







我自己的原文哦~ https://blog.51cto.com/whaosoft/13361345
#微调、推理与优化指南
2W6000字综述大模型核心技术:
本文2W6000字,10篇参考文献,内容涵盖了语言建模、预训练面临的挑战、量化技术、分布式训练方法,以及大语言模型的微调。此外,还讨论了参数高效微调(PEFT)技术,包括适配器、LoRA和QLoRA;介绍了提示策略、模型压缩方法(如剪枝和量化),以及各种量化技术(GPTQ、NF4、GGML)。最后,对用于减小模型大小的蒸馏和剪枝技术进行了讲解。有些内容是翻译自HuggingFace和一些论文。
1. 什么是大语言模型?
大语言模型(LLM)是非常庞大的深度学习模型,它们在大量数据上进行预训练。其底层的Transformer是一组神经网络,由具有自注意力能力的编码器和解码器组成。编码器和解码器从文本序列中提取含义,并理解其中单词和短语之间的关系。


Transformer神经网络架构允许使用非常大的模型,这些模型通常包含数千亿个参数。如此大规模的模型可以摄取大量数据,这些数据通常来自互联网,也可以来自如包含超过500亿个网页的Common Crawl,以及约有5700万页面的维基百科等来源。

2. 语言建模(LM)
语言和交流的过程可以简化为计算吗?
语言模型通过从一个或多个文本语料库中学习来生成概率。文本语料库是一种语言资源,由一种或多种语言的大量结构化文本组成。文本语料库可以包含一种或多种语言的文本,并且通常带有注释。

语言模型可以根据其在训练过程中学习到的统计模式,预测最可能跟随某个短语的单词(或多个单词)。在图中,语言模型可能会估计“天空的颜色是”这个短语后面跟着“蓝色”一词的概率为91%。
构建语言模型的最早方法之一是基于n - gram。n - gram是从给定文本样本中连续的n个项目组成的序列。在这里,模型假设序列中下一个单词的概率仅取决于前面固定数量的单词:

其中, 表示单词, 是窗口大小。

然而,n - gram语言模型在很大程度上已被神经语言模型所取代。神经语言模型基于神经网络,这是一种受生物神经网络启发的计算系统。这些模型利用单词的连续表示或嵌入来进行预测:

神经网络将单词表示为权重的非线性组合。因此,它可以避免语言建模中的维度灾难问题。已经有几种神经网络架构被提出用于语言建模。

3. 基础模型和大语言模型
这与自然语言处理(NLP)应用程序早期的方法有很大不同,早期是训练专门的语言模型来执行特定任务。相反,研究人员在大语言模型中观察到了许多涌现能力,这些能力是模型从未接受过训练的。
例如,大语言模型已被证明能够执行多步算术运算、解乱序单词的字母,以及识别口语中的冒犯性内容。最近,基于OpenAPI的GPT系列大语言模型构建的流行聊天机器人ChatGPT,通过了美国医学执照考试等专业考试。
基础模型通常是指在广泛数据上进行训练的任何模型,它可以适应各种下游任务。这些模型通常使用深度神经网络创建,并使用自监督学习在大量未标记数据上进行训练。

在训练过程中,从语料库中提取文本序列并进行截断。语言模型计算缺失单词的概率,然后通过基于梯度下降的优化机制对这些概率进行微调,并反馈给模型以匹配真实情况。这个过程在整个文本语料库上重复进行。
尽管如此,大语言模型通常在与语言相关的数据(如文本)上进行训练。而基础模型通常在多模态数据(文本、图像、音频等的混合)上进行训练。更重要的是,基础模型旨在作为更特定任务的基础或基石:

基础模型通常通过进一步训练进行微调,以完成各种下游认知任务。微调是指采用预训练的语言模型,并使用特定数据针对不同但相关的任务进行训练的过程。这个过程也被称为迁移学习。
4. 大语言模型的架构
早期的大语言模型大多是使用带有长短期记忆网络(LSTM)和门控循环单元(GRU)的循环神经网络(RNN)模型创建的。然而,它们面临挑战,主要是在大规模执行NLP任务方面。但这正是大语言模型预期要发挥作用的领域。这就促使了Transformer的诞生!
一开始,大语言模型主要是使用自监督学习算法创建的。自监督学习是指处理未标记数据以获得有用的表示,这些表示可以帮助下游的学习任务。
通常,自监督学习算法使用基于人工神经网络(ANN)的模型。我们可以使用几种架构来创建人工神经网络,但大语言模型中使用最广泛的架构是循环神经网络(RNN)。

RNN可以利用其内部状态来处理可变长度的输入序列。RNN具有长期记忆和短期记忆。RNN有一些变体,如长短期记忆网络(LSTM)和门控循环单元(GRU)。
使用LSTM单元的RNN训练速度非常慢。此外,对于这样的架构,我们需要按顺序或串行地输入数据。这就无法进行并行化处理,也无法利用可用的处理器核心。
或者,使用GRU的RNN模型训练速度更快,但在更大的数据集上表现较差。尽管如此,在很长一段时间里,LSTM和GRU仍然是构建复杂NLP系统的首选。然而,这样的模型也存在梯度消失问题:

当反向传播多层时,梯度可能会变得非常小,导致训练困难。

RNN的一些问题通过在其架构中添加注意力机制得到了部分解决。在像LSTM这样的循环架构中,可以传播的信息量是有限的,并且保留信息的窗口较短。
然而,有了注意力机制,这个信息窗口可以显著增加。注意力是一种增强输入数据某些部分,同时削弱其他部分的技术。其背后的动机是网络应该更多地关注数据的重要部分:

其中, 是注意力权重,表示对每个输入部分的关注程度。

注意力和自注意力之间有一个微妙的区别,但它们的动机是相同的。注意力机制是指关注另一个序列不同部分的能力,而自注意力是指关注当前序列不同部分的能力。
自注意力允许模型访问来自任何输入序列元素的信息。在NLP应用中,这提供了关于远距离标记的相关信息。因此,模型可以捕获整个序列中的依赖关系,而无需固定或滑动窗口。
带有注意力机制的RNN模型在性能上有了显著提升。然而,循环模型本质上很难扩展。但是,自注意力机制很快被证明非常强大,以至于它甚至不需要循环顺序处理。
2017年,谷歌大脑团队推出的Transformer可能是大语言模型历史上最重要的转折点之一。Transformer是一种深度学习模型,它采用自注意力机制,并一次性处理整个输入:


与早期基于RNN的模型相比,Transformer有一个重大变化,即它没有循环结构。在有足够训练数据的情况下,Transformer架构中的注意力机制本身就可以与带有注意力机制的RNN模型相媲美。
使用Transformer模型的另一个显著优势是它们具有更高的并行化程度,并且需要的训练时间大大减少。这正是我们利用可用资源在大量基于文本的数据上构建大语言模型所需要的优势。
许多基于人工神经网络的自然语言处理模型都是使用编码器 - 解码器架构构建的。例如,seq2seq是谷歌最初开发的一系列算法。它通过使用带有LSTM或GRU的RNN将一个序列转换为另一个序列。
最初的Transformer模型也使用了编码器 - 解码器架构。编码器由编码层组成,这些层逐层迭代处理输入。解码器由解码层组成,对编码器的输出进行同样的处理:

每个编码器层的功能是生成编码,其中包含关于输入中哪些部分相互相关的信息。输出编码随后作为输入传递给下一个编码器。每个编码器由一个自注意力机制和一个前馈神经网络组成。
此外,每个解码器层获取所有编码,并利用其中包含的上下文信息生成输出序列。与编码器一样,每个解码器由一个自注意力机制、一个对编码的注意力机制和一个前馈神经网络组成。
5. 预训练
在这个阶段,模型以自监督的方式在大量非结构化文本数据集上进行预训练。预训练的主要挑战是计算成本。
存储10亿参数模型所需的GPU内存:
- 1个参数 -> 4字节(32位浮点数)
- 10亿参数 -> 4×10^9 字节 = 4GB
- 存储10亿参数模型所需的GPU内存 = 4GB(32位全精度)
让我们计算训练10亿参数模型所需的内存:
- 模型参数
- 梯度
- ADAM优化器(2个状态)
- 激活值和临时内存(大小可变)
-> 4字节参数 + 每个参数额外20字节
所以,训练所需的内存大约是存储模型所需内存的20倍。
存储10亿参数模型所需内存 = 4GB(32位全精度)
训练10亿参数模型所需内存 = 80GB(32位全精度)
6. 数据并行训练技术6.1 分布式数据并行(DDP)
分布式数据并行(DDP)要求模型权重以及训练所需的所有其他额外参数、梯度和优化器状态都能在单个GPU中容纳。如果模型太大,则应使用模型分片。

6.2 全分片数据并行(FSDP)
全分片数据并行(FSDP)通过在多个GPU之间分布(分片)模型参数、梯度和优化器状态来减少内存使用。

7. 微调
微调有助于我们通过调整预训练的大语言模型(LLM)的权重,使其更好地适应特定任务或领域,从而充分发挥这些模型的潜力。这意味着与单纯的提示工程相比,你可以用更低的成本和延迟获得更高质量的结果。

与提示相比,微调通常在引导大语言模型的行为方面要有效得多。通过在一组示例上训练模型,你可以缩短精心设计的提示,节省宝贵的输入令牌,同时不牺牲质量。你通常还可以使用小得多的模型,这反过来又可以减少延迟和推理成本。
例如,经过微调的Llama 7B模型在每个令牌的基础上,成本效益比现成的模型(如GPT-3.5)高得多(大约50倍),且性能相当。
如前所述,微调是针对其他任务对已经训练好的模型进行调整。其工作方式是获取原始模型的权重,并对其进行调整以适应新任务。
模型在训练时会学习完成特定任务,例如,GPT-3在大量数据集上进行了训练,因此它学会了生成故事、诗歌、歌曲、信件等。人们可以利用GPT-3的这种能力,并针对特定任务(如以特定方式生成客户查询的答案)对其进行微调。
有多种方法和技术可以对模型进行微调,其中最流行的是迁移学习。迁移学习源自计算机视觉领域,它是指冻结网络初始层的权重,只更新后面层的权重的过程。这是因为较底层(更接近输入的层)负责学习训练数据集的通用特征,而较上层(更接近输出的层)学习更具体的信息,这些信息直接与生成正确的输出相关。
7.1 PEFT
PEFT,即参数高效微调(Parameter Efficient Fine-Tuning),是一组以最节省计算资源和时间的方式微调大型模型的技术或方法,同时不会出现我们可能在全量微调中看到的性能损失。之所以采用这些技术,是因为随着模型越来越大,例如拥有1760亿参数的BLOOM模型,在不花费数万美元的情况下对其进行微调几乎是不可能的。但有时为了获得更好的性能,使用这样的大型模型又几乎是必要的。这就是PEFT发挥作用的地方,它可以帮助解决在处理这类大型模型时遇到的问题。
以下是一些PEFT技术:

7.2 迁移学习
迁移学习是指我们获取模型的一些已学习参数,并将其用于其他任务。这听起来与微调相似,但实际上有所不同。在微调中,我们重新调整模型的所有参数,或者冻结一些权重并调整其余参数。但在迁移学习中,我们从一个模型中获取一些已学习参数,并将其用于其他网络。这在我们的操作上给予了更大的灵活性。例如,在微调时我们无法改变模型的架构,这在很多方面限制了我们。但在使用迁移学习时,我们只使用训练好的模型的一部分,然后可以将其附加到任何具有不同架构的其他模型上。
迁移学习在使用大语言模型的NLP任务中经常出现,人们会使用像T5这样的预训练模型中Transformer网络的编码器部分,并训练后面的层。
7.3 Adapters 适配器
适配器是最早发布的参数高效微调技术之一。相关论文Parameter-Efficient Transfer Learning for NLP表明,我们可以在现有的Transformer架构上添加更多层,并且只对这些层进行微调,而不是对整个模型进行微调。他们发现,与完全微调相比,这种技术可以产生相似的性能。

在左边,是添加了适配器层的修改后的Transformer架构。我们可以看到适配器层添加在注意力堆栈和前馈堆栈之后。在右边,是适配器层本身的架构。适配器层采用瓶颈架构,它将输入缩小到较小维度的表示,然后通过非线性激活函数,再将其放大到输入的维度。这确保了Transformer堆栈中的下一层能够接收适配器层生成的输出。
论文作者表明,这种微调方法在消耗更少计算资源和训练时间的同时,性能可与完全微调相媲美。他们在GLUE基准测试中,仅增加3.6%的参数,就能达到全量微调0.4%的效果。

