






生信碱移
GenePT: 另辟蹊径
人们的目光已经从语言任务的学习,转向了生物底层基因和细胞的学习。
基础模型的概念在生物学研究越来越火热,前者泛指一类大型机器学习模型,它们经大规模数据训练而成,能够用于广泛的下游任务,一般基于transformer架构。比如,最著名的Chatgpt便是通过大规模语料学习到了人类语言的基本属性。
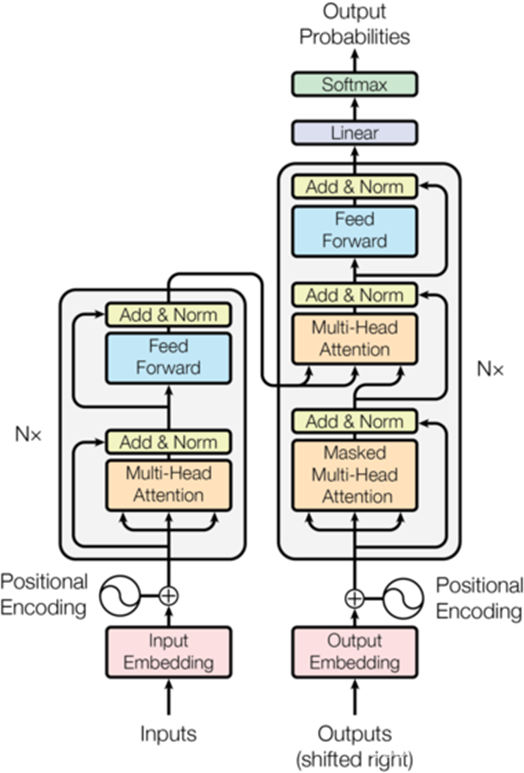
▲ transformer架构,通过词嵌入与attention机制表示超长文本之间的语义关系。图片来源:网络。
搞不懂上图也没关系,应用层面关键在于理解什么是“嵌入”?在针对自然语言的基础模型(大语言模型)中,嵌入是将文字(比如单词或句子)转化为数字形式的过程。计算机无法直接理解文字,因此需要把每个字、词或句子转换为计算机可以处理的数字向量(简单理解如下)。
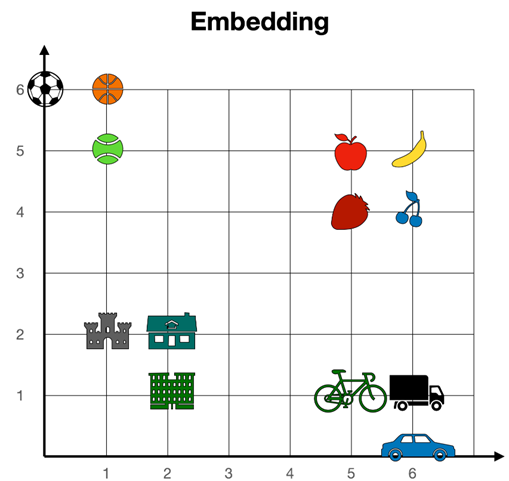
▲ 理解嵌入:举个简单的例子,假设你有两个词:“篮球”和“足球”。在传统的机器学习做法中,可能会把它们转换成一个简单的数字(例如“篮球”=1,“足球”=2)。但是,这种方法并没有体现出“篮球”和“足球”之间的相似性。嵌入技术的目标是将这些词转化为一个高维空间中的向量,使得相似的词(如“篮球”和“足球)在这个空间中的距离较近,而不相似的词(如“篮球”和“苹果”)则距离较远。图片来源:网络。
近年来,单细胞生物学领域对“基础模型”产生了浓厚兴趣。一些研究利用大批量的公开单细胞测序数据学习基因和细胞的嵌入表示,以促进各种下游分析(比如基因敲除、细胞聚类等)。像scBERT、Geneformer和scGPT等方法已经被提出,它们采用了相似的基本思路,包括以下几个步骤:
-
采用深度学习架构(通常来自transformer家族)。
-
收集大规模的单细胞基因表达数据,进行自监督预训练(即通过填补一些缺失的表达值)。训练后的编码器将输入的基因和细胞映射到一个高维嵌入向量,该向量封装了潜在的生物学信息。
-
对于下游任务,可以选择性地利用一定量的任务特定数据对模型进行微调,以提高其预测能力。
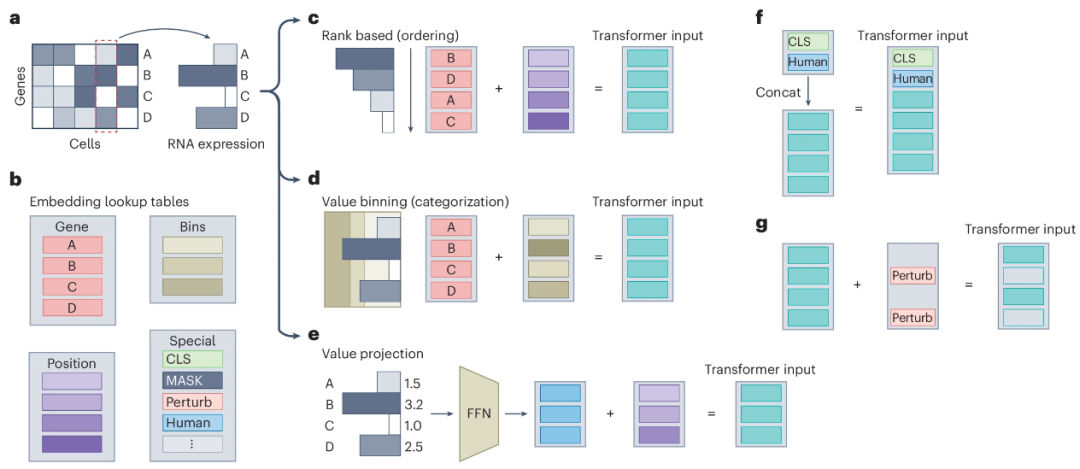
