







我自己的原文哦~ https://blog.51cto.com/whaosoft/13774809
#MapDistill
速度精度双起飞,让End2End更丝滑
在线高精(HD)地图构建是自动驾驶领域的一项重要且具有挑战性的任务。最近,人们对不依赖于激光雷达等其他传感器的基于环视相机的低成本方法越来越感兴趣。然而只使用视觉传感器的方法缺乏明确的深度信息,需要更大的主干网络来实现令人满意的性能。为了解决这个问题,我们首次采用知识蒸馏(Knowledge Distillation, KD)思想进行高效的高精地图构建,引入了一种新的基于KD的在线矢量高精地图构建方法MapDistill。MapDistill将知识从高准确性的Camera-LiDAR融合模型转移到轻量级的仅依赖相机的模型。具体而言,我们采用师生架构,即Camera-LiDAR融合模型作为教师,轻量的只基于相机的模型作为学生,并设计了双BEV转换模块,以促进跨模态知识对齐。此外,我们还提出了一个适用于在线高精地图构建任务的全面蒸馏方案,包括跨模态关系蒸馏、双层特征蒸馏和地图任务头蒸馏。这种方法一定程度上解决了模态间知识转移的困难,使学生模型能够学习更好的用于高精地图构建的特征表示。我们在目前最具有挑战性的nuScenes数据集上的实验结果证明了MapDistill的有效性,超越了基线方法7.7 mAP或实现4.5倍的加速。
项目链接:https://github.com/Ricky-Developer/MapDistill
领域背景介绍
在线高精地图提供了丰富、精确的驾驶场景静态环境信息,是自动驾驶系统规划与导航模块的基础。最近,基于多视角相机的在线高精地图构建由于BEV感知技术的重大进展而受到越来越多的关注。相较于只基于激光雷达的方法和基于激光雷达与相机融合的方法,只基于多视角相机的方法具有更低的部署成本。但由于缺乏深度信息,目前的基于纯视觉的方案常常采用参数更多的骨干网络进行有效的特征提取以取得较好的性能。因此,在实际部署中权衡基于摄像机的模型的性能和效率是至关重要的。
知识蒸馏(Knowledge Distillation, KD)作为训练高效而准确的模型最实用的技术之一,在相关领域受到了极大的关注。基于知识蒸馏的方法通常将知识从训练有素的大模型(教师)转移到小模型(学生)。这类方法在图像分类、二维目标检测、语义分割和三维目标检测等许多领域取得了显著进展。以前的方法大多遵循需学生网络逻辑与教师网络逻辑相匹配的teacher-student范式。最近,基于BEV的知识蒸馏方法推动了3D目标检测任务的发展。这类方法统一了BEV空间中的图像和点云特征,并在师生范式中自适应地跨非同质表示传递知识。此前的工作使用强激光雷达教师模型帮助相机学生模型进行训练,如BEVDistill、UVTR、BEVLGKD、TiG-BEV和DistillBEV。最近,UniDistill提出了一种用于3D目标检测的通用跨模态知识蒸馏框架。
与这些方法相比,基于BEV的在线高精地图构建知识蒸馏方法在两个关键方面有所不同:首先,检测头(DetHead)对目标进行分类和定位输出,而在在线矢量高精地图构建模型(如MapTR)中地图头(MapHead)往往输出的是分类和点回归结果。其次,现有的基于BEV的3D目标检测知识蒸馏方法通常侧重于对准前景目标的特征,以减轻背景环境的不利影响,这显然不适合高精地图的构建。因此,将基于BEV的3D目标检测知识蒸馏方法直接应用于的高精地图构建中,由于两者任务的内在差异性,无法获得满意的结果(实验结果见表1)。据我们所知,基于BEV的用于在线高精地图构建的知识蒸馏方法仍处于探索阶段。
为了填补这一空白,我们提出了一种新的基于知识蒸馏的方法MapDistill,将知识从高性能的教师模型转移到高效的学生模型。首先,我们采用师生架构,即相机-激光雷达融合模型作为教师,轻量化的只基于相机传感器的模型作为学生,并设计了双BEV转换模块,以促进跨模态知识升华,同时保持成本效益的只基于相机传感器的建图方案部署。在此基础上,我们提出了一种包含跨模态关系蒸馏、双层特征蒸馏和地图头部蒸馏的综合蒸馏方案,以减轻模态之间的知识转移挑战,并帮助学生模型学习改进的高精地图构建特征表示。具体来说,我们首先为学生模型引入了跨模态关系蒸馏损失,以便从融合教师模型中更好地学习跨模态表示。其次,为了更好地实现语义知识转移,我们在统一的BEV空间中对低级和高级特征表示都采用了两级特征蒸馏损失。最后,我们特别引入了为高精地图构建任务量身定制的地图头蒸馏损失,包括分类损失和点对点损失,它可以使学生的最终预测与教师的预测非常相似。在具有挑战性的nuScenes数据集上的大量实验证明了MapDistill的有效性,超越了现有竞争对手超过7.7 mAP或4.5倍的加速,如图1所示。

图1:nuScenes数据集上不同方法的比较。我们在单个NVIDIA RTX 3090 GPU上对推理速度进行基准测试。MapDistill可以在速度(FPS)和精度(mAP)之间实现更好的平衡。
本文的贡献主要体现在三个方面:
- 我们提出了一种用于在线高精地图构建任务的有效知识蒸馏模型架构,包括相机-激光雷达融合教师模型,带有双BEV转换模块的轻量级相机学生模型,该模块促进了不同模式内部、之间的知识转移,同时具备低成本、易部署的特征。
- 我们提出了一种同时支持跨模态关系蒸馏、两级特征蒸馏和地图头蒸馏的综合蒸馏方案。通过减轻模态之间的知识转移挑战,该方法可以帮助学生模型更好地学习高精地图构建的特征表示。
- MapDistill的性能优于最先进的(SOTA)方法,可以作为基于知识蒸馏的高精地图构建研究的强大基线。
MapDistill
在本节中,我们将详细描述我们提出的MapDistill。我们首先在图2中给出了整个框架的概述图示,并在2.1节中阐明了教师模型和学生模型的模型设计。然后,我们在第2.2节详细阐述MapDistill的细节,如跨模态关系蒸馏、两级特征蒸馏和地图头蒸馏。

图2:MapDistill由一个基于多模态融合的教师模型(上)和一个基于轻量级相机传感器的学生模型(下)组成。此外,为了使教师模型能够将知识传递给学生,我们采用了三种蒸馏损失以指导学生模型产生相似的特征和预测,即跨模态关系蒸馏、两级特征蒸馏和地图头蒸馏。特别说明,推理只使用学生模型进行。
2.1 模型整体架构
融合模型(教师):为了将Camera-LiDAR融合教师模型的知识转移到学生模型,我们首先基于最先进的MapTR模型建立了基于融合的高精地图构建基线。如图二上半部分所示,融合的MapTR模型有两个分支。对于相机分支,首先使用Resnet50提取多视图图像特征。接下来,使用GKT作为2D-to-BEV转换模块,将多视图特征转换为BEV空间。生成的摄像机BEV特征可表示,其中H、W、C分别表示BEV特征的高度、宽度和通道数,上标T为“teacher”的缩写。激光雷达分支采用SECOND进行点云体素化和特征编码,采用Bevfusion中的展平操作将点云特征投影到BEV空间,表示为。此后,MapTR将和聚合,并使用全卷积网络进行处理,获取融合鸟瞰特征。此后,MapTR使用以融合BEV特征作为输入的地图编码器产生高维BEV特征。

然后,教师地图头(MapHead)使用分类和点分支来生成地图元素类别和点位置的最终预测:

基于相机传感器的模型(学生):为了提升实际部署的实时推理速度,我们采用MapTR的相机分支作为学生模型的基础。特别的,我们使用Resnet18作为主干来提取多视图特征,这可以使网络轻量级且易于部署。在MapTR的基础上,为了模拟教师模型的多模态融合管道,我们提出了一个双流 BEV转换模块,将多视图特征转换成两个不同的BEV子空间。具体的来说,我们首先使用GKT生成第一个子空间特征,其中上标S表示“student”的缩写。然后我们使用LSS生成另一个子空间的鸟瞰特征。此后,我们使用全卷积网络融合上述两个子空间鸟瞰特征,获得融合BEV特征。
2.2 MapDistill的细节
跨模态关系蒸馏:跨模态关系蒸馏的核心思想是让学生模型在训练过程中模仿教师模型的跨模态注意力。更具体地说,对于教师模型,我们调整相机BEV特征和激光雷达BEV特征转换为2D patches序列,表示为。之后,我们计算来自教师分支的跨模态注意力,包含C2L注意和L2C注意力,如下所示:

对于学生分支,我们使用相同的策略:

此后,我们提出了跨模态关系蒸馏,采用KL散度损失帮助对齐学生分支与教师分支的跨模态注意力。

两级特征蒸馏:为了方便学生模型从教师模型中吸收丰富的语义/几何知识,我们利用融合的BEV特征进行特征级蒸馏。具体来说,我们通过MSE损失,让老师分支的low-level融合BEV特征监督学生分支对应的low-level BEV特征:
![]()
相似地,我们使用MSE损失帮助对齐由地图编码器生成的和:
![]()
我们使用两级特征蒸馏进行统一表示:
![]()
地图任务头蒸馏:为了使学生的最终预测接近老师的预测,我们进一步提出了地图任务头蒸馏。具体来说,我们使用教师模型生成的预测作为伪标签,通过地图任务头损失来监督学生模型。地图任务头损失由两部分表示,其中分类损失函数用于地图元素分类,基于曼哈顿距离的点对点损失用于点位置的回归:

实验与SOTA方法的比较
我们在nuScenes数据集进行了大量实验。我们将我们的方法与两类最先进的基线进行了比较,即基于摄像机的高精地图构建方法,以及最初被设计用于实现基于BEV的3D目标检测的知识蒸馏方法。对于基于知识蒸馏的方法,我们实现了三种基于bev的三维目标检测方法,并针对高精地图构建任务进行了修改,分别是BEV-LGKD、BEVDistill和UnDistill。为了公平起见,我们使用与我们的方法相同的教师和学生模型。实验结果如表1所示。

消融实验:
三项知识蒸馏损失函数的影响:如表2所示,在模型变量(a)、(b)、(c)中,我们单独使用不同的蒸馏损失对学生分支进行训练。实验结果表明,与基线方法相比,三项损失函数均对模型表现出提升。此外,模型变量(d)、(e)、(f)证明了不同蒸馏损失项的结果是相互补充的。最终,将所有的蒸馏损失融合在一起,我们得到了完整的MapDistill结果,实现了53.6mAP的先进性能。

不同高精地图构建方法的消融研究:如表5(a)所示,为了探究MapDistill与不同高精地图构建方法的兼容性,我们综合对比了两种流行的方法,结果如表5a所示。其中,Teacher model-1和Teacher model-2分别是使用SwinTransformer-T的MapTR变体模型和最先进的MapTRv2模型。注意,两个学生模型都使用Resnet 18作为主干来提取多视图特征。实验结果表明,效果更好的教师模型将教出更好的学生模型。由于已完成预训练的教师模型已经获得了构建高精地图的宝贵知识,学生模型可以通过知识蒸馏技术(例如所提出的MapDistill)有效地利用这些知识,从而增强其执行相同任务的能力。此外,结果表明我们的方法对不同的教师模型都是有效的。
各种学生模型的消融研究:如表5(b)所示,为了探究MapDistill在不同学生模型下的泛化能力,我们综合考察了两种流行的骨干网络作为学生模型的骨干。其中Student model- i和Student model- ii是指学生模型分别采用Resnet50和SwinTransformer-T作为主干提取多视图特征。这里我们使用MapTR作为Teacher,即表1中的R50&Sec融合模型作为教师模型。实验结果表明,我们的方法始终能取得较好的结果,证明了方法的有效性和泛化能力。

可视化结果
如图4所示,我们比较了来自不同模型的预测,即基于相机-激光雷达的教师模型,没有MapDistill的基于摄像机的学生模型(基线方法),以及带有MapDistill的基于摄像机的学生模型。各模型的mAP值分别为62.5、45.9、53.6,如表1所示。我们观察到基线模型的预测有很大的不准确性。然而,采用MapDistill方法部分纠正了这些错误,提高了预测精度。

图4:nuScenes val 数据集的可视化结果。(a) 输入的6个视角图像。(b)GT (c)基于摄像头-激光雷达的教师模型的结果。(d)没有MapDistill的基于相机的学生模型的结果(基线)。(e)使用MapDistill的基于相机的学生模型的结果。
结论
在本文中,我们提出了一种名为MapDistill的新方法,通过相机-激光雷达融合模型蒸馏来提高只基于相机的在线高精地图构建效率,产生一种经济高效且准确的解决方案。MapDistill是建立在一个相机-激光雷达融合的教师模型,一个轻量级的只依赖于相机的学生模型,和一个专门设计的双流BEV转换模块。此外,我们还提出了一种包含跨模态关系蒸馏、两级特征蒸馏和地图任务头蒸馏的综合蒸馏方案,促进了不同模态内部和不同模态之间的知识转移,帮助学生模型获得更好的性能。大量的实验和分析验证了我们的MapDistill的设计选择和有效性。
局限性与社会影响:使用知识蒸馏策略,学生模式可以继承教师模式的弱点。更具体地说,如果教师模型是有偏见的,或者对不利的天气条件和/或长尾情景没有鲁棒性,那么学生模型可能表现得类似。MapDistill具有成本效益,在自动驾驶等实际应用中显示出巨大的潜力。
#简单总结SLAM中的各种地图
自己搞了这么多年SLAM,使用的主要还是点云地图。虽然知道种种地图表征,但一直没有梳理过。最近集中时间学习了一下各种地图,在这里进行整理与分享。能力有限,难免有不恰之处,请批评指正。
1、地图的不同分类方式
地图有多种不同的分类方式,网上有不少帖子介绍各种各样的地图,但并没有非常完整的总结地图应该怎么分类。论文[1]中将地图分成以下几种:拓扑地图、度量地图、度量-语义地图和混合地图。我觉得按照这种方式进行归类相对比较科学。
1.1 拓扑地图
拓扑地图(Topological Map)使用节点和边来表示环境,其中节点表示重要位置(如拐角、门口),边表示这些位置之间的可达路径。拓扑地图注重表示环境的连接关系,而不是具体的几何细节。这种地图表示方法适用于大型、复杂环境中的高效路径规划和导航。个人简单理解为,是一种表示拓扑关系、不存在准确距离信息的地图,例如:我家地图是,客厅在中间,周围连着卧室、书房、厨房、卫生间,书房又连着阳台。

1.2 度量地图/尺度地图/几何地图
度量地图(Metric Map)或几何地图(Geometric Map)是SLAM种较为常用的一种表示方法,常见的点云(PointCloud)、八叉树地图(OctoMap)、栅格地图(Grid Map)等都属于度量地图,下一节会展开介绍。个人简单的理解为,能够从这个地图中获取具体的尺度信息,例如某个点距离某个点多远、XXX障碍物面积有多大。
根据地图的稠密程度,度量地图还可进一步分为:稀疏地图、稠密地图。稀疏地图例如视觉SLAM建立的特征点地图,是稀疏的,一般多用于自身定位而难以直接导航;而RGBD或LiDAR可以建立稠密地图。
根据地图是连续的还是离散的,还可进一步分为:离散地图、连续地图。栅格地图、体素地图(Voxel Map)就是典型的离散地图,把空间进行了划分,然后离散化表达;连续地图是采用高斯过程或者NeRF方式建立的地图。

离散地图(左)与连续地图(右)
1.3 语义地图
语义地图(Semantic Map)是包含了语义信息的地图,语义信息可以是物体的种类、姿态和形状等描述。例如,无人驾驶需要知道地图中那些是车道、哪些是障碍。需要注意的是,只要包含于语义信息就可以算是语义地图,尺度地图、拓扑地图也可以是语义地图。

带语义信息的点云地图(左)和带语义信息的拓扑地图(右)
1.4 混合地图与多层级地图
混合地图(Hybrid Map)是一种结合多种地图表示的地图,例如在大范围导航时,我们可能既需要拓扑信息(从客厅到卧室),又需要尺度信息(走多少米),这就需要混合地图。
分层级地图(Hierarchy Map)顾名思义,是多层次的地图表示,通过将环境信息组织成不同层次以提高数据管理和处理的效率。例如无人驾驶时,顶层地图表示全局的道路网络,底层表示局部的道路详细结构,可以理解成“分辨率”从粗到细的过程,以适应不同的任务需求。
2、尺度地图细分
2.1 特征地图
特征地图(Feature Map)是仅保留特征的地图,常见于视觉SLAM。一些场景,例如水下的定位放置一些标志物,这样建立的地图就是特征点地图。视觉SLAM一般提取特征点匹配后建立特征点地图。除了点特征意外,线特征和面特征也可以建立地图,但也属于是特征地图的一种。

左:水下声呐建立的声呐目标特征点地图;中:vSLAM建立的特征点地图;右:线+面特征地图
2.2 点云地图
点云地图(Point Cloud Map)是利用点云形式表示地图,常见的激光雷达SLAM建立的都是点云地图。

2.3 栅格地图
栅格地图(Grid Map)将空间划分为均匀的网格,每个网格存储一个值,表征地图的属性。一种常见的方式,用三种状态:占用、空闲、未知,表示某个栅格是否被占用,这种表达方式称作“占用栅格地图”(Occupancy Grid Map),机器人导航常用栅格地图,在“空闲”栅格中规划运动轨迹。一般来说,栅格地图指的是二维平面地图。

2.4 体素地图
体素地图(Voxel Map)可以理解为三维的栅格地图,当然也包括占用体素地图(Occupancy Grid Map)。如果是无人机这类的导航,一般需要用到3D的栅格地图。和点云地图相比,体素地图的“分辨率”更低,对点云地图进行了离散化。

室内场景的占用栅格地图(左)和用于无人机导航的占用栅格地图(右)
2.5 高程地图
高程地图(Elevation Map)也称2.5D地图。如果是平坦地面、二维场景,用栅格地图就可以;如果是无人机,需要用到三维场景体素地图;但如果是无人车在非平坦路面运行、或者是四足/轮式机器人在野外的行进,需要对地形进行建模,常用的方式就是高程地图,例如经典的elevation mapping就是建立的高程地图[2]。在栅格地图的基础上增加了一个维度即高度。

2.6 神经辐射场地图
神经辐射场地图(Neural Radiance Fields, NeRF)是一种新兴的三维场景表示和渲染技术,通过神经网络隐式地表示三维空间中的颜色和密度场。其特点是高精度、连续表示、数据驱动。具体可参考[6]。

2.x 八叉树地图、ikdtree地图、哈希地图等
这些我认为不属于具体的地图表征形式,只是地图存储的数据结构。具体来说:
- 八叉树地图(Octree Map)是利用八叉树数据结构存储体素地图,可以节省数据存储空间。具体实现例如 OctoMap[3]
- ikdtree地图是动态kd-tree的地图,存储的是原始点云形式,由Fastlio2[4]采用,专门用于处理点云数据的高效存储、增量更新和查询
- 哈希地图(Hash Map)使用哈希函数将二维或者三维空间坐标映射到哈希表中,用于存储和检索空间信息,节省存储空间,存取速度快,可以存储点云地图、体素地图
除此之外,还有其他改进例如i-octree[5]等,不展开介绍。
3、一些讨论
这里记录一些自己学习的困惑,或者其他地方的讨论。
3.1 为什么要关注地图的表示?
对于最基础的SLAM而言,实现了定位与建图任务就可以了。但问题是,建立的地图要干什么、如何服务后面的任务?如果不加以考虑、忽视建图,就完全是一个定位过程了。所以,需要根据后续任务决定建立什么地图。
3.2 无人驾驶的高精度地图是什么?
个人简单总结,就是:尺度地图的绝对坐标精度更高,所包含的道路交通信息元素丰富细致。按照第一部分的分类,应该数据多层级地图。
4、小结
本文整理了一些SLAM领域常见的地图,但并没有细致讨论每种地图的优缺点以及应用场景。
参考文献
[1] Survey on Active Simultaneous Localization and Mapping: State of the Art and New Frontiers
[2] GitHub - ANYbotics/elevation_mapping: Robot-centric elevation mapping for rough terrain navigation
[3] https://octomap.github.io/
#ModelMerging
无需训练数据!合并多个模型实现任意场景的感知
近日,来自清华大学智能产业研究院(AIR)助理教授赵昊老师的团队,联合戴姆勒公司,提出了一种无需训练的多域感知模型融合新方法。研究重点关注场景理解模型的多目标域自适应,并提出了一个挑战性的问题:如何在无需训练数据的条件下,合并在不同域上独立训练的模型实现跨领域的感知能力?团队给出了“Merging Parameters + Merging Buffers”的解决方案,这一方法简单有效,在无须访问训练数据的条件下,能够实现与多目标域数据混合训练相当的结果。
论文题目:
Training-Free Model Merging for Multi-target Domain Adaptation
作者:Wenyi Li, Huan-ang Gao, Mingju Gao, Beiwen Tian, Rong Zhi, Hao Zhao
1 背景介绍
一个适用于世界各地自动驾驶场景的感知模型,需要能够在各个领域(比如不同时间、天气和城市)中都输出可靠的结果。然而,典型的监督学习方法严重依赖于需要大量人力标注的像素级注释,这严重阻碍了这些场景的可扩展性。因此,多目标域自适应(Multi-target Domain Adaptation, MTDA)的研究变得越来越重要。多目标域自适应通过设计某种策略,在训练期间同时利用来自多个目标域的无标签数据以及源域的有标签合成数据,来增强这些模型在不同目标域上的鲁棒性。
与传统的单目标域自适应 (Single-target Domain Adaptation, STDA)相比,MTDA 面临更大的挑战——一个模型需要在多个目标域中都能很好工作。为了解决这个问题,以前的方法采用了各种专家模型之间的一致性学习和在线知识蒸馏来构建各目标域通用的学生模型。尽管如此,这些方法的一个重大限制是它们需要同时使用所有目标数据,如图1(b) 所示。
但是,同时访问到所有目标数据是不切实际的。一方面原因是数据传输成本限制,因为包含数千张图像的数据集可能会达到数百 GB。另一方面,从数据隐私保护的角度出发,不同地域间自动驾驶街景数据的共享或传输可能会受到限制。面对这些挑战,在本文中,我们聚焦于一个全新的问题,如图1(c) 所示。我们的研究任务仍然是MTDA,但我们并没有来自多个目标域的数据,而是只能获得各自独立训练的模型。我们的目标是,通过某种融合方式,将这些模型集成为一个能够适用于各个目标域的模型。

图1:不同实验设置的对比
2 方法
如何将多个模型合并为一个,同时保留它们在各自领域的能力?我们提出的解决方案主要包括两部分:Merging Parameters(即可学习层的weight和bias)和 Merging Buffers(即normalization layers的参数)。在第一阶段,我们从针对不同单目标域的无监督域自适应模型中,得到训练后的感知模型。然后,在第二阶段,利用我们提出的方法,在无须获取任何训练数据的条件下,只对模型做合并,得到一个在多目标域都能工作的感知模型。