7.4 LoRA——低秩自适应
LoRA是一种与适配器层类似的策略,但它旨在进一步减少可训练参数的数量。它采用了更严谨的数学方法。LoRA通过修改神经网络中可更新参数的训练和更新方式来工作。
从数学角度解释,我们知道预训练神经网络的权重矩阵是满秩的,这意味着每个权重都是唯一的,不能通过组合其他权重得到。但在这篇论文Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning中,作者表明,当预训练语言模型针对新任务进行调整时,权重具有较低的“内在维度”。这意味着权重可以用更小的矩阵表示,即它具有较低的秩。反过来,这意味着在反向传播过程中,权重更新矩阵的秩较低,因为大部分必要信息已经在预训练过程中被捕获,在微调过程中只进行特定任务的调整。
更简单的解释是,在微调过程中,只有极少数权重会有较大的更新,因为神经网络的大部分学习是在预训练阶段完成的。LoRA利用这一信息来减少可训练参数的数量。
以GPT-3 175B为例,LoRA研究团队证明,即使全秩(即d)高达12288,非常低的秩(即图1中的r可以是1或2)也足够了,这使得LoRA在存储和计算上都非常高效。

图2展示了矩阵 和 的维度为 ,而我们可以改变 r 的值。 r 值越小,需要调整的参数就越少。虽然这会缩短训练时间,但r值过小时也可能导致信息丢失并降低模型性能。然而,使用LoRA时,即使秩较低,性能也能与完全训练的模型相当甚至更好。
用HuggingFace实现LoRA微调
要使用HuggingFace实现LoRA微调,你需要使用PEFT库将LoRA适配器注入模型,并将它们用作更新矩阵。
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", trust_remote_code=True)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, inference_mode=False, r=32, lora_alpha=16, lora_dropout=0.1,
target_modules=['query_key_value']
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()完成这些后,你就可以像平常一样训练模型了。但这一次,它将比平常花费更少的时间和计算资源。
LoRA的效率
论文的作者表明,LoRA仅用总可训练参数的2%就能超越全量微调的效果。
至于它训练的参数数量,我们可以通过秩r参数在很大程度上进行控制。例如,假设权重更新矩阵有100,000个参数,A为200,B为500。权重更新矩阵可以分解为较低维度的较小矩阵,A为200×3,B为3×500。这样我们就只有200×3 + 3×500 = 2100个可训练参数,仅占总参数数量的2.1%。如果我们决定只将LoRA应用于特定层,这个数量还可以进一步减少。

由于训练和应用的参数数量比实际模型少得多,文件大小可以小至8MB。这使得加载、应用和传输学习到的模型变得更加容易和快速。
7.5 QLoRA
QLoRA如何与LoRA不同?它是一种4位Transformer。

QLoRA是一种微调技术,它将高精度计算技术与低精度存储方法相结合。这有助于在保持模型高性能和准确性的同时,使模型大小保持较小。
QLoRA使用LoRA作为辅助手段来修复量化过程中引入的误差。
QLoRA的工作原理
QLoRA通过引入3个新概念来帮助减少内存使用,同时保持相同的性能质量。它们是4位Normal Float、双重量化和分页优化器。
4位Normal Float(NF4)
4位NormalFloat是一种新的数据类型,是保持16位性能水平的关键因素。它的主要特性是:数据类型中的任何位组合,例如0011或0101,都会从输入张量中分配到数量相等的元素。
QLoRA对权重进行4位量化,并以32位精度训练注入的适配器权重(LORA)。
QLoRA有一种存储数据类型(NF4)和一种计算数据类型(16位BrainFloat)。
我们将存储数据类型反量化为计算数据类型以进行前向和反向传递,但我们只对使用16位BrainFloat的LORA参数计算权重梯度。
- 归一化:首先对模型的权重进行归一化,使其具有零均值和单位方差。这确保了权重分布在零附近,并落在一定范围内。
- 量化:然后将归一化后的权重量化为4位。这涉及将原始的高精度权重映射到一组较小的低精度值。对于NF4,量化级别被选择为在归一化权重的范围内均匀分布。
- 反量化:在前向传递和反向传播过程中,量化后的权重被反量化回全精度。这是通过将4位量化值映射回其原始范围来完成的。反量化后的权重用于计算,但它们以4位量化形式存储在内存中。

数据会被量化到“桶”或“箱”中。数字2和3都落入相同的量化区间2。这种量化过程通过“四舍五入”到最接近的量化区间,让你可以使用更少的数字。
双重量化
双重量化是指对4位NF量化过程中使用的量化常数进行量化的独特做法。虽然这看起来不太起眼,但相关研究论文指出,这种方法有可能平均每个参数节省0.5位。这种优化在采用块wise k位量化的QLoRA中特别有用。与对所有权重一起进行量化不同,这种方法将权重分成不同的块或片段,分别进行量化。

块wise量化方法会生成多个量化常数。有趣的是,这些常数可以进行第二轮量化,从而提供了额外的节省空间的机会。由于量化常数的数量有限,这种策略仍然有效,减轻了与该过程相关的计算和存储需求。
分页优化器
如前所述,分位数量化涉及创建桶或箱来涵盖广泛的数值范围。这个过程会导致多个不同的数字被映射到同一个桶中,例如在量化过程中,2和3都被转换为值3。因此,权重的反量化会引入1的误差。
在神经网络中更广泛的权重分布上可视化这些误差,就可以看出分位数量化的固有挑战。这种差异凸显了为什么QLoRA更像是一种微调机制,而不是一种独立的量化策略,尽管它适用于4位推理。在使用QLoRA进行微调时,LoRA调整机制就会发挥作用,包括创建两个较小的权重更新矩阵。这些矩阵以更高精度的格式(如脑浮点16或浮点16)维护,然后用于更新神经网络的权重。

值得注意的是,在反向传播和前向传递过程中,网络的权重会进行反量化,以确保实际训练是以更高精度格式进行的。虽然存储仍然采用较低精度,但这种有意的选择会引入量化误差。然而,模型训练过程本身具有适应和减轻量化过程中这些低效性的能力。从本质上讲,采用更高精度的LoRA训练方法有助于模型学习并积极减少量化误差。
用HuggingFace进行QLoRA微调
要使用HuggingFace进行QLoRA微调,你需要同时安装BitsandBytes库和PEFT库。BitsandBytes库负责4位量化以及整个低精度存储和高精度计算部分。PEFT库将用于LoRA微调部分。
import torch
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "EleutherAI/gpt-neox-20b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_cnotallow=bnb_config, device_map={"":0})
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)7.6 IA3
IA3(通过抑制和放大内部激活注入适配器,Infused Adapter by Inhibiting and Amplifying Inner Activations)是一种基于适配器的技术,与LoRA有些相似。作者的目标是在避免上下文学习(ICL,in context learning或Few-Shot prompting)相关问题的同时,复制其优势。ICL在成本和推理方面可能会变得复杂,因为它需要用示例来提示模型。更长的提示需要更多的时间和计算资源来处理。但ICL可能是开始使用模型的最简单方法。
IA3通过引入针对模型激活的缩放向量来工作。总共引入了3个向量,lv、ik和lff。这些向量分别针对注意力层中的值、键以及密集层中的非线性层。这些向量与模型中的默认值进行逐元素相乘。一旦注入,这些参数在训练过程中就会被学习,而模型的其余部分保持冻结。这些学习到的向量本质上是针对手头的任务对预训练模型的权重进行缩放或优化。

到目前为止,这似乎是一种基本的基于适配器的参数高效微调(PEFT)方法。但不止如此。作者还使用了3个损失项来增强学习过程。这3个损失项是LLM、LUL和LLN。LLM是标准的交叉熵损失,它增加了生成正确响应的可能性。然后是LUL,即非似然损失(Unlikelihood Loss)。这个损失项通过等级分类(Rank Classification)来降低错误输出的概率。最后是LLN,它是一种长度归一化损失,对所有输出选择的长度归一化对数概率应用软max交叉熵损失。这里使用多个损失项是为了确保模型更快、更好地学习。因为我们试图通过少样本示例进行学习,这些损失是必要的。
现在让我们谈谈IA3中的两个非常重要的概念:等级分类和长度归一化。
在等级分类中,模型被要求根据正确性对一组响应进行排序。这是通过计算潜在响应的概率得分来完成的。然后使用LUL来降低错误响应的概率,从而增加正确响应的概率。但是在等级分类中,我们面临一个关键问题,即由于概率的计算方式,令牌较少的响应会排名更高。生成的令牌数量越少,概率就越高,因为每个生成令牌的概率都小于1。为了解决这个问题,作者提出将响应的得分除以响应中的令牌数量。这样做将对得分进行归一化。这里需要非常注意的一点是,归一化是在对数概率上进行的,而不是原始概率。对数概率是负数,且在0到1之间。
示例用法
对于序列分类任务,可以按如下方式为Llama模型初始化IA3配置:
peft_config = IA3Config(
task_type=TaskType.SEQ_CLS, target_modules=["k_proj", "v_proj", "down_proj"], feedforward_modules=["down_proj"]
)7.7 P-Tuning
P-Tuning方法旨在优化传递给模型的提示的表示。在P-Tuning论文中,作者强调了提示工程在使用大语言模型时是一种非常强大的技术。P-Tuning方法建立在提示工程的基础上,并试图进一步提高优质提示的有效性。
P-Tuning通过为你的提示创建一个小型编码器网络来工作,该网络为传入的提示创建一个软提示。要使用P-Tuning调整你的大语言模型,你应该创建一个表示你的提示的提示模板。还有一个上下文x,用于模板中以获得标签y。这是论文中提到的方法。提示模板中使用的令牌是可训练和可学习的参数,这些被称为伪令牌。我们还添加了一个提示编码器,它帮助我们针对手头的特定任务更新伪令牌。提示编码器通常是一个双向LSTM网络,它为模型学习提示的最佳表示,然后将该表示传递给模型。LSTM网络连接到原始模型。这里只有编码器网络和伪令牌被训练,原始网络的权重不受影响。训练完成后,LSTM头部被丢弃,因为我们有可以直接使用的hi。

简而言之,提示编码器只改变传入提示的嵌入,以更好地表示任务,其他一切都保持不变。
7.8 Prefix Tuning
Prefix Tuning可以被视为P-Tuning的下一个版本。P-Tuning的作者发表了一篇关于P-Tuning V-2的论文,解决了P-Tuning的问题。在这篇论文中,他们实现了本文中介绍的Prefix Tuning。Prefix Tuning和P-Tuning没有太大区别,但仍然可能导致不同的结果。让我们深入解释一下。
在P-Tuning中,我们只在输入嵌入中添加可学习参数,而在Prefix Tuning中,我们在网络的所有层中添加这些参数。这确保了模型本身更多地了解它正在被微调的任务。我们在提示以及Transformer层的每一层激活中附加可学习参数。与P-Tuning的不同之处在于,我们不是完全修改提示嵌入,而是只在每一层提示的开头添加很少的可学习参数。

在Transformer的每一层,我们将一个带有可学习参数的软提示与输入连接起来。这些可学习参数通过一个非常小的MLP(只有2个全连接层)进行调整。这样做是因为论文的作者指出,直接更新这些提示令牌对学习率和初始化非常敏感。软提示增加了可训练参数的数量,但也大大提高了模型的学习能力。MLP或全连接层稍后可以去掉,因为我们只关心软提示,在推理时,软提示将被附加到输入序列中,引导模型。


7.9 Prompt Tuning(并非提示工程)
Prompt Tuning是最早基于仅使用软提示进行微调这一想法的论文之一。Prompt Tuning是一个非常简单且易于实现的想法。它包括在输入前添加一个特定的提示,并为该特定提示使用虚拟令牌或新的可训练令牌。在这个过程中,可以对这些新的虚拟令牌进行微调,以更好地表示提示。这意味着模型被调整为更好地理解提示。以下是论文中Prompt Tuning与全量微调的比较:

从图中可以看到,如果我们想将模型用于多个任务,全模型微调需要存在多个模型副本。但使用Prompt Tuning,你只需要存储学习到的提示令牌的虚拟令牌。例如,如果你使用“对这条推文进行分类:{tweet}”这样的提示,目标将是为该提示学习新的更好的嵌入。在推理时,只有这些新的嵌入将用于生成输出。这使得模型能够调整提示,以帮助自己在推理时生成更好的输出。
Prompt Tuning的效率
使用Prompt Tuning的最大优点是学习到的参数规模很小。文件大小可能只有KB级别。由于我们可以确定新令牌的维度大小和使用的参数数量,因此可以极大地控制要学习的参数数量。论文作者展示了,即使可训练令牌的数量非常少,该方法的表现也相当出色。并且随着使用更大的模型,性能只会进一步提升。

