







论文阅读:GaussianBeV : 3D Gaussian Representation meets Perception Models for BeV Segmentation
Abstract
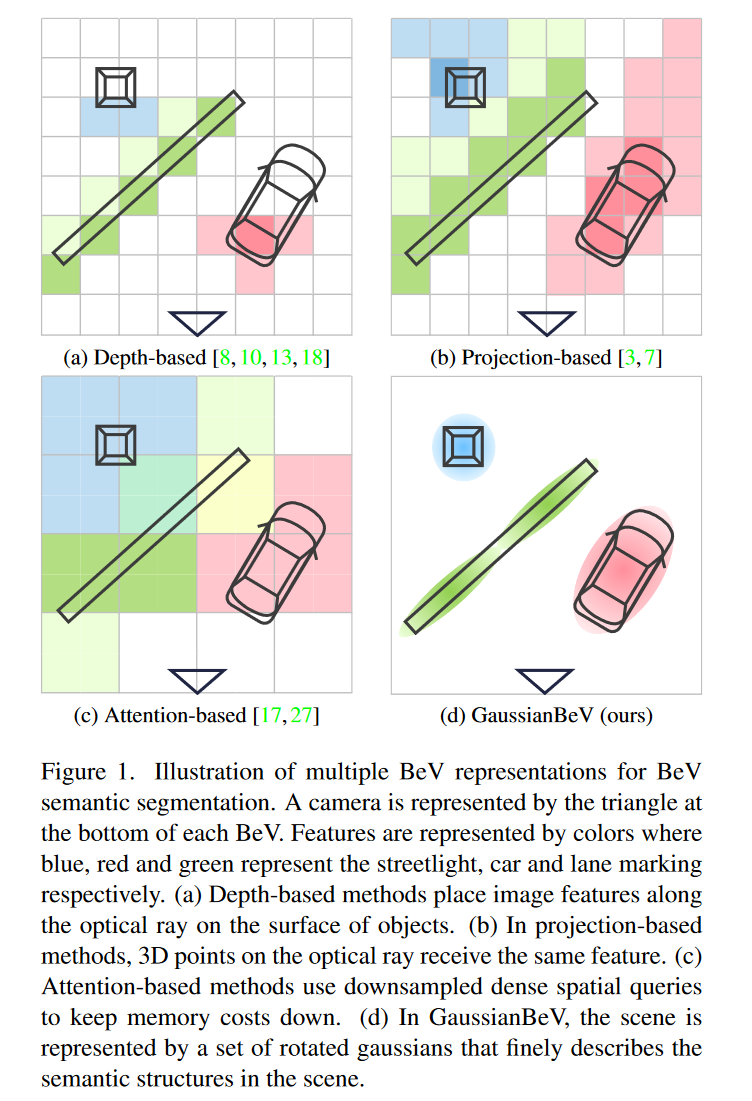
鸟眼图(BEV)表示法被广泛用于从多视角摄像机图像中进行3D感知。它允许将不同摄像头的特征合并到一个公共空间,提供3D场景的统一表示。关键组件是视图转换器,它将图像视图转换为Bev。然而,基于几何或交叉注意的实际视图变换方法不能提供场景的足够详细的表示,因为它们使用3D空间的子采样,该子采样对于环境的精细结构的建模是非最佳的。在本文中,我们提出了一种新的将图像特征转换为BEV的方法–GaussianBeV,该方法通过在3D空间中定位和定位的一组3D GaussianBeV来精细地表示场景。然后,通过适应基于高斯飞溅的3D表示渲染的最新进展,该表示被飞溅以产生BEV特征图[12]。GaussianBeV是第一个在线使用这种3D高斯建模和3D场景渲染过程的方法,即不在特定场景上进行优化,直接集成到用于Bev场景理解的单个阶段模型中。实验表明,所提出的表示方法是高效的,并使GaussianBeV成为nuScenes数据集上Bev语义分割任务的最新研究成果[2]。
3. GaussianBeV
3.1. Overview
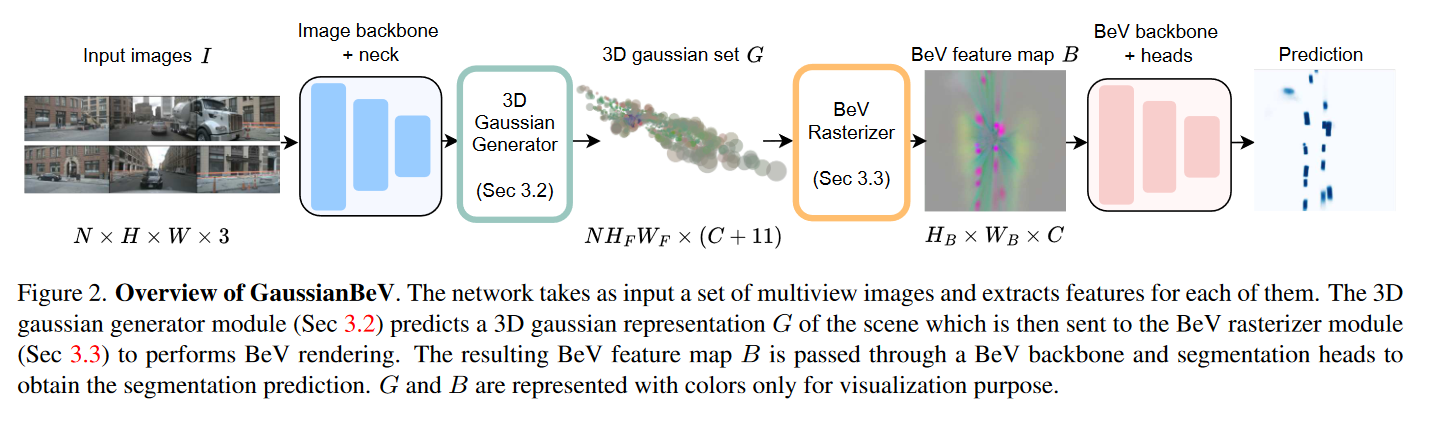