图2:整体实验流程
下面,我们将详细介绍这两种合并的技术细节和研究动机。
2.1 Merging Parameters
2.1.1 Permutation-based的方法出现退化
事实上,如何将模型之间可学习层的 weight 和 bias 合并一直是一个前沿研究领域。在之前的工作中,有一种称为基于置换 (Permutation-based) 的方法。这些方法基于这样的假设:当考虑神经网络隐藏层的所有潜在排列对称性时,loss landscape 通常形成单个盆地(single basin)。因此,在合并模型参数 和时,这类方法的主要目标是找到一组置换变换 ,确保 在功能上等同于 ,同时也位于参考模型 附近的近似凸盆地(convex basin)内。之后,通过简单的中点合并 以获得一个合并后的模型 ,该模型能够表现出比单个模型更好的泛化能力,
在我们的实验中,模型 和 在第一阶段都使用相同的网络架构进行训练,并且,源数据都使用相同的合成图像和标签。我们最初尝试采用了一种 Permutation-based 的代表性方法——Git Re-Basin,该方法将寻找置换对称变换的问题转化为线性分配问题 (LAP),是目前最高效实用的算法。

图3:Git Re-basin和mid-point的实验结果对比
但是,如图3所示,我们的实验结果出乎意料地表明,不同网络架构(ResNet50、ResNet101 和 MiT-B5)下 Git Re-Basin 的性能与简单中点合并相同。进一步的研究表明,Git Re-Basin 发现的排列变换在解决 LAP 的迭代中保持相同的排列,这表明在我们的领域适应场景下,Git Re-Basin 退化为一种简单的中点合并方法。
2.1.2 线性模式连通性的分析
我们从线性模式连通性(linear mode connectivity)的视角进一步研究上述退化问题。具体来说,我们使用连续曲线 在参数空间中连接模型 和模型 。在这种特定情况下,我们考虑如下线性路径,
接下来,我们通过对 做插值遍历评估模型的性能。为了衡量这些模型在两个指定目标域(分别表示为 和 )上的有效性,我们使用调和平均值 (Harmonic Mean) 作为主要评估指标,
我们之所以选择调和平均值作为指标,是因为它能够赋予较小的值更大的权重,这能够更好应对世界各地各个城市中最差的情况。它有效地惩罚了模型在一个目标域(例如,在发达的大城市)的表现异常高,而其他目标域(例如,在第三世界乡村)表现低的情况。不同插值的实验结果如图4(a)所示。“CS”和“IDD”分别表示目标数据集 Cityscapes 和 Indian Driving Dataset。

图4:线性模式连通性的分析实验
2.1.3 理解线性模式连通性的原因
在上述实验结果的基础上,我们进一步探究:在先前域自适应方法中观察到的线性模式连通性,背后的根本原因是什么?为此,我们进行了消融实验,来研究第一阶段训练 和 期间的几个影响因素。
- 合成数据。使用相同的合成数据可以作为两个域之间的桥梁。为了评估这一点,我们将合成数据集 GTA 中的训练数据划分为两个不同的非重叠子集,每个子子集包含原始训练样本的 30%。在划分过程中,我们将合成数据集提供的具有相同场景标识的图像分组到同一个子集中,而具有显着差异的场景则放在单独的子集中。我们使用这两个不同子集分别作为源域,训练两个单目标域自适应模型(目标域为 CityScapes 数据集)。随后,我们研究这两个 STDA 模型的线性模式连通性。结果如图 4(b) 所示,可以观察到,在参数空间内连接两个模型的线性曲线上,性能没有明显下降。这一观察结果表明,使用相同的合成数据并不是影响线性模式连通性的主要因素。
- 自训练架构。使用教师-学生模型可能会将最后的模型限制在 loss landscape 的同一 basin 中。为了评估这种可能性,我们禁用了教师模型的指数移动平均 (EMA) 更新。相应地,我们在每次迭代中将学生权重直接复制到教师模型中。随后,我们继续训练两个单目标域自适应模型,分别利用 GTA 作为源域,Cityscapes 和 IDD 作为目标域。然后,我们研究在参数空间内连接两个模型的线性曲线,结果如图 4(c) 所示。我们可以看到线性模式连接属性保持不变。
- 初始化和预训练。 使用相同的预训练权重初始化 backbone 的做法,可能会使模型在训练过程中难以摆脱的某一 basin。为了验证这种潜在情况,我们初始化两个具有不同权重的独立 backbone,然后继续针对 Cityscapes 和 IDD 进行域自适应。在评估两个收敛模型之间的线性插值模型时,我们观察到性能明显下降,如图 4(d) 所示。为了更深入地了解潜在因素,我们继续探究,是相同的初始权重,还是预训练过程导致了这种影响? 我们初始化两个具有相同权重但没有预训练的主干,然后再次进行实验。有趣的是,我们发现,在参数空间的线性连接曲线仍然遇到了巨大的性能障碍,如图 4(e) 所示。这意味着预训练过程在模型中的线性模式连接方面起着关键作用。
2.1.4 关于合并参数的小结
我们通过大量实验证明,当领域自适应模型从相同的预训练权重开始时,模型可以有效地过渡到不同的目标领域,同时仍然保持参数空间中的线性模式连通性。因此,这些训练模型可以通过简单的中点合并,得到在两个领域都有效的合并模型。
2.2 Merging Buffers
Buffers,即批量归一化 (BN) 层的均值和方差,与数据域密切相关。因为数据不同的方差和均值代表了域的某些特定特征。在合并模型时如何有效地合并 Buffers 的问题通常被忽视,因为现有方法主要探究如何合并在同一域内的不同子集上训练的两个模型。在这样的前提下,之前的合并方法不考虑 Buffers 是合理的,因为来自任何给定模型的 Buffers 都可以被视为对整个总体的无偏估计,尽管它完全来自随机数据子样本。
但是,在我们的实验环境中,我们正在研究如何合并在完全不同的目标域中训练的两个模型,这使得 Buffers 合并的问题不再简单。由于我们假设在模型 A 和模型 B 的合并阶段无法访问任何形式的训练数据,因此我们可用的信息仅限于 Buffers 集 。其中, 表示 BN 层的数量,而 、 和 分别表示第 层的平均值、标准差和 tracked 的批次数。生成 BN 层的统计数据如下:
以上方程背后的原理可以解释如下:引入 BN 层是为了缓解内部协变量偏移(internal covariate shift)问题,其中输入的均值和方差在通过内部可学习层时会发生变化。在这种情况下,我们的基本假设是,后续可学习层合并的 BN 层的输出遵循正态分布。由于生成的 BN 层保持符合高斯先验的输入归纳偏差,我们根据从 和 得到的结果估计 和 。如图5所示,我们获得了从该高斯先验中采样的两组数据点的均值和方差,以及这些集合的大小。我们利用这些值来估计该分布的参数。

图5:合并BN层的示意图
当将 Merging Buffers 方法扩展到 个高斯分布时,tracked 的批次数 、均值的加权平均值 和方差的加权平均值可以按如下方式计算。
3 实验与结果
3.1 数据集
在多目标域适应实验中,我们使用 GTA 和 SYNTHIA 作为合成数据集,并使用 Cityscapes 、Indian Driving Dataset 、ACDC 和 DarkZurich 的作为目标域真实数据集。在训练单个领域自适应模型时,使用带有标记的源域数据和无标记的目标域数据。接下来,我们采用所提出的模型融合技术,直接从训练好的模型出发构建混合模型,这个过程中无需使用训练数据。
3.2 与Baseline模型的比较
在实验中,我们将我们的模型融合方法在 MTDA 任务上的结果与几种 baseline 模型进行对比。baseline 模型包括数据组合(Data Comb.)方法,其中单个域自适应模型在来自两个目标域的混合数据上进行训练(这个baseline仅供参考,因为它们与我们关于数据传输带宽和数据隐私问题的设定相矛盾)。baseline 模型还包括单目标域自适应(STDA),即为单一目标域训练的自适应模型,评估其在两个域上的泛化能力。

表1:与Baseline模型的比较
表 1 展示了基于 CNN 架构的 ResNet101和基于 Transformer 架构的 MiT-B5 的结果。与最好的单目标域自适应模型相比,当将我们的方法分别应用于 ResNet101 和 MiT-B5 两种不同 Backbone 时,在两个目标域上性能的调和平均值分别提高 +4.2% 和 +1.2%。值得注意的是,这种性能水平(ResNet101架构下的调和平均值为 56.3%)已经与数据组合(Data Comb.)方法(56.2%)相当,而且我们无需访问任何训练数据即可实现这一目标。
此外,我们探索了一种更为宽松的条件,其中仅合并 Encoder backbone,而 decoder head 则针对各个下游域进行分离。值得注意的是,这种条件下,分别使两种 backbone 下的调和平均性能显著提高 +5.6% 和 +2.5%。我们还发现,我们提出的方法在大多数类别中能够始终实现最佳调和平均,这表明它能够增强全局适应性,而不是偏向某些类别。
3.3 与SoTA模型的比较
我们首先将我们的方法与 GTACityscapes 任务上的单目标域自适应 (STDA) 进行比较,如表 2 所示。值得注意的是,我们的方法可以应用于任何这些方法,只要它们使用相同的预训练权重适应不同的域。这使我们能够使用单个模型推广到所有目标域,同时保持 STDA 方法相对优越的性能。

表2:与SoTA模型的比较
我们还将我们的方法与表 2 中的域泛化(DG)方法进行了比较,域泛化旨在将在源域上训练的模型推广到多个看不见的目标域。我们的方法无需额外的技巧,只需利用参数空间的线性模式连接即可实现卓越的性能。在多目标域自适应领域,我们的方法也取得了领先。我们不需要对多个学生模型做显式的域间一致性正则化或知识提炼,但能使 STDA 方法中的技术(如多分辨率训练)能够轻松转移到 MTDA 任务。可以观察到,我们对 MTDA 任务的最佳结果做出了的显著改进,同时消除了对训练数据的依赖。
3.4 多目标域拓展
我们还扩展了我们的模型融合技术,以涵盖四个不同的目标领域:Cityscapes 、IDD 、ACDC 和 DarkZurich 。每个领域都面临着独特的挑战和特点:Cityscapes 主要关注欧洲城市环境,IDD 主要体现印度道路场景,ACDC 主要针对雾、雨或雪等恶劣天气条件,DarkZurich 则主要处理夜间道路场景。我们对针对每个领域单独训练后的模型,以及用我们的方法融合后的模型进行了全面评估。

表3:在4个目标域上的实验结果
如表 3 所示,我们提出的模型融合技术表现出显著的性能提升。虽然我们将来自单独训练模型的调和平均值最高的方法作为比较的基线,但所有基于模型融合的方法都优于它,性能增长高达 +5.8%。此外,尽管合并来自多个不同领域模型的复杂性不断增加,但我们观察到所有领域的整体性能并没有明显下降。通过进一步分析,我们发现我们的方法能够简化领域一致性的复杂性。现有的域间一致性正则化和在线知识提炼方法的复杂度为 ,而我们的方法可以将其减少到更高效的 ,其中 表示考虑的目标域数量。
3.5 消融实验
我们使用 ResNet101 和 MiT-B5 作为分割网络中的图像编码器,对我们提出的 Merging Parameters 和 Merging Buffers 方法进行了消融研究,结果如表 4 所示。我们观察到单目标域自适应 (STDA) 模型在不同域中的泛化能力存在差异,这主要源于所用目标数据集的多样性和质量差异。尽管如此,我们还是选择 STDA 模型中的最高的调和平均值作为比较基线。

表4:消融实验
表 4(a) 和 4(b) 中的数据显示,采用简单的中点合并方法对参数进行处理,可使模型的泛化能力提高 +2.7% 和 +0.6%。此外,当结合 Merging Buffers 时,这种性能的增强会进一步放大到 +4.2% 和+1.2%。我们还观察到 MiT-B5 作为 backbone 时的一个有趣现象:在 IDD 域中进行评估时,融合模型的表现优于单目标自适应模型。这一发现意味着模型可以从其他域获取域不变的知识。这些结果表明,我们提出的模型融合技术的每个部分都是有效的。
3.6 模型融合在分类任务上的应用
我们还通过实验验证了我们所提出的模型融合方法在图像分类任务上的有效性。通过将 CIFAR-100 分类数据集划分为两个不同的、不重叠的子集,我们在这些子集上独立训练两个 ResNet50 模型,标记为 A 和 B。这种训练要么从一组共同的预训练权重中进行,要么从两组随机初始化的权重中进行。模型 A 和 B 的性能结果如图 6 所示。结果表明,从相同的预训练权重进行融合的模型优于在任何单个子集上训练的模型。相反,当从随机初始化的权重开始时,单个模型表现出学习能力,而合并模型的性能类似于随机猜测。

图6:CIFAR-100 分类任务上的模型融合结果
随机初始化会破坏模型线性平均性,而相同的预训练主干会导致线性模式连接。我们在另一个预训练权重上再次验证了这个结论。图 7 中的结果表明,DINO 预训练和 ImageNet 预训练在模型参数空间中具有不同的loss landscape,模型的融合必须在相同的loss landscape内进行。

图7:ImageNet和DINO预训练权重对线性模式连接的影响
4 结论
本文介绍了一种新颖的模型融合策略,旨在解决多目标域自适应 (MTDA)问题,同时无需依赖训练数据。研究结果表明,在大量数据集上进行预训练时,基于 CNN 的神经网络和基于 Transformer 的视觉模型都可以将微调后模型限制在 loss landscape 的相同 basin 中。我们还强调了 Buffers 的合并在 MTDA 中的重要性,因为 Buffers 是捕获各个域独特特征的关键。我们所提出的模型融合方法简单而高效,在 MTDA 基准上取得了最好的评测性能。我们期待本文所提出的模型融合方法能够激发未来更多关于这个领域的探索。
#GaussianBEV
首次将Gaussian引入BEV感知领域!
BEV感知又要进化了!今天看到了一篇BEV感知结合3D Gaussian实现BEV分割的任务,很赞!!!性能暂时算不上惊艳,但范式上有很大的参考性,分割任务上是可行的,OCC、检测等任务也可以考虑!
BEV感知已经广泛用于环视3D感知。它允许将不同相机的特征合并到一个空间中,提供3D场景的统一表示。其核心是view transformer,将图像视图转换为BEV。然而基于几何或cross-att的view transformer方法并不能提供足够详细的场景表示,因为它们使用的3D空间的子采样对于建模环境的精细结构来说是不足的。于是本文提出了GaussianBEV,这是一种将图像特征转换为BEV的新方法,通过使用一组在3D空间中定位和定向的3D高斯来精细地表示场景。然后通过调整基于高斯splatting的3D表示渲染,以生成BEV特征图。GaussianBEV是第一种在线使用这种3D高斯建模和3D场景渲染过程的方法,即不在特定场景上对其进行优化,而是直接集成到单阶段模型中以用于BEV场景理解。实验表明,所提出的表示方法非常有效,将高斯BEV作为nuScenes数据集上BEV语义分割任务的最新技术。
总结来说,GaussianBEV主要贡献如下:
- GaussianBEV利用3D高斯表示从图像生成BEV特征图,从而实现精细的3D场景建模。然后使用栅格化模块在BEV中splatting此表示。据我们所知,这是第一次提出非场景特定的高斯splatting表示并将其集成到感知模型中。
- 验证明了我们的方法的有效性,使其成为BEV语义分割的最新技术。
相关工作回顾
基于深度。基于像素深度估计和图像特征的显式预测,建立了一系列模型。结合相机标定参数,这使得2D特征能够反投影到3D特征点云中,最终在BEV网格中聚合。为了适应深度估计的不确定性,特征实际上沿着穿过其像素的光线传播,并由离散的深度概率估计进行微调。为了改进深度预测,提出了一种在模型训练期间使用LiDAR数据的显式深度监督方案。然而,基于深度的方法对光线采样策略很敏感,通常是沿着光线和物体表面反向投影特征(见图1a)。
基于投影。通过严格的比较研究,[7]建议放弃深度估计,转而采用更简单的投影方案:使用一组预定义的3D点来描述场景,并通过使用校准数据将点投影到相机特征图上来探测相机特征。此投影忽略了实际对象和背景放置,但返回了场景的更密集表示,没有超出对象表面深度的空隙。通过选择稀疏网格表示来减少生成BEV网格的计算和内存开销。基于投影的视图变换方法很简单,但会产生粗略的BEV表示,因为沿着光线的所有体素都接收到相同的特征(见图1b)。
基于注意力。利用Transformer模型的最新进展,深度估计被基于注意力的特征调制方案所取代。提出了几种优化方案来解决图像和BEV网格标记之间成对匹配的计算复杂性:空间和时间注意力的因子分解、可变形注意力、标定和时间戳先验的引入。对于分割任务,由于需要定义密集的查询映射,基于注意力的视图转换在计算和内存方面都是密集的。这就是为什么一些方法预测低分辨率BEV(见图1c),然后通过逆卷积对其进行上采样。
高斯splatting。高斯splatting(GS)是一种3D场景渲染技术,它使用3D高斯来描述场景。每个高斯函数都由其位置、比例、旋转、不透明度和球谐颜色模型参数化。整个渲染管道是差分的,允许基于一组图像将高斯参数优化到特定场景。GS既快速又并行,允许在GPU上进行实时操作。此外,通过修剪更窄、更透明的高斯分布,可以在细节和渲染速度之间进行权衡。与稀疏体素网格相比,高斯网格提供了更有效的场景表示,因为单个高斯网格可以描述大体积,而较小的高斯网格可以以任意分辨率精确编码更精细的细节。细节和光栅化分辨率是渲染管道的参数,而不是场景描述。已经提出了几个扩展,允许管理动态对象或从表示中的基础模型中提取语义特征。在所有情况下,高斯表示都是特定于场景的。
在我们的工作中,我们建议使用高斯表示来克服以前视图变换方法的缺点。与之前离线学习高斯表示的高斯电高斯splatting不同,我们建议学习一个能够提供场景在线高斯表示的神经网络。
详解GaussianBEV
整体结构如图2所示:
3D Gaussian generator
给定输入特征图F,3D高斯生成器使用多个预测头预测场景的3D高斯表示。图3说明了它如何在特征图上运行。
高斯中心。场景中高斯分布的3D位置由应用于F的深度头和3D偏移头估计。第一种方法预测3D中心沿光线的初始位置。第二种方法通过向其添加一个小的3D位移来细化这个3D位置,通过不沿光线冻结高斯分布,为高斯分布的定位提供了更大的灵活性。
更确切地说,对于坐标为($u_{n,i}$,$v_{n,i}$)的相机n的特征图中的像素i,深度头预测视差$d_{n,i}$∈[0,1]。为了补偿从一个相机到另一个相机的焦距多样性对深度预测的影响,如[23]中提出的,在参考焦距f中,视差被预测到一个缩放因子。知道与相机n相关的真实焦距fn,然后对度量深度$z_{n,i}$进行如下解码:
![]()
然后使用第n个相机的内参Kn推导出相机参考系中的相应3D点:

产生的3D点被约束为沿着穿过所考虑像素的光线。由于这种约束,它们的定位不一定是最优的。为了克服这个问题,我们建议使用3D偏移预测头。它的目的是提供一个小的位移$△_{n,i}$,应用于高斯的3D中心,以细化其在所有三个方向上的位置。通过以下步骤可以简单地获得精确的3D点:
![]()
在这个阶段,为每个相机计算的3D高斯中心在相应的相机参考系中表示。为了在世界参考系中表达这些点,应用了外参矩阵[Rn|tn],实现相机到世界的转换:
![]()
高斯旋转。场景中高斯分布的3D旋转是通过应用于F的旋转头来估计的。对于相机n的特征图中的给定像素,它以单位四元数q的形式输出偏心旋转。像素的偏心旋转对应于相对于穿过它的3D光线的旋转。这种建模使旋转头更容易学习,因为它不知道与它正在处理的像素对应的光线。例如,放置在场景中两个不同位置并在相机参考系中具有不同绝对(自中心)旋转的两个对象在图像中可能具有相同的外观。在这种情况下,旋转头预测的偏心旋转将是相同的。然后,使用相机的固有参数来检索自中心旋转信息。
为此,计算表示穿过相机n的像素i的光线与轴$[0,0,1]^T$之间的旋转的四元数。然后通过以下步骤恢复表示相机参考系中的自中心旋转的四元数:
![]()
最后,对于高斯中心,使用$q^w_{n,i}$计算表示高斯在世界参考系中的旋转的四元数,该四元数对相机n的相机到世界的旋转进行建模:
![]()
高斯尺寸、不透明度和特征。最后三个高斯参数不依赖于光学特性和相机定位,而是编码语义特性。因此,简单地使用三个头来预测BEV光栅化器模块渲染高斯集G所需的集S、O和E。
BEV rasterizer
BEV光栅化器模块用于从3D高斯生成器预测的高斯集G中获得BEV特征图B。为此,高斯高斯splatting中提出的差分光栅化过程已被调整为执行这种渲染。第一种调整已经在其他离线语义重建工作中提出,包括渲染C维特征而不是颜色。在我们的例子中,这会产生一个包含感知任务所必需的语义特征的渲染。第二个调整涉及所使用的投影类型。我们对渲染算法进行了参数化,以生成正交渲染而不是透视渲染,更适合场景的BEV表示。
GaussianBEV training
![]()
高斯正则化损失。尽管高斯BEV可以通过上述损失进行有效训练,但直接作用于高斯表示的正则化函数的添加提高了其代表性。特别是,在训练过程中增加了两个正则化损失。
首先,深度损失旨在使用激光雷达在图像中的投影提供的深度信息来规范高斯人的位置。这种损失增加了对深度水头预测的约束,以获得初始3D位置,然后通过3D偏移对其进行细化。深度损失Ldepth定义如下:
![]()
其次,早期监督损失旨在优化BEV骨干之前的高斯表示。其想法是限制BEV特征,以直接为语义分割任务提供所有必要的信息。在实践中,分割头被添加并直接连接到BEV光栅化器模块的输出。早期监督损失的定义与Lsem类似。因此,总损失函数由下式定义:
![]()
实验结果结论
本文介绍了GaussianBEV,这是一种新的图像到BEV变换方法,是BEV语义分割的最新进展。基于在线3D高斯生成器,它将图像特征图的每个像素转换为语义化的3D高斯。然后,高斯人被泼洒以获得BEV特征图。我们已经证明,高斯表示能够适应场景中存在的不同几何结构,从而实现精细的3D建模。我们希望这项初步工作将为使用在线高斯splatting表示的3D感知的进一步研究打开大门。
#Snail-Radar
专为4D Radar slam设计!
大规模4D radar数据集
近年来,毫米波雷达因其在恶劣条件下的鲁棒性而被用于里程计和建图。常用的雷达类型有两种:
- 扫描雷达,它们通过旋转捕获360°视野的扫描
- 固态单芯片雷达,通常具有大约120°的水平视野。
单芯片雷达频率更高且不如扫描雷达笨重。通过多普勒速度,单芯片雷达可以轻松检测移动物体,从而解决基于摄像头或激光雷达里程计方法中遇到的重要挑战。然而,传统汽车雷达的垂直分辨率较差,导致低高物体在同一视野中的混淆。
近期的单芯片4D成像雷达进展,使得垂直分辨率提高,能精确测量高度,同时具备距离、方位角和多普勒速度(因此称为4D)。利用毫米波,4D雷达能轻松区分移动物体,并在雾、雨和雪等恶劣条件下正常感知。这些特性使4D雷达对需要在动态和恶劣环境中可靠运行的自主系统(如机器人和汽车)具有吸引力。
现有的公共4D雷达数据集在参考轨迹的准确性、数据采集平台的多样性、地理范围以及同一路线的数据采集重复性等方面常常有所欠缺。
武汉大学SNAIL小组从2022年8月开始的数据采集计划的精心制作的数据集Snail-Radar[1]。该数据集包含了在一年内使用手持设备、电动自行车和SUV等多种平台采集的各种数据序列。虽然每个平台的传感器配置略有不同,但每个传感器架通常包括立体摄像头、一到两个4D雷达、一个3D激光雷达、一到两个IMU和一个GNSS/INS系统。发布的序列数据覆盖了从密集植被的大学校园到高速公路隧道等多种环境,在晴天或雨天和夜间进行采集。
考虑到在同步定位与地图构建(SLAM)中的应用,我们提供了使用地面激光扫描仪(TLS)数据生成的参考轨迹。基于已验证的技术进行同步和精心校准,确保了我们数据的可靠性。我们相信这一数据集将大大有助于评估基于4D雷达点云的里程计、建图和位置识别算法。数据集和配套工具可在我们的网站上获取。
- 数据集链接:https://snail-radar.github.io/
- 数据集工具:https://github.com/snail-radar/dataset_tools
该数据集的贡献总结如下:
- 发布了一个大规模多样化的4D雷达数据集,覆盖多种环境条件下由三种不同平台在选定路线多次采集的数据,包括雨天和夜晚、校园道路和高速公路。提供了数据在ROS包和文件夹格式之间转换的工具及校准结果。
- 提出了严格的程序,同步所有传感器的运动相关信息,并校准它们之间的外部参数。同步程序从激光雷达和GNSS的硬件同步开始,然后所有传感器时间映射到GNSS时间,以激光雷达时间为桥梁,最后估计所有运动相关信息类型之间的恒定时间偏差。外部参数通过手动测量初始化并通过相关方法优化。
- 提出了一个定位流水线,用于生成提供序列的参考位姿。流水线从使用TLS捕获测试区域的点云开始,这些拼接的点云在定位模式下被用作LIO方法中的子地图。为了便于在序列末尾生成参考位姿,还提出了一种反向处理激光雷达里程计信息的方法。
雷达信号处理背景
如图1顶部所示,发射天线发送频率递增的射频信号。接收天线检测由物体反射的波,并通过将信号与发射载波混频来获得中频信号。这些信号然后通过模数转换器(ADC)采样,得到复数(同相和正交分量,I/Q)ADC样本。这些ADC样本被传送到数字信号处理器(DSP)进行进一步处理。
数字信号处理,如图1底部所示,包括四个基本组件:距离处理、多普勒处理、恒虚警率(CFAR)检测和2D到达角(AoA)处理。每个组件在TI mmwave SDK文档中有详细说明。这些组件的数学原理在Iovescu和Rao(2017)中解释。这里我们提供这些组件的功能性高层描述,并省略了高级选项以便清晰。
以下是一些符号表示:
- :每帧的多普勒脉冲数
- :接收天线数
- $N_{T_x}:发射天线数
- :每脉冲的ADC样本数
- $N_{D_b}:快速傅里叶变换(FFT)中的多普勒频谱数
- :FFT中的距离频谱数
距离处理过程以ADC脉冲样本I/Q值为输入,在活动帧时间内执行1D距离FFT和可选的直流距离校准,输出一个雷达立方体。ADC数据的大小为 · · · 。雷达立方体的大小为 · · · 。
多普勒处理过程以先前的雷达立方体为输入,在帧间时间内执行2D多普勒FFT和能量求和,输出一个大小为 · 的检测矩阵。
CFAR过程从检测矩阵开始,执行CFAR检测和峰值分组,输出范围-多普勒域中的CFAR检测列表。
2D AoA处理过程以雷达立方体和CFAR检测列表为输入,对检测到的物体的相关条目进行2D多普勒FFT,随后进行2D角度FFT和CFAR选择峰值,以确定检测物体的方位角和仰角,生成具有1D多普勒速度的3D点云。
图1描述了典型的德州仪器(TI)4D雷达的工作原理(Iovescu和Rao,2017)。发射天线发射的射频信号被物体反射,并由接收天线接收。信号被下变频为中频信号,通过模数转换器(ADC)进行采样,得到复数(同相和正交分量,I/Q)ADC样本。这些样本被传送到数字信号处理器(DSP)进行进一步处理。
数字信号处理过程包括距离处理、多普勒处理、恒虚警率(CFAR)检测和2D到达角(AoA)处理。每个步骤的详细说明可以在TI mmwave SDK文档中找到。这些组件的数学原理在Iovescu和Rao(2017)中解释。
距离处理过程包括对ADC样本进行1D距离FFT变换,并在活动帧时间内进行可选的直流距离校准,最终生成一个雷达立方体。多普勒处理过程则是在帧间时间内对雷达立方体进行2D多普勒FFT变换和能量求和,生成检测矩阵。CFAR过程基于检测矩阵进行CFAR检测和峰值分组,生成CFAR检测列表。最后,2D AoA处理过程对CFAR检测列表中的相关条目进行2D多普勒FFT和2D角度FFT,确定检测物体的方位角和仰角,生成3D点云。
数据集
传感器设置
数据集使用了三个平台:手持设备、电动自行车和SUV。这些平台的传感器配置几乎相同,包括一个Hesai Pandar XT32激光雷达、一个Oculii Eagle雷达、一个ZED2i立体摄像头和一个Bynav X36D GNSS/INS系统。电动自行车和SUV还配备了Continental ARS548雷达和XSens MTi3DK IMU。数据通过一台运行Ubuntu 20.04的ThinkPad P53笔记本实时预处理和记录。
文件格式
每个序列的数据以一个整体的rosbag文件和一个包含单独消息的文件夹形式提供。传感器数据类型包括点云、图像、IMU数据和GNSS/INS解决方案。文件夹内的点云数据以pcd文件保存,压缩图像以jpg格式保存,其他类型数据以txt文件保存。
数据集提供了每个序列的参考轨迹,这些轨迹是在TLS地图帧中以10Hz生成的。然而,对于大规模的SUV序列,仅提供起始子序列和结束子序列的参考位姿,这些子序列在TLS覆盖范围内。所有TLS点云及其优化后的位姿也提供在数据集中。数据还包括实时GNSS/INS解决方案及其相应的UTM50N坐标转换结果。
Ground truth
在数据集中,Bynav GNSS RTK/INS系统的解决方案在高度上经常会出现跳跃现象,误差可达几米。因此,我们使用精确的地面激光扫描仪(TLS)点云来生成参考位姿,类似于Ramezani等(2020)的方法,但我们采用的是逐帧对齐未失真的激光雷达帧到TLS地图。
TLS扫描使用Leica RTC360扫描仪在晴天捕获,覆盖了“星湖”和“星湖塔”路线。这些扫描首先通过Cyclone Register 360程序处理,并在Open3D中进一步通过点到平面ICP进行优化。最终的TLS地图由93个扫描拼接而成,期望精度在5厘米以内。
对于完全覆盖在TLS地图内的序列,我们通过两步法将激光雷达扫描相对于TLS地图进行定位:首先获取初始位姿,然后在定位模式下运行LIO方法。对于大型序列,由于TLS地图仅覆盖序列的开始和结束部分,我们仅生成起始和结束子序列的参考轨迹。为了实现反向LIO处理,我们提出了数据反向技术,通过时间反转处理序列信息,从而在序列末端生成参考位姿。
反向处理还提供了一种验证参考精度的方法,通过比较前向和反向处理结果,我们确认参考位置的精度通常在10厘米以内。这一技术保证了数据集的高参考精度,有助于评估和开发基于4D雷达的SLAM算法。
同步
由于在硬件上同步所有传感器具有挑战性,我们提出了一种方案,确保所有传感器消息由同一个虚拟时钟标记。该方案首先使用激光雷达数据作为桥梁,将所有传感器消息的时间戳映射到GNSS时间,以消除抖动和长期漂移。然后,使用里程计和相关算法估算传感器数据与GNSS/INS解决方案之间的恒定时间偏差:
- 激光雷达同步:对所有传感器消息的主机时间进行平滑处理,以消除传输抖动。XT32激光雷达通过GNSS时间同步,因此可以通过主机时间将所有消息时间戳映射到GNSS时间。
- 时间偏差估算:使用相关算法估算不同传感器消息流之间的恒定时间偏差。对于激光雷达数据,使用KISS-ICP方法计算3D激光雷达位姿,并通过中心差分法计算INS位姿和LO位姿之间的角速度,从而确定时间偏差。对于4D雷达,通过GNC方法估算其自我速度,并与INS解进行比较来确定时间偏差。对于IMU,直接计算IMU数据的角速度,并与INS解进行比较来确定时间偏差。
- ZED2i同步:使用Swift-VIO方法估算ZED2i IMU和摄像头之间的时间偏差。虽然在挑战性序列中Swift-VIO的轨迹可能会漂移,但时间偏差通常能迅速稳定下来,精度在1ms以内。
整体同步精度预计在10ms以内,这得益于GNSS/INS解的高频率(100Hz)和相关算法的精细优化,以及ZED2i曝光时间的合理设置(不超过5ms)。
最终,发布的数据集中的所有消息时间戳都已经补偿了与GNSS时间的时间偏差,确保了数据的高精度同步。
传感器刚体标定
为了确保数据集的准确性,定义了基于激光雷达(XT32)的机体坐标系,其x轴指向前方,y轴指向左侧,z轴指向上方。所有传感器的外参相对于机体坐标系进行标定。
初始标定
- 传感器的相对位置通过手动测量获得。
- 相对方向通过CAD图纸确定。
精细标定
- 使用激光雷达IMU校准工具对ZED2i IMU或MTi3DK与XT32激光雷达之间的外部参数进行优化。
- 通过Swift-VIO方法获取ZED2i摄像头和IMU的时间偏差及其外部参数。
- 使用相关算法对Bynav系统的激光雷达与IMU之间的相对方向进行校准。
- 使用相关算法对Oculii Eagle和ARS548雷达与X36D IMU之间的相对方向进行优化。
每个传感器的外部参数都经过多种方法优化,并提供在数据集中,以确保传感器数据的准确性和一致性。
总结一下
Snail-Radar是一个大规模的4D雷达数据集,专为基于多传感器融合的定位和建图应用而设计。该数据集使用三种平台在各种环境条件下进行采集,包括雨天、夜晚、校园道路和隧道,共采集了44个序列,遍布八条路线的多次重复采集。
参考位置(对于大规模序列仅在开始和结束部分)是使用LIO方法生成的,该方法依次将去失真的Hesai激光雷达帧定位到TLS地图上。数据反向处理技术实现了时间上的反向LIO。传感器数据通过两步方案同步:
- 首先使用硬件同步的激光雷达数据将消息主机时间映射到GNSS时间,以消除抖动和长期漂移
- 使用里程计和相关算法估算传感器数据与GNSS/INS解之间的恒定时间偏差。
所有传感器之间的外部参数通过多种方法进行优化,并随数据集一同提供。
#天天说的48V汽车系统,到底是个啥?
这几年,越来越多汽车OEM和Tier1推出12V/48V双电池汽车系统设计的轻混合动力汽车 (MHEV)及方案 ,而自从特斯拉高调宣布,Cybertruck和特斯拉将来推出的所有平台都将采用48V,更是为48V系统“添了一把柴”,12V退出历史舞台的脚步加快了。
第一部分:为什么是48V?
如今,12V已面临过多限制,许多汽车OEM都将48V视作最为合理的发展目标,因为这一电压能够达成一种理想的平衡。
一是功率损耗更低,效率更高,提高能源利用率,有利于简化汽车组件散热设计,降低成本。根据欧姆定律P=I²R,理论上,在48V架构中,由于电流是12V架构的四分之一,所以电力传输系统中电阻导致的各种功率损耗都可以降低到原来的十六分之一。
二是产品/线束更轻,成本降低,并且有利于整车减重,提高电车续航。根据电功率公式P=V·I和 PLOSS = I2R,电压加倍意味着设备可以用一半的电流获得相同的功率,电流降低意味着可以使用规模更小的导线、端子和连接器,这些因素都能减轻重量并降低成本。
三是48V远低于60V这一防范电击危险所要求公认限值,48V电池的充电电压最高56V,已经很接近60V,即48V电池电压是安全电压下的最高电压等级了。
四是48V电网还能在车联网 (V2X) 和 ADAS 方面使系统为未来应用做好准备(负载点控制)。

48V系统由BSG(发动机皮带驱动的电机)+48V 电池+DC/DC三大部分组成。值得注意的是,48V轻混系统并不是完全替代了传统的12V电气系统,而是保留了此前的 12V系统,这样可以最大程度的兼容原有系统,节约大量的研发成本。48V系统对工作温度和软件的匹配标定等方面都有着较为苛刻的要求。

第二部分:48V系统设计难题
既然48V这么万能,为什么汽车行业切换起来这么费劲?实际上,这会牵扯到许多设计方面的问题。同时,48V系统对工作温度和软件的匹配标定等方面都有着较为苛刻的要求。
电弧防护
电弧风险受电压水平及端子间距影响,温度可达2800~19000°C。12V电路中,电弧一般会快速熄灭,但在48V下,电弧可能持续,损坏端子和连接器。
目前尚不确定,用于48V系统的12V刀片式保险丝能否提供足够的电弧防护。而且,由于48V系统所需的继电器触点距离将大于12V系统所需的,因此需要重新设计保险丝和继电器。由于这些组件的要求都可通过采用半导体器件轻松满足,所以这些问题很可能通过电子方案来解决。也就是说,更多eFuse方案会被采纳。
电压架构不断发生变化
目前很难跨越到全48V系统,因此市面大部分方案并没有完全替代传统12V电气系统,而是保留了此前的12V系统,这样可以最大程度的兼容原有系统,节约大量的研发成本,所以设备很有可能是12V系统和48V系统并存,因此整个的电源架构可能在未来每个时期都会有所不同。

EMI要求更高了
在48V下,尽管输出功率相同,但较低负载电流减少了传导(差分)发射,因此开关波形(EMI 的第二主要来源)成了关注重点。较大的开关波形振幅会增加EMI,开关节点的噪声辐射也会因大面积铜区(如电感器)而加剧,尤其在48V输入电压下更为明显。
因此,在选择48V应用的电源稳压器时,必须评估高输入电压对EMI的影响,并选用具有 EMI缓解功能的稳压器,以降低额外的噪声。即便使用低噪声稳压器,设计时仍需遵循低噪声PCB布局原则,选用合适的EMC元件,并以系统化的方法进行设计。设计低噪声电源转换器的最佳步骤是先参考数据表和评估板示例进行仿真。

具有相同负载条件的24V和48V输入的LM5164-Q1 EMI性能,图源|TI
BMS控制更谨慎了
48V电池系统由锂离子电池构成,相较于铅酸电池,需要更多注意和处理。鉴于此,48V汽车需要电池管理系统(BMS)负责监控电池电压和电池温度,以便能够安全地为电池充电。由于48V系统具有再生能力,这种情况也变得更为复杂。当汽车电池的剩余电量足够低时,可发出再生指令,但是对BMS的控制需要非常谨慎,这对于防止过充或过热至关重要。
端子接触及锁定
避免使用有间歇接触或微动腐蚀的端子,否则会形成微电弧,损坏端子材料,增大电阻。采用有效的端子二次锁定,防止端子退出(TPO)导致间歇性断电及电弧形成。维修48V连接器前,务必断电,以免断开时形成高温电弧。
爬电距离和电气间隙
爬电距离是沿绝缘材料表面的最短距离,电气间隙是导体间空气中的最短距离。使用IEC 60664-1规范确定爬电距离和电气间隙。传统汽车连接器大多满足电气间隙要求,但部分需设计调整以满足爬电距离。

爬电距离和电气间隙,图源|APTIV
电压隔离
在混合电压系统中,需避免电流从48V流向12V,因此最佳方式是隔离不同电压的电路,或在连接器内进行物理分区。同时在布线时,尽量分开布置48V和12V电路,并为易受损部位的48V电线提供额外保护。避免使用相同的接地螺栓,以防电流通过共享连接跨电压流动。
密封要求
48V连接器意外接触到盐水等电解液,产生的电化学腐蚀反应对端子的侵蚀比12V情况下更严重,所以必须保持密封足够严密。
配套产业链都要更换
从12V提高到48V后, 零部件、接插件、开关等的耐压要提高;为了兼容12V的硬件,还需增加48V转12V的直流变压器;由于电压升高了,触点更容易产生电弧,所以采通常需要采用电子继电器来代替传统的电磁继电器或者电子保险丝;甚至为了安全着想,48V连接器也通常采纳浅蓝色的颜色编码,提示人们注意穿戴个人防护装备。
第三部分:48V设计架构上的变化
特斯拉是坚定的“48V爱好者”。特斯拉不仅表示,其CyberTruck采用全48V方案,同时将进行一系列设计修改,在几款现有车型中停用12V母线,已经组建了自己的“秘密”附件团队,专门开发面向48V架构的产品,如照明、绞盘和空气压缩机。

不过,经过拆解分析,CyberTruck将48V的连接器和包装设计成了蓝色,较好地与高压的橙色进行了区分,同时目前CyberTruck的设计与特斯拉所说有些出入,并不是所有的低压设计都采用了48V,依然保留了12V的设计。
所以,目前市场还没有真正意义上的全48V汽车系统,只是向48V系统的渐进式过渡,并且预期10到15 年许多车辆将继续使用现有的12V附件和子系统。

目前,使用比较多的48V电气系统的简化图如下图所示。由两个电源总线、一个12V电池和总线组成,用于为大多数传统汽车负载供电;一个48V电池和总线,用于为电动驱动电机和其他高功率附件供电。12V系统运行所有常规设备,包括信息娱乐系统、照明和车身电气附件,如车窗、车门、座椅等。48V系统运行电动驱动电机和任何重型负载,如 HVAC、选定的泵、转向和悬架系统,如果 ICE 使用电动涡轮增压器,则使用电动涡轮增压器。
两个主要电气系统连接到双向升降压DC/DC转换器,该转换器为12V和48V总线提供服务,以及一个用于操作三相同步感应驱动电机的逆变器。一些S/G是皮带驱动的,而其他制造商则将S/G放置在发动机和变速箱之间。

还有一些比较实际方法是实施一种分布式电源传输架构,比如Vicor开发的分布式系统。这种系统中,车辆的48V电源来自主要400/800V电池,然后发送到靠近负载点的12V电源转换器。通过使用两个或更多独立、隔离的电压转换器供电,可以为制动、转向和其他ASIL D安全关键功能提供冗余电源。

此外,Vicor还展示过一个很具有前瞻性方案。当前,汽车E/E架构从域控制Domian过渡到区域控制Zonal是主流,Vicor则将48V和Zonal结合在一起。
从下图来看,包含12V和48V负载,整车低压负载通过48V传输,12V电气负载通过48V进行转换。区域E/E架构配备了高性能计算单元,并通过CAN总线和汽车以太网连接,实现了更高效的负载管理和电源分配。48V PDN通过集成充电器和48V电源传递网络到电池包中,解决了400V/800V充电基础设施之间不兼容性问题。这种集成不仅减少了热量、成本和重量,还提高了系统的整体效率。

写在最后
目前,48V技术的应用还较为有限。48V系统面世已有几年,主要为轻度混合动力汽车的起动机-发电机及大功率配件(如主动悬挂和动力转向)提供动力。正如特斯拉在演示中所述,电压越高,电流越小,需要的电线也越细,从而减轻重量并节省成本。
引入48V轻度混合动力系统后,设计完成的优势显著。然而,改变传统12V供电网络(PDN)的犹豫依然存在,因为转换过程可能涉及大量测试,还可能需要符合汽车产业高安全性和高质量标准的新供应商。数据中心行业在转向48V PDN的过程中发现,这一变革的优势远远超过了转换成本。同样,对于汽车行业而言,48V轻度混合动力系统为快速推出排放更低、油耗更低、行驶里程更远的全新车辆提供了新途径。此外,它为提升性能并减少二氧化碳排放带来了全新设计选择。
那么,48V电机驱动能否彻底取代12V电机驱动?答案是否定的。TI的Karl-Heinz Steinmetz曾向EEWorld表示,高端汽车制造商全面转向48V系统可能仍需10至15年,未来一段时间内12V/48V双动力结构将会继续存在。
参考文献
[1]ONsemi:https://www.onsemi.jp/site/pdf/ONSAR2893_Automotive_Manufacturin_Design_for_China_ONSAR2893.pdf
[2]Vicor:https://www.vicorpower.com/documents/whitepapers/wp-solving-auto-electrification-challenges_CN.pdf
#STR2
nuPlan又一SOTA!赵行团队新作STR2:运动规划的重新出发,仿真闭环的强大泛化!
论文链接:https://arxiv.org/pdf/2410.15774项目网页:https://tsinghua-mars-lab.github.io/StateTransformer/代码开源:https://github.com/Tsinghua-MARS-Lab/StateTransformer
以下视频来源于
卷不赢躺不平摆不烂
,时长02:59
主要内容:
大型实际驾驶数据集推动了有关自动驾驶数据驱动运动规划器的各个方面的研究,包括数据增强、模型架构、奖励设计、训练策略和规划器架构。在处理复杂和少样本情况下,这些方法有较好的表现。但是由于设计过于复杂或训练范式的问题,这些方法在规划性能上的泛化能力有限。在本文中,我们回顾并比较了以前的方法,重点关注泛化能力。实验结果显示,随着模型的适当扩展,许多设计元素变得冗余。我们介绍了StateTransformer-2 (STR2),这是一种可扩展的、仅使用解码器的运动规划器,它结合了Vision Transformer (ViT) 编码器和混合专家(MoE) 的Transformer架构。MoE骨干通过训练期间的专家路由解决了模态崩溃和奖励平衡问题。在NuPlan数据集上的大量实验表明,我们的方法在不同测试集和闭环模拟中比以前的方法具有更好的泛化能力。此外,我们评估了其在真实城市驾驶场景中的可扩展性,显示出随着数据和模型规模的增长其一致的准确性提升。

下面我们详细解释STR2的模型设计。我们选择的不是向量化的输入,而是栅格化图片的输入,可以方便进行规模化训练。输入还加入了聚类的轨迹作为引导线,结果可以看到在大曲率的场景表现会更合理一些。输入经过一个使用MoE架构增强的Transformer模型,自回归的方式输出引导线类别,关键点以及轨迹。
ViT编码器。我们采用仅解码的ViT图像编码器,以实现更好的可扩展性和性能,它由堆叠的12层Transformer组成。栅格化的图像被切分成16个小块。我们选择GeLU作为ViT编码器的激活函数。
Mixture-of-Expert。语言建模任务要求模型从复杂且通常具有统计争议的专家数据奖励中学习和实现平衡。受MoE模型在语言建模任务上泛化结果的启发,我们将GPT-2骨干网络替换为MoE骨干网络用于序列建模。MoE层通过专用内核和专家并行(EP)提供了更好的内存效率。我们还利用了Flash Attention2 和数据并行(DP)以提高训练效率。
自回归。在生成序列中我们添加了聚类轨迹作为嵌入特征用于模态分类,并使用交叉熵损失。我们使用K-Means聚类,从0.7百万个随机选择的动态可行轨迹中按其时空距离提取了512个候选轨迹。每条归一化的轨迹包括未来8秒的80个轨迹点(x, y和偏航角)。
liauto数据集上的规模化实验。我们采用了liauto数据集进行了scaling law的探索,liauto数据集是一个工业级的超大规模现实世界驾驶数据集。该数据集包括车道级导航地图和来自7个RGB摄像头、1个LiDAR和1个毫米波雷达(MMWR)的传感器设置的跟踪结果。我们选择了过去6个月内收集的城市驾驶场景,其中没有任何人工标注。我们筛选出错误的导航路线,因为这些路线与实际的未来驾驶轨迹不匹配。最终,我们将所有驾驶日志重新整理为长达10秒的训练和测试样本,其中包括过去的2秒和未来的8秒。最终的训练数据集拥有超过1b训练样本。实验结果(如图2)可以看到随着数据规模的增加以及模型参数的增加,test loss都有下降的趋势。均衡考虑训练成本和收益的关系,我们最后采用的为800m的模型。