另一个很大的优点是,我们可以在不做任何修改的情况下,将同一个模型用于多个任务,因为唯一被更新的只是提示令牌的嵌入。这意味着,只要模型足够大且足够复杂,能够执行这些任务,你就可以将同一个模型用于推文分类任务和语言生成任务,而无需对模型本身进行任何修改。但一个很大的限制是,模型本身不会学到任何新东西。这纯粹是一个提示优化任务。这意味着,如果模型从未在情感分类数据集上进行过训练,Prompt Tuning可能不会有任何帮助。需要特别注意的是,这种方法优化的是提示,而不是模型。所以,如果你无法手工制作一个能较好完成任务的硬提示,那么尝试使用提示优化技术来优化软提示就没有任何意义。
硬提示与软提示
硬提示可以被看作是一个定义明确的提示,它是静态的,或者充其量是一个模板。一个生成式人工智能应用程序也可以使用多个提示模板。
提示模板允许提示被存储、重复使用、共享和编程。生成式提示可以被整合到程序中,用于编程、存储和重复使用。
软提示是在Prompt Tuning过程中创建的。
与硬提示不同,软提示无法在文本中查看和编辑。提示由嵌入(一串数字)组成,它从更大的模型中获取知识。
可以肯定的是,软提示的一个缺点是缺乏可解释性。人工智能发现了与特定任务相关的提示,但无法解释为什么选择这些嵌入。就像深度学习模型本身一样,软提示是不透明的。
软提示可作为额外训练数据的替代品。

7.10 LoRA与Prompt Tuning对比
现在我们已经探索了各种参数高效微调(PEFT)技术。那么问题来了,是使用像适配器(Adapter )和LoRA这样的添加式技术,还是使用像P-Tuning和Prefix Tuning这样基于提示的技术呢?
在比较LoRA与P-Tuning和Prefix Tuning时,可以肯定地说,就充分发挥模型性能而言,LoRA是最佳策略。但根据你的需求,它可能不是最有效的。如果你想在与模型预训练任务差异很大的任务上训练模型,毫无疑问,LoRA是有效调整模型的最佳策略。但如果你的任务或多或少是模型已经理解的,只是挑战在于如何正确地向模型提供提示,那么你应该使用Prompt Tuning技术。Prompt Tuning不会修改模型中的许多参数,主要侧重于传入的提示。
需要注意的一个重要点是,LoRA将权重更新矩阵分解为较小的低秩矩阵,并使用它们来更新模型的权重。即使可训练参数较少,LoRA也会更新神经网络目标部分中的所有参数。而在Prompt Tuning技术中,只是向模型添加了一些可训练参数,这通常有助于模型更好地适应和理解任务,但并不能帮助模型很好地学习新特性。
7.11 LoRA和PEFT与全量微调对比
参数高效微调(PEFT)是作为全量微调的替代方案被提出的。在大多数任务中,已有论文表明,像LoRA这样的PEFT技术即使不比全量微调更好,也与之相当。但是,如果你希望模型适应的新任务与模型预训练的任务完全不同,PEFT可能并不够。在这种情况下,有限数量的可训练参数可能会导致严重问题。
如果我们试图使用像LLaMA或Alpaca这样基于文本的模型构建一个代码生成模型,我们可能应该考虑对整个模型进行微调,而不是使用LoRA来调整模型。这是因为这个任务与模型已知和预训练的内容差异太大。另一个典型的例子是训练一个只懂英语的模型来生成尼泊尔语的文本。
8. 大语言模型推理
在使用大语言模型(LLM)进行推理时,我们通常可以配置各种参数来微调其输出和性能。以下是一些关键参数的详细介绍:
- Top-k采样:在每一步只对可能性最高的k个词元进行采样,这样可以增加多样性并避免重复。k值越高,输出的多样性越强,但可能连贯性会变差。
- 温度参数:影响下一个可能词元的概率分布,用于控制随机性和 “创造性”。较低的温度会生成更可能出现但可能重复的文本,而较高的温度则会鼓励多样性,产生更不可预测的输出。
- Top-P(核)采样:Top-P或核采样将词元的选择限制在累计概率达到某个阈值的词汇子集内,有助于控制生成输出的多样性。
- 最大长度:设置大语言模型生成的最大词元数,防止输出过长。
- 上下文提示:通过提供特定的上下文提示或输入,可以引导模型生成与该上下文一致的文本,确保生成的输出在给定的上下文中相关且连贯。
- 重复惩罚:对出现重复n - gram的序列进行惩罚,鼓励多样性和新颖性。
- 采样方式:在确定性(贪心)和基于随机采样的生成方式中选择。贪心模式在每一步选择最可能的词元,而随机采样则引入随机性。贪心模式优先考虑准确性,而随机采样鼓励多样性和创造性。
- 束搜索:保留多个潜在序列,在每一步扩展最有希望的序列,与Top-k采样相比,旨在生成更连贯、更准确的输出。


9. 提示工程
提示工程,也称为上下文提示,是指在不更新模型权重的情况下,与大语言模型进行沟通,引导其行为以获得期望结果的方法。这是一门实证科学,提示工程方法的效果在不同模型之间可能差异很大,因此需要大量的实验和探索。
什么是提示?
我们与大语言模型交互时使用的自然语言指令被称为提示。构建提示的过程称为提示工程。

提示的作用
大语言模型根据提示中的指令进行推理并完成任务的过程被称为上下文学习。
少样本提示
大语言模型在没有任何示例的情况下响应提示指令的能力称为零样本学习。
当提供单个示例时,称为单样本学习。
如果提供多个示例,则称为少样本学习。
上下文窗口,即大语言模型可以提供和推理的最大词元数,在零样本/单样本/少样本学习中至关重要。

9.1 思维链(CoT)提示
思维链(CoT)提示(Wei等人,2022)会生成一系列短句子,逐步描述推理逻辑,即推理链或推理依据,最终得出答案。在使用大型模型(例如参数超过500亿的模型)处理复杂推理任务时,CoT的优势更为明显。而简单任务使用CoT提示的受益则相对较小。

9.2 PAL(程序辅助语言模型)
Gao等人(2022)PAL: Program-aided Language Models提出了一种方法,使用大语言模型读取自然语言问题,并生成程序作为中间推理步骤。这种方法被称为程序辅助语言模型(PAL),它与思维链提示的不同之处在于,它不是使用自由形式的文本获取解决方案,而是将解决方案步骤交给诸如Python解释器这样的程序运行时处理。

9.3 ReAct提示
ReAct的灵感来自于 “行动” 和 “推理” 之间的协同作用,这种协同作用使人类能够学习新任务并做出决策或进行推理。
CoT由于无法访问外部世界或更新自身知识,可能会导致事实幻觉和错误传播等问题。
ReAct是一种将推理和行动与大语言模型相结合的通用范式。ReAct促使大语言模型为任务生成语言推理轨迹和行动。这使系统能够进行动态推理,创建、维护和调整行动方案,同时还能与外部环境(例如维基百科)进行交互,将更多信息纳入推理过程。下图展示了ReAct的一个示例以及执行问答任务所涉及的不同步骤。

10. 模型优化技术
模型压缩方法包括:(a)剪枝、(b)量化和(c)知识蒸馏。


10.1 量化
模型量化是一种用于减小大型神经网络(包括大语言模型LLM)大小的技术,通过修改其权重的精度来实现。大语言模型的量化之所以可行,是因为实证结果表明,虽然神经网络训练和推理的某些操作必须使用高精度,但在某些情况下,可以使用低得多的精度(例如float16),这可以减小模型的整体大小,使其能够在性能和准确性可接受的情况下,在性能较弱的硬件上运行。

模型大小的趋势

一般来说,在神经网络中使用高精度与更高的准确性和更稳定的训练相关。使用高精度在计算上也更为昂贵,因为它需要更多且更昂贵的硬件。谷歌和英伟达的相关研究表明,神经网络的某些训练和推理操作可以使用较低的精度。
除了研究之外,这两家公司还开发了支持低精度操作的硬件和框架。例如,英伟达的T4加速器是低精度GPU,其张量核心技术比K80的效率要高得多。谷歌的TPU引入了bfloat16的概念,这是一种为神经网络优化的特殊基本数据类型。低精度的基本思想是,神经网络并不总是需要使用64位浮点数的全部范围才能表现良好。

bfloat16数值格式
随着神经网络越来越大,利用低精度的重要性对使用它们的能力产生了重大影响。对于大语言模型来说,这一点更为关键。
英伟达的A100 GPU最先进的版本有80GB内存。在下面的表格中可以看到,LLama2 - 70B模型大约需要138GB内存,这意味着要部署它,我们需要多个A100 GPU。在多个GPU上分布模型不仅意味着要购买更多的GPU,还需要额外的基础设施开销。另一方面,量化版本大约需要40GB内存,因此可以轻松地在一个A100上运行,显著降低了推理成本。这个例子甚至还没有提到在单个A100中,使用量化模型会使大多数单个计算操作执行得更快。
使用llama.cpp进行4位量化的示例,大小可能会因方法略有不同

- 量化如何缩小模型?:量化通过减少每个模型权重所需的比特数来显著减小模型的大小。一个典型的场景是将权重从FP16(16位浮点数)减少到INT4(4位整数)。这使得模型可以在更便宜的硬件上运行,并且 / 或者运行速度更快。然而,降低权重的精度也会对大语言模型的整体质量产生一定影响。研究表明,这种影响因使用的技术而异,并且较大的模型对精度变化的影响较小。较大的模型(超过约700亿参数)即使转换为4位,也能保持其性能,像NF4这样的一些技术表明对其性能没有影响。因此,对于这些较大的模型,4位似乎是在性能与大小 / 速度之间的最佳折衷,而6位或8位可能更适合较小的模型。
- 大语言模型量化的类型:获得量化模型的技术可以分为两类。
- 训练后量化(PTQ):将已经训练好的模型的权重转换为较低精度,而无需任何重新训练。虽然这种方法简单直接且易于实现,但由于权重值精度的损失,可能会使模型性能略有下降。
- 量化感知训练(QAT):与PTQ不同,QAT在训练阶段就整合了权重转换过程。这通常会带来更好的模型性能,但计算要求更高。一种常用的QAT技术是QLoRA。

本文将只关注PTQ策略及其关键区别。
- 更大的量化模型与更小的未量化模型:我们知道降低精度会降低模型的准确性,那么你会选择较小的全精度模型,还是选择推理成本相当的更大的量化模型呢?尽管理想的选择可能因多种因素而异,但Meta的最新研究提供了一些有见地的指导。虽然我们预期降低精度会导致准确性下降,但Meta的研究人员已经证明,在某些情况下,量化模型不仅表现更优,而且还能减少延迟并提高吞吐量。在比较8位的130亿参数模型和16位的70亿参数模型时,也可以观察到相同的趋势。本质上,在比较推理成本相似的模型时,更大的量化模型可以超越更小的未量化模型。随着网络规模的增大,这种优势更加明显,因为大型网络在量化时质量损失较小。
- 在哪里可以找到已经量化的模型?:幸运的是,在Hugging Face Hub上可以找到许多已经使用GPTQ(有些与ExLLama兼容)、NF4或GGML进行量化的模型版本。快速浏览一下就会发现,这些模型中有很大一部分是由大语言模型社区中一位有影响力且备受尊敬的人物TheBloke量化的。该用户发布了多个使用不同量化方法的模型,因此人们可以根据具体的用例选择最合适的模型。要轻松试用这些模型,可以打开一个Google Colab,并确保将运行时更改为GPU(有免费的GPU可供使用)。首先安装Hugging Face维护的transformers库以及所有必要的库。由于我们将使用由Auto - GPTQ量化的模型,因此还需要安装相应的库:
!pip install transformers
!pip install accelerate
!pip install optimum
!pip install auto - gptq你可能需要重新启动运行时,以便安装的库可用。然后,只需加载已经量化的模型,这里我们加载一个之前使用Auto - GPTQ量化的Llama - 2 - 7B - Chat模型,如下所示:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")- 量化大语言模型:如前所述,Hugging Face Hub上已经有大量量化模型,在许多情况下,无需自己压缩模型。然而,在某些情况下,你可能希望使用尚未量化的模型,或者你可能希望自己压缩模型。这可以通过使用适合你特定领域的数据集来实现。为了演示如何使用AutoGPTQ和Transformers库轻松量化模型,我们采用了Optimum(Hugging Face用于优化训练和推理的解决方案)中简化版的AutoGPTQ接口:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_cnotallow=quantization_config)模型压缩可能很耗时。例如,一个1750亿参数的模型至少需要4个GPU小时,尤其是使用像 “c4” 这样的大型数据集时。值得注意的是,量化过程中的比特数或数据集可以通过GPTQConfig的参数轻松修改。更改数据集会影响量化的方式,因此,如果可能的话,使用与推理时看到的数据相似的数据集,以最大化性能。
- 量化技术:在模型量化领域已经出现了几种最先进的方法。让我们深入了解一些突出的方法:

- GPTQ:有一些实现选项,如AutoGPTQ、ExLlama和GPTQ - for - LLaMa,这种方法主要侧重于GPU执行。
- NF4:在bitsandbytes库中实现,它与Hugging Face的transformers库紧密合作。它主要被QLoRA方法使用,以4位精度加载模型进行微调。
- GGML:这个C库与llama.cpp库紧密合作。它为大语言模型提供了一种独特的二进制格式,允许快速加载和易于读取。值得注意的是,它最近转换为GGUF格式,以确保未来的可扩展性和兼容性。
许多量化库支持多种不同的量化策略(例如4位、5位和8位量化),每种策略在效率和性能之间都提供了不同的权衡。
10.2 蒸馏
知识蒸馏(KD; Hinton等人,2015年;Gou等人,2020年)Distilling the Knowledge in a Neural Network是一种构建更小、成本更低模型(“学生模型”)的直接方法,通过将预训练的高成本模型(“教师模型”)的能力转移到学生模型中,来加快推理速度。除了要求学生模型的输出空间与教师模型匹配,以便构建合适的学习目标之外,对学生模型的架构构建方式并没有太多限制。

知识蒸馏示意图

教师模型已经在训练数据上进行了微调,因此,其概率分布可能与真实数据非常接近,并且在生成的token上不会有太多变化。
当温度>1时,概率分布会变得更宽泛。
- T > 1时 => 教师模型的输出 -> 软标签 学生模型的输出 -> 软预测
- T = 1时 => 教师模型的输出 -> 硬标签 学生模型的输出 -> 硬预测
蒸馏对于生成式解码器模型的效果并不显著,它对仅编码器模型(如BERT)更为有效,因为这类模型存在大量的表示冗余。
10.3 剪枝
网络剪枝是指在保持模型能力的同时,通过修剪不重要的模型权重或连接来减小模型大小。这一过程可能需要也可能不需要重新训练。剪枝可分为非结构化剪枝和结构化剪枝。
非结构化剪枝允许删除任何权重或连接,因此不会保留原始网络架构。非结构化剪枝通常与现代硬件的适配性不佳,并且无法真正加快推理速度。
结构化剪枝旨在保持矩阵乘法中部分元素为零的密集形式。为了适配硬件内核的支持,它们可能需要遵循特定的模式限制。这里我们主要关注结构化剪枝,以在Transformer模型中实现高稀疏性。
构建剪枝网络的常规工作流程包含三个步骤:
- 训练一个密集网络直至收敛;
- 对网络进行剪枝,去除不需要的结构;
- 可选步骤,重新训练网络,通过新的权重恢复模型性能 。
通过网络剪枝在密集模型中发现稀疏结构,同时使稀疏网络仍能保持相似性能,这一想法的灵感来源于彩票假设(LTH):一个随机初始化的、密集的前馈网络包含多个子网络,其中只有一部分(稀疏网络)是 “中奖彩票”,当单独训练时,这些子网络能够达到最佳性能。
结论
在本篇文章中,我们探索了检索增强生成(RAG)应用中的文本生成部分,重点介绍了大语言模型(LLM)的使用。内容涵盖了语言建模、预训练面临的挑战、量化技术、分布式训练方法,以及大语言模型的微调。此外,还讨论了参数高效微调(PEFT)技术,包括适配器、LoRA和QLoRA;介绍了提示策略、模型压缩方法(如剪枝和量化),以及各种量化技术(GPTQ、NF4、GGML)。最后,对用于减小模型大小的蒸馏和剪枝技术进行了讲解。
[1]Transformer: https://arxiv.org/abs/1706.03762
[2]BLOOM: https://huggingface.co/docs/transformers/model_doc/bloom
[3]Parameter-Efficient Transfer Learning for NLP: https://arxiv.org/abs/1902.00751
[4]Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning: https://arxiv.org/abs/2012.13255
[5]Infused Adapter by Inhibiting and Amplifying Inner Activations: https://arxiv.org/abs/2205.05638
[6]P-Tuning论文: https://arxiv.org/abs/2103.10385
[7]P-Tuning V-2: https://arxiv.org/abs/2110.07602
[8]思维链(CoT)提示: https://arxiv.org/abs/2201.11903
[9]PAL: Program-aided Language Models: https://arxiv.org/abs/2211.10435
[10]Distilling the Knowledge in a Neural Network: https://arxiv.org/abs/1503.02531
#ConRFT
真实环境下基于强化学习的VLA模型微调方法
本文第一作者为陈宇辉,中科院自动化所直博三年级;通讯作者为李浩然,中科院自动化所副研;研究方向为强化学习、机器人学习、xx智能。
视觉-语言-动作模型在真实世界的机器人操作任务中显示出巨大的潜力,但是其性能依赖于大量的高质量人类演示数据。
由于人类演示十分稀缺且展现出行为的不一致性,通过监督学习的方式对 VLA 模型在下游任务上进行微调难以实现较高的性能,尤其是面向要求精细控制的任务。
为此,中科院自动化所深度强化学习团队提出了一种面向 VLA 模型后训练的强化微调方法 ConRFT(Consistency-based Reinforced Fine-tuning)。其由离线和在线微调两阶段组成,并具有统一的基于一致性策略的训练目标。这项工作凸显了使用强化学习进行后训练以增强视觉-语言-动作模型在真实世界机器人应用中的潜力。
目前,该论文已被机器人领域顶级会议 Robotics: Science and Systems XXI(RSS 2025)接收。
- 论文标题:ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
- 论文地址:https://arxiv.org/abs/2502.05450
- 项目主页:https://cccedric.github.io/conrft/
- 开源代码:https://github.com/cccedric/conrft
研究背景
视觉-语言-动作模型(Vision-Language-Action, VLA)在训练通用机器人策略方面取得的最新进展表明机器人数据集上进行大规模预训练后 [1,2],其拥有在理解和执行各种操作任务方面的卓越能力。
虽然预训练的通用策略能够捕捉泛化性的表征,但其仍然难以在真实机器人和任务上做到零样本泛化 [3],因此使用任务专用的数据进行后训练微调对于优化模型在下游任务中的性能来说非常重要。
目前广泛使用的方法是使用人类遥操作收集的数据对 VLA 模型进行监督微调(Supervised Fine-tuning, SFT)。然而,模型的性能严重依赖于数据集的质量和数量。由于人类收集数据的次优性和策略不一致性等固有问题,这些数据很难提供最优轨迹 [4],导致微调后的模型效果不佳。
与此同时,大语言模型(Large Language Model, LLM)和视觉-语言模型(Vision-Language Model, VLM)的最新进展凸显了强化学习在对齐模型策略与人类偏好之间差距 [5] 或改进模型推理 [6] 方面的价值,证明了部署使用任务专用的奖励函数的强化学习(Reinforcement Learning, RL)来从在线交互中机性能策略更新具有巨大的潜力。
然而,与 LLM/VLM 不同,VLA 模型需要机器人与真实世界进行物理交互,因而将 RL 扩展到 VLA 模型面临着巨大的挑战。尤其是在要求精细控制的操作任务上,交互安全性和成本限制要求 RL 算法具有探索的安全保障和很高的样本效率。
ConRFT:基于强化学习的 VLA 模型微调方法
为了充分利用 RL 技术的优势,利用在线交互数据高效微调 VLA 模型,我们提出了一种强化微调(Reinforced Fine-tuning, RFT)方法,包含离线和在线两个阶段,并采用统一的训练目标。
基于我们之前的工作 CPQL [7],本文方法将 SFT 与 Q-learning 相结合,并利用一致性策略微调 VLA 模型。离线微调过程中利用人类收集的专家数据,在模型与真实环境交互之前提取有效的策略和稳定的价值函数。
随后的在线微调阶段通过人在回路(Human-in-the-Loop Learning, HIL)进行干预,并使用奖励驱动的策略学习,从而解决了在真实环境下进行 RL 的安全要求和样本效率两个挑战。该方法示意图如下:

本文方法采用一致性策略(Consistency Policy)作为动作单元(Action Head),对 VLA 模型进行微调,解决了两个关键问题:
1)它有助于利用预收集的数据中经常出现的策略不一致和次优演示问题;
2)与基于扩散模型(Diffusion Model)的动作单元相比,其在计算上保持轻量,可以实现高效推理。
一致性策略是一种基于概率流常微分方程(Probability Flow Ordinary Differential Equation)的策略,它学习从高斯分布中采样的随机动作映射到基于当前状态的专家动作分布,从而生成目标动作用于决策任务。
阶段I:离线微调(Cal-ConRFT)
由于预训练的 VLA 模型通常缺乏对未见过场景的零样本泛化能力,因此离线阶段专注于使用预先收集的小型离线数据集(大约 20-30 次演示)训练策略,然后再过渡到在线微调阶段,从而减少整体在线训练时间和探索过程带来的安全风险。
为了能够有效利用离线数据,离线阶段选择(Cal-QL)[8] 作为价值函数更新方法,以提高 Q 函数对分布外(Out of Distribution, OOD)动作的鲁棒性。使用 Cal-QL 进行价值函数更新的训练目标如下:

尽管通常情况下,Cal-QL 能够高效地利用离线数据集,但在只有少量演示(例如 20-30 个)可用时,其依然很难训练出有效的策略。因为有限的状态-动作覆盖会导致 Q 值估计不准,从而使策略难以推广到未见过的状态。相比传统的离线强化学习方法,其数据集通常由多种行为策略收集而成,可以提供广泛的状态-动作覆盖范围以减少分布偏移。
为了解决这个问题,离线阶段加入了 BC(Behavior Cloning)损失。BC 损失直接最小化策略生成的动作与演示中的动作之间的差异,通过鼓励模型模仿演示中的行为,在离线阶段提供额外的监督信号。这有助于 VLA 模型学习更有效的策略,并初始化稳定的 Q 函数。
具体而言,使用一致性策略动作单元的 VLA 模型更新训练目标如下:

阶段II:在线微调(HIL-ConRFT)
虽然离线阶段可以从少量演示数据中提供初始策略,但其性能受限于预先收集的演示数据的范围和质量。因此,本文方法引入在线阶段,即 VLA 模型通过与真实环境交互并进行在线微调。
在阶段 II 的强化微调过程中,离线阶段的演示缓冲区
![]()
依然保持用于存储演示数据,同时还有一个重放缓冲区
![]()
来存储在线数据,并使用平均采样来形成单个批次(Batch)用于模型训练。
由于 VLA 模型会根据其当前策略不断收集新的数据,数据分布会自然地随着策略而演变,这种持续的交互减少了离线阶段面临的分布偏移问题。因此,在线微调阶段直接使用标准 Q 损失进行价值函数更新:

对于 VLA 模型,在线微调阶段使用与离线阶段结构统一的训练目标,因此 VLA 模型可以快速适应并实现策略性能提升:

可以注意到,在线阶段仍然保留了 BC 损失。主要有两个原因:
1)它确保策略与演示数据一致,防止出现可能导致性能崩溃的剧烈偏差;
2)由于强化学习本质上涉及探索,因此它在高维状态-动作空间中可能变得不稳定,而 BC 损失可以防止策略与离线基线方法偏差过大,从而降低低效或不安全行为的风险。这在真实机器人的训练中和要求精细控制的操作任务中非常重要,尤其是在不安全动作可能导致物体损坏或其他危险的物理环境中。
此外,在线阶段通过人在回路学习将人工干预融入学习过程。具体而言,其允许人类操作员及时干预并从 VLA 模型接管机器人的控制权,从而在探索过程中提供纠正措施。
当机器人出现破坏性行为(例如碰撞障碍物、施加过大的力量或破坏环境)时,人工干预至关重要。这些人工纠正措施会被添加到演示缓冲区
![]()
中,以提供高层次的指导,引导策略探索朝着更安全、高效的方向演变。
除了确保安全的探索之外,人工干预还可以加速策略收敛。因为当策略导致机器人陷入不可恢复状态或不良状态(如机械臂将被操作物体扔出桌面或与桌面撞击),或者机器人陷入局部最优解(如果没有外部帮助,则需要花费大量时间和步骤才能克服)时,人类操作员可以介入纠正机器人的行为,并引导其朝着更安全、有效的方向演变。
实验结果与分析
为了评估本文方法在真实环境中强化微调 VLA 模型的有效性,我们在八个不同的操作任务上进行了实验,并选择 Franka Emika 机械臂作为实验平台,如下图所示。