图2展示了GaussianBeV的概览。该模型将一组多视图图像作为输入 I ∈ R N × H × W × 3 I \in \mathbb{R}^{N\times H \times W \times 3} I∈RN×H×W×3, N N N 是摄像机的数量,$ H$ 和 W W W 是图像的维度。这些图像顺序通过四个模块,指导BeV分割。
第一模块使用图像主干和颈部提取图像特征,获得特征地图 F ∈ R N × H F × W F × C F F\in \mathbb{R}^{N\times H_{F}\times W_{F}\times C_{F}} F∈RN×HF×WF×CF,其中 C F C_F CF 为通道数, H F H_F HF 和 W F W_F WF 为特征地图的维度。
第二个模块是3D高斯生成器(第3.2节),它为特征地图中的每个像素预测世界参考系中相应高斯的参数。该模块的输出是一组3D高斯 G ∈ R N H F W F × ( C + 11 ) G \in \mathbb{R}^{NH_{F}W_{F}\times(C+11)} G∈RNHFWF×(C+11), C C C 是与每个高斯相关的嵌入的通道数。更具体地说, G G G包含以下参数:位置 P ∈ R N H F W F × 3 P\in\mathbb{R}^{NH_{F}W_{F}\times3} P∈RNHFWF×3、标度 P ∈ R N H F W F × 3 P\in\mathbb{R}^{NH_{F}W_{F}\times3} P∈RNHFWF×3、单位四元数旋转 Q ∈ R N H F W F × 4 Q \in \mathbb{R}^{NH_{F}W_{F}\times4} Q∈RNHFWF×4 、不透明度 O ∈ R N H F W F × 1 O~\in~\mathbb{R}^{NH_{F}W_{F}\times1} O ∈ RNHFWF×1和嵌入 E ∈ R N H F W F × C E \in \mathbb{R}^{NH_{F}W_{F}\times C} E∈RNHFWF×C。