从图3 nuplan闭环仿真的结果可以看到STR2取得了全面SOTA。结果来看专家轨迹的NR分数较高,R的分数却很低,说明专家轨迹没有一个适应环境变化的能力,仿真环境和实车有一定的区别。结果可以看出PDM-Hybrid相比于其他的方法的R得分明显高于NR,说明生成-评估的范式在模型泛化性能上表现优异。我们借鉴了PDM的生成-评估范式,基于STR2模型的输出结果进行了候选轨迹生成,再经过PDM打分器输出得分最高的轨迹。

图4可视化结果可以看出PDM-Hybrid轨迹因为基于当前车道中心线,没有主动变道和绕障的能力,我们的模型由于泛化性能强,所以很多场景下表现比PDM-Hybrid合理很多。本工作在nuplan testhard 数据集上的实验结果证明了生成-评估范式的合理性。对于生成-评估范式,在后续工作中我们还可以有更多尝试,例如如何在模型层面输出更合理的候选轨迹,如何将未来的不确定性考虑进打分器中,同时可以考虑将本文的方法作为真值标注的一种方式,帮助模型朝着更合理的方向迭代。为了感受模型的泛化性能我们将nuplan数据训练得到的模型直接应用于liauto数据集上推理,结果表现良好,对于动态障碍物的避让交互等都有合理的输出。
#自动驾驶公司扎堆IPO,回报投资人的时候到了
几乎是前后脚,自动驾驶公司地平线和文远知行成功上市。
与此同时,还有一大批公司正在路上,Momenta和小马智行选择赴美上市,纵目科技、佑驾创新则在冲刺港交所……
除此之外,今年1月和8月,激光雷达企业速腾聚创、自动驾驶芯片公司黑芝麻智能也都成功登陆港交所。
自动驾驶企业扎堆寻求上市的背后,除了对资金的需求,更多的还有兑现对投资人的承诺。
“目前这些上市的企业,我感觉有一些是为了上而上,它不是真的业务基本面达到要求了。”有资深投资人对《赛博汽车》表示,“对很多基本面不好的企业来说,投资协议一般都有上市期限的对赌,理论上也可以延长,但是如果上市,这些对赌协议就全作废了,不用再背这个包袱。”
上述人士指出,这些企业上市只是技术性的问题,即只要满足交易所的要求就可以,比如说美股或者港股,都是自由市场。要发行成功,首先合规满足要求,其次要有人能够认购它的股权,这两个条件实现就可以。
说起来容易,但落地并不简单。一方面,无论是港股还是美股都会面临很多的流程审核;另一方面,提前找到上市的基石投资者更是不易。
显然,自动驾驶企业扎堆上市的背后,并非是一片繁花似锦,还有压力和窘迫。
01
兑现承诺,上市是最体面的方式
为什么要上市?
兑现承诺是很重要的原因,到给投资人回报的时候了。
有投资人告诉《赛博汽车》,一般来说,国内一级市场的人民币基金,存续期在7年左右,其中5年投资期,2年时间是资本退出变现。
退出变现有几大途径,包括IPO(基石基金在解禁后卖出)、并购、新三板挂牌、股份转让、回购、借壳上市、清算等等。其中IPO是资本最理想和体面的退出方式。

10月24日地平线正式登陆港股
而细数这一批寻求上市的自动驾驶公司,多在2016年左右成立。其中,地平线成立于2015年7月;小马智行、Momenta均创办于2016年;文远知行(前身景驰科技)成立于2017年;纵目科技和佑驾创新则分别成立于2013年2014年。
在自动驾驶故事最受追捧的那些年,他们或多或少都拿到了资本的加持。甚至,不乏达到独角兽级别估值。
当时拿的钱越多,如今上市的压力就越大。
国内的股权投资,很多时候都会有投资方与创始团队的对赌协议出现,即在公司没有达成一些条款时(比如上市),公司包括创始团队需要掏钱从投资人那里回购股份。
业内人士坦言,现在投资人也挺难的,从大多数公司的实际经营情况来看,不管是创始团队还是企业本身持有的资金,回购股份的难度是很高的。
如果无法完成回购,其他路径又无法行得通,剩下的或许就是一个个创始团队与资方对簿公堂,公司清算,甚至创始人被成“老赖”这样令人唏嘘的故事。
这显然无论对于企业,还是投资人来说,都是是“双输的买卖”。
抽屉协议是私下签订的协议,通常只有协议双方知晓,类似于被放置在抽屉里,不轻易向外界透露
上市,显然是最体面的方式。“很多企业上市募集的资金,在上市前就已经谈好了,甚至很多想要上市的公司是有地方政府兜底的,与地方政府或一些战略方有‘抽屉协议’。”有资深投资人认为,一些公司是为了上而上,并非企业业务需求。
至于为什么多数选择港股和美股,主要是因为,美股或者港股都是自由市场。要发行成功只要实现两个条件,合规满足要求、有人能够认购股权。“企业本身业务好不好、持续性怎么样,这不是必然条件”。
有意思的是,自动驾驶“明星”公司似乎更偏爱美股,除了地平线或许因一些敏感问题选择了港股。小马智行、文远知行、Momenta都选择了美股。上述人士称,原因是美股更撑得住此前高额的估值。
02
普遍缺钱,上市迫在眉睫
上市也并非“百利而无一害”,企业也将面临信息公开,信息披露等成本。
正因为此波“上市潮”也让外界进一步了解智能驾驶、乃至自动驾驶企业的“窘迫面”:缺钱,这也是他们需要上市的另一个重要因素。
以10月28日,刚刚在中国证监会获得境外上市备案,拟在港股发行不超过1.38亿股境外上市普通股的佑驾创新(MINIEYE)为例,截止到去年年末,其账上的现金及现金等价物,仅剩不到2亿元,上市筹资迫在眉睫。

佑驾创新部分财务数据
而其他家账面数字稍好一些,比如文远知行账上有18.3亿元、小马智行有23.8亿元(3.35亿美元)、地平线甚至有现金及现金等价物113.6亿元,但结合他们亏损速度来看,如果再不融资、不上市,目前的资金仅能维持公司运转少则一两年,多则五六年。
以现金流情况最好的地平线为例,2021年到2023年,地平线净亏损分别为20.64亿元、87.2亿元以及67.39亿元。就算扣除与经营关系不大的项目后,经调整净亏损也达到11.03亿元、18.91亿元以及16.35亿元,三年经调整亏损超过46.29亿元。
而显然,一级市场这些企业已经很难再融到资。
根据企业披露信息来看,上述提及已经或正在上市的企业中,只有文远知行在今年6月获得了广汽集团一笔不超过2000万美元的战略投资;小马知行今年10月获得了广汽集团2700万美元的战略投资。两者还应该还都“沾了点IPO的光”。

而佑驾创新尽管显示2023年8月和11月都有融资到账,但属于Pre-IPO轮,也都受益于上市计划。
不考虑上市因素,文远知行最后一次融资发生在2022年10月,地平线也是;纵目科技的上一轮融资也在2022年3月;Momenta最新一次融资更是要追溯到2021年11月。
这背后的逻辑很好理解。
一方面,受经济大环境影响,国内资本市场活跃度远不如以前。据《赛博汽车》不完全统计,2021年在汽车智能化方向上,市场累计投融资总额达1591.9亿元,投资热点主要在整车、自动驾驶解决方案、芯片、激光雷达等领域,生长出一批“独角兽”企业,此后资本市场逐年降温,2023年头部自动驾驶公司中只有小马智行拿到了新的融资。
另一方面,投资“估值高的老人”不具性价比。有自动驾驶行业高管表示,自动驾驶领域,只要不是存在很严重路径依赖的情况下,大部分公司的技术差距可以在2-3年内,甚至更短时间完全拉平,而一些“老人”估值已经处于较高位置,在大环境不算好的当下,投一些“小而新”的企业似乎更有性价比。
与此同时,整个汽车产业越来越卷的情况下,作为上游的供应商们日子也不会好过,而且在面对车企的时候,大多数初创智驾公司没有太多的议价权,利润空间被极致压缩,想要走向盈利更是难上加难。
融资不顺畅、研发投入高、盈利遥遥无期,冲刺IPO,既有机会拿到战略融资;又能抛去一些包袱,再拿一笔钱,确实是不错的选择。
03
上岸不易,但现在是最好时间点
越来越多的智能(自动)驾驶公司选择上市。
他们如果去港股或者美股,理论上都是可行的。毕竟,理论上来说,只要满足交易所要求就可以了,即满足合规要求和有人认购股权。
但前者也会面临很多的流程审核。

10月25日文远知行在美股上市
比如文远知行,IPO就两度推迟。
2024年8月15日,路透社旗下IFR媒体发布消息称,文远知行将纳斯达克IPO定价由8月16日推迟至8月19-23日期间;8月22日,IFR又报道称,文远知行推迟纳斯达克IPO,没有新的时间表。
有资深投资人表示,文远知行第一次“失败”有可能就是被美国证监会针对了。
通过流程审核本身并不是一件很容易的事情,更难的是提前找到上市的投资方,在资本市场不算好的当下,想要有投资者认购,不仅要“流血”,还需要足够的诚意和信任。
地平线找到了阿里巴巴、百度、法国达飞集团CMA CGM和JSC(宁波甬宁高芯SP);文远知行找来了Alliance Ventures(雷诺日产三菱联盟的风险投资基金)、JSC International Investment Fund SPC、Get Ride、Beijing Minghong、Kechuangzhixing Holdings、Guangqizhixing Holdings and Gac Capital International、GZJK WENYUAN。
认购者,基本都是企业此前的投资人、“好伙伴”。
尽管困难不少,但当下依然是上市最好的时机。

10月底Waymo获新一轮56亿融资
“最好的上市时机是三年前,其次就是现在。”有自动驾驶从业者表示,一方面,萝卜快跑走红、Waymo获得大额融资、特斯拉发布Robotaxi车型,大众对自动驾驶的认知在不断加深;另一方面,美股降息之后,资本市场流动性也有所增强。
自动驾驶企业们经历过寒冬后,显然想抓住这一波“热浪”。
当然,就算已经上市也不等于一劳永逸,即使已经成功上岸的企业,股价也在遭遇不同程度的波动。
截至11月1日收盘,文远知行的股价报收14.52美元/股,已经低于IPO发行价15.50美元/股(即“破发”)。
但至少,文远知行已经“上岸”,更多的智能驾驶赛道玩家们,还在经历“生存大逃杀”。
#自动驾驶仿真超全综述:从仿真场景、系统到评价

▲ 一个自动驾驶仿真软件的运行可视化界面
什么是自动驾驶仿真?个人来下一个不成熟的定义,自动驾驶仿真是借助计算机虚拟技术对实际交通系统进行某种层次的抽象。
仿真的重要性已经不容置疑,自动驾驶想要大规模商业化落地,仿真是绕不过去的。为什么?因为自动驾驶的核心痛点之一就是成本,而仿真测试能把大量自动驾驶开发和测试的成本转化为GPU的物料成本和工程师的知识经验成本,进而大大缓解该痛点。
当前,几乎每家自动驾驶公司或涉及相应业务的公司都在进行仿真相关的工作。但同是仿真,不同公司的水平却参差不齐,不同工程师的仿真工程经验也有很大差异。如何才能搭建一个良性的高效的自动驾驶仿真体系?如何才能成为一名优秀的自动驾驶仿真工程师?这是公众号的未来讨论核心。
搭建自动驾驶仿真体系是一个下限很低,上限很高的事情。下载一个仿真软件,它可以是MATLAB,CarSim,也可以是CARLA、Lgsvl,或者是Prescan、VTD,通过文档学习一下仿真流程,就基本可以开始进行相关工作,这是大多数人对自动驾驶仿真的认识,也是这个细分领域门槛不高的佐证。但需要清楚的是,一个良性的自动驾驶仿真体系是一个标准的系统工程,它包括广义上的场景、系统以及评价三个主要模块,贯穿自动驾驶的开发、测试、落地以及运营等整个流程。有人说,需要让最熟悉自动驾驶系统的人来承担仿真相关工作,这个观点从某种程度上来说是正确的。
接下来就让我们按照这三个主要维度,来谈谈一个良性的自动驾驶仿真体系应该包括什么。
1、仿真场景
场景是仿真体系的开端,它在整个体系扮演着极其重要的角色,但其重要性相比于仿真系统却相对容易被忽略。而且随着仿真系统和评价体系的逐渐完善,越往后期,场景在整个体系中扮演的角色越重要。场景之所以有此地位,本质是因为其是对自动驾驶相关数据的一种价值提炼,是发挥数据价值的必须且高效的途径之一。基于场景的测试方法可以弥补基于里程的测试方法的局限性,在提高系统开发效率、产品落地效率方面都有重要作用。

以光照程度为自变量的场景
场景是公众号后期要讨论的核心内容之一,主要会围绕场景的形式和内容两方面展开。
1.1 场景形式
场景形式指的是场景数据的具体呈现方式。为什么要着重介绍场景的形式?核心在于三个字:标准化。标准化的场景体系的作用包括但不限于以下几点:
- 提高对原始数据的提取以及转化效率;
- 方便构建冗余度低的场景体系;
- 方便不同场景体系之间的比较以及场景交换;
- 减轻第三方测试时的多余工作。
目前相对比较通用的场景形式是由德国PEGASUS项目提出的功能场景-逻辑场景-具体场景三层体系。举个例子,功能场景可以描述为,“自车(被测车)在当前车道运行,在自车前方有前车加速运行,自车跟随前车行驶。” 逻辑场景则提炼出关键场景参数,并赋予场景参数特定的取值范围,如以上描述的场景可提取自车车速,前车车速以及加速度,自车与前车距离等参数,每个参数都有一定的取值范围和分布特性,参数之间可能还存在相关性。具体场景则需要选取特定的场景参数值,组成场景参数向量,并通过具体的场景语言表示。以上示例只是为了说明三层场景体系的内涵,具体的表述形式会有更多细节,需要有更多的标准和约束。

三层场景体系
具体场景需要转换为计算机可理解的语言即场景语言才能发挥作用。场景语言是一种可用以描述自动驾驶系统待处理的外部环境的计算机可解析的形式化语言。
场景语言的具体形式不一。针对功能场景、逻辑场景以及具体场景都有相应的场景语言:如针对前两者,有M-SDL等高级场景语言;针对后者有OpenSCENARIO、GeoScenario等。不同仿真软件支持的场景语言也不同:如CARLA和lgsvl等都支持基于Python脚本的场景语言;CARLA、VTD和最新版本的51Sim-One1.2等支持基于XML的场景语言。此外,protobuf、JSON都可以作为承载具体场景语言的格式。
这其中的关键不在于语言本身,而在于能全面且不冗余的覆盖交通元素的体系标准。目前已有一些机构在推相应的标准,比较成功的是由VTD发起的由ASAM(国际)/ CASAM(国内)推动的OpenX系列。公众号在后期会围绕OpenX系列展开较多介绍,因为这是目前看来最有可能推广开来的一个标准。具体也可以关注中汽中心周博林周博的分享。

M-SDL 一种高级场景语言
1.2 场景内容
1.2.1 基于知识、数据的场景来源在确定场景形式后,后期日常工作会围绕场景内容的构建展开。场景内容有两个主要来源:知识和数据。其中,基于知识的方法主要是依赖于具体场景结构,综合借鉴各相关学科的知识,分析自动驾驶系统需要处理的静、动态元素类型,并结合自动驾驶系统的测试需求构建场景。基于数据的分析方法则是从采集的自然驾驶数据中分析提取出有价值的场景。
基于知识、数据的场景构建方法最终都可以生成测试所需要的具体场景,这部分也是公众号后期要展开讨论的核心内容之一。

知识驱动和数据驱动的场景生成方法
1.2.2 具体静、动态场景内容从具体元素的角度看待场景内容,可将元素分为静态元素和动态元素(半动态)两部分。
静态场景元素的分析和提取相对较简单,主要包括道路、基础交通设施(交通标线、交通标志、交通信号灯以及抽象的交通规则等)、天气、光照、其他建筑物基础设施等,难点在于一些连续量(如光照和雨量)的取值范围分析,以及不同静态场景元素之间的约束关系。
动态场景元素的提炼和转化相对较为困难。主要原因如下:
- 除了静态场景元素固有的连续值取值范围和多约束问题外,交通行为是在一个高度复杂的存在多种约束条件的环境下的高交互性行为;
- 交通参与者类型众多,包括重卡、轻卡、乘用车、电动车、行人等,每种交通参与者都有自己特定的动态行为模式;
- 具体的动态行为模式有多种类型:带时间戳的轨迹数据、基于行为分类的数据(如跟车、换道等)、基于Agent的动态行为;
- 在实际提取动态交通数据时,需要考虑采集车自身的影响,即考虑处理交互性;
- 简单动态交通元素的分析以及大规模复杂交通元素的提取和具体形式有较多不同,需要不同的技术手段。
以上都是在提取动态场景内容时需要考虑的问题,也是公众号未来会重点展开的内容。

动态交通流示意
1.2.3 场景提取pipline最后再大致回顾一下场景提取的pipline。基本流程是数据采集、数据提取和数据转化。传统的数据采集工作,包括数据存储、数据标注、数据分类在企业中往往由基础架构部门负责,这部分在理论上和实践上也已经相当成熟了。仿真需要重点关注的是如何高效的从数据中提取有价值的场景,并将其转化为具体的场景格式。
2、仿真系统
仿真系统是整个仿真体系中承上启下的部分。它播放仿真场景,测试研究对象,通过仿真数据接口提供被测对象的运行表现数据。仿真系统是当之无愧的仿真体系核心,前面抛出有个仿真软件就能进行仿真工作的观点,只是为了说明构建仿真体系的下限。但在实际应用工作中,仿真系统的性能也决定着整个仿真体系的上限。
接下来我们来谈谈应该怎么看待仿真系统,围绕着仿真系统又该重点关注什么工作。
2.1 仿真软件 | 被测对象 | 通信环境
首先需要明确的是,仿真系统不止是仿真软件。从狭义上来说,它是仿真软件、通信环境与被测对象的集合;从广义上来说,它又包括云仿真环境等。
其次需要明确的是,仿真系统是具体的工具,是“术”。而在构建仿真系统时,作为仿真工程师在关注“术”之余,也需要关注“道”的部分。不同仿真软件、不同的通信环境、不同的被测对象都有各自的特点,作为仿真工程师需要了解不同仿真模块各自的共有属性,并充分理解并利用不同对象的特异性。关键是做到兼容并包,调节需求和客观仿真资源之间的矛盾。
仿真软件
在了解不同仿真软件的共有属性方面,可以学习基本的pipline。从比较粗的粒度上看,基本的仿真pipline是加载静态地图、构建动态场景、接入被测对象、导出运行数据、结果评价处理。这之后就基本可以上手一个仿真软件,剩余的深入拓展工作也可以围绕整体流程向外展开。
在了解不同仿真软件的差异方面,需要明白市面上各类软件各自的特点,集中精力是正确的,但是封闭眼界并不可取。单就自动驾驶仿真软件而言,Prescan、VTD、Panosim、51simOne、GaiA等商业自动驾驶仿真软件,CARLA、lgsvl、Airsim等开源自动驾驶仿真软件,稍微粗糙一些的DeepDrive、一些基于ROS构建的自动驾驶仿真平台,就都有各自的可取之处。

CARLA Simulator
另外,还有一些专精于特定功能仿真的软件。如在交通流仿真方面有Vissim、SUMO、High-env等;在动力学仿真方面有CarSim、Trucksim、Carmaker等软件;在静态场景仿真方面有一些大规模城市构建仿真软件;在构建复杂交通流场景方面也有一些软件。这些软件都可以纳入到整个自动驾驶仿真体系里来。我们会以后也会重点展开介绍各软件的不同点。

SUMO Simulator
被测对象根据被测对象的不同,业界常用的仿真工具链包括模型在环(MIL)、软件在环(SIL)、硬件在环(HIL)、整车在环(VIL)。目前SIL在各类公司应用范围最广,但其他各类也都有自己的独特优势和测试必要性;按照自然开发的流程,完整的测试过程也确实需要兼顾这几种平台。站在具体实践角度,每种在环仿真平台有适配于自己的仿真软件和技术栈,其中部分要掌握的技术如下:
- MIL与SIL相似,最基础的问题是通信环境构建,往上进一步则需要研究仿真效率、实时性、同步性等;
- HIL需要补充实时机与硬件通信接口的知识;
- VIL是大工程,需要投入大量人力物力来搭建专门的实验室,目前一般都应用于驾驶员在环仿真。
各种技术栈也是我们未来要探讨的重点之一,SIL会是主体,其他几种优先级会放的低一些。
通信环境
最后再来说说通信环境,即仿真软件和被测对象之间的信息传输环境。其基础是利用计算机网络的相关知识完成信息传输工作,也即各种JD描述中提到的开发仿真接口。
一般情况下,可以通过通信中间件处理仿真数据,并将其转化为被测对象所需的数据格式进行传输。中间件类型有很多,常用的可能有基于ROS的中间件、基于AutoSAR的中间件等。关键问题是结合具体测试需求选择合适的中间件;以及如何减少仿真消息的延迟和丢失以保证通信效率,这和仿真的可用度密切相关。
总之,优秀的仿真工程师除了需要有为软件增加仿真功能的能力外,更关键的是需要对自动驾驶系统有整体宏观上和局部微观上的理解,并能对接各方其他工程师的需求。在此基础上,如果是基于成熟商业仿真软件进行工作,就围绕着说明书、教程以及培训,同时与仿真软件的技术支持工程师时刻保持交流,并不断积累自己的应用能力。如果是基于开源仿真软件进行开发,则需要时刻关注软件的新版本和新功能,多刷issue以解惑。当然,也可时刻关注借助一些典型的基于仿真平台的优秀项目提升自己的能力。
2.2 静态环境模块 | 交通流模块 | 传感器模块 | 动力学模块 | 数据模块
在了解基本仿真系统的构成后,还是需要再回到仿真软件本身。只有在了解仿真软件的机理并清楚相应软件的缺陷之后,才能高效的对接各种测试需求以及针对性地开发相应功能。
以我个人的理解,一个完整的自动驾驶仿真软件从逻辑上包括静态环境模块,交通流模块 ,传感器模块,动力学模块,数据模块(包括场景模块)。针对每个模块都有一些亟需解决的关键仿真问题。
静态环境模块静态环境模块指构建、维护静态场景的模块。具体需要的静态元素需要同感知组进行对接,也可以结合具体的专家知识提取分析产品ODD。之后需要设计符合真实情况的场景元素并以合理的方法进行泛化。
这一模块的关键问题在于静态环境的真实度保障以及自动化构建大规模静态场景的方法两方面。
交通流模块对应于动态场景的概念,参考51VR公众号的总结,需要重点关注以下几种动态场景构建方式。每种构建方式都有一整套基础理论和实践手段,之后我们会一一展开。
- 典型交通行为建模,如启动、跟车、换道、超车、十字路口处理等。这部分主要可以使用DBM相关方法进行分析。
- 利用AI技术生成驾驶模型,在虚拟世界中设置AI车辆自动行驶,AI可以学习交通流的特性,尤其在行人仿真方面有比较好的成效。这部分主要可以使用模仿学习、强化学习来完成;
- 导入交通学中的交通流模型,并引入数学概率分布数学模型。这样的交通流模型包括宏观交通流模型和微观模型,相应的数学概率分布模型应该以高斯模型为主,这部分可以通过与SUMO/Vissim联合仿真完成,也可直接构建交通流模型。
将真人开车的数据导入交通流中,研究rare-events simulation,主要利用驾驶模拟器实现。