这些任务旨在反映各种操作任务挑战,包括物体放置任务(例如将面包放入烤面包机)、要求精确控制的任务(例如将轮子对准并插入椅子底座)以及柔性物体处理的任务(例如悬挂中国结)。
在八个真实环境任务上的实验测试证明了 ConRFT 性能超越最先进(SOTA)方法的能力。VLA 模型在本文提出的框架下经过 45-90 分钟的在线微调后,平均任务成功率达到 96.3%,展现了极高的策略性能和样本效率。
此外,它的性能优于基于人类收集数据或强化学习策略数据训练的 SFT 方法,平均成功率提高了 144%,且平均轨迹长度缩短了 1.9 倍,这些结果凸显了使用奖励驱动的强化微调方法在提升 VLA 模型在下游任务上性能的巨大潜力。
策略测试
通过奖励驱动的强化微调,VLA 模型表现出对外部人为干扰的极强鲁棒性,确保更可靠地完成任务。包含外部人为干扰的策略效果可以参考 Pick Banana 和 Hang Chinese Knot 任务。
Pick Banana(含外部人为干扰)
Put Spoon
Open Drawer
Pick Bread
Open Toaster
Put Bread
Insert Wheel
Hang Chinese Knot(含外部人为干扰)
在精细操作任务上的展示
为了进一步展示本文方法在 VLA 模型微调方面的能力,我们进行了穿针任务实验。经过 40 分钟的在线微调,微调后的 VLA 模型取得了 70% 的成功率。
总结与展望
本文提出了一种两阶段方法 ConRFT,用于在真实环境下的机器人应用中强化微调 VLA 模型。
首先,利用少量演示进行离线微调(Cal-ConRFT),并通过一个统一的训练目标初始化一个可靠的策略和价值函数,该目标将 Q 损失和 BC 损失整合到一个基于一致性策略的框架中。然后,在线微调阶段(HIL-ConRFT)利用任务专用的奖励和人工干预对 VLA 模型进行微调。
在八个不同的真实环境操作任务上实验结果表明,本文方法在成功率、平均轨迹长度和样本效率方面均优于 SOTA 方法。总而言之,这项工作展示了一种利用强化学习进行安全且高效的 VLA 模型微调的方法。
参考文献
[1] Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. RT-2: vision-language-action models transfer web knowledge to robotic control. Conference on Robot Learning, CoRL, 2023.
[2] Kevin Black, Noah Brown, Danny Driess, Adnan Es-mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024.
[3] Joshua Jones, Oier Mees, Carmelo Sferrazza, Kyle Stachowicz, Pieter Abbeel, and Sergey Levine. Beyond sight: Finetuning generalist robot policies with heterogeneous sensors via language grounding. arXiv preprint arXiv:2501.04693, 2025.
[4] Charles Xu, Qiyang Li, Jianlan Luo, and Sergey Levine. RLDG: robotic generalist policy distillation via reinforcement learning. arXiv preprint arXiv:2412.09858, 2024.
[5] Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Neural Information Processing Systems, NeurIPS, 2017.
[6] Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, and Jason Weston. Iterative reasoning preference optimization. In Neural Information Processing Systems, NeurIPS, 2024.
[7] Yuhui Chen, Haoran Li, and Dongbin Zhao. Boosting continuous control with consistency policy. In International Conference on Autonomous Agents and Multiagent Systems, AAMAS, 2024.
[8] Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning. In Neural Information Processing Systems, NeurIPS, 2023
#为什么DeepSeek-R1之后的大模型都开始做思维链?
何为思维链?
思维链最早是在预训练模型中涌现出来的现象。人们发现,仅仅只是在模型解数学题的时候,要求它 think step by step,模型就能极为显著地改善其做数学题的正确率。这个现象在最初是让很多人感到相当震撼的,和 In-context learning (大模型有能力看懂任务指示和示例,在不进行训练的情况下,直接学会在训练时没遇到过的新任务)一道成为大模型智能涌现的标志之一。
大模型的数学能力以及逻辑能力差,是所有和它们对话过的人都能发现的一个问题。这个问题严重影响了大模型落地赚钱的可能,因为人们普遍不敢信任说话没逻辑的大模型能做出什么正确的决策。于是,提升大模型数学能力,被所有做基础模型的公司当作了第一目标。
那么自然会有人想要强化思维链,看看有没有办法能够把大模型的数学能力给做上去。一个很简单的想法是,模型 think step by step 就像人类思考问题、并且用草稿纸写下过程那样,这里面有假设、演绎、反思、纠错等等。既然人类这样做可以有效做对数学题,那大模型应该也可以?于是问题就转化为了如何让大模型学会正确地思考。
第一个证明这件事有用的是 OpenAI 的 o1 系列模型。在此之前,OpenAI 已经炒作了很久的 Q* 以及“草莓”,让人猜想下一个模型强化的地方。而在o1-preview之后,便掀起了复现 o1 的竞赛。大部分题目中提到的公司(kimi、qwen、天工)都早就开始了这方面的探索,并且在 DeepSeek-R1 发布前就已经有思维链模型发布,只不过效果没做到 DeepSeek-R1 这么好。
那么怎么强化思维链复现 o1 呢?主要有以下四条路线:
一、基于过程监督的强化学习。
就是说,本来我们让模型 think step by step 它就可以写出一些过程的,但这些过程大抵是不太对的。那我们就像人类的老师改学生作业一样,仔细看看过程,看看是哪一步做错了,对于做错的那一步扣分;做对的那一步加分。
这个路线所面临的核心问题是,
- 1、怎么去界定步骤?毕竟打分是以步骤来进行的。但是每次解题的过程都不一定能和标答对上,于是得分点就不好判断了。
- 2、谁来判定哪个过程是正确的?理想情况是老师能仔细阅读每一个步骤,如果想错了就扣分,如果做对了就给分。但是在当时大家手上并没有一个数学非常好的模型能做到这一点。
代表性的工作,比如 OpenAI 的 Let's verify step by step,就是用过程监督的办法来强化思维链,取得了一定效果。
二、蒙特卡洛树搜索(MCTS)。
这也是个强化学习的经典算法,当初阿尔法狗就是用了这个算法在围棋中打爆了人类的。如果把解数学题看作是一个在迷宫中搜索正确路径的过程,那么就可以引入这个算法。在搜索中,需要准确评估当前这条路径到底看上去合不合理(状态价值有多少,状态价值可以看作是当前期望能拿到的奖励)。
这个路线所面临的核心问题:
- 1、把以文字为主的数学题抽象成迷宫,怎么做?毕竟无论是题目还是解答过程都是文字,怎么对这些连续的文字划分成分段的过程?怎么清晰地把所有下一步可能的过程或者结果抽象成有限的节点?
- 2、假如我们已经把数学问题抽象成了一个迷宫,怎么判断当前这条路径好不好?谁有能力来做这样的判断?
这一类工作代表作有微软的 rStar,也取得了一定的效果。
三、监督微调。
既然原先大模型在预训练的时候要预测下一个字符是什么,那么我们收集一堆思维过程给大模型,让它们照葫芦画瓢,没准就有用呢?毕竟一开始的预训练模型就能通过 think step by step 来改善正确率,当然有理由认为我塞更多思维链的数据进去,能进一步改善正确率。
这个路线所面临的核心问题是:并没有那么多思维过程数据能给到大模型。 几乎所有的教科书、教辅书都只会把正确过程给印到答案上,而不会把错误的过程给印上去,但很多时候我们希望模型在想错的时候能稍微多想一步、反思一下,至少能纠正那些看起来明显不对的错误。所以这种思维数据得从头收集。
- 1、可以让已有的预训练大模型 think step by step 然后筛选出得到正确结果的那些样本。但有人观察到某些大模型的 think step by step 是装模做样分析一通,但实际上给出的结果和它的分析并不符合。换句话说,这样收集到的过程并不一定可靠。
- 2、也可以召集一堆学生把自己解题时脑袋里的碎碎念给写下来。但是很显然这样做的成本很高,毕竟脑袋里的碎碎念这种东西全部写下来要花的时间可不短。尽管语音输入可以稍微缓解这个问题,但数学公式还是没法语音输入的。
- 3、蒸馏 OpenAI o1 (preview/mini)。但是 OpenAI 并不开放思维链,而且对任何妄图诱导模型说出自己思维过程的用户都进行严厉打击。
这一类工作的代表作有很多,比如 DeepSeek-R1 蒸馏出来的那些 Qwen 和 Llama 小模型。在这之前也有很多模型,并且报告说自己的模型能达到 OpenAI o1 preview 的水平,那大抵是用了这个方法,效果也确实很不错。只要真的收集到了很多思维链数据,小模型就真的照葫芦画瓢学会思考。
四、基于规则的强化学习。
在过程监督以及 MCTS 两种方法中,都会面临怎么去对过程进行拆分、怎么去对过程中的某一步(正确性或者未来预期的正确性)进行打分的问题。有人感到这件事实在是过于困难了,等于是手动往解题这件事上加“结构”(见《苦涩的教训》)。所以,他们打算只看结果,不看过程,让模型自由发挥。
这条路线面临的问题是,没什么人对这件事情有信心。毕竟,你只关心结果,那你怎么知道,模型会按照你期望的方式获得正确的结果呢?
- 1、模型可能一直都做不对题,从而摆烂。就算做对了,那也是侥幸对的。
- 2、模型可能找到一些其他的办法稍微多做对几道题,比如背答案,或者找一些逻辑上完全没有关联的规律。总之模型看上去不像是能自己学会思考的样子。
- 3、想想就觉得这事很难。要是这能成,那我干脆直接设立一个目标,让模型去给我赚钱,那模型就能真的学会怎么赚钱了?这就AGI了?这条路线事实上也挺难,很多人也尝试过,但没调通,放弃了。
这条路线的代表作,自然是 DeepSeek-R1、Kimi-k1.5。当然我们现在知道了,OpenAI 的 o1 系列也是这条路线训练出来的——这件事很难,但真的能成,而且效果非常好。在 DeepSeek-R1 出来之后,基本上就只剩下第三和第四条路线了(因为它们的效果最好,而且既然有人能做出来,那自己做不出来肯定是没做对,只要多试试就好了)。
未来展望
那么以后的大模型是不是得标配思维链呢?基本上是的。GPT-4.5 是 OpenAI 公司发布的最后一个非思维链大模型,以后该公司的所有模型都会具有思维链能力。思维链是一个能以最小的代价,而非常显著提升模型智力水平(逻辑能力、解题能力、代码能力)的技术,此外还有一些其他方面的好处,不做白不做。
#大模型最近的突破,全是作弊
AI应用创业公司
Llama 4 或许只是冰山一角。
「AI 大模型自去年 8 月以来就没有太大进步」。这是一位 AI 创业者在近期的一篇博客中发表的观点。
他在创业过程中发现,自去年 8 月以来,AI 大模型(如 Claude 3.7 等)在官方发布的基准测试上声称的巨大进步与实际应用场景中的有限提升之间存在明显脱节。这导致他们无法借助模型能力来提升产品体验。很多 YC 创业者也有类似的体验。
作者认为,这其中可能的原因包括基准测试作弊、基准无法衡量实用性或模型实际很聪明但对齐存在瓶颈。如果不解决这些基础问题,AI 系统可能会在表面上显得很聪明,但在组合成社会系统时会出现根本问题。
以下是博客原文:
模型得分与消费者体验脱节
大约九个月前,我和三个朋友认为人工智能已经足够好,可以自主监控大型代码库的安全问题了。我们围绕这个任务成立了一家公司,试图利用最新的大模型能力来创建一种工具,用以取代至少很大一部分渗透测试人员的价值。我们从 2024 年 6 月开始从事这个项目。
在公司成立后的头三个月内,Anthropic 的 Claude 3.5 sonnet 就发布了。只需切换在 GPT-4o 上运行的服务部分,我们刚刚起步的内部基准测试结果就会立即开始饱和。我记得当时很惊讶,我们的工具不仅似乎犯的基本错误更少,而且其书面漏洞描述和严重性估计似乎也有了质的提高。就好像即使是在不完整的信息中,这些模型也能更善于推断人类提示背后的意图和价值。
事实上,安全研究基本上没有公开的基准。有「网络安全」评估会向 AI 模型询问有关孤立代码块的问题,「CTF」评估会为模型提供明确的挑战描述和对 <1kLOC Web 应用程序的 shell 访问权限。但没有什么能触及 LLM 应用程序渗透测试的难点 —— 一是浏览一个太大而无法放在上下文中的真实代码库;二是推断目标应用程序的安全模型;三是深入理解其实现,以了解该安全模型在哪里出现了问题。
出于这些原因,我认为漏洞识别任务是衡量 LLM 在狭窄的软件工程领域之外的泛化性的一个很好的试金石。
自 3.5-sonnet 以来,我们一直在监控 AI 大模型的发布,并尝试过几乎每个声称有所改进的主要新版本。令人意想不到的是,除了 3.6 的小幅提升和 3.7 的更小提升外,我们尝试的所有新模型都没有对我们的内部基准或开发人员发现新错误的能力产生重大影响。这包括新的测试时间计算 OpenAI 模型。
起初我很紧张,不敢公开报告此事,因为我认为这可能会对我们团队产生不良影响。自去年 8 月以来,我们的扫描有了很大的改进,但这是因为常规工程,而不是模型改进的提升。这可能是我们设计的架构存在问题,随着 SWE-Bench 分数的上升,我们并没有获得更多的进展。
但最近几个月,我与其他从事 AI 应用初创企业的 YC 创始人进行了交谈,他们中的大多数人都有相同的经历:1. 见证了 o99-pro-ultra 大模型发布,2. 基准测试看起来不错,3. 实际应用评估表现平平。尽管我们从事不同的行业,处理不同的问题,但情况大致相同。有时创始人会对这种说法做出回应(「我们只是没有任何博士级的问题可以问」),但这种说法是存在的。
我读过这些研究,也看过这些数字。也许与大模型的交谈变得更有趣了,也许他们在受控考试中表现得更好了。但我仍然想根据内部基准以及我自己和同事们使用这些模型的看法提出观点:大模型公司向公众报告的任何提升都不能反映经济实用性或普遍性。它们不能反映我或我客户的实际体验。就能够执行全新的任务或更大比例的用户智力劳动而言,我认为自去年 8 月以来它们就没有太大进步了。
如果你是大模型竞品公司的工程师,这或许是个好消息!对我个人而言,作为一个试图利用大模型能力赚钱的人,它们还没有聪明到能解决整个问题,对那些担心快速过渡到 AI 经济会带来道德风险的人来说,或许也不需要太过担忧了。
与此同时,有一种观点认为,模型得分与消费者体验脱节是一个不好的迹象。如果业界现在还搞不清楚如何衡量模型的智力,而模型大多局限于聊天机器人,那么当 AI 在管理公司或制定公共政策时,又该如何制定衡量其影响的标准呢?如果我们在将公共生活中繁琐而艰难的部分委托给机器,之前就陷入了古德哈特定律(当一个政策变成目标,它将不再是一个好的政策),我想知道原因。
AI 实验室是在作弊吗?
AI 实验室的创始人们经常认为,他们正在进行一场文明竞争,以控制整个未来的光锥,如果他们成功了,世界就将会改变。指责这些创始人从事欺诈行为以进一步实现这些目的是相当合理的。
即使你一开始对科技大佬的评价异常高,你也不应该指望他们在这场竞赛中成为自己模型表现的诚信来源。如果你能规避惩罚,那么夸大能力或有选择地披露有利的结果有非常强大的短期激励。投资是其中之一,但吸引人才和赢得(具有心理影响力的)声望竞赛可能也是同样重要的激励因素。而且基本上没有法律责任迫使实验室对基准测试结果保持透明或真实,因为从来没有人因为在测试数据集上进行训练然后向公众报告该表现而被起诉或被判犯有欺诈罪。
如果你尝试过,任何这样的实验室仍然可以声称自己在非常狭隘的意义上说的是实话,因为该模型「确实在该基准上实现了该性能」。如果对重要指标的一阶调整在技术意义上可以被视为欺诈,那么负责伪造统计数据的团队还有一百万种其他方式来稍微间接地处理它。
在本文的初稿中,我在上面一段后面加上了这样一句话:「话虽如此,不可能所有收益都来自作弊,因为一些基准测试有保留数据集。」最近有一些私人基准测试,如 SEAL,似乎显示出了改进。但 OpenAI 和 Anthropic 发布的每一个基准测试都有一个公开的测试数据集。我能想到的唯一例外是 ARC-AGI 奖,其「半私人」评估中的最高分由 o3 获得,但尽管如此,它尚未对 Claude 3.7 Sonnet、DeepSeek 或 o3-mini 进行过公开评估。关于 o3 本身:

所以也许没有什么秘密:AI 实验室公司在撒谎,当他们改进基准测试结果时,是因为他们之前已经看到过答案并把它们写下来了。从某种意义上说,这可能是最幸运的答案,因为这意味着我们在衡量 AGI 性能方面其实并没有那么糟糕;我们只是面临着人为的欺诈。欺诈是人的问题,而不是潜在技术困难的迹象。
我猜这在一定程度上是正确的,但并非全部。
基准测试是否没有跟踪实用性?
假设你对一个人的唯一了解是他们在瑞文渐进矩阵(智商测试)中得分为 160。你可以对这个人做出一些推断:例如,RPM 得分越高,可推断出生活条件越积极,比如职业收入很高、健康状况很好、不会进监狱等等。
你可以做出这些推断,部分原因是在测试人群中,瑞文渐进矩阵测试的分数可以反映人类在相关任务上的智力能力。完成标准智商测试并获得高分的能力不仅能让你了解这个人的「应试」能力,还能让你了解这个人在工作中的表现如何,这个人是否做出了正确的健康决定,他们的心理健康是否良好,等等。
至关重要的是,这些相关性不必很强,瑞文测试才能成为有用的诊断工具。患者不会接受智商测试训练,而且人类大脑的设计也并非是为了在 RPM 等测试中获得高分。我们在这些测试中的优异表现(相对于其他物种而言)是过去 5 万年中偶然发生的事情,因为进化间接地让我们能够追踪动物、灌溉庄稼和赢得战争。
然而在大模型领域,除了几个明显的例外,我们几乎所有的基准测试都具有标准化测试的外观和感觉。我的意思是,每一个都是一系列学术难题或软件工程挑战,每个挑战你都可以在不到几百个 token 的时间内消化并解决。也许这只是因为这些测试评估起来更快,但人们似乎理所当然地认为,能够获得 IMO 金牌的 AI 模型将具有与陶哲轩相同的能力。因此,「人类的最后考试」(ENIGMAEVAL)不是对模型完成 Upwork 任务、完成视频游戏或组织军事行动的能力的测试,而是一个自由反应测验。
我不会做任何「人类的最后考试」的测试问题,但我今天愿意打赌,第一个拿到满分的大模型仍然无法作为软件工程师就业。 HLE 和类似的基准测试很酷,但它们无法测试语言模型的主要缺陷,比如它们只能像小商贩一样通过复述的方式来记住东西。Claude Plays Pokemon 是一个被过度使用的例子,因为视频游戏涉及许多人类特定能力的综合。这项任务适合于偶尔回忆 30 分钟前学到的东西,结果不出所料地糟糕。

就我个人而言,当我想了解未来能力的改进时,我将几乎只关注 Claude Plays Pokemon 这样的基准测试。我仍然会查看 SEAL 排行榜,看看它在说什么,但我的 AI 时间表的决定因素将是我在 Cursor 中的个人经历,以及 LLM 处理类似你要求员工执行的长期任务的能力,其他的一切都太过嘈杂。
这些模型或许已经很智能,但在对齐方面存在瓶颈?
在介绍下一点之前,让我先介绍一下我们的业务背景。
正如我所提到的,我的公司使用这些模型来扫描软件代码库以查找安全问题。从事这个特定问题领域(维护已交付软件的安全性)工作的人被称为 AppSec 工程师。
事实上,大多数大公司的 AppSec 工程师都有很多代码需要保护。他们的工作过度,典型要回答的问题不是「我如何确保这个应用程序没有漏洞」,而是「我如何管理、筛选和解决我们 8000 条产品线中已经存在的大量安全问题」。
如果他们收到一条警报,他们希望它影响活跃的、理想情况下可通过互联网访问的生产服务。任何低于这个水平的情况都意味着要么有太多结果需要审查,要么安全团队是在浪费有限的沟通资源来要求开发人员修复甚至可能没有影响的问题。
因此,我们自然会尝试构建我们的应用程序,以便它只报告影响活跃的、理想情况下可通过互联网访问的生产服务的问题。但是,如果你只是向聊天模型解释这些限制,它们会偶尔遵循人的指示。例如,如果你告诉他们检查一段代码是否存在安全问题,他们倾向于像你是刚刚在 ChatGPT UI 中询问该代码的开发人员一样做出回应,因此会推测代码有问题或险些失误。即使你提供了我刚刚概述的情况的完整书面描述,几乎每个公共模型都会忽略你的情况,并将无法利用的 SQL 查询连接报告为「危险」。
这并不是说 AI 模型认为它遵循了你的指示,但实际上并没有。LLM 实际上会在简单的应用程序中说,它报告的是一个「潜在」问题,并且可能无法验证。我认为发生的情况是,大型语言模型被训练成在与用户的实时对话中「看起来很聪明」,因此它们更喜欢突出显示可能的问题,而不是确认代码看起来不错,就像人类想要演得很聪明时所做的那样。
每个 LLM 应用初创公司都会遇到这样的限制。当你是一个直接与聊天模型交互的人时,阿谀奉承和诡辩只是小麻烦,甚至也是能适应的。当你是一个团队试图将这些模型组合成更大的系统时(由于前面提到的内存问题,这是必要的),想要看起来不错会引发严重的问题。更智能的模型可能会解决这个问题,但它们也可能使问题更难检测,特别是当它们取代的系统变得更加复杂并且更难验证输出时。
有很多不同的方法来克服这些缺陷。在有人想出解决问题的外在表现之前,我们完全有可能无法解决核心问题。
我认为这样做是一个错误。这些 AI 机器很快就会成为我们生活的社会的跳动的心脏。它们在组合和互动时创造的社会和政治结构将定义我们周围看到的一切。更重要的是,它们要尽可能地有道德。
原文链接:
#Jeff Dean演讲回顾LLM发展史
Transformer、蒸馏、MoE、思维链等技术都来自谷歌
月 14 日,谷歌首席科学家 Jeff Dean 在苏黎世联邦理工学院举办的信息学研讨会上发表了一场演讲,主题为「AI 的重要趋势:我们是如何走到今天的,我们现在能做什么,以及我们如何塑造 AI 的未来?」

在这场演讲中,Jeff Dean 首先以谷歌多年来的重要研究成果为脉络,展现了 AI 近十五年来的发展轨迹,之后又分享了 Gemini 系列模型的发展历史,最后展望了 AI 将给我们这个世界带来的积极改变。
将在本文中对 Jeff Dean 的演讲内容进行总结性梳理,其中尤其会关注演讲的第一部分,即谷歌过去这些年对 AI 领域做出的奠基性研究贡献。我们将看到,Transformer、蒸馏、MoE 等许多在现代大型语言模型(LLM)和多模态大模型中至关重要的技术都来自谷歌。正如 𝕏 网友 @bruce_x_offi 说的那样,你将在这里看到 AI 的进化史。

下面我们就来具体看看 Jeff Dean 的分享。
,时长01:18:47
- 源地址:https://video.ethz.ch/speakers/d-infk/2025/spring/251-0100-00L.html
- 幻灯片:https://drive.google.com/file/d/12RAfy-nYi1ypNMIqbYHjkPXF_jILJYJP/view

首先,Jeff Dean 分享了他得到的一些观察:
- 近年来,机器学习彻底改变了我们对计算机可能性的期望;
- 增加规模(计算、数据、模型大小)可带来更好的结果;
- 算法和模型架构的改进也带来了巨大的提升;
- 我们想要运行的计算类型以及运行这些计算的硬件正在发生巨大的变化。
机器学习十五年

首先,神经网络!