首先,该模块在其自己的相机参考系中为每个相机预测一组3D高斯分布。接下来,应用相机外部参数将相机的3D高斯变换到世界参考系,最终将所有高斯串接到单个集合 G G G 中。
第三个模块是BeV网格化器(第3.3节),它执行3D高斯集 G G G 的BeV渲染,以产生BeV特征地图 B ∈ R H B × W B × C {B}\in\mathbb{R}^{H_{B}\times{W}_{B}\times C} B∈RHB×WB×C, H B H_B HB 和 W B W_B WB 是BeV地图的维度。
最后,在最后一个模块中,BeV主干和分割头顺序应用于BeV特征,以提供最终的预测。
3.2. 3D Gaussian generator
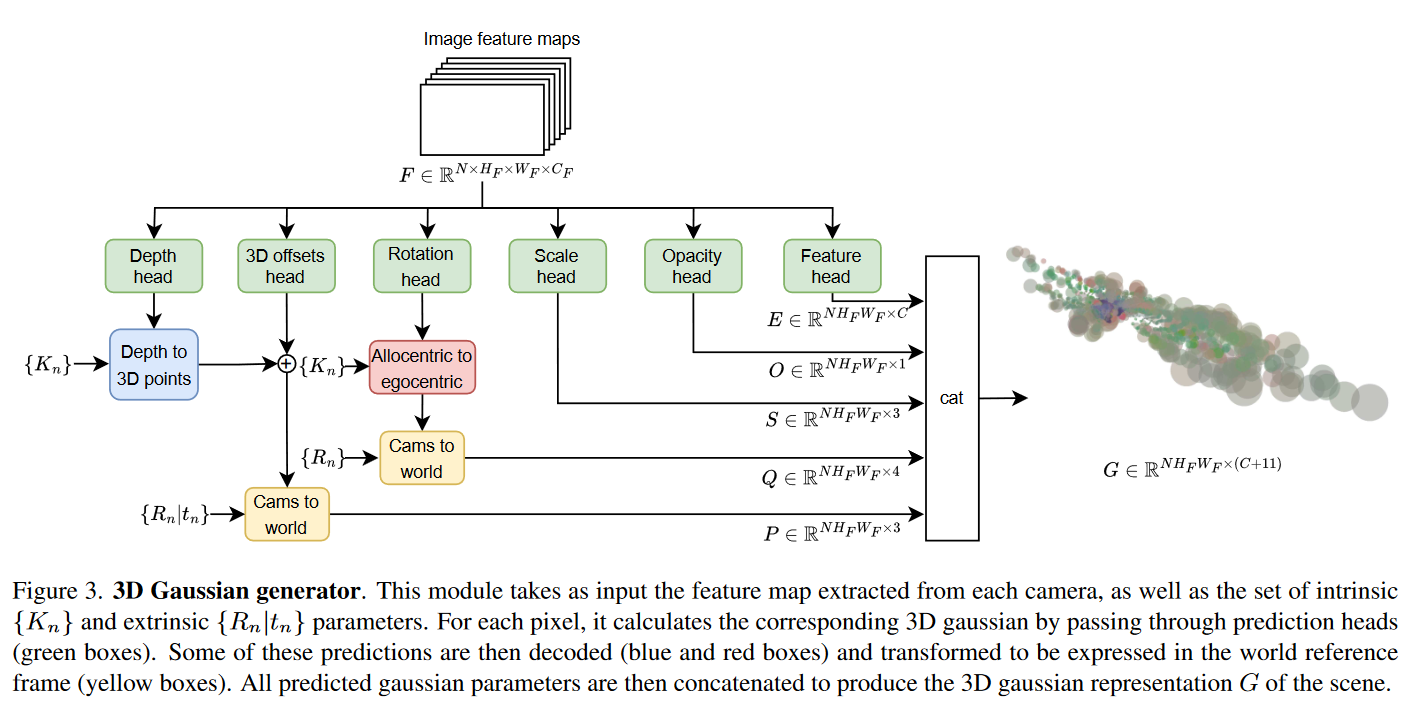
给定输入特征地图 F F F ,3D高斯生成器使用多个预测头来预测场景的3D高斯表示。图3说明了它如何在特征地图上操作。
Gaussian centers. 场景中高斯的3D位置通过应用于 F F F 的深度头和3D偏置头估计。第一个预测3D中心沿着光线的初始位置。第二个方法通过添加小的3D位移来细化这个3D位置,通过不沿着光线冻结高斯,为高斯的定位提供更大的灵活性。(giving more flexibility in the positioning of gaussians by not freezing them along the optical rays.)