Agent-based traffic simulation
传感器模块传感器模块是连接外界环境和被测车辆的媒介。针对不同的被测对象,有不同的传感器模块使用方法。在进行决策规划系统测试时,可使用对象级传感器,由此可以避免传感器模型的不准确带来的大部分后续问题。对于需要原始仿真信息(如图像、点云)的被测系统,则需要基于实际产品情况精确标定传感器参数,如对于图像传感器标定位置外参和畸变系数等内参,对于激光雷达等传感器,标定线数、旋转速度等。
传感器建模是个处理难度很高的模块,目前有物理建模和统计建模两种典型的传感器建模方法。物理建模难度比较高,且需要大量的计算资源;统计建模方法始终存在真实度gap。如何弥补这两种模型的缺陷是需要深入讨论的问题。
一个可以借鉴的手段来自waymo,对于感知仿真的相关问题,它们似乎没有直接进行传感器建模,而是采用GAN的方式解决。如果必须要用到传感器建模,对于统计建模的方法,可以精心设计噪声参数并通过数据处理方法解决由真实程度带来的仿真结果差异。对于物理建模,则要看各仿真器的硬实力。但不管怎么样,首要的是处理真实程度的问题,其次是考虑计算资源的约束。

Surfel GAN
动力学模块这部分的重要性不再多提。它在传统车辆仿真工作中占有非常重要的地位,相关的理论和实践工作也已非常成熟。但不能因为待攻克的工程问题比较少就忽略它,相反,必须高度重视动力学仿真的结果,因为它的精确度可以直接影响仿真结果的可用程度。这部分的工作主要需考虑的是集成动力学仿真的方式,是内部支持还是通过与CarSim等进行联仿支持高精度动力学仿真?要不要考虑实时性问题?
总的来说,对于动力学仿真模块,要熟练掌握CarSim和TruckSim等动力学仿真软件和各种动力学模型,掌握联仿方法,动力学模型标定方法。另外,百度提供了一种基于数据的动力学建模方法,也有很高的实用价值。
数据管理模块本文指管理整个仿真数据pipline的模块,它的内涵覆盖范围很广,包括场景解析、仿真过程记录、过程回放、数据导出等等。每个具体功能都可以专门拿出一篇文章来谈,这部分也非常重要,但限于篇幅在此就不具体展开了。
2.3 本地仿真 | 大规模云仿真 | 稀有事件仿真
仿真可以降低时间成本、经济成本,提高测试的安全性。但是要保证自动驾驶系统的安全性,需要进行非常多的测试里程。即使采用场景测试的方法作为补充,但由于可能的场景参数较多以及部分参数具有连续性,因此很容易形成海量的测试场景。在这样的前提条件下,只用几个本地仿真系统的话,跑完这些场景的时间成本是不可接受的。能否合理解决这个问题,决定着仿真体系能不能发挥最大效能。
目前学术界/工业界有以下几个主流方案。其一是大规模云仿真,这也是工业界正在推动的主要路径,通过使用云资源进行并行计算,并在不同agent之间交换仿真结果以提高效率。另外一种由学术界重点推动的方法,则是借助场景的概念,通过设计一些策略缩少无风险里程,或者提高能对自动驾驶系统形成特定挑战的场景的生成效率,即通过“压力测试”提高仿真效率。

Sim Cloud of TAD

One Case of Stress Test
3、仿真评价
最后说说整个仿真体系中最容易被忽略的部分,基于仿真的评价。想象这样一个需求,自动驾驶系统更新了一个重要功能,相应的版本从V0.8更新到V0.9,现在需要进行回归测试以保证新的修改在解决新问题的同时,不对系统已经被验证过的能力造成影响。需要怎么做?
这时首要是要准备一个“标准场景库”,这个场景库也必须被精心设计,此处先不具体展开。考虑另外一个问题,如何保证系统过了这个场景库?用pass/fail的二元指标,或者违反交通规则的次数? 这种指标是有局限性的。最大的问题在于,由于仿真测试和实车测试结果的差异性,单纯的二元指标会催生大量的假阴性、假阳性结果,进而造成系统的安全性风险。因此我们需要建立一个更合理的评价体系,设计带有连续值属性的评价指标,通过评估“距离”来评估系统的安全性。
具体仿真评价指标的设计需要精确对接产品需求。不同的算法,不同的系统有自己的特定指标,这些可灵活发挥的点比较少,关键是对接好开发工程师的具体需求;面向第三方的评价体系则相对更具灵活性,可以设计面向安全性、舒适性、经济性等维度的具体指标。
总的来说,评价体系是必须精心设计的,因为它是评估迭代后的系统性能是否变好的基础。
4、主要挑战
在文章的最后,我们再集中谈谈目前仿真工作中遇到的几个挑战。
4.1 Reality Gap
Gap1:仿真对物理现实的表现是不充分的。举个典型例子,在针对感知系统进行测试时,是否需要保证渲染图像/点云和现实世界的高度一致性?由仿真合成的图像/点云等用于训练对应的自动驾驶系统是否能有效提高性能?
保持高度一致性需要非常高的成本。为了规避较高成本,目前也有一部分相关研究工作。典型的如百度的AADS(虚实结合)、谷歌的SurfelGAN(以GAN为代表的一系列工作)等。
Gap2:考虑所有相关的物理现象具有挑战性。举一些典型例子,简单车辆模型如果没有包含轮胎模型,在较高速度下如何考虑转向以及加减速等行为?如何建模随机过程(如信号噪声)并将这些模型作为一个整体集成到仿真中?如何将V2X仿真与物理地形仿真集成在一起?
解决这些问题,要开源节流。例如,感知渲染做不好,从工程的角度,可以考虑把仿真重心放在决策规划和控制上,而感知测试的重心可暂时放在回放型仿真上。或者仿真工程师可在已有的gap下,通过数据处理分析,以及一些交叉验证手段来覆盖掉gap。
总的来说,若系统在仿真环境和实际运行环境之间的表现差异太大,必须仔细分析造成差异的关键矛盾。如果该矛盾在短期内因为客观原因不能解决,则需果断调整重心。仿真非常有用,但不是测试过程的万能药,为了仿真而仿真是没什么意义的。
4.2 Complexity & Lack & Business
Complexity复杂性表征在三个方面。其一,自动驾驶软件本身的多样性;其二,单个仿真软件的功能复杂性;其三,针对特定系统和特定软件开发仿真接口的复杂性。
当前的自动驾驶仿真软件确实很多。VTD、Prescan、51Simone、PanoSim、GaiA、rfPro、CARLA、Airsim、Lgsvl、DeepDrive、Carsim、CarMaker;甚至Matlab/Simulink、GTA-5、Gazebo都可用于自动驾驶仿真。每个仿真软件都有自己的优缺点,如果面对具体测试需求不断切换要使用的模拟器,无疑会增加很多学习成本。此外,面向同一被测系统,针对不同自动驾驶仿真软件,往往需要开发不同的仿真接口,这也需要较高的时间成本。如此之多的仿真套件也不利于工程师日常维护,进而在开展工程级别的大规模仿真测试会有较多掣肘。
Lack
如果有一款足够完美的自动驾驶仿真软件是不是就一劳永逸了呢?
话虽如此,但实际情况没这么简单。从功能来说,目前很难说有一款公认的足够完美的自动驾驶仿真软件。大部分软件都还不能同时支持以下列举的全部功能:
- 由于可能破坏物理引擎的稳定性无法提供高于实时的模拟速度;
- 不支持高效的无GUI运行(headless execution)模式进而影响自动化测试等;
- 建模基于复杂多维真实交通行为的动态场景时需要较高数据成本以及专业知识;
- 构建大规模真实、异构静态场景时需要较高时间成本;
- 适配多种场景语言(或者说,将场景编码为场景语言)时,需要较高的时间成本;
- 不支持多agent联合仿真以及跨多台机器仿真会话有效分发;
- 不支持大规模场景(整个市区级)(此需求合理性有待讨论)。
Business不可否认,对有些自动驾驶仿真领域的深耕玩家而言,以上功能都已直接间接得开发成熟。但在实际进行研发时,还必须考虑软件使用的经济成本、所用数据安全性、仿真与基础架构的契合度(与数据闭环的契合度)。
因此部分机构还是会去独立开发完善一个仿真系统。此时,以上提到的相应功能开发也正是自动驾驶仿真工程师可能的部分日常工作。
4.3 Reproducibility
可复现性,某种角度上也叫仿真结果的确定性,包括两个方面,由仿真到现实的可复现性和仿真本身的可复现性。需要注意的是,前者是可复现性的重点和难点,需要通过精心处理Reality gap 解决,这里只是说说相对容易被忽略的后者。在实际测试过程中,只有在一定程度上保障了系统的可复现性,就可以知道对代码所做的更改是否修复了问题,进而有利于测试自动化和CI,规避假阴性和假阳性的结果。
MIL、SIL、HIL、VIL,无论是哪种仿真系统,仿真结果都可能存在一定噪声。表现在采用同一组场景,重复运行多次,评价指标值会出现一定的波动。自动驾驶系统作为CPS系统的一种,相应的仿真结果出现波动是正常的。由于波动出现的原因受众多较难追溯的因素影响(线程不稳定性、信息传输帧率、指标本身的高度非线性),因此需要精确建模噪声并定量分析的可能性较小。一种可行方法是通过多次运行实验,采用平均值等统计处理手段尝试定性解决这个问题。另外一种可行的方法则是通过设计模糊化、综合化的评价指标实现。
4.4 CI
在CI中集成仿真是大势所趋。但其会受到以下特性影响。
模拟器可靠性。CI的挑战之一是仿真软件本身的可靠性。在自动化中使用仿真软件时,可能有意外的崩溃、时间和同步问题。
接口稳定性。自动驾驶仿真软件接口的稳定性会对自动化过程产生重大影响,因为不一致的、不稳定的、脆弱的仿真软件接口可能会导致客户端应用程序出现故障。这里需要做大量的工程工作,来不断开发并维护仿真接口。
5、结语
自动驾驶仿真体系的搭建,下限很低,上限也很高。它在很多方面上决定着一个自动驾驶公司或部门能走多远。合理的完整的仿真体系能加速整个系统的开发和测试,提供正反馈。
目前已有很多知名公司和前辈分享了许多仿真相关的知识,这些知识令人受益匪浅,但由于每次分享时间有限,所以不太能展开更多,不易形成完整的系统。国内的51VR等于2019年参与出台了自动驾驶仿真蓝皮书,这本书为仿真的学习提供了系统学习路线,但受限于蓝皮书的性质,不易展开更多细节。
#高逼真合成数据助力智驾“看得更准、学得更快”
01 引言
随着自动驾驶技术的逐步落地,感知系统对数据的依赖正以前所未有的速度增长。传统实车采集虽然真实可信,但在效率、安全性、标注精度以及边缘场景覆盖方面均存在显著限制。
合成数据(Synthetic Data)因具备低成本、高可控性、无限扩展性和高精度标签等优势,已成为感知算法训练与验证的重要数据来源。尤其在多模态、多场景、大规模自动化生成等方面,仿真平台正成为构建感知数据体系的重要工具。
在感知系统的开发过程中,我们依托仿真平台生成覆盖多种场景和传感器类型的合成数据,用于支持AVM(环视系统)开发,同时也利用合成数据生成符合公开格式标准的数据集,助力算法在真实部署前实现高效迭代与验证。本文将系统介绍利用合成数据开发的具体应用流程和实践效果。
02 AVM系统开发中的仿真验证应用
环视系统(AVM, Around View Monitor)是自动驾驶和高级辅助驾驶系统(ADAS)中常见的功能模块,通常由4个或更多广角鱼眼相机构成,通过拼接多个摄像头图像生成车辆周围360°的鸟瞰图。
自动泊车系统(APA)需要环视图像提供对车辆周围环境的精准感知。通过仿真方式模拟鱼眼相机布设和 BEV 拼接,可生成多种泊车场景下的高保真图像,包括地库、斜列车位、窄通道等复杂工况。相比实车采集,仿真不仅可以批量构造极端和边缘泊车条件,还能自动提供精确的障碍物位置与车辆姿态标注,大幅加速感知模型的训练和验证流程,减少实车调试时间。
传统 AVM 系统的相机标定依赖人工操作和实车设备,流程繁琐且精度受限。通过仿真,可控制各摄像头位置与视角,并生成可重复、可验证的图像和标定数据,适用于整车项目开发初期的快速迭代。虚拟标定不仅提高了标定效率,还支持在方案切换、批量测试、相机布局验证等场景中自动生成对齐标注,降低人力投入,提升系统上线速度
在实际开发中,AVM对图像畸变建模、拼接精度、投影映射等有较高要求,传统方法依赖人工标定与测试,周期长、灵活性差。而基于aiSim的仿真流程,可有效提升开发效率与验证精度。
通过合成数据仿真平台,我们借助从环境搭建到数据生成的全流程仿真,成功实现了4个鱼眼相机生成AVM合成数据的优化和验证。

图1 基于aiSim构建AVM图像流程
标定地图与仿真环境构建
我们在Unreal Engine环境中快速搭建6米×11米标定区域,使用2×2黑白相间标定板构成特征纹理区域,并精确布设车辆初始位置,确保视野重叠区域满足投影需求,并通过特定插件将其无缝导入仿真器中。

图2 基于aiSim插件的Unreal Engine地图编辑
鱼眼相机配置与参数设置
设置前、后、左、右四个鱼眼相机,分别具备:
- 高水平FOV(约180°);
- 不同俯仰角(前15°、后25°、侧向40°);
- 安装位置贴近真实车辆安装场景(如后视镜下方)。
我们采用了仿真器内置的OpenCV标准内参建模,输出图像同步生成物体的2D/3D边界框与语义标签。

图3 环视OpenCV鱼眼相机传感器配置
BEV图像生成与AVM拼接
利用已知相机内参和标定区域结构,通过OpenCV完成图像去畸变与投影矩阵求解,逐方向生成BEV视图(Bird's Eye View)。结合车辆图层与坐标对齐规则,拼接生成完整的AVM图像。
支持配置图像分辨率(如1cm²/像素)与投影视野范围,确保几何准确性。

图4 投影区域及BEV转化示意图
多场景合成与传感器布局优化
通过批量仿真脚本,可快速测试不同环境(如夜间、窄巷、地库)、不同相机布局组合对AVM系统效果的影响。在算法不变的前提下,系统性评估外参配置的优劣,为传感器部署提供数据支持。

图5 不同场景下的AVM合成数据
03 合成数据构建多模态数据集
随着智能驾驶逐步从基础辅助走向复杂场景下的高阶功能,对感知系统的数据需求也在迅速升级。不仅需要覆盖高速、城区、出入口等典型 NOA 场景,还要求在不同模态之间实现精确对齐,以支撑融合感知模型的训练与验证。在这类任务中,仿真生成的合成数据具备可控性强、标签精准、格式标准的优势,正在成为算法开发的重要支撑手段。
在智能领航辅助(NOA)场景中,系统需识别高速匝道、变道车辆、道路边缘等要素,对训练数据多样性与标注精度要求极高。通过仿真构建城市快速路、高速公路等多类 NOA 场景,配合光照、天气、车流密度等变量自动生成图像与多模态同步数据。这类合成数据可用于训练检测、分割、追踪等模型模块,特别适合用于填补实车采集难以覆盖的复杂或高风险场景,增强模型鲁棒性。
融合感知模型依赖相机、毫米波雷达、激光雷达等多种传感器协同输入,对数据的同步性和一致性要求较高。通过仿真,可以同时生成这三类传感器的视角数据,并自动对齐时间戳、坐标系和标注信息,输出包括 3D 边界框、语义分割、目标速度等在内的完整标签,且格式兼容 nuScenes 等主流标准。这类数据可用于训练融合模型识别道路上的异形障碍物,例如夜间难以通过视觉识别的散落杂物,或需要多模态补强感知的边缘目标。仿真带来的高度可控性也便于统一测试条件,对模型性能进行定量分析与精细化调优。
在实际项目中,合成数据的价值不仅体现在生成效率和标注精度,更在于其能否与下游算法开发流程无缝衔接。为了实现这一目标,我们将 aiSim 导出的多模态原始数据,通过自研数据处理脚本,转换为基本符合 nuScenes 标准格式的数据集。
数据构建流程如下:
编写符合 nuScenes 规范的传感器配置文件
首先,我们根据 nuScenes 的数据结构要求,定义并生成了包含相机、雷达、激光雷达等传感器的配置文件,包括传感器类型、安装位置、外参信息等。该步骤确保生成数据可直接映射至 nuScenes 的 calibrated_sensor.json 和 sensor.json。

图6 激光雷达部分的传感器配置文件

图7 符合nuScenes格式的传感器配置
利用 aiSim Stepped 模式导出对齐的原始数据
其次,在仿真阶段,我们启用了仿真器的 Stepped Simulation 模式,该模式支持以固定时间步长(如每 0.1 秒)推进仿真,并确保所有传感器在同一时间戳输出数据。这种方式实现了多模态数据的时间戳全局对齐,满足 nuScenes 对数据同步的要求。

图8 aiSim相机传感器Bounding Box真值输出
然后,在仿真运行中,我们导出包含图像、点云、雷达、Ego Pose、2D/3D 标注等原始数据,场景长度约为 20 秒,覆盖了一段在高流量城市交通中经过十字路口的场景,作为构建示例数据集的基础。
结构化转换为 nuScenes JSON 格式
此外,使用自研转换脚本,我们将导出的原始数据组织并填充为 nuScenes 所需的各类 JSON 文件,并和官方标准格式对齐,包括:
- scene.json:记录场景序列;
- sample.json:定义帧级时间结构;
- sample_data.json:图像、雷达、点云等数据路径与时间戳;
- calibrated_sensor.json 和 sensor.json:传感器类型及配置;
- ego_pose.json:车辆轨迹;
- sample_annotation.json:3D 边界框、类别、属性;
- instance.json、category.json、visibility.json 等其他语义层级数据。

图9 nuScenes 标准数据集JSON结构表
数据集结构搭建完成
最终,构建完成的数据集具备完整的时空同步结构与语义标签,可直接用于视觉感知、雷达检测、融合感知等模型训练与评估任务。该流程验证了合成数据向标准训练数据的转换路径,并具备可扩展性,适用于更大规模的批量数据生成。

图10 激光雷达点云 + 相机融合标注框

图11 激光雷达点云 + 同类型标注框 (俯视/侧视)
图12 多帧实例+激光雷达点云 (俯视+路径)
这一完整流程不仅验证了合成数据在工程流程中的落地能力,也为后续基于大规模仿真生成标准训练集打下了结构基础。
04 aiSim:感知研发全流程平台
在自动驾驶感知系统的开发过程中,仿真平台已逐渐发展为合成数据生产的重要基础设施。aiSim 通过集成环境建模、传感器仿真、多模态数据输出与标准格式转换等功能,支持从场景构建到数据集生成的完整流程。
多样场景与数据格式的灵活支持
aiSim 可精细还原环视系统中鱼眼相机的安装布局、图像畸变特性及 BEV 视角拼接逻辑,生成贴近实车采集的高保真图像。同时,平台有一套自成体系的仿真数据组织与输出机制,涵盖视觉、激光雷达、毫米波雷达等多类型传感器数据及真值标注。支持通过脚本调度自动批量生成不同气候、光照、地形和交通条件下的多样化场景,满足大规模训练与边缘场景验证的需求
从物理建模到标签输出的完整链条
借助图形引擎,aiSim 实现了对真实物理光照、材质、阴影和天气的动态建模。平台支持相机、激光雷达、毫米波雷达等传感器的物理与几何特性建模,兼容 OpenCV、ROS 等常见开发标准。在数据输出方面,aiSim 支持多传感器同步控制,可自动生成对齐的 2D/3D 检测框、语义标签、Ego 轨迹等数据,覆盖感知算法训练常见需求,减少数据清洗与后处理工作量。
工程集成与可扩展性
aiSim 提供图形界面、工具链与开放 API,方便用户将其集成至企业现有的数据平台和模型训练流程中。平台内的场景配置与资源系统具备良好的可扩展性,支持用户自定义传感器布设、交通要素和场景资产,用于支持环视系统、感知模型、融合算法等不同研发阶段的需求。
无论是环视系统的泊车能力与虚拟标定,还是面向 NOA 和多模态融合的训练任务,仿真生成的数据都在感知系统的实际落地中提供了可衡量、可扩展的价值。让数据获取从“拍”到“造”,从“靠人”到“自动”,为智能驾驶研发提速、降本、增稳。
#DMAD
无需改动规划模块,分合语义-运动的端到端新框架~
近年来,模块化的端到端自动驾驶作为一种将感知、预测和规划统一优化的范式,受到了越来越多的关注。相比传统的模块化自动驾驶系统,端到端方法可以减少误差累积和模块间的信息传播损失,提高系统效率与鲁棒性。然而,它也面临着一个关键挑战:端到端的训练往往会伴随着感知性能的下降,也就是感知负迁移。此外,一些子任务之间的关联性也并未被充分利用,例如物体和地图之间的关联性。
这篇论文分析了感知负迁移的原因,并基于此设计了分合语义-运动的端到端框架,消除了负迁移从而全面提升了感知性能,并在不改进规划模块的情况下达到了开环和闭环规划SOTA:
Divide and Merge: Motion and Semantic Learning in End-to-End Autonomous Driving
论文:https://arxiv.org/abs/2502.07631
代码:https://github.com/shenyinzhe/DMAD
负迁移产生原因
语义和运动是驾驶任务所需的最基本但又异构的两种信息。语义信息指代环境中其他物体的类别,车道,交通标志等,它们通常是时不变的(time-invariant);而运动信息则描述了环境随时间的变化。在现有的端到端框架中,这两种信息是按顺序(sequential)学习的:首先进行物体和地图的感知,随后使用物体和地图的特征进行运动预测和规划,如图中的(a)所示。在此情况下,运动任务的梯度也被反向传播到感知任务中,在原本的语义特征中融入了运动特征。而运动特征对于目标检测和地图感知等语义任务来说是不明确的(ambiguous),从而导致了感知任务的负迁移。图中的(b)是另一类结构,主张使用单独的预测头将所有任务并行化。但由于目标检测和轨迹预测两个任务之间固有的关联性,语义-运动的顺序学习仍然存在而导致负迁移。