神经网络的概念是在上个世纪提出的,而现在 AI 的各种能力基本上都是某种基于神经网络的计算。我们可以粗略地将神经网络视为真实神经元行为的非常不完美的复制品。它还有很多我们不理解的地方,但它们是 AI 的基本构建模块之一。
反向传播是另一个关键构建模块,这是一种优化神经网络权重的方法。通过反向传播误差,可让模型的输出逐渐变成你想要的输出。这种方法能有效地用于更新神经网络的权重,以最小化模型在训练数据上的误差。并且由于神经网络的泛化特性,得到的模型也具有泛化能力。

神经网络和反向传播是深度学习革命的两大关键。
2012 年时,Jeff Dean 与其他一些研究者开始研究:如果训练真正的大型神经网络,它们会比小型神经网络表现更好。在这一假设基础上,他们决定训练一个非常大的神经网络,并且他们使用了无监督学习算法。

这个大型神经网络比 2012 年已知的最大神经网络还大 60 倍,使用了 16,000 个 CPU 核心。
Jeff Dean 说:「当时,我们的数据中心还没有 GPU。我们有很多普通的旧 CPU 计算机。我们看到的是,这个无监督的训练目标再加上一些监督训练,将 AI 在 ImageNet 22K 上的最佳性能提高了 70% 左右。」
这是一个相当大的进步,也证明了我们的假设,即如果投入足够的训练计算,更大模型的能力会更强。
作为这项工作的一部分,谷歌开发了他们第一个神经网络大规模基础设施系统,称为 DistBelief。这是一个分布式计算系统,分散在许多机器上,而且我们许多同事并不认为它能其作用。但实际上,当模型很大时,本就不适合仅使用单台计算机。
在分摊计算时,有几种不同的方法。第一种是垂直或水平地切分神经网络中的神经元。这样一来,每台计算机上都只有神经网络的一部分,然后你需要想办法让这些不同部分之间互相通信。这叫做模型并行化。

另一种方法是数据并行化,即在许多不同的机器上都有底层模型的副本,然后将训练数据划分给不同的模型副本。
模型并行化与数据并行化可以同时使用。
在 DistBelief 中,实际上还有一个中心系统,可以接收来自模型不同副本的梯度更新,并将它们应用于参数。但 Jeff Dean 表示他们的做法实际上在数学上并不正确,因为这个过程是完全异步的。不同的模型副本将获得参数的新副本,在一些数据上进行计算,再将基于这些参数和该批次训练数据的梯度发送回参数服务器。但这时候,参数已经有变化了,因为其他模型副本在此期间应用了它们的梯度。因此,根据梯度下降算法,这在数学上显然是不正确的,但它是有效的。所以这就是个好方法。
这就是使我们能够真正将模型扩展到非常大的原因 —— 即使只使用 CPU。
在 2013 年,谷歌使用该框架扩展了一个扩大了词的密集表示的训练,这还用到了一个词嵌入模型 Word2Vec。

基于此,谷歌发现,通过使用高维向量表示词,如果再用特定的方式训练,就能得到两个很好的属性:
一、在训练大量数据后,这个高维空间中的近邻词往往是相关的,比如所有与猫、美洲狮和老虎相关的词都汇集到了一个高维空间的同一部分。
二、方向在这种高维空间中是有意义的。举个例子,为了将一个男性版本的词转化为女性版本,比如 king → queen、man→woman,都要朝着大致相同的方向前进。
2014 年,我的三位同事 Ilya Sutskever、Oriol Vinyals、Quoc V. Le 开发了一个神经网络,名为序列到序列学习模型。这里的想法是,对于一个输入序列,或许可以根据它预测出一个输出序列。

一个非常经典的例子是翻译。比如如果源句子是英语,可以一个词一个词地处理输入的英语句子来构建表示,得到一个密集表示,然后你可以将这个表示解码成法语句子。如果有大量的英语 - 法语对,就可以学习得到一个语言翻译系统。整个过程都是使用这种序列到序列的神经网络。
Jeff Dean 表示自己在 2013 年左右开始担心:由于模型越来越大,语音识别等方面也开始出现一些好用的应用,用户量可能有很多,那么该如何提供所需计算呢?
因此,谷歌开始尝试改进硬件,并决定为神经网络推理构建更定制的硬件。这就是张量处理单元(TPU)的起源。

第一个版本的 TPU 只专门用于推理,所以它使用了非常低的精度 —— 它的乘法器只支持 8 位整数运算。但他们真正的目标是构建一种非常擅长低精度线性代数的硬件,它将能服务于许多不同类型的基于神经网络的模型。这个硬件也不需要现代 CPU 中那些花哨复杂的功能,例如分支预测器或各种缓存。相反,他们的做法是尽力以更低的精度构建最快和最小的密集线性代数硬件。
不出所料,最终生产出的 TPU 在这些任务上比当时的 CPU 和 GPU 快 15 到 30 倍,能源效率高 30 到 80 倍。顺便说一下,这是 ISCA 50 年历史上被引用最多的论文。这很了不起,因为它 2017 年才发表。
之后,谷歌开始研发专用于训练神经网络的专用型超级计算机 —— 大量芯片用高速网络连接起来。现在谷歌 TPU pod 在推理和训练方面都适用,并且连接的 TPU 也越来越多。最早是 256 台,然后是 1000,之后是 4000,最近已经来到了八九千。而且谷歌使用了定制的高速网络来连接它们。

上周,谷歌宣布了新一代的 TPU,名为 Ironwood。Jeff Dean 表示谷歌不会继续再用数字来命名 TPU。Ironwood 的 pod 非常大:它有 9216 块芯片,每块芯片可以执行 4614 TFLOPS 的运算。

TPU 的能源效率也在快速提升。

另一个非常重要的趋势是开源。这能吸引更广泛的社区参与并改进这些工具。Jeff Dean 认为,TensorFlow 和 Jax(都是谷歌开发的)另外再加上 PyTorch,对推动 AI 领域的发展做出了巨大的贡献。

然后到 2017 年,Transformer 诞生了。当时,他们观察到:循环模型有一个非常顺序化的过程,即一次吸收一个 token,然后在输出下一个 token 之前更新模型的内部状态。这种固有的顺序步骤会限制从大量数据学习的并行性和效率。因此,他们的做法是保存所有内部状态,然后使用一种名为注意力的机制去回顾经历过的所有状态,然后看它们哪些部分与当前执行的任务(通常是预测下一 token)最相关。

这是一篇非常有影响力的论文。部分原因是,他们最初在机器翻译任务上证明,用少 10 到 100 倍的计算量和小 10 倍的模型,就可以获得比当时最先进的 LSTM 或其他模型架构更好的性能。注意,下图使用了对数刻度。所以尽管箭头看起来很小,但其中差异实际非常大。

这篇论文很重要,几乎所有现代大型语言模型都使用 Transformer 或其某种变体作为底层模型架构。
2018 年时,一个新思潮开始流行(当然这个想法之前就有了)。也就是人们意识到大规模语言建模可以使用自监督数据完成。比如对于一段文本,你可以用其中一部分来预测文本的其他部分。这样做能够得到一些问题的答案。实际情况也证明了这一点。并且人们也发现,使用更多数据可以让模型变得更好。

这类模型有多种训练目标。一是自回归,即查看前面的词来预测下一个词。今天大多数模型都采用了这种形式。另一种则是填空。上图中展示了一些例子。
这两种训练目标都非常有用。自回归式如今被用得更多,比如你在与聊天机器人对话时,模型就在根据之前的对话进行自回归预测。
2021 年,谷歌开发了一种方法,可将图像任务映射到基于 Transformer 的模型。在此之前,大多数人都在使用某种形式的卷积神经网络。本质上讲,图像可被分解成像素块;就像 Word2Vec 将词嵌入到密集表示中一样,也可以对像素块做类似的事情 —— 用一些高维向量来表示这些块。然后,就可以将它们输入到 Transformer 模型,使其能够处理图像数据。现在我们知道,图像和文本还可以组合成多模态数据。因此,这项研究在统一文本 Transformer 和图像 Transformer 方面产生了巨大的影响。

另外,在 2017 年,Jeff Dean 还参与开发了一种创造稀疏模型的方法。本质上讲,就是对于一个很大的模型,仅激活其中一小部分,而不是针对每个 token 或样本都激活整个模型。

在最初的论文中,实际上有相当多的专家 —— 每层有 2048 名专家。而每次会激活其中 2 个。这很不错,因为模型现在有了非常大的记忆能力,可以记住很多东西。并且选择具体激活哪些专家也可以通过反向传播以端到端的方式学习。这样一来,你可以得到擅长不同任务的专家,比如有的擅长处理时间和日期,有的擅长地理位置,有的擅长生物学。
然后,Jeff Dean 列出了更多谷歌在稀疏模型方面的研究成果,感兴趣的读者可以参照阅读。

2018 年,谷歌开始思考,对于这些大型分布式机器学习计算,可以有哪些更好的软件抽象。谷歌构建了一套可扩展的软件 Pathways 来简化大规模计算的部署和运行。

如上图所示,每一个黄点构成的框都可被视为一个 TPU Pod。当这些 TPU Pod 在同一栋建筑内时,使用该建筑物内的数据中心网络来保证它们互相通信。而当它们位于不同的建筑内时,可以使用建筑物之间的网络以及相同的数据中心设施。甚至可以将不同区域的 TPU Pod 连接在一起。
事实上,Pathways 给机器学习开发和研究人员的抽象之一是你只需要一个 Python 过程。Jax 本就有「设备(device)」的概念。比如如果你只是在一台机器上运行,里面有 4 块 TPU 芯片,当使用 Jax 和 Pathways 训练时,整个训练过程中所有芯片都将作为 Jax 的设备进行处理。依照这个机制,你可以用单一的 Python 进程管理成千上万个 TPU 设备。Pathways 负责将计算映射到实际的物理设备上。而自上周开始,Pathways 已开始向谷歌云的客户提供。
2022 年,谷歌一个团队发现,在推理时思考更长时间是非常有用的。基于此观察,他们提出了思维链(CoT)。

图中举了个例子:如果给模型展示一些示例,示例中如果包含得到正确结论的思考过程,那么 LLM 更有可能得到正确答案。
这个方法看起来很简单,而实际上却能极大提升模型的准确度,因为通过鼓励它们生成思考步骤,可以让它们以更细粒度的方式解决问题。
可以看到,在 GSM8K(八年级一般数学水平问题)上,随着模型规模增大,如果只使用标准提示方法,解决准确度会有一些提高,但如果使用思维链提示法,解决准确度则会大幅上升。
这正是在推理时使用更多计算的一种方式,因为模型必须在生成更多 token 之后才给出最终答案。
下面来看蒸馏 —— 也是谷歌发明的。2014 年,Geoffrey Hinton、Oriol Vinyals 和 Jeff Dean 最早开发出了这种名为蒸馏(Distillation)的技术,可用来蒸馏神经网络中的知识。这种方法能够将更好的大模型中的知识放入到一个更小的模型中。

在训练小模型时,比如想要其预测下一 token,典型方法是让其先根据前面的句子进行预测,如果对了,很不错,如果错了,就反向传播误差。
这种方法还不错,但蒸馏却能做到更好。
教师模型不仅会给小模型正确的答案,而且还会给出它认为这个问题的好答案的分布。也就是说,教师模型能提供更丰富的训练信号。这种非常丰富的梯度信号可以用来为较小模型的每个训练样本注入更多知识,并使模型更快地收敛。
如上图中表格所示。这是一个基于语音识别的设置,其中给出了训练帧准确度和测试帧准确度。
可以看到,当使用 100% 的训练集时,测试帧准确度为 58.9%。而如果只使用 3% 的训练集,可以看到其训练帧准确度还提高了,但测试帧准确度下降很明显,这说明出现了过拟合现象。但是,如果使用蒸馏方法,3% 的训练集也能让模型有很好的测试帧准确度 —— 几乎和使用 100% 训练集时一样准确。这说明可以通过蒸馏将大型神经网络的知识转移到小型神经网络中,并使其几乎与大型神经网络一样准确。
有意思的是,这篇论文被 NeurIPS 2014 拒了。于是他们只得在研讨会上发表了这篇论文。而现在,这篇论文的引用量已经超过了 2.4 万。
另外在 2022 年,谷歌一个团队研究了一种不同的将计算映射到 TPU Pod 以执行有效推理的方法。其中,有很多变体需要考虑,比如权重固定、X 权重聚集、XY 权重聚集、XYZ 权重聚集……

谷歌得到的一个见解是:正确的选择取决于许多不同的因素。正如图中所示,其中的圆点虚线是最佳表现。可以看到,随着批量大小的变化,最佳方案也会随之变化。因此在执行推理时,可以根据实际需求选择不同的并行化方案。
时间来到 2023 年,谷歌开发了一种名为推测式解码(Speculative Decoding)的技术,可让模型推理速度更快。这里的想法是使用一个比大模型小 10 到 20 倍的 drafter 模型,因为其实很多东西靠小模型就能预测,而小模型速度又快得多。因此,就可以将两者结合起来提升效率:先让小模型预测 k 个 token,然后再让大模型一次性预测 k 个 token。相比于让大模型一次预测一个 token,这种做法的效率明显更高。

Jeff Dean 表示:「所有这些结合在一起,真正提高了人们今天看到的模型的质量。」

从底层的 TPU 发展到高层的各种软件和技术进步,最终造就了现今强大的 Gemini 系列模型。

这里我们就不继续整理 Jeff Dean 对 Gemini 系列模型发展历程的介绍了。最后,他还分享了 AI 将给我们这个社会带来的一些积极影响。
他说:「我认为随着更多投资和更多人进入这个领域,进一步的研究和创新还将继续。你会看到模型的能力越来越强大。它们将在许多领域产生巨大影响,并有可能让更多人更容易获得许多深度的专业知识。我认为这是最令人兴奋的事情之一,但也会让一些人感到不安。我认为我们有 AI 辅助的未来一片光明。」