更准确地说,对于具有坐标
(
u
n
,
i
,
v
n
,
i
)
(u_{n,i},v_{n,i})
(un,i,vn,i) 的相机
n
n
n 的特征地图中的像素
i
i
i ,深度头预测差异
d
n
,
i
∈
[
0
,
1
]
d_{n,i}\in[0,1]
dn,i∈[0,1] ,正如处理单目深度图估计的先前作品中一样[6,26]。为了补偿从一个相机到另一个相机的焦距多样性对深度预测的影响,如[23]中提出的,在参考焦距
f
f
f 中预测差异高达一定比例因子。知道与摄像机
n
n
n 相关的真实焦距
f
n
f_n
fn ,然后对度量深度
z
n
,
i
z_{n,i}
zn,i 进行如下解码:
z
n
,
i
=
f
n
f
(
1
d
n
,
i
−
1
)
z_{n,i}=\frac{f_n}f(\frac1{d_{n,i}}-1)
zn,i=ffn(dn,i1−1)
然后使用第
n
n
n 个相机的内参矩阵
K
n
K_n
Kn 来推导相机参考系中相应的3D点
p
n
,
i
c
p^c_{n,i}
pn,ic:
p
n
,
i
c
=
K
n
−
1
[
z
n
,
i
u
n
,
i
z
n
,
i
v
n
,
i
z
n
,
i
]
p_{n,i}^c=K_n^{-1}\begin{bmatrix}z_{n,i}u_{n,i}\\z_{n,i}v_{n,i}\\z_{n,i}\end{bmatrix}
pn,ic=Kn−1
zn,iun,izn,ivn,izn,i
产生的3D点被限制为沿着穿过所考虑像素的光线。(The resulting 3D points are constrained to lie along the optical ray passing through the pixel under consideration.)由于这种限制,他们的定位不一定是最佳的。为了克服这个问题,我们建议使用3D补偿预测头。它的目标是提供小位移
Δ
n
,
i
=
(
Δ
x
n
,
i
,
Δ
y
n
,
i
,
Δ
z
n
,
i
)
T
\Delta_{n,i}=(\Delta x_{n,i},\Delta y_{n,i},\Delta z_{n,i})^T
Δn,i=(Δxn,i,Δyn,i,Δzn,i)T ,应用于高斯
p
n
,
i
c
p_{n,i}^{c}
pn,ic 的3D中心,以细化其在所有三个方向上的位置。细化的3D点
p
n
,
i
c
p_{n,i}^{c}
pn,ic 简单地通过以下方式获得:
p
‾
n
,
i
c
=
p
n
,
i
c
+
Δ
n
,
i
\overline{p}_{n,i}^c=p_{n,i}^c+\Delta_{n,i}
pn,ic=pn,ic+Δn,i
在此阶段,为每个相机计算的3D高斯中心在相应的相机参考系中表达。为了在世界参考系中表达这些点,外部参数矩阵
[
R
n
∣
t
n
]
[R_n|t_n]
[Rn∣tn] 被应用,允许相机到世界的转变:
p
n
,
i
w
=
[
R
n
∣
t
n
]
p
‾
n
,
i
c
p_{n,i}^w=[R_n|t_n]\overline{p}_{n,i}^c
pn,iw=[Rn∣tn]pn,ic
结果是高斯中心集
P
=
{
p
n
,
i
w
}
∈
R
N
H
F
W
F
×
3
P = \{p_{n,i}^w\} \in \mathbb{R}^{NH_FW_F\times3}
P={pn,iw}∈RNHFWF×3。
Gaussian rotations. 场景中高斯的3D旋转通过应用于 F F F 的旋转头来估计。对于相机 n n n 的特征地图中的给定像素,它以单位四元数 q n , i a q_{n,i}^a qn,ia 的形式输出异心旋转(allocentric rotation)。像素的异心旋转对应于相对于穿过它的3D光线的旋转。这种模型化使旋转头更容易学习,因为它不知道与它正在处理的像素对应的光线。例如,放置在场景中两个不同位置并且在相机参考系中具有不同绝对(自我中心)旋转的两个对象在图像中可能具有相同的外观。在这种情况下,旋转头预测的异心旋转将相同。然后使用相机的内在参数来检索自我中心旋转信息。
为此目的,计算四元数
q
n
,
i
q_{n,i}
qn,i,其代表穿过相机
n
n
n 的像素
i
i
i 的光线与轴
[
0
,
0
,
1
]
T
[0,0,1]^T
[0,0,1]T 之间的旋转。然后通过以下方式恢复代表相机参考系中自我中心旋转的四元数
q
n
,
i
e
q_{n,i}^e
qn,ie :
q
n
,
i
e
=
q
n
,
i
q
n
,
i
a