语义-运动分合架构
这篇论文提出了语义-运动分合架构。根据子任务所学习的信息将它们分为语义任务(目标检测和追踪、在线建图)和运动任务(轨迹预测、规划)。这个架构分离两类任务之间的梯度反向传播以消除负迁移,合并同类任务以利用任务之间的关联性而促进正迁移。
图片展示了本架构的概览,黑色实线为带有梯度的特征传播,灰色虚线则是无梯度的人类可读信息。上下两条路径分别用于学习语义和运动信息,并且切断了互相之间的梯度传播。

如何分离检测和预测?
由于目标检测和运动预测的固有关系,通常必须先执行检测,再对检测到的目标执行预测,形成了顺序学习的结构。本文提出了Neural-Bayes运动解码器。具体而言,本文为运动任务额外初始化了一系列和物体查询(object query)一一对应的运动查询(motion query),这些运动查询直接从历史图像特征中学习场景的运动信息。为了保留检测和预测的固有关系,本文提出了层间(inter-layer)参考点更新和帧间(inter-frame)参考点更新。每个运动解码层都接收来自上一个语义解码层的参考点作为运动查询的位置嵌入(positional embedding),这是层间更新。执行完当前帧的所有解码层以后,本文使用学习到的运动特征预测未来轨迹,并将预测结果作为物体查询在下一帧的初始参考点,这是帧间更新。这个思想和贝叶斯滤波有些相似:物体查询可以看作是贝叶斯滤波中的观测(observation),而运动查询则为状态(state)。贝叶斯滤波的任务是从嘈杂(noisy)的观测中估计未知的状态,而本文将这个思想与Transformer解码器结合了起来,实现了分离的检测和预测。在最终输出时,运动查询则根据所对应的物体查询是否阳性(positive)来进行筛选。

合并语义任务
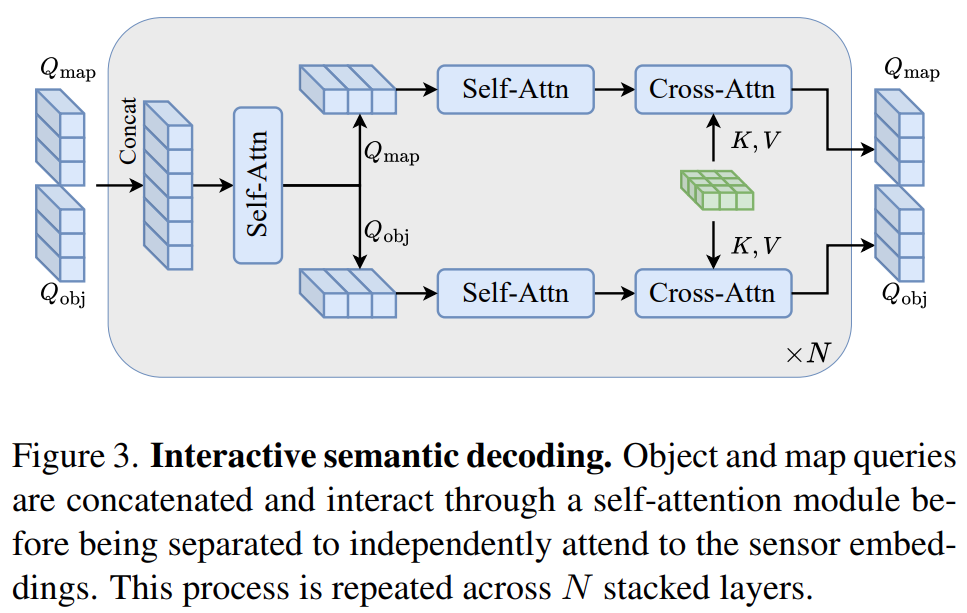
本文还提出合并同类任务以促进正迁移。物体类别和地图存在关联性,比如车辆大概率出现在可驾驶区域上,并且通常在车道内,而行人则很少出现在除了人行横道以外的可驾驶区域。本文提出了一种简单的方法以利用物体和地图之间的关联性:在每一个语义解码层中额外加入了一个物体和地图的自注意力模块以促进信息交互。
合并相似任务的思想也已可以应用在运动任务上,有一些其他论文提出了合并预测和规划,如SparseDrive等。但本文注重于提升端到端模型的感知性能,并将其推广到更好的规划,因此不对规划模块做显著更改。
实验结果
本文使用nuScenes作为感知,预测和开环规划的评估基准,使用NeuroNCAP作为闭环评估基准。本文将所提出的分合架构应用与目前流行的两个端到端模型:UniAD和SparseDrive,两者分别代表了基于稠密BEV的和基于稀疏感知的端到端驾驶方法。我们将基于UniAD的实现命名为DMAD,把基于SparseDrive的实现命名为SparseDMAD。在检测,追踪和在线建图的实验中,我们对比了模型在两阶段训练下感知性能的变化。由于第二阶段中加入了运动任务,UniAD和SparseDrive在第二阶段通常表现出更差的感知性能,而分合架构能够消除第二阶段的负迁移问题,在感知上最多能达到10%以上的提升。更好的感知也在轨迹预测任务上提升了端到端预测精度(EPA)。




本文在nuScenes开环评估中验证了分合架构对感知的提升可以被推广到规划上,对比两个基线分别降低了15%和4%的碰撞率。

在代码仓库中还提供了NeuroNCAP闭环评估代码和结果。将分合架构应用与UniAD上显著提提高了得分,实现了SOTA的闭环碰撞率结果。

可视化
论文使用SHAP values检验了分合架构对目标检测的分类头的影响。在UniAD的二阶段训练后,物体特征的SHAP values分布变得更加聚集,这意味着一部分特征维度对物体分类的作用降低了,这是负面的变化,也一定程度解释了负迁移。DMAD则在二阶段训练后基本维持原先的分布。

下面一些例子展现了DMAD相比于UniAD在降低碰撞率上的优势:

#RoboVerse
机器人大一统框架!迄今最大、最多样化的统一框架~机器人大一统框架来啦!
数据规模扩展和标准化评估基准推动了自然语言处理和计算机视觉领域的重大进展。然而,机器人学在数据规模扩展和建立可靠评估协议方面面临独特挑战。收集现实世界中的机器人数据资源消耗大且效率低下,而在现实场景中进行基准测试仍然非常复杂。合成数据和模拟提供了有前景的替代方案,但现有成果在数据质量、多样性和基准标准化方面往往存在不足。为应对这些挑战,我们推出了ROBOVERSE,一个全面的框架,包含模拟平台、一个合成数据集和统一的基准。模拟平台支持多种模拟器和机器人实体,能够在不同环境之间实现无缝转换。合成数据集具有高保真物理模拟和逼真渲染效果,通过多种方法构建而成,包括从公共数据集迁移、策略展开和运动规划等,并通过数据增强进行强化。
此外,还提出了用于模仿学习和强化学习的统一基准,能够在不同泛化水平上进行一致的评估。模拟平台的核心是METASIM,这是一种基础设施,它将各种模拟环境抽象为通用接口。它将现有的模拟环境重组为与模拟器无关的配置系统,以及一个对齐不同模拟器功能的API,例如启动模拟环境、加载具有初始状态的资产、推进物理引擎等。这种抽象确保了互操作性和可扩展性。
综合实验表明,ROBOVERSE提高了模仿学习、强化学习和世界模型学习的性能,改善了从模拟到现实的迁移效果。这些结果验证了数据集和基准的可靠性,确立了RoboVerse作为推进模拟辅助机器人学习的强大解决方案的地位。
如果您对足式机器人操作控制比较感兴趣,也欢迎学习我们的:足式机器人算法与实战教程
行业介绍
大规模数据集与完善的基准相结合,推动了自然语言处理(NLP)和计算机视觉(CV)领域的快速发展。大规模数据提供了丰富的训练示例,有助于学习过程,而统一的基准则能够对不同方法进行标准化评估和公平比较。然而,由于难以收集高质量、多样化的数据以及缺乏广泛认可的评估协议,在机器人学领域复制这些成功经验颇具挑战。
构建数据集和基准的现实世界方法虽然真实反映了操作环境的复杂性,但面临着重大的实际限制。首先,收集演示数据既耗时又耗费资源,而且得到的数据往往依赖特定硬件或特定模态,限制了其对新场景的适应性。此外,建立标准化且广泛适用的基准本身就极具挑战性,因为要再现相同条件以进行公平比较几乎是不可能的。例如,不同试验中的物体放置位置可能不同,自然阳光下的环境光照会发生变化,背景环境也可能改变。因此,扩展现实世界数据集规模、评估策略以及在现实场景中迭代开发,成本高昂且难以实现标准化。
另一方面,模拟器为大规模数据集和基准构建提供了有前景的替代方案。通过在可重现的环境中提供高效计算、合成资产和完备信息,模拟器能够以较低成本构建数据集并进行一致的性能评估。最近的研究已经证明了基于模拟的方法在各种机器人任务中的潜力。尽管有这些优势,但仍存在一些挑战阻碍了合成数据集和基准的更广泛应用。首先,由于模拟器设计的复杂性以及许多平台相对不成熟,使用模拟器通常需要大量专业知识,这使得数据构建过程变得复杂。其次,模拟器在内部架构和外部接口方面差异很大,将数据和模型从一个模拟器转移到另一个模拟器,或者调整工作流程以适应不同模拟器,都非常费力。因此,现有合成数据集和基准难以重复使用,导致生态系统碎片化,进一步阻碍了在模拟环境中便捷地构建和有效使用大规模数据。
为了充分发挥模拟在机器人学中的潜力,这里推出了ROBOVERSE,一个可扩展的模拟平台,它将现有模拟器统一在标准化格式和单一基础设施下,还包括一个大规模合成数据集和统一的基准。为此,首先提出了METASIM,它是ROBOVERSE的核心基础设施。通过精心设计,METASIM为智能体、物体、传感器、任务和物理参数建立了通用配置系统,同时提供了一个与模拟器无关的接口,用于模拟设置和控制。这种架构能够以最小的适配成本,无缝集成来自不同模拟环境的任务、资产和机器人轨迹。METASIM具备三项关键能力:(1)跨模拟器集成:能够在不同模拟器之间无缝切换,便于统一基准测试,并促进环境和演示在不同平台之间的转移。(2)混合模拟:结合多个模拟器的优势,例如将先进的物理引擎与出色的渲染器配对,生成可扩展的高质量合成数据。(3)跨实体转移:通过重新定位末端执行器的姿态,在各种配备平行夹爪的机械臂之间重用轨迹,最大限度地提高异构数据源的数据集重用率。
METASIM使ROBOVERSE能够系统地优化构建和扩展模拟环境及数据集的工作流程。方法具有以下特点:
- 可扩展且多样的数据生成:通过对齐多个基准和任务轨迹,并利用强大的多源集成和数据过滤pipeline,生成大规模、高质量的数据集。此外,数据随机化和增强pipeline提高了数据的多样性和数量,进一步丰富了数据集,有利于全面的模型训练。
- 逼真的模拟和渲染:借助METASIM的混合模拟能力,我们能够融合多个模拟器和渲染器的先进物理引擎和渲染系统。再结合精心策划的场景、材质和光照资产,ROBOVERSE增强了物理交互和感官观察的真实感。
- 统一的基准测试和评估:将广泛使用的基准统一为一个连贯的系统,在结构化评估框架内简化算法开发和性能比较。此外,引入标准化的基准测试协议,以评估不同程度的泛化能力和从模拟到现实的可转移性。
- 高度的可扩展性:对齐的API和基础设施简化了开发过程,能够在不同模拟环境中高效地集成、测试和部署算法。此外,还开发了从现实到模拟的框架、多种远程操作方法和人工智能生成系统,用于可扩展的任务和数据创建。
利用ROBOVERSE中的这些工作流程,构建了迄今为止最大、最多样化的高质量合成数据集和基准,且均采用统一格式。该数据集包含约50万个独特的高保真轨迹,涵盖276个任务类别和约5500个资产。此外,我们生成了超过5000万个高质量的状态转换数据,以支持策略学习。
除了数据集和基准构建,我们还通过在模仿学习、强化学习和世界模型学习方面的广泛实验,探索ROBOVERSE的潜力。结果表明,ROBOVERSE能够实现可靠的策略学习和评估,通过高保真物理模拟和渲染支持强大的模拟到模拟以及模拟到现实的转移,并通过远程操作、轨迹增强、域随机化和生成模型促进高效的数据扩展。这些发现凸显了该框架的稳健性、可扩展性和现实世界适用性。
相关工作一览
(一)机器人模拟器
计算机图形学的进步推动了高保真模拟器的发展,这些模拟器广泛应用于机器人研发。CoppeliaSim、Bullet和MuJoCo提供精确的物理模拟,在强化学习和机器人基准测试等应用中被广泛使用。更多模拟器充分利用并行性以提高效率。IsaacGym、IsaacSim、SAPIEN、MuJoCo MJX和Genesis利用GPU加速计算,实现大规模强化学习和高效数据收集,显著提高了训练速度和可扩展性。一些模拟器专注于缩小模拟与现实之间的差距,采用光线追踪和定制渲染器等技术实现逼真渲染。此外,IsaacSim和Genesis提供高保真软体和液体模拟,扩展了机器人真实交互的范围。ROBOVERSE提出了一个统一平台,支持多个模拟器,便于它们之间的无缝过渡,并实现混合集成,以利用每个模拟器的优势。
(二)大规模机器人数据集
机器人领域长期面临大规模、高质量和多样化数据集稀缺的问题。一些研究展示了直接在真实机器人上收集演示数据的可能性。RoboNet是一个大规模操作数据集,包含来自多个机器人平台的约16.2万条轨迹。DROID在86个任务中收集了超过7.6万个富含接触信息的机器人操作演示。RH20T提出了一个包含超过10万个演示和147个任务的数据集。同时,RT-1在700多个任务上创造了13万个演示的记录。最近,Open X-embodiment展示了一种有前景的方法,联合社区力量,在160266个任务上使用22种不同实体收集了超过100万条轨迹。现阶段,由于收集更多演示轨迹所需的努力和成本成比例增加,现实世界数据集难以进一步扩展。
基于模拟的数据收集为解决现实世界数据集的高成本和低效率问题提供了可行方案。相关研究提出了包含大量转换数据和任务的数据集,用于离线组合强化学习和通用机器人研究。DexGraspNet2.0收集了超过4亿个灵巧抓取演示。尽管有这些努力,但合成数据集通常存在于不同的模拟器中,导致生态系统碎片化,多样性和质量有限。此外,基于模拟的数据往往无法捕捉现实世界中复杂的物理现象和多样的任务变化,可能导致对特定模拟器的过拟合,阻碍在现实场景中的泛化能力。
ROBOVERSE为大规模、高质量和多样化的合成数据提供了统一解决方案。它使智能体能够在大量环境和模拟器上进行训练,以减少过拟合,从而提高所学策略的稳健性。
(三)机器人学中的基准测试
基准测试在机器人领域仍然是一个关键但极具挑战性的问题。与监督学习任务相比,评估机器人模型的性能相对困难。MetaWorld是早期在多任务基准测试方面的尝试。随后有RLBench、Behavior-1k、Habitat和ManiSkill等,涵盖了各种各样的机器人任务。Grutopia和InfiniteWorld朝着通用机器人基准测试迈出了一步。
尽管在这些基准测试上投入了大量努力,但不同基准测试的结果并不能保证具有可重复性。不确定性来自多个方面,包括模拟精度、渲染风格和资产属性等。为应对这些挑战,ROBOVERSE使研究人员能够在多个基准和模拟器之间无缝评估他们的策略,而无需分别熟悉每个基准和模拟器。
基础设施:METASIM
(一)METASIM概述
METASIM是位于特定模拟环境实现之上的高级接口,也是ROBOVERSE的核心基础设施。如图2所示,METASIM为ROBOVERSE模拟平台提供支持,能够生成大规模高质量数据集,并构建统一的基准。
(二)METASIM实现
如图3所示,METASIM采用三层架构,包括通用配置系统、与模拟器无关的接口和用户友好的环境包装器。通用配置系统统一了模拟场景的规范,确保不同模拟器之间的格式一致性。与模拟器无关的接口解释这些规范,并将其转换为特定模拟器的命令,从而对齐不同的模拟器后端。此外,环境包装器将与模拟器无关的接口封装到标准化的学习环境中,例如Gym环境。我们在以下部分详细描述每一层。
通用配置系统:一个典型的模拟环境包括智能体、物体、任务、传感器和物理参数。它们共同定义了谁执行动作(智能体)、环境的外观(物体)、智能体应该做什么(任务,包括指令、成功指标和奖励)、如何感知和测量环境(传感器)以及支配物理规律(物理参数)。理想情况下,这些组件应该与模拟器无关,这就需要一个统一的模拟场景标准。这样的标准将使研究人员能够在不同模拟器之间无缝工作,并通过交叉模拟整合社区现有的研究成果。
基于这一原则,我们设计了一个配置系统MetaConfig,以与模拟器无关的方式抽象模拟场景。如图4所示,MetaConfig是一个嵌套类,包含上述核心组件。不同的模拟器后端可以解释它,以构建相应的模拟。此外,MetaConfig支持可选的特定模拟器超参数(例如求解器类型),允许通过定制充分利用不同模拟器的独特功能。
对齐的模拟器后端:不同的模拟器有各自的实现和特点。然而,诸如初始化场景、加载物体、推进物理引擎、检索观察结果、时间管理和确定成功状态等常规操作,往往遵循相似的模式。为了标准化这些共享操作,我们通过Handler类创建了一个统一接口。每个模拟器都有自己实现该接口的handler实例。handler类实现了launch()、get_states()和set_states()等常用方法,涵盖了模拟任务的整个生命周期。
用户友好的环境包装器:Gym API是强化学习和机器人学中广泛采用的范式,其中gym.Env类是构建学习环境的基础。我们定义了一个包装器,便于将Handler转换为配备Gym API(step()、reset()、render()和close())的环境。如代码1所示,这些方法通过调用底层Handler的方法来实现。
(三)METASIM能力
METASIM具备以下三项关键能力:
- 跨模拟器集成:能够在不同模拟器之间无缝切换,允许在其他模拟器中使用来自一个模拟器的任务和轨迹。这种能力实现了高效的任务和轨迹集成、统一的基准构建,以及用于强化学习训练的模拟到模拟的转移。例如,MetaWorld中的任务可以在Isaacgym中用于快速并行训练,之后生成的轨迹可以部署在IsaacSim中进行渲染。
- 混合模拟:METASIM支持同时结合一个模拟器的物理引擎和另一个模拟器的渲染器,使用户能够受益于不同模拟器的优势。具体来说,通过一个命令,用户可以启动一个具有强大渲染器(例如IsaacSim)和精确物理引擎(例如MuJoCo)的模拟器,形成更强大的模拟,实现高质量的数据生成。
- 跨实体转移:通过重新定位末端执行器的姿态,在不同基于夹爪的机器人形态之间重用轨迹,使从不同机器人收集的数据能够整合为统一格式。
RoboVerse数据集(一)数据集概述在METASIM的基础之上,我们结合多种数据收集方法,生成大规模的高质量数据集。有三种关键的数据类型需要收集:任务、资产和机器人轨迹。这些数据的主要来源是从现有的模拟环境迁移而来。除了迁移,还探索了多种收集这些数据的方法,比如使用大语言模型生成新任务、利用RealSsim工具集从现实世界重建资产、通过远程操作收集新轨迹等等。此外,对轨迹和视觉观测数据采用数据增强方法。最后,我们汇报RoboVerse中数据迁移的当前进展统计情况。
(二)任务、资产和轨迹收集:迁移
借助RoboVerse的格式和基础设施,我们将一系列基准测试和数据集以统一格式、清晰代码库的形式,无缝集成到我们的系统中。我们采用以下方法来收集任务和演示数据:
- 直接从其他模拟环境迁移:一些基准测试为集成到RoboVerse提供了基本组件。我们为任务初始化和评估定义环境配置,然后转换轨迹数据和资产格式,以实现无缝兼容。值得注意的是,RoboVerse通过预先对齐原始模拟器中的格式,并自动确保在所有模拟器中的兼容性,简化了这一迁移过程。
- 运动规划和强化学习策略展开:当基准测试仅提供部分操作数据,如关键点轨迹或抓取姿势时,我们利用运动规划来生成完整的轨迹。如果没有明确的操作数据,但存在预先设定的策略或强化学习框架,要么利用这些策略,要么训练新的策略,通过策略展开来收集演示数据。为确保数据质量较高且符合我们的系统标准,我们会仔细调整成功检查机制,并严格筛选规划和收集到的轨迹。
通过上述技术,我们将多个现有的操作数据集迁移到了RoboVerse中。目前,我们支持ManiSkill、RLBench、CALVIN、MetaWorld、RoboSuite、MimicGen、GAPartNet、Open6DOR、ARNOLD、LIBERO、Simpler、GraspNet、GarmentLab和UniDoorManip。
我们还整合了来自更多样化实体的数据集,包括灵巧手、四足机器人和人形机器人,涵盖了诸如灵巧操作、移动、导航和全身控制等任务。目前,已经迁移了用于导航的VLN-CE R2R和RxR,以及用于移动和全身控制的HumanoidBench和Humanoid-X。
RoboVerse简化并规范了迁移过程,我们将继续维护并拓展这一过程。
(三)任务、资产和轨迹收集:远程操作和生成
用于轨迹收集的远程操作系统:如图5所示,RoboVerse在METASIM基础设施内集成了远程操作系统,为高质量数据收集提供了灵活且高效的解决方案。它支持各种机器人系统,包括机械臂、灵巧手和双手操作设置,能够在不同模拟器之间实现无缝远程操作。为降低专业设备的高成本和复杂性,我们引入了一种交互式运动控制系统,该系统可使用键盘、操纵杆、移动应用程序(我们开发了一款新的安卓和iOS应用程序来控制机械臂;更多详细信息见补充材料)、动作捕捉和VR系统等便捷设备。这些设备集成的传感器可捕获运动数据,实现基于手势的自然控制,并进行实时、高频通信,以实现精确、低成本的远程操作。
人工智能辅助任务生成:利用大型生成模型的泛化能力,人工智能辅助任务生成机制可实现任务种类和场景分布的多样化。通过学习示例布局,它能掌握空间和语义约束(例如,通过展示特定约束,它可以学习分散放置物体以避免潜在重叠等)。它可以基于METASIM将来自不同基准测试的物体排列成符合物理规律的场景,如图6所示。结合机器人和物体选择及其初始姿态的随机化,大型生成模型可以生成各种初始状态。系统可自动输出统一格式的所有所需配置文件,便于即时可视化和用户友好的编辑。任务生成后,我们将进行两步筛选,以避免错误和生成不合理内容:(1)格式验证:不符合RoboVerse格式标准的任务将被丢弃。(2)可行性检查:由于轨迹数据是通过人工远程操作收集的,远程操作员认为不合理的任务将被剔除。通过发挥大型生成模型的外推和少样本学习能力,我们自动将资产整合到统一模式下,推动跨多个模拟器和基准测试的任务生成。
基于现实到模拟的资产构建:基于视频的重建通过现实到模拟技术,成为数据和资产创建的重要来源。我们的方法整合了多种重建流程,从视频数据中提取高保真资产。首先,使用Colmap进行结构初始化,并采用高斯溅射法进行高质量渲染。接下来,将语义图像和原始图像输入视觉语言模型,以推断物理属性。对于几何重建,从视频中估计表面法线,应用表面溅射法,并使用基于截断符号距离函数(TSDF)的动态滤波方法重建详细网格。通过利用语义mask,从高斯和网格表示中选择性地提取组件。为进一步增强真实感,直接从视频中推断和学习物体运动学,确保准确的运动表示。最后,通过细化关键属性,如坐标系、方向、轴对齐、比例、相对六自由度姿态和PD控制参数,构建URDF模型。这个流程有效地弥合了现实世界视频数据与适用于模拟的资产之间的差距,提升了机器人学习和模拟的逼真度。
(四)数据增强
轨迹增强:凭借统一的模拟接口和数据格式,RoboVerse显著提高了数据增强的效率,并支持先进的增强技术。除了视觉随机化,还提供强大的轨迹空间增强功能。我们提供了一个API,可从有限数量的源演示中生成大规模机器人轨迹数据集。遵循MimicGen框架,对于大多数任务,可以将其分解为一系列以物体为中心的子任务,其中机器人在每个子任务中的轨迹是相对于单个物体的坐标系的。此外,我们假设每个任务中的子任务顺序是预先定义的。利用关于子任务顺序的少量人工注释,可以使用模拟器将每个源演示有效地划分为连续的以物体为中心的操作片段,然后使用MimicGen为各种任务变体(在我们的案例中:物体和机器人的初始和目标状态分布的变化)生成大量轨迹数据集。这种方法已被证明在模仿学习中,特别是在源演示数量有限的场景中,对提高泛化能力有显著帮助。更多细节请参考补充材料。
域随机化:在MetaSim的IsaacLab处理器中实施域随机化。这涉及四种类型的随机化:
- 桌子、地面和墙壁:对于没有预定义场景的任务,可以添加墙壁(和天花板)。对于在桌面上执行的任务,还可以包含可定制的桌子。这些元素的视觉材质从精心挑选的ARNOLD和vMaterials子集中随机选择。桌子有大约300种材质选项,而墙壁和地面各有大约150种材质选项。
- 光照条件:可以指定两种光照场景:远光和圆柱光阵列。对于远光,光源的极角是随机化的。对于圆柱光,在智能体上方固定高度处添加一个随机大小的n×m圆柱光矩阵。在这两种场景中,光的强度和色温都在合理范围内随机化。
- 相机姿态:精心挑选了59个候选相机姿态,其中大多数直接面向机器人,一小部分位于侧面角度。
- 反射属性:每个表面的粗糙度、镜面反射和金属属性在合理范围内随机化。
这些随机化选项可以自由组合。例如,一个场景可以包括定制的桌子、带天花板的墙壁和一组圆柱光,以模拟室内环境。详细信息请参考补充材料。
(五)RoboVerse数据集
数据集统计信息:
操作数据集:将来自现有源基准测试的各种操作数据集迁移到RoboVerse中。每个源基准测试贡献的任务类别、轨迹和资产数量汇总如下。此次迁移总共产生了276个任务类别、51.05万条轨迹和5500个资产。图8展示了具有丰富域随机化的代表性任务。
导航数据集:将视觉语言导航任务迁移到RoboVerse中。需要注意的是,视觉语言导航任务有多种不同设置;在这里,特别关注连续环境中的视觉语言导航,因为它更接近现实世界场景。基于RoboVerse构建数据集,整合了MatterPort 3D场景和现成的来自R2R和RxR的指令。这里提供两种移动实体,包括Unitree Dog(一种腿式机器人)和JetBot(一种轮式机器人),它们支持不同的控制策略。
人形机器人数据集:我们迁移了HumanoidBench任务用于强化学习基准测试,并整合了来自Humanoid-X和SkillBlender的任务、策略和数据样本。此外,在框架内重新实现了UH-1推理流程。预训练策略成功使人形机器人能够在多个基于RoboVerse的模拟器中,跟随演示姿势并保持稳定移动。
RoboVerse基准测试
(一)基准测试概述
利用收集到的任务、资产和轨迹,RoboVerse为机器人学习建立了标准化的基准测试,包括模仿学习和强化学习。在RoboVerse平台内定义了统一的训练和评估协议,并实现了标准化的基线和学习框架用于基准测试。对于模仿学习,引入了不同级别的泛化基准测试,以评估模型的泛化能力。
(二)模仿学习基准测试
对于每个模仿学习基准测试,建立了一个标准化的评估框架,其中包含一组固定的演示和受控的评估环境。策略必须仅在提供的训练数据上进行训练,并在该环境中进行评估,以确保公平比较。为了严格测试泛化能力,从特定领域精心挑选训练数据,并在未见样本上评估策略,挑战它们对新场景的适应性。我们系统地将视觉泛化因素分为多个级别,包括任务空间泛化、环境设置泛化、相机设置泛化以及光照和反射泛化。每个级别引入受控的变化,以评估策略在日益多样化和具有挑战性的条件下的适应性和稳健性。
- 级别0:任务空间泛化:通过标准化环境,保持相机、材质、光照和其他参数一致,建立受控评估。任务空间,包括物体初始化和指令,按90%训练和10%验证进行划分,以评估在固定设置下的泛化能力。
- 级别1:环境随机化:在标准化设置的基础上,在保持相机、材质和光照固定的同时引入场景随机化。通过改变房屋、桌子和地面的配置,我们创建多样化的视觉输入,以测试策略对环境变化的稳健性。一组预定义的随机场景确保了结构化评估。
- 级别2:相机随机化:为了评估策略在相机变化下的泛化能力,使用精心标注的真实相机姿态,引入不同的观察高度和角度。按照90/10的训练/测试划分,我们确保评估的一致性和严格性。
- 级别3:光照和反射随机化:现实世界环境包含各种材质和光照条件。为了模拟这些挑战,随机化光照和反射,精心挑选现实的物体材质和照明设置。这增强了在不同条件下的稳健性测试。
(三)强化学习基准测试
除了模仿学习,RoboVerse还提供了一个全面的强化学习基准测试,旨在适应各种任务、机器人实体和模拟后端。将来自STABLE-BASELINES3和RSL_RL的近端策略优化(PPO)算法集成到METASIM接口中,实现了简单的任务定义、无缝的环境切换和标准化的性能记录。
在此基础设施之上,成功将多个来自HumanoidBench基准测试的人形机器人控制任务移植到RoboVerse中。通过为RSL_RL适配的接口,有效地扩展了框架的兼容性,以支持来自原始基准测试的TD-MPC2算法,同时保持实现的准确性。
实验结果分析
(一)概述
我们开展了大量实验,以验证ROBOVERSE的有效性和实用性。首先,在来自不同基准源的代表性任务上对基线模型进行评估,以此确保所收集数据集和建立基准的可靠性。这其中包括对模仿学习基线模型和强化学习基线模型的评估。随后,进一步展示高质量合成数据集的优势。研究发现,合成数据能够显著推动世界模型学习的发展。
(二)模仿学习基准测试结果
基线模型和任务选择:为真实反映RoboVerse数据集的数据质量,并为各类模仿学习策略模型提供标准的基准,我们选取了主流的专业模型和通用模型作为RoboVerse基准测试的基线模型。对于专业模型,整合了ACT和扩散策略模型。对于通用模型,在OpenVLA和Octo上进行基准测试,并利用合成数据集对它们进行微调。ACT是双手操作领域应用最为广泛的方法之一。扩散策略则是首个将条件去噪扩散过程应用于机器人视觉运动策略的研究成果,具备出色的泛化能力。OpenVLA是最大的开源视觉语言动作模型,拥有70亿参数。
借助RoboVerse的格式和基础设施设计,能够在统一平台上对不同任务的模型进行评估。为全面测试策略模型在多种设置下的性能,从RoboVerse数据集整合的每个源基准中挑选一个代表性任务。实验子集包括来自ManiSkill的“PickCube”和“StackCube”任务、来自RLBench的“CloseBox”任务、来自CALVIN的“MoveSliderLeft”任务、来自LIBERO的“PickChocolatePudding”任务,以及来自RoboSuite的“NutAssembly”任务。这些任务不仅要求精确的抓取和放置技能,还需要与关节物体进行丰富的物理交互,通过这些任务,基准测试结果能够全面反映每个模型在不同场景下的性能表现。
实现细节:由于时间和资源有限,采用不同策略来实现专业模型和通用模型,且所有结果均在单任务设置下获得。训练和评估设置遵循RoboVerse基准测试协议中规定的90/10划分方式。在评估时,从训练集中随机选取10个任务设置,从验证集中再随机选取10个。报告的成功率是在3个随机种子上的平均值。
对于每个步骤,输入为256×256×3的RGB图像,以及根据任务设置而定的简短语言描述。对于专业模型,从9维机器人关节状态空间的动作开始进行从头训练。对于通用模型,动作从绝对末端执行器位置空间预处理为增量末端执行器位置空间,并且夹爪动作被离散化为二进制值{0, +1}。由于时间和资源不足,只能在单任务设置下对通用模型进行微调。在评估过程中,使用Curobo作为逆运动学求解器,将动作转换到机器人关节状态空间。具体的模型实现细节和超参数在补充材料中提供。
实验结果:在表格中展示了模仿学习基准测试的结果,以及泛化评估的结果。还在简单和复杂的语言条件任务上进一步微调大型视觉语言动作模型。
(三)强化学习基准测试结果
使用STABLE-BASELINES3和RSL_RL中实现的近端策略优化(PPO)算法,在一致的超参数下对来自IsaacLab的任务训练策略。
对于其他任务(如人形机器人、灵巧手相关任务),同样基于PPO的工作流程依然适用。我们成功将HumanoidBench从MuJoCo迁移到RoboVerse,实现了在多个模拟器(IsaacLab和MuJoCo)上使用一致的接口进行训练。实验结果表明,策略在不同模拟器上均能稳定收敛,性能与原生MuJoCo基线相当。利用RSL_RL的泛化能力,进一步扩展基准测试,使其支持TD-MPC2算法,该算法在所有环境中都展现出稳健的训练动态。
(四)增强实验
为验证轨迹增强API的有效性,在四个代表性任务上进行对比实验,观察在模仿学习设置下,Diffusion Policy在使用50个源演示以及分别使用200、1000和3000个生成的增强演示进行训练后的成功率变化。实验结果显示,随着生成数据数量的增加,模型性能持续提升,这突出了轨迹增强API的有效性和可扩展性。
(五)世界模型学习
通用视频生成和交互式世界模型的最新进展展现出良好的发展前景。然而,大规模机器人数据集的稀缺,仍然制约着适用于广泛机器人应用场景的稳健世界模型的开发。这里将展示如何利用RoboVerse模拟产生的合成数据,扩充现实世界数据集,进而训练出更强大的机器人世界模型。
当模型仅在DROID数据集的50,000个情节上进行训练时,它通常能够遵循动作条件,但在精确捕捉夹爪与目标物体之间的物理交互方面存在困难。值得注意的是,在夹爪接触物体时,物体在画面中会出现“变形”的情况。通过从RoboVerse引入额外的50,000个合成情节,构建一个包含100,000个情节的组合数据集后,模型在保留物体几何形状的预测方面有所改进。然而,仅依靠“观看视频”的方式,仍不足以让模型学习到DROID数据集中复杂的物理交互。
相比之下,当模型仅在RoboVerse - 50K或DROID - RoboVerse - 100K数据集上进行训练,然后在RoboVerse样本上进行验证时,观察到生成的帧在大多数场景下物理上更加真实。这种改进可归因于RoboVerse中广泛的随机化和增强技术。相反,仅在DROID数据上训练的模型,无法有效地迁移到RoboVerse场景中。推测,这一不足源于DROID中每个场景的样本覆盖范围有限,以及相机视图中夹爪的可见性不完整。
(六)模仿RoboVerse数据集可实现直接的模拟到现实迁移
RoboVerse系统将强大的物理引擎与高质量渲染器无缝集成,确保生成逼真、高保真的数据。为展示其潜力,我们进行实验,验证其在直接模拟到现实迁移方面的有效性。在RoboVerse数据集上对OpenVLA进行微调,然后将学习到的策略直接应用于现实场景,无需额外的微调操作。该模型成功在之前未见过的现实环境中,对未见过的物体进行操作,展示了我们系统的稳健性和泛化能力。在更具挑战性的语言引导任务上的定量结果进一步表明,在RoboVerse数据集上训练的模型具有较高的成功率。
(七)RoboVerse中的强化学习可实现模拟到模拟再到现实的迁移
大规模并行环境为大规模探索提供了巨大潜力,在强化学习(RL)任务中非常有效。然而,尽管它们效率很高,但在某些场景下,其准确性可能会受到限制。为解决这个问题,模拟到模拟评估和微调提供了可行的解决方案。RoboVerse平台无缝支持这些功能,实现了稳健的模拟到模拟以及模拟到现实的转换。我们通过全面的实验进一步展示了模拟到模拟再到现实泛化的有效性,突出了该平台在弥合模拟与现实世界性能差距方面的能力。
局限性
尽管ROBOVERSE提供了一个全面且可扩展的平台,但仍存在一些局限性。首先,目前尚未完全支持非刚性物体的统一格式集成,这将留待未来的工作进一步开发。此外,虽然大规模数据集在预训练基础模型方面具有巨大潜力,但由于资源限制,未对其进行探索。再者,尽管努力在ROBOVERSE基线中全面重新实现并优化所有基线方法,但部分实现可能仍未达到最佳状态。我们的主要目标并非直接比较策略性能,而是展示该系统的全面性,它能够支持多种策略,并确保模拟与现实世界性能之间的高度一致性。尽管全力构建一个稳健的平台,但难免会存在一些疏忽或错误。我们鼓励更广泛的研究社区为维护和完善基线做出贡献,通过合作进一步提升该平台的能力。
参考
[1] ROBOVERSE: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
#Seed-Thinking-v1.5
200B参数击败满血DeepSeek-R1,字节豆包推理模型Seed-Thinking-v1.5要来了
字节跳动豆包团队今天发布了自家新推理模型 Seed-Thinking-v1.5 的技术报告。从报告中可以看到,这是一个拥有 200B 总参数的 MoE 模型,每次工作时会激活其中 20B 参数。其表现非常惊艳,在各个领域的基准上都超过了拥有 671B 总参数的 DeepSeek-R1。有人猜测,这就是字节豆包目前正在使用的深度思考模型。