▲ 单细胞测序数据以单个细胞为单位,每个细胞可以获得数万个基因的表达量(维度:cells/genes)。为了适应transfomer的架构,研究者开发了不同的方法,将单细胞数据嵌入为模型可处理的格式。这些方法通过逐元素求和,将单个细胞的基因表达转换为嵌入表示,图中展示了常见的方法,包括基因嵌入、位置编码、值分箱和数据投影等。这些方法通过编码细胞的转录组特征,使transformer能够处理这些数据,其中位置编码反映了基因表达顺序或空间信息。特殊标记也被用于编码附加信息,如基因扰动或物种特定数据。具体可以参见文献DOI: 10.1038/s41592-024-02353-z。
值得注意的是,尽管上面的方法在单细胞转录组数据和任务的应用中取得了一定成功,但它也有几个局限性。①需要大量的工作来收集、处理和训练大规模的单细胞转录组数据。②从提取的嵌入中获得的信号,严重依赖于第二步中使用的基因表达数据,而这些数据未能充分利用基因功能相关的文献,可能导致样本效率低下并在某些应用中得出次优结果。为此,来自斯坦福大学的研究者提出了GenePT,一种替代且互补的方法,于2024年12月7日发表于 Nat. Biomed. Eng [IF: 26.8]。GenePT的特点是不需要使用大规模的单细胞进行预训练,仅通过利用ChatGPT文本嵌入模型与基因表达进行嵌入编码,节省了训练模型的成本。对于卷不动算力资源的研究者,可以说是提供了新的思路。

▲ DOI: 10.1038/s41551-024-01284-6
小编去年就看到这篇文章了,今天终于看到它上线了,便简单分享一下。其github链接如下,各位铁子也可自行学习:
-
https://github.com/yiqunchen/GenePT
GeneGPT原理介绍
GeneGPT的核心思想是通过大语言模型(如GPT-3.5)对基因信息进行嵌入,从而生成能够反映基因功能和细胞特征的嵌入向量(其他方法则是需要使用大规模的单细胞数据进行预训练,GeneGPT 属于是触类旁通、借花献佛了)。这些基因嵌入向量能够帮助我们在单细胞转录组学研究中更好地表示基因和细胞的生物学信息,被进一步用于细胞级别的嵌入表示。