q_{n,i}^e=q_{n,i}q_{n,i}^a
qn,ie=qn,iqn,ia
最后,对于高斯中心,使用
q
R
n
q_{R_n}
qRn 计算代表高斯在世界参考系中旋转的四元数
q
n
,
i
w
q_{n,i}^w
qn,iw ,该四元数对相机
n
n
n 的相机到世界旋转进行建模:
q
n
,
i
w
=
q
R
n
q
n
,
i
e
q_{n,i}^w=q_{R_n}q_{n,i}^e
qn,iw=qRnqn,ie
由此计算出的四元数形成高斯旋转集
Q
=
{
q
n
,
i
w
}
∈
R
N
H
F
W
F
×
4
Q=\left\{q_{n,i}^w\right\}\in\mathbb{R}^{NH_FW_F\times4}
Q={qn,iw}∈RNHFWF×4。
Gaussian scales, opacities and features. 最后三个高斯参数不取决于光学属性和相机定位,而是编码语义属性。因此,三个头部简单地用于预测BeV网格化模块渲染高斯集 G G G 所需的集 S S S、 O O O 和 E E E。
3.3. BeV rasterizer(看不懂 感觉藏东西了)
BeV网格化模块用于从3D高斯生成器预测的高斯 G G G 集合中获得BeV特征地图 B ∈ R H B × W B × C B \in \mathbb{R}^{H_B\times W_B\times C} B∈RHB×WB×C 。为此,高斯飞溅[12]中提出的可微网格化过程已被改编来执行此渲染。第一种适应已经在其他离线语义重建工作中提出[19],包括渲染 C C C维特征而不是颜色。在我们的例子中,这会产生包含对于解决感知任务至关重要的语义特征的渲染。第二种调整涉及使用的投影类型。我们已经参数化了渲染算法,以生成正投影渲染而不是透视渲染,更适合场景的BeV表示。
3.4. GaussianBeV training
我们的模型使用[3,7,8]中使用的损失函数进行端到端训练。在这些之前的作品中,语义分割损失
L
s
e
m
L_{sem}
Lsem 定义如下:
L
s
e
m
=
λ
b
c
e
L
b
c
e
+
λ
c
t
r
L
c
t
r
+
λ
o
f
f
L
o
f
f
L_{sem}=\lambda_{bce}L_{bce}+\lambda_{ctr}L_{ctr}+\lambda_{off}L_{off}
Lsem=λbceLbce+λctrLctr+λoffLoff
L
b
c
e
L_{bce}
Lbce 是二元交叉熵损失。
L
c
t
r
L_{ctr}
Lctr 和
L
o
f
f
L_{off}
Loff分别对应中心度和抵消损失,作为辅助损失来规范训练。参数
λ
\lambda
λ 是平衡这三个损失的权重。
Gaussian regularization losses. 尽管GaussianBeV可以在上述损失的情况下进行有效训练,但添加直接作用于高斯表示的正规化函数可以提高其表示质量。特别是,训练期间增加了两次正规化损失。
首先,深度损失旨在使用LiDART在图像中投影提供的深度信息来规范高斯的位置。这种损失增加了对深度头预测的约束,以获得初始3D位置,然后通过3D偏差来细化该位置(参见第3.2节)。
z
z
z 是GT深度,
z
∗
z*
z∗是预测深度,深度损失
L
d
e
p
t
h
L_{depth}
Ldepth 定义如下:
L
d
e
p
t
h
(
z
,
z
∗
)
=
∣
l
o
g
(
z
)
−
l
o
g
(
z
∗
)
∣
L_{depth}(z,z^*)=|log(z)-log(z^*)|
Ldepth(z,z∗)=∣log(z)−log(z∗)∣
其次,早期监督损失旨在在应用BeV主干+头部之前优化高斯表示。其想法是限制BeV特征,以直接为语义分割任务提供所有必要的信息。在实践中,分段头被添加并直接连接到BeV格栅器模块的输出。早期监督损失
L
s
e
m
e
a
r
l
y
L_{sem}^{early}
Lsemearly 的定义类似于
L
s
e
m
L_{sem}
Lsem(参见等式7)。因此,总损失函数定义为:
L
=
L
s
e
m
+
L
s
e
m
e
a
r
l
y
+
λ
d
e
p
t
h
L
d
e
p
t
h
L=L_{sem}+L_{sem}^{early}+\lambda_{depth}L_{depth}
L=Lsem+Lsemearly+λdepthLdepth
第4.2节分析了这些学习策略的影响。















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