字节近期官宣的「2025 火山引擎 Force Link AI 创新巡展」活动推文中提到,4 月 17 日首发站杭州站时,豆包全新模型将重磅亮相,这会是 Seed-Thinking-v1.5 的正式发布吗?
- 报告标题:Seed-Thinking-v1.5: Advancing Superb Reasoning Models with Reinforcement Learning
- 项目地址:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5
- 报告地址:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5/blob/main/seed-thinking-v1.5.pdf
Seed-Thinking-v1.5 是一款通过深度思考提升推理能力的模型,在多个权威基准测试中展现出卓越性能。在具体评测中,该模型在 AIME 2024 测试中获得 86.7 分,Codeforces 评测达到 55.0 分,GPQA 测试达到 77.3 分,充分证明了其在 STEM(科学、技术、工程和数学)领域以及编程方面的出色推理能力。

除推理任务外,该方法在不同领域都表现出显著的泛化能力。例如,在非推理任务中,其胜率比 DeepSeek R1 高出 8%,这表明了其更广泛的应用潜力。
从技术架构看,Seed-Thinking-v1.5 采用了混合专家模型(Mixture-of-Experts,MoE)设计,总参数量为 200B,实际激活参数仅为 20B,相比同等性能的其他最先进推理模型,规模相对紧凑高效。
为全面评估模型的泛化推理能力,团队开发了 BeyondAIME 和 Codeforces 两个内部基准测试,这些测试工具将向公众开放,以促进相关领域的未来研究与发展。
先来看看其具体表现。

在数学推理方面,在 AIME 2024 基准上,Seed-Thinking-v1.5 取得了 86.7 的高分,与高计算量的 o3-mini-high 差不多。
由于 AIME 2024 已经不足以彰显前沿模型的差异,豆包团队还使用了另一个更具挑战性的评估基准 BeyondAIME,其中所有问题都是人类专家新整理编写的。结果可以看到,虽然 Seed-Thinking-v1.5 的成绩超过了 R1 和 o1,但相比于 o3 和 Gemini 2.5 pro 还有所差距。
在竞赛编程方面,在 Codeforces 基准上,该团队没有采用之前的依赖 Elo 分数的评估策略,而是采用了基于最新的 12 场 Codeforces 竞赛的具体评估方案。
具体来说,他们报告的是 pass@1 和 pass@8 指标,其中 pass@k 表示模型能否在 k 次尝试内解决问题,即从 k 次生成的提交中选择最佳结果。之所以选择报告 pass@8,是因为能提供更稳定的结果,并且更接近实际用户提交模式。
结果来看,Seed-Thinking-v1.5 在这两个指标上均超过 DeepSeek-R1,不过与 o3 的差距仍旧比较明显。该团队表示未来将公开发布这个评估集。
在科学问题上,Seed-Thinking-v1.5 在 GPQA 基准上得分为 77.3,接近 o3 的表现。该团队表示,这一提升主要归功于数学训练带来的泛化能力的提升,而非增加了特定领域的科学数据。
豆包也测试了 Seed-Thinking-v1.5 在非推理任务上的表现。这里他们使用的测试集尽力复现了真实的用户需求。通过人类对 Seed-Thinking-v1.5 与 DeepSeek-R1 输出结果的比较评估,结果发现,Seed-Thinking-v1.5 获得的用户积极反馈总体高出 8.0%,凸显了其在复杂用户场景处理能力方面的能力。
下面我们就来简单看看豆包是如何创造出 Seed-Thinking-v1.5 的。
开发高质量推理模型有三大关键:数据、强化学习算法和基础设施。为了打造出 Seed-Thinking-v1.5,该团队在这三个方面都进行了创新。
数据
推理模型主要依赖思维链(CoT)数据,这种数据展示逐步推理过程。该团队的初步研究表明,过多非思维链数据会削弱模型探索能力。
研究团队在强化学习训练中整合了 STEM 问题、代码任务、逻辑推理和非推理数据。其中逻辑推理数据提升了 ARC-AGI 测试表现。而数学数据则展现除了优秀的泛化能力。
另外,他们还构建了一个新的高级数学基准 BeyondAIME,其中包含 100 道题,每道题的难度等于或高于 AIME 中最难的题目。与 AIME 类似,所有答案都保证为整数(不受特定数值范围的限制),这能简化并稳定评估过程。
强化学习算法
推理模型的强化学习训练常出现不稳定性,尤其对未经监督微调的模型。为解决这一问题,研究团队提出了 VAPO 和 DAPO 框架,分别针对基于价值和无价值的强化学习范式。两种方法均能提供稳健的训练轨迹,有效优化推理模型。参阅报道《超越 DeepSeek GRPO 的关键 RL 算法,字节、清华 AIR 开源 DAPO》。
奖励建模
奖励建模是强化学习的关键,它确定了策略的目标。良好的奖励机制能在训练时提供准确的信号。团队针对可验证和不可验证的问题使用不同的奖励建模方法。
1、可验证问题
通过适当的原则和思维轨迹,团队利用 LLMs 来判断各种场景下的可验证问题。这种方法提供了超越基于规则的奖励系统局限性的更普遍解决方案。
团队设计了两个递进式的奖励建模方案:Seed-Verifier 和 Seed-Thinking-Verifier:
- Seed-Verifier 基于一套由人类制定的原则,利用大语言模型的能力评估由问题、参考答案和模型生成答案组成的三元组。如果参考答案与模型生成的答案本质上等价,它返回「YES」;否则返回「NO」。这里的等价不要求逐字匹配,而是基于计算规则和数学原理进行深层评估,确保奖励信号准确反映模型回答的本质正确性。
- Seed-Thinking-Verifier 的灵感来自人类的判断过程,通过细致思考和深入分析得出结论。为此,团队训练了一个能够提供详细推理路径的验证器,将其视为可验证任务,与其他数学推理任务一起优化。该验证器能够分析参考答案与模型生成答案之间的异同,提供精确的判断结果。
Seed-Thinking-Verifier 显著缓解了 Seed-Verifier 存在的三个主要问题:
- 奖励欺骗(Reward Hacking):非思考型模型可能利用漏洞获取奖励,而不真正理解问题。Seed-Thinking-Verifier 的详细推理过程使这种欺骗变得更加困难。
- 预测的不确定性:在参考答案与模型生成答案本质相同但格式不同的情况下,Seed-Verifier 可能有时返回「YES」,有时返回「NO」。Seed-Thinking-Verifier 通过深入分析答案背后的推理过程,提供一致的结果。
- 边界情况处理失败:Seed-Verifier 在处理某些边界情况时表现不佳。Seed-Thinking-Verifier 提供详细推理的能力使其能够更好地应对这些复杂场景。
表 1 展示了上述两种验证器的性能。结果表明,Seed-Verifier 在处理某些特殊情况时效果欠佳,而 Seed-Thinking-Verifier 展现出提供准确判断的卓越能力。尽管后者的思维过程消耗了大量 GPU 资源,但其产生的精确且稳健的奖励结果对于赋予策略强大的推理能力至关重要。