具体来说,基因嵌入通过提取NCBI基因数据库中的文本摘要,并利用GPT-3.5生成每个基因的向量表示(维度为1536)。此过程去除了超链接和日期信息,确保基因信息的标准化和高效编码。同时,为了增加基因表示的全面性,还结合了基因别名和外部数据库(如HGNC)进行映射,并对不同类型的基因摘要输入进行了敏感性分析,以优化嵌入的准确性和泛化能力。
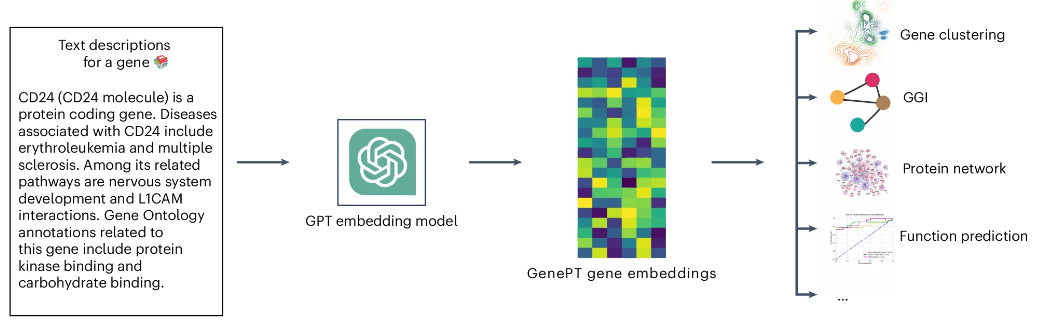
▲ 基因嵌入的生成方式如上,使用NIBI的文本进行输入生成,随后可以用于一些下游任务。
随后,GeneGPT设计了两个主要的细胞嵌入框架:GenePT-w(加权框架)和GenePT-s(句子框架)。
-
GenePT-w方法首先根据基因的标准化表达值计算加权 GPT 的平均基因嵌入,并将结果归一化为单位ℓ2范数;
-
GenePT-s方法则将细胞表示为一个基因名称按表达水平降序排列的自然语言句子,并将该句子传入GPT-3.5生成嵌入。
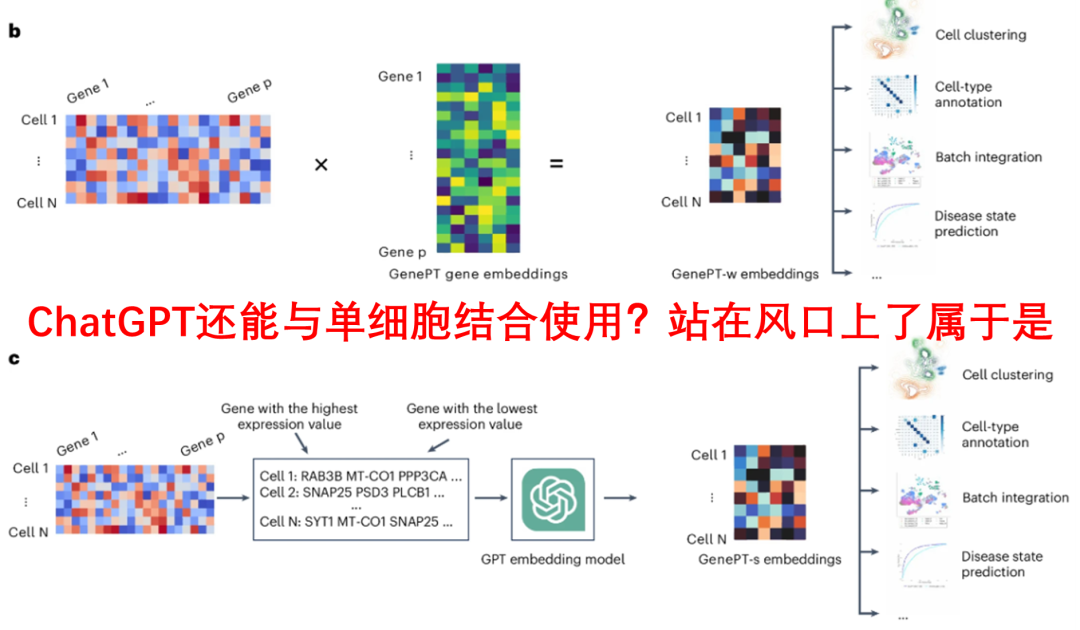
▲ 细胞嵌入的生成方法:b图文GenePT-w,c图为GenePT-s。其实简单来说就是对于一个细胞,有2万多个基因。每个基因使用gpt生成了嵌入,但同时也有基因的表达量。这两种方法便是用于融合这gpt嵌入和表达信息的。
上述两种方法分别从加权平均和基因排序两个角度来捕捉细胞的生物学信息,提供了灵活的细胞表示方式。最后,生成的基因嵌入与细胞嵌入可以用于下游的各种任务(如上图)。
GeneGPT使用方法
作者在示例中介绍了生成基因嵌入的方法,大家可以自行学习使用:
-
https://github.com/yiqunchen/GenePT/blob/main/gene_embeddings_examples.ipynb
▲ 整个文件的代码其实不长。
对于普通的研究者
训练一个大模型基本是不可能的
可以好好利用好gpt的嵌入功能
想想不同层面的嵌入
GenePT是细胞、基因级别
而组织、泛疾病等生物级别是否也能借鉴呢
今天就分享到这里了
欢迎各位佬哥点击关注

















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









