是一个统一的视觉-语言模型,能够处理多种多模态任务,如图像描述、视觉问答和文本生成。它在多个评测基准上取得了领先的成绩。
5. VinVL (Microsoft): VinVL 是一个专注于视觉-语言预训练的模型,能够生成高质量的图像描述,并在VQA任务中表现出色。它在多个评测基准上排名靠前。
6. SimVLM (Google): SimVLM 是一个简单的视觉-语言模型,通过大规模预训练在多个视觉-语言任务中取得了优异的表现。
这些模型在公开的评测基准(如 COCO、VQA、Flickr30k 等)上都有详细的排名和性能比较。具体的排名可能会根据不同的评测基准和任务有所不同。建议查阅最新的研究论文和评测结果以获取最准确的信息。
如果需要更详细的排名和性能数据,建议参考相关学术会议(如 CVPR、ICCV、NeurIPS)上发布的最新研究成果。
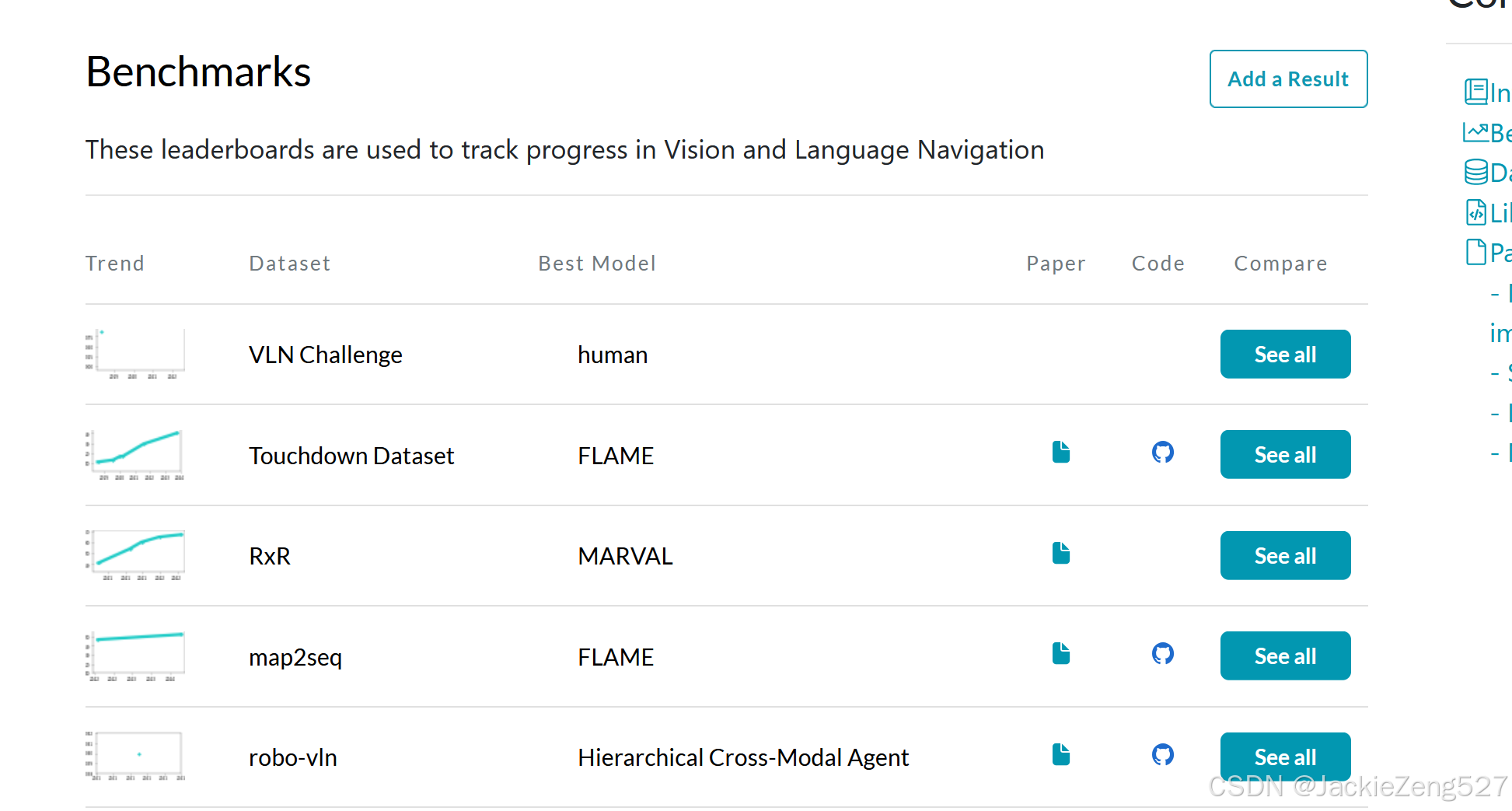
大家可以查找:Robots | Papers With Code

















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