2、不可验证问题
研究团队为不可验证问题训练了一个强化学习奖励模型,使用与 Doubao 1.5 Pro 相同的人类偏好数据,主要覆盖创意写作和摘要生成。
团队采用了成对生成式奖励模型,通过直接比较两个回答的优劣并将「是 / 否」概率作为奖励分数。这种方法让模型专注于回答间的实质差异,避免关注无关细节。
实验表明,此方法提高了强化学习的稳定性,尤其在混合训练场景中减少了不同奖励模型间的冲突,主要是因为它能降低异常分数的生成,避免与验证器产生显著的分数分布差异。
基础设施
大语言模型强化学习系统需要强大基础设施支持。团队开发的流式推演架构通过优先级样本池异步处理轨迹生成,使迭代速度提升 3 倍。系统还支持自动故障恢复的混合精度训练,确保大规模强化学习运行的稳定性。
框架
Seed-Thinking-v1.5 采用的训练框架是基于 HybridFlow 编程抽象构建的。整个训练工作负载运行在 Ray 集群之上。数据加载器和强化学习算法在单进程 Ray Actor(单控制器)中实现。模型训练和响应生成(rollout)在 Ray Worker Group 中实现。
流式 Rollout 系统
其 SRS 架构引入了流式 Rollout,可将模型演化与运行时执行解耦,并通过参数 α 动态调整在策略和离策略的样本比例:
- 将完成率(α ∈ [0, 1])定义为使用最新模型版本以在策略方式生成的样本比例。
- 将剩余的未完成片段(1- α)分配给来自版本化模型快照的离策略 rollout,并通过在独立资源上异步延续部分生成来实现无缝集成。
此外,该团队还在环境交互阶段实现了动态精度调度,通过后训练量化和误差补偿范围缩放来部署 FP8 策略网络。
为了解决 MoE 系统中 token 不平衡的问题,他们实现了一个三层并行架构,结合了用于分层计算的 TP(张量并行化)、具有动态专家分配的 EP(专家并行)和用于上下文分块的 SP(序列并行)。这样一来,其 kernel auto-tuner 就能根据实时负载监控动态选择最佳 CUDA 核配置。
训练系统
为了高效地大规模训练 Seed-Thinking-v1.5 模型,该团队设计了一个混合分布式训练框架,该框架集成了先进的并行策略、动态工作负载平衡和内存优化。下面详细介绍一下其中的核心技术创新:
- 并行机制:该团队 TP(张量并行)/EP(专家并行)/CP(上下文并行)与完全分片数据并行(FSDP)相结合,用于训练 Seed-Thinking-v1.5。具体而言,他们将 TP/CP 应用于注意力层,将 EP 应用于 MoE 层。
- 序列长度平衡:有效序列长度可能在不同的 DP 等级上不平衡,从而导致计算负载不平衡和训练效率低下。为了应对这一挑战,他们利用 KARP 算法重新排列了一个 mini-batch 内的输入序列,使它们在 mini-batch 之间保持平衡。
- 内存优化:他们采用逐层重新计算、激活卸载和优化器卸载来支持更大 micro-batch 的训练,以覆盖 FSDP 造成的通信开销。
- 自动并行:为了实现最佳系统性能,他们开发了一个自动微调系统,称为 AutoTuner。具体来说,AutoTuner 可按照基于配置文件的解决方案对内存使用情况进行建模。然后,它会估算各种配置的性能和内存使用情况,以获得最佳配置。
- 检查点:为了以最小的开销从不同的分布式配置恢复检查点,该团队使用了 ByteCheckpoint。这能让用户弹性地训练任务以提高集群效率。
#多模态类R1推理模型新突破,7B超越38B
论文题目:
Boosting the Generalization and Reasoning of Vision Language Models with Curriculum Reinforcement Learning
01 工作概述:
在中小尺寸多模态大模型上,我们成功复现了R1,并提出了一种创新的后训练范式,Curr-ReFT。通过结合课程强化学习和基于拒绝采样的自我改进方法,我们显著提升了视觉语言模型(VLM)的推理能力和泛化能力。
- Curr-ReFT:我们提出了一种新型后训练范式,结合课程强化学习和自我改进策略。在Qwen2.5-VL-3B和Qwen2.5-VL-7B模型中验证了其有效性。
- 全面评估:在多个自建数据集和权威基准测试上进行对比实验,验证了模型的通用表现,结果表明7B模型甚至超越了最新的InternVL2.5-26B和38B模型。
理论与实验分析:
- 强化学习的重塑能力:我们证明了基于规则的强化学习能够有效重塑多模态/CV任务的训练方案,从传统的精调转向强化精调。
- 提升推理与泛化能力:实验结果显示,强化学习方法显著提升了VLM在分布外数据上的表现。
论文链接:
https://arxiv.org/pdf/2503.07065
开源链接:
https://github.com/ding523/Curr_REFT (代码)
https://huggingface.co/datasets/ZTE-AIM/Curr-ReFT-data(数据)
https://huggingface.co/ZTE-AIM/3B-Curr-ReFT (模型权重)
https://huggingface.co/ZTE-AIM/7B-Curr-ReFT (模型权重)
02 动机背景
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。然而,这些成就主要依赖于大规模模型扩展(>32B 参数),这在资源受限的环境中造成了显著的部署障碍。因此,如何通过有效的后训练(post-training)范式来缩小小规模多模态模型与大规模模型之间的性能差距,是亟待解决的问题。
目前,VLM的主流训练方法是监督微调(SFT),即使用人工标注或AI生成的高质量数据对模型进行有监督训练。但这种方法在小模型上存在两个关键问题:
- 域外泛化能力不足 (Out-of-Domain generalization collapse):容易过拟合训练数据,在未见过的场景时性能显著下降。
- 推理能力有限 (shallow reasoning abilities):倾向于浅层模式匹配,而非真正的理解和推理。这导致模型虽能应对相似问题,但难以处理需要深度思考的复杂问题。
通过系统实验,我们发现基于强化学习的训练方法在提升模型域外泛化性方面具有独特优势。然而,在实践中我们观察到一个显著的“砖墙”(Brick Wall)现象:小规模模型在简单任务上快速进步,但在复杂任务上遇到瓶颈,甚至导致已掌握能力的退化。这种现象表现为训练过程的剧烈震荡,最终导致模型收敛到次优解。

图1. 方法动机. (a) SFT与RL方法性能对比:通过对比域内和域外性能,实验证实了强化学习方法在各类视觉任务中具有更强的OOD泛化能力。(b) "砖墙"现象分析:在小规模VLMs中观察到: 面对复杂样本时出现训练不稳定性, 模型最终收敛到次优解。我们提出的课程强化学习方法采用难度感知的奖励设计,确保模型能力从基础任务到复杂推理任务的稳步提升。
为突破这一瓶颈,我们从课程学习(Curriculum Learning,CL)中汲取灵感。课程学习是一种将模型逐步暴露于递增复杂任务的训练策略。我们提出了课程式强化学习后训练范式(Curr-ReFT),确保模型能力从基础任务到复杂推理任务的稳步提升。这一创新方法能够帮助小型VLMs突破性能瓶颈,在保持部署友好性的同时,实现与大规模模型相媲美的推理能力。
03 具体方法

图2. 所提出的Curr-ReFT后训练范式整体框架。Curr-ReFT包含两个连续的训练阶段:1. 课程强化学习:通过与任务复杂度匹配的奖励机制,逐步提升任务难度。2. 基于拒绝采样的自我改进: 维持LLM模型的基础能力。
Curr-ReFT包含两个连续的训练阶段:
- 课程强化学习:通过与任务复杂度匹配的奖励机制,逐步提升强化学习任务难度。
- 基于拒绝采样的自我改进:维持LLM模型的基础能力。

图3. 训练数据组织架构图. (a) 课程强化学习的三阶段渐进式响应格式示例. 展示了任务从简单到困难的递进过程, 呈现不同阶段的响应格式变化. (b) 拒绝采样SFT阶段使用的数据来源分布
Stage1:课程强化学习 (Curriculum Reinforcement Learning)
课程学习(Curriculum Learning,CL)作为一种教学式训练策略,其核心思想是让模型循序渐进地接触复杂度递增的任务。针对强化学习中普遍存在的训练不稳定性和收敛性问题,我们创新性地将课程学习与GRPO相结合,突破了传统基于样本难度评估的局限,转而关注任务层面的渐进式学习。本研究的关键创新点在于设计了难度感知的奖励机制,该机制与任务的自然进阶路径相匹配,具体包括三个递进阶段:
- 二元决策阶段 (Binary Decision)
- 多项选择阶段 (Multiple Choice)
- 开放式回答阶段 (Open-ended Response)
这一课程强化学习(Curr-RL)框架通过精确校准任务复杂度对应的奖励机制,成功实现了视觉感知和数学推理任务的稳定优化过程。(具体reward设计见论文)
Stage2:拒绝采样自我增强 (Rejected Sample based Self-improvement)
数据准备过程涉及对综合数据集的系统采样。我们使用GPT-4-O作为奖励模型,从多个维度评估生成的响应,评估标准包括:准确性、逻辑一致性、格式规范性、语言流畅度。所有响应在0-100分范围内进行量化评估。得分超过85分的响应及其对应的问题会被纳入增强数据集。最终整理的数据集包含1,520个高质量样本,涵盖多个领域:数学、科学、通用场景的通用知识。数据分布如下:
1. 数学领域(共700条数据)
- 多模态数据(300条):
- Geometry3K_MathV360K (100条)
- Geo170k_qa (100条)
- Geomverse (100条)
- 纯文本数据:
- SK1.1数学题 (400条)
2. 科学领域(共320条数据)
- 多模态数据(220条):
- Scienceqa_cauldron (100条)
- Scienceqa_nona_context (120条)
- 纯文本数据:
- SK1.1科学题 (100条)
3. 通识领域(共500条多模态数据)
- Illava_cot_100k (300条)
- Visual7w (100条)
- VSR (100条)
实验结果
为了验证我们的模型在多模态数学推理任务中的表现,我们进行了广泛的实验,并在多个基准数据集上进行了测试。以下是实验部分的详细介绍:
4.1 实验设置
4.1.1 Visual Datasets
我们构建了一个全面的评估框架,涵盖视觉检测、视觉分类和多模态数学推理三个主要任务,以评估强化学习对视觉语言模型的有效性和泛化能力。
- 视觉检测:使用RefCOCO和RefGta数据集。
- 视觉分类:采用RefCOCO、RefCOCOg和Pascal-VOC数据集。
- 多模态数学推理:结合Math360K、Geo170K和CLEVER-70k-Counting数据集。
4.1.2 Benchmarks
我们在多个权威基准数据集上评估了模型的表现,包括:
- MathVisa:综合数学基准。
- MATH:高中竞赛级别数学问题。
- AI2D:小学科学图表及相关问题。
- MMVet和MMBench:复杂推理和多模态能力评估。
4.2 实验结果
我们展示了使用课程强化微调(Curr-ReFT)训练的模型在多模态任务上的显著性能提升,特别是在跨领域泛化能力和复杂推理任务方面。与传统的监督微调(SFT)方法相比,我们的方法不仅提高了准确率,还增强了模型处理未见过的数据的能力。以下表格展示了不同训练方法在域内和域外数据集上的性能对比。具体包括传统监督微调(SFT)和强化学习(RL)两种方法:

通过这些实验结果可以看出,强化学习训练(RL)方法在提高模型的域内和域外表现方面具有显著优势,尤其是在处理未见过的数据时,能够保持较高的准确率。
Viual Datasets上不同方法模型的测试结果如下:

为了验证Curr-ReFT的泛化性以及使用后不会削弱模型在其他领域的推理能力,我们在多模态领域多个Benchmark数据集上进行验证。Benchmarks上不同方法模型的测试结果如下(评测集裁判模型使用GPT-3.5):

总结
本研究聚焦于提升小规模视觉-语言模型(VLMs)在推理能力和域外(OOD)泛化性能两个关键方面的表现。通过实证研究,我们发现强化学习不仅能有效提升模型的推理能力,更在视觉任务中展现出超出预期的泛化性能提升。
基于这一重要发现,我们提出了创新性的课程式强化学习微调(Curr-ReFT)后训练范式。该方法巧妙地融合了渐进式课程学习与拒绝采样策略。Curr-ReFT通过两个关键机制:
- 任务复杂度的渐进式提升
- 高质量样本的选择性学习
成功实现了模型性能的稳定优化,同时有效维持了推理能力和泛化能力的均衡发展。
#RelightVid
IC-Light的视频版本来了:强光动态环境下的视频光照编辑神器
大家还记得那个 ICLR 2025 首次满分接收、彻底颠覆静态图像光照编辑的工作 IC-Light 吗?
今天,来自复旦大学、上海交通大学、浙江大学、斯坦福大学等机构的学者们正式宣布:IC-Light 的视频版本来了——RelightVid!
- 论文标题:RelightVid: Temporal-Consistent Diffusion Model for Video Relighting
- 论文链接:https://arxiv.org/pdf/2501.16330
- 项目地址:https://aleafy.github.io/relightvid/
- Code: https://github.com/Aleafy/RelightVid
在视频动态环境下实现时序一致、光影真实、支持强光动态场景的高质量视频光照编辑,彻底打开下一代视频重光照的新篇章!

图 1. RelightVid 框架结构图,从背景合成、光照注入到最终编辑,全面支持高质量光影一致性视频重光照
RelightVid 有何突破?
在 Relight Your Images 静态图像版本中,作者提出了通过条件控制方式实现灵活光照风格迁移的革命性方法。而这次,团队将目光瞄准更具挑战性的目标——视频光照编辑。
这不再是逐帧操作,而是要在真实的视频中保持光照随时间连续变化的时序一致性,还原自然真实的物理光影逻辑。
RelightVid 首次实现了在强动态光照条件下的长视频编辑,不仅支持文字描述的光照风格控制,还兼容参考视频背景/光源图像。最终输出的视频在保持内容不变的同时,实现了光照的统一重构和流畅过渡。
从图像到视频:光照编辑的质变飞跃

图 2. RelightVid 框架结构图,从背景合成、光照注入到最终编辑,全面支持高质量光影一致性视频重光照
RelightVid 展示了如何在图像层面实现任意光照控制,但当场景换成视频后,新的挑战扑面而来:
时间一致性:逐帧编辑很容易出现光影跳变、边界闪烁等问题
强光源建模:KTV、舞台灯、城市霓虹灯等高动态强光环境,传统方法无法真实还原
细节保持 vs 光照迁移的平衡:需要在保持原视频内容的前提下,引入合理的光照变化
为此,RelightVid 提出了 Reference-to-Video 光照注入框架,结合合成背景生成和双分支前景编辑网络,构建全新的视频级光照编辑流程。
技术亮点抢先看!
Dual-Branch Architecture:将前景和背景解耦处理,前景保持结构稳定,背景灵活响应光照变化,从而有效避免伪影和失真。
Reference-based Illumination Injection:支持通过静态图像、描述文字、甚至参考视频,实现多模态光照风格控制。
Temporal-aware Editing Strategy:引入时序建模模块,对帧间关系进行学习,使得输出视频在光照变化中保持连贯性和自然性。
支持真实+合成混合输入:Relight a Video 不依赖于实验室条件构建的数据集,而是能从真实视频+合成参考中学习强泛化能力。
实验结果震撼全场!
RelightVid 在多个真实+合成视频数据集上进行了系统测试,覆盖了城市夜景、KTV 舞台、户外灯光等多个强动态光源环境。


图 3. RelightVid 实验效果
通过与图像逐帧方法、video editing 等 baseline 方法比较,RelightVid 在保持视频内容连贯性的同时,实现了更加真实、自然的光照变化。
图 3 右图展示了在城市夜景场景下,输入原视频、参考霓虹灯图像后,Relight a Video 能够精确模拟出霓虹反光、水面投影等复杂光影现象,视觉效果极为震撼。
构建全新光照视频编辑基准数据集!

图 4 LightAtlas 数据集构建过程
为了支持这一任务的评估,作者构建了一个融合真实与合成场景的高质量 benchmark,LightAtlas 包括:
- 多种类型的参考光源(图像/视频/文本)
- 超过百段来自真实世界场景的动态视频
- 长达 10 秒以上的高时序连续性
- 并配套设计了光照质量、内容保持度、时间稳定性等多维度指标,用于全面评估视频 relighting 效果。
Relight a Video 正式开源!快来一起 relight the world!
Relight a Video 已全面开源,项目主页提供了详细的模型结构、推理脚本、demo 视频和数据下载地址。如果你对图像/视频编辑、3D 重建、视觉物理建模、生成模型感兴趣,Relight a Video 是你绝不能错过的方向!
#PRIMEDrive-CoT
驾驶场景中不确定性感知目标交互的全新思维链框架~PRIMEDrive-CoT
- 论文标题:PRIMEDrive-CoT: A Precognitive Chain-of-Thought Framework for Uncertainty-Aware Object Interaction in Driving Scene Scenario
- 论文链接:https://arxiv.org/abs/2504.05908

核心创新点:
1. 贝叶斯图神经网络(BGNN)驱动的不确定性建模
- 首次将BGNN应用于驾驶场景的物体交互推理,通过概率图结构建模车辆-行人、车辆-车辆间的动态交互。结合Shannon熵与偏航角偏差量化检测不确定性,并引入接近度感知风险指标 (基于指数衰减函数),实现对潜在威胁的优先级排序。
2. 可解释的链式思维(CoT)推理机制
- 通过分阶段的CoT模块生成结构化解析(如"减速因行人接近与前车急刹"),同步融合Grad-CAM可视化注意力图,显式关联决策依据与多模态输入(LiDAR点云与RGB图像),确保黑箱模型的透明性。
3. 多模态特征增强与轻量化部署
- 采用改进的MVX-Net架构实现LiDAR点云体素化与多视角RGB特征融合,在保持3D检测精度(IoU 78%)的同时,通过RGB验证机制降低误检率。推理速度达18.7 FPS(单RTX 3090),满足实时性需求。
MIAT
- 论文标题:MIAT: Maneuver-Intention-Aware Transformer for Spatio-Temporal Trajectory Prediction
- 论文链接:https://arxiv.org/abs/2504.05059

核心创新点:
1. 机动意图感知Transformer架构(MIAT)
- 提出Transformer-based时空交互建模 ,替代传统LSTM,通过自注意力机制(self-attention)捕捉车辆轨迹的长程时空依赖,解决LSTM在长序列处理中的梯度消失与效率瓶颈。
2. 多模态机动意图融合机制
- 引入六类驾驶意图分类 (横向:车道保持、左/右换道;纵向:加速、减速、匀速),通过动态意图概率分布 (softmax分类)与时空特征融合(soft attention),实现意图感知的轨迹预测。
3. 可调节损失加权策略
- 设计联合优化目标函数(L = + ),通过控制机动损失权重(λ)平衡短期精度与长期预测鲁棒性。实验表明,高权重(如200x)显著提升长时域(5秒)预测精度(+11.1%),验证意图建模对复杂行为长期演化的关键作用。
4. 动态交互依赖建模(DID模块)
- 采用多头自注意力 捕捉车辆间交互的时序相关性,突破传统方法对静态交互假设的局限,动态建模邻车影响随时间的变化。
5. 高效并行计算优化
- 利用Transformer的并行特性,结合GPU加速,实现实时轨迹预测 (50Hz以上),满足自动驾驶系统的低延迟需求。
DDT
- 论文标题:DDT: Decoupled Diffusion Transformer
- 论文链接:https://arxiv.org/abs/2504.05741

核心创新点:
1. 解耦架构设计
- 采用双模块分工机制 :条件编码器(Condition Encoder)通过自监督对齐预训练视觉特征(REPAlign),专注提取低频语义信息;速度解码器(Velocity Decoder)基于编码器生成的自条件特征(self-condition),高效解码高频细节。该设计突破了传统扩散Transformer单模块处理全频段信息的局限性,在ImageNet 256×256和512×512数据集上分别实现1.31 FID(256 epochs)和 1.28 FID(500K steps)的SOTA性能,训练效率提升4倍。
2. 推理加速策略
- 利用编码器特征的时序一致性,提出统计动态规划算法 优化自条件特征共享策略。通过构建相似性矩阵并求解最小路径和问题,在保证生成质量的前提下,实现相邻去噪步骤间编码器计算的动态复用(如87%共享率下FID仅上升0.09),显著降低推理复杂度。
3. 架构扩展性突破
- 发现编码器容量与模型性能的强相关性,提出非对称层分配原则 (如DDT-XL/2采用22层编码器+6层解码器),验证了大规模模型下"强编码-轻解码"架构的优越性。结合改进的RoPE位置编码与RMSNorm等技术,进一步优化高频重建能力。
Pedestrian-Aware Motion Planning
- 论文标题:Pedestrian-Aware Motion Planning for Autonomous Driving in Complex Urban Scenarios
- 论文链接:https://arxiv.org/abs/2504.01409
- 代码:https://github.com/TUM-AVS/PedestrianAwareMotionPlanning

核心创新点:
1. 社会力模型驱动的行人仿真框架
- 提出基于改进社会力模型(Social Force Model)的行人行为仿真模块,集成于CommonRoad环境,首次实现对城市结构化场景(人行道/斑马线)的细粒度建模。通过离线值迭代生成行人路径策略,动态响应车辆交互(如避让高速车辆),解决了传统仿真中行人行为僵化及局部极小值问题。
2. 风险-伤害联合评估的运动规划算法
- 开发风险感知运动规划器,创新性地融合碰撞概率(Collision Probability)与伤害值(Harm Metric)构建风险评估框架。采用逻辑回归模型量化MAIS3+级伤害概率,并基于Maximin原则筛选轨迹,突破传统仅依赖碰撞概率的局限,有效缓解"机器人冻结"问题。
3. 车辆-行人耦合预测机制
- 行人运动预测采用常速模型结合车辆预测的BND(Bivariate Normal Distribution)不确定性建模,车辆端集成Wale-Net预测动态障碍物轨迹。通过蒙特卡洛采样与解析法混合计算碰撞概率,提升复杂交互场景的决策鲁棒性。
4. 开源验证体系构建
- 首次公开行人-车辆耦合仿真代码库(基于CommonRoad扩展),包含可复现的行人策略生成器与风险评估模块,为自动驾驶在密集人群场景的研究提供标准化测试基准。
强化学习运动规划综述
- 论文标题:A Survey of Reinforcement Learning-Based Motion Planning for Autonomous Driving: Lessons Learned from a Driving Task Perspective
- 论文链接:https://arxiv.org/abs/2503.23650

核心创新点:
1. 安全增强的强化学习框架
- 提出对抗性约束RL与控制屏障函数(CBF)融合方法,通过动态不确定环境下的鲁棒性约束优化,解决自动驾驶中的安全临界场景(如紧急避撞)
- 基于模型不确定性的风险敏感型算法,采用分布鲁棒策略优化(DRPO)实现碰撞概率的显式约束
2. 多智能体与分层强化学习架构
- 构建分层决策架构,将驾驶任务解耦为策略层(宏观行为决策)与执行层(轨迹规划),通过Option框架实现层次化策略优化
- 提出多智能体深度RL(MADRL)协同机制,采用注意力机制建模交通参与者交互,解决多车博弈场景下的策略收敛性问题
3. 持续学习与知识迁移方法
- 开发基于弹性权重固化(EWC)的持续RL框架,通过参数重要性评估缓解灾难性遗忘,实现跨场景策略迁移
- 提出混合专家系统(MoE)与元学习结合的元策略迁移方法,在匝道汇入等动态场景中提升策略适应效率
4. 基于模仿学习的高效探索策略
- 创新性结合专家示范与好奇心驱动机制,采用优先经验回放(PER)与逆RL联合训练,将人类驾驶数据的利用率提升40%
- 设计基于参数化动作空间的深度Q网络,通过混合离散-连续动作建模解决传统方法在复杂场景中的维度爆炸问题
5. 泛化能力增强技术
- 提出元强化学习与因果推理融合框架,通过干预变量建模提升策略在未见过的交通场景中的适应性
- 开发基于神经过程(Neural Process)的上下文感知RL,实现动态环境特征的快速推理与策略调整
Vision-Language Model Predictive Control
- 论文标题:Vision-Language Model Predictive Control for Manipulation Planning and Trajectory Generation
- 论文链接:https://arxiv.org/abs/2504.05225

核心创新点:
1. 提出视觉-语言模型预测控制(VLMPC)框架
- 将视觉-语言模型(VLM)与模型预测控制(MPC)相结合,通过VLM的感知能力和MPC的前瞻性规划能力,解决了传统MPC在复杂、非结构化场景中缺乏环境感知的局限性。VLMPC能够基于目标图像或语言指令生成候选动作序列,并利用视频预测模型模拟未来状态,从而实现精准的机器人操作规划。
2. 设计条件动作采样模块和层次化成本函数
- 条件动作采样:通过VLM生成基于视觉观察和任务目标的动作采样分布,避免了手动设计动作原语,提升了动作生成的灵活性和适应性。
- 层次化成本函数:结合像素级成本(评估视频预测与目标图像的相似性)和知识级成本(通过VLM动态识别子目标和干扰物),实现了从粗到细的多层级动作评估,显著提高了复杂任务的规划能力。
3. 提出轨迹优化的增强版框架(Traj-VLMPC)
- Traj-VLMPC通过引入高斯混合模型(GMM)生成3D运动轨迹,并结合体素化3D价值图进行高效轨迹评估。相比于逐帧动作采样的VLMPC,Traj-VLMPC显著降低了计算复杂度,同时增强了轨迹规划的稳定性和避障能力,特别适用于长时域任务和实时应用。
4. 实验验证与性能提升
- 在模拟和真实场景中验证了VLMPC和Traj-VLMPC的有效性,证明其在多种操作任务中优于现有方法。
- Traj-VLMPC在长时域任务中表现出更高的控制稳定性和执行速度,特别是在涉及多个子目标和干扰物的复杂任务中表现突出。

















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