#从国家级实验室前沿技术到聚焦能源智能化落地
中科类脑获国家级产业资本亿元投资
在能源AI这个高门槛赛道,中科类脑完成了一场从技术攻坚到商业变现的深度突围。
单笔融资破亿,能源 AI 杀出实力派
「 AI 的尽头是能源!」马斯克与 Sam Altman 的隔空对话,将能源革命与智能革命的交汇点推向全球视野。当前,这一进程正在中国加速。
据统计,2024 年前三季度,能源行业大模型招标项目超 80 个,多数能源企业已建成自有模型,涵盖核电、电网、发电等多个领域。DeepSeek 爆火后,以国家电网、南方电网及五大发电集团为代表的能源央企,正加速推进 AI 融合应用。
在智能化转型浪潮中,能源行业 AI 大模型全栈解决方案提供商中科类脑宣布完成亿元级 B 轮融资。此轮融资由中国移动旗下的北京中移数字新经济产业基金独家战略投资,也是该基金在 AI 模型领域的又一重要布局。
此前,中科类脑已在 A 轮融资中获得合肥创新投等地方国资支持。此番「国家队」资本强势注入,不仅标志着中科类脑正式跻身「 AI 国家队」行列,更意味着其自主可控的技术体系进一步获得产业界的广泛认可。
从顶天到立地,七年锚定能源赛道
中科类脑成立于 2017 年,是中国科学技术大学赋权项目之一,也是类脑智能技术及应用国家工程实验室(以下简称「类脑实验室」)迄今唯一产业化单位,肩负「顶天立地」的成果转化使命与愿景。类脑智能技术通过模拟人脑神经机制实现认知突破,是国家下一代 AI 布局的核心方向。然而,如何将类脑实验室技术转化为产业应用?
知名管理咨询机构埃森哲曾指出:「未来的能源世界是一个由数以十亿计的可再生能源发电、储能、智能用电设备构成的『碎片化』能源系统」,它们在数字世界重构与融合根本离不开 AI 技术。
初创期的中科类脑虽开发出类脑云 OS 底座,却在业务聚焦上经历阵痛。2019 年,公司战略转向能源赛道,迎来关键转折。
作为国民经济的基础性产业,能源世界正在发生重大变革。供给侧(发电侧),随着分布式光伏、风电等可再生能源的广泛普及,其装机容量和发电量正在迅速增长;用电侧(负荷),随着新能源汽车的普及,自动驾驶、V2G(车辆到电网)等技术也在不断进步,推动交通行业电气化水平日益提升;输配电侧,电网作为承载电能转换利用和输送的「大动脉」,面临迫切的智能升级需求。
尤其是 2021 年 —— 十四五规划开局之年,「做好碳达峰、碳中和工作」 (亦即「双碳」)被列为重点任务之一,使得能源数字化有了更强的政策驱动性。中国能源研究会能源互联网专委会等发布的《数字能源发展白皮书 2023 》预测,到 2029 年中国数字能源产业市场规模将达 6384.43 亿元。中研普华数据显示,预计到 2029 年,中国数字能源市场规模将达到 881 亿美元。实验室的「顶天」技术可以大展拳脚。
例如,作为电网核心目标之一,电力运作体系的安全、可靠、经济及高效运行是关键。而在人力有限情况下,为实现设备巡视、集中监控、无人机飞巡等生产方式和作业模式逐步向数字化、智能化发展,需深度介入 AI 及物联网等技术,构建「健康诊断科学化、运行维护智能化、检修抢修精益化」新运检模式,保障电网安全运行,提高运检质量、效率和效益。
随着风能和太阳能等间歇性可再生能源发电占比不断增加,对精确发电量预测的需求水涨船高,与此同时,如何优化电力设备配置,提高电网调度运行效率也成为电网的必然选择。这些不稳定能源如何消纳以及保障能源的稳定提供,都需 AI 的核心技术——新能源的智能预测和区域调度决策技术。
「一米宽、千米深」
唯有全栈,方能「深耕」
谋定而后动。中科类脑建构起「全栈式」技术路径——从底层算力支撑、核心算法研发到上层场景应用,有效推动了前沿技术与真实业务场景的深度融合。目前,其产品和解决方案已覆盖发、输、变、配、用、安监等核心场景,并推出算电融合服务,凭借高精度、低成本、自主可控等优势获得市场高度认可,AI 项目复购率超 75% ,客户覆盖五大发电集团等 80% 的行业头部企业。

融合能源多模态大模型+DeepSeek的新一代智慧电站运维「智能体」系统
能源电力行业对安全性、鲁棒性(Robustness)要求极高,通用大模型(如 ChatGPT、DeepSeek )虽为「通才」,却因幻觉问题不可控、缺乏行业知识,难以满足全工况条件下的基线要求。为此,中科类脑基于电力场景知识,结合人类反馈机制,打造了能源多模态大模型。
该模型是一种模拟人脑多感官信息处理的先进视觉检测技术。它创新性地融合了图像和文字信息,使模型能更深入理解和识别复杂的能源场景。特别是在电力场景中,模型通过典型图例辅助,能更准确地检测难以用文字描述的缺陷。为解决数据不足问题,模型利用 SAM 等技术从无标签图像中学习,并能在少量标记样本下精准检测。针对实际应用,模型进行了国产化适配,使其能在昇腾 NPU 上高效运行,提升了推理速度和效率。

能源多模态大模型赋能电力业务应用
能源电力行业的特殊性决定了单纯提供算法模型难以真正深入。同时,能源行业涉及国家关键基础设施,全面的国产自主可控已成定局。中科类脑围绕能源场景,结合全国产化算力打造了与能源业务系统协同的数据采集、传输、分析到辅助决策的闭环系统,确保能源多模态大模型高质量迭代。同时,构建了全国产化的异构算力调度和大模型研发平台,确保大模型的高效快。
中科类脑自 2017 年起深耕异构算力系统研发,其自研平台具备高效调度、算力加速等能力。在多款国产芯片上,训练效能可达国际同级芯片的 80% ,满足自主可控需求;在大模型多机推理实测算力加速约 30% 。
此外,针对当下行业算力资源分布不均、调配不合理、存储架构不兼容等共性难题,中科类脑突破异构算力适配、调度、存储统一纳管等关键技术,可实现不同计算中心算力、网络、存储等资源的互联互通,可智能调配跨地域、跨架构、跨归属的算力资源。
夯筑壁垒,众人拾柴火焰高
在能源 AI 这个高门槛赛道,中科类脑用七年时间完成了一场从技术攻坚到商业变现的深度突围。电力行业的特殊性构筑了天然壁垒——系统复杂性、安全严苛性,这些看似阻碍的因素,恰恰成为中科类脑构建护城河的最佳材料。
在能源电力领域,能源多模态大模型预训练数据量已成规模,构建起强大的基础认知能力。同时,通过将大量电力的专家经验转化为模型的基础能力,资深工程师数十年的实践经验被转化为 AI 可理解的决策逻辑。更重要的是,三十类机理模型库的建立,确保了 AI 预测既符合物理规律又具备可解释性。
工程化能力是国产化落地的关键一跃。据了解,中科类脑通过建设淮海人工智能中心、合肥多元异构算力调度平台以及宁波东方理工智算中心等智算集群,沉淀出算力调度优化、算子融合加速、国产化 AI 芯片适配等核心工程能力。此外,公司同步推进的皖疆绿色算力科技产业园正加速布局低碳基础设施,为「东数西算」战略提供跨区域算力协同与绿色转型支撑。
服务创新是中科类脑的另一大特色。公司组建了一支由研发人员、数据专家以及能源市场专家构成的复合型团队,这些「行业翻译官」有效弥合了技术与业务之间的鸿沟。企业创新采用「开发-验证-迭代」的动态闭环体系,实现算法研发全链条的并行协同。经实证,这些创新不仅带来 10 倍审核效率飞跃,算法迭代周期也缩短了 60% ,成功推动 AI 技术完成从实验室到实用化的价值跃迁。
此外,团队还提供特定细分场景的设备诊断攻关服务。例如,通过多模态数据融合数据分析能力,结合运行工况与机理,实现变压器的综合诊断和状态评价,有效降低维护成本,并使变压器保持长周期稳定运行。
在能源电力这个复杂的巨系统面前,单打独斗难以推动行业智能化发展。为此,中科类脑采取了开放合作的战略,「我们需要更多的合作伙伴、更多的前沿技术共同投入到这个行业当中,一起推动行业的变革。」中科类脑董事长、90 后国家万人领军刘海峰曾说。
公司一方面与类脑实验室持续联动,通过技术资产成果转化等机制,将实验室在计算机视觉、多媒体内容处理、视频编解码等领域的前沿研究成果转化为产业应用,既保障了技术源头活水,又加速了科研成果转化。
另一方面,公司通过 BitaHub 社区开放算力资源与 AI 开发环境,支撑科研机构与企业的智能化转型,已实现能源电力能力向建材、水利、政务等行业的横向复制。
三层变现结构,迈向更广阔行业
目前,中科类脑的核心技术已在多个领域取得显著成效:为十余省市的 100 余座变电站提供智能化运维服务;助力安徽配网无人机诊断效率有效提升;在新能源领域打造了多个标杆项目,其中某央企智慧风电场站项目荣获「四星级」评定。
在商业模式上,公司构建了「算力调度-模型服务-应用订阅」的三层价值体系,正在实现从项目制向产品化的转型:标准化 AI 套件收入占比从过去的 20% 提升至 55% ,年度经常性收入数亿元,标杆客户年付费增长达 300% 。更值得一提的是,公司人效比达到行业平均水平的两倍。这些成绩充分验证了其专业化发展路径的商业价值。
人工智能赋能能源行业转型升级,是一条充满挑战却前景广阔的道路。正如刘海峰所言:「我们做好了至少 8-10 年的长期投入准备,扎根能源智能化领域,为国家的能源转型贡献科技力量。」
这种长期主义的坚持,也得到图灵奖得主约瑟夫·斯发基斯( Joseph Sifakis )近期观点的支持。前不久,在中关村论坛上,这位杰出计算机科学家指出,中国应制定独特的 AI 愿景。中国的 AI 具有强大的工业特征,可凭借雄厚的工业基础,打造智能电网、智能工厂、自动驾驶交通系统、智慧城市等智能产品和服务。
如今,中科类脑正将能源领域淬炼出的 AI 能力,不断向更广阔的工业制造场景延伸。技术「顶天」与产业「立地」之间,创新火花在这里持续迸发,推动行业巨轮远航。
#VITA-1.5
腾讯优图联合南京大学开源实时视频-语音交互大模型VITA-1.5
近年来,多模态大语言模型(MLLMs)主要聚焦在视觉和文本模态的融合上,对语音的关注较少。然而,语音在多模态对话系统中扮演着至关重要的角色。由于视觉和语音模态之间的差异,同时在视觉和语音任务上取得高性能表现仍然是一个显著的挑战。
论文标题:VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
论文链接:https://arxiv.org/pdf/2501.01957
代码链接(Star数破千):https://github.com/VITA-MLLM/VITA
视频 Demo Video:
VITA-1.5 的核心动机在于:
1. 增加语音模态:在视觉-语言多模态模型的基础上,增加语音输入和输出能力,使其能够高效处理视觉、文本和语音任务。
2. 快速端到端交互:避免使用独立的自动语音识别(ASR)和语音合成(TTS)模块与 LLM 级联的方案,显著提升交互时端到端响应速度。
VITA-1.5 的主要贡献如下:
1. 多阶段训练方法:提出了一种精心设计的多阶段训练策略,逐步训练大语言模型 LLM 理解视觉和语音信息。这种策略使得模型在保留强大的视觉-语言能力的基础上,进一步获得了高效的语音对话能力。
2. 端到端 Speech-to-Speech:采用端到端语音输入和语音输出方式,大幅提升了视觉-语音的性能表现。
3. 实时交互能力:VITA-1.5 能够实现接近实时的视觉-语音交互,是目前开源领域最快的视觉-语音交互模型。
4. 开源与社区支持:VITA-1.5 的训练和推理代码已开源,并在社区中获得了广泛关注(已取得 2.2K GitHub Star)。
VITA-1.5 致力于推动多模态交互系统的发展,向 GPT-4o 水平的实时交互迈出了重要一步。
1模型架构

VITA-1.5 的整体架构包括输入侧的视觉编码器和音频编码器,以及输出侧的端到端语音生成模块。与上一版的 VITA-1.0 不同,VITA-1.5 不再级联外部独立的 TTS 模块,而是实现了端到端的语音生成能力。模型采用“多模态编码器-适配器-LLM” 的配置,旨在通过联合训练提升视觉、语言和语音的统一理解能力。
1.1 视觉模态
视觉编码器
VITA-1.5 使用 InternViT-300M 作为视觉编码器,输入图像大小为 448×448 像素,每张图像生成 256 个视觉 token。对于高分辨率图像,采用动态分块策略以捕获局部细节,从而提升图像理解的精度。
视频处理
视频被视为多帧图像的特殊输入:
- 视频长度小于 4 秒时,均匀采样 4 帧;
- 长度在 4 至 16 秒之间时,每秒采样 1 帧;
- 长度超过 16 秒时,均匀采样 16 帧。视频帧不使用动态分块,以避免生成过多视觉 token,影响处理效率。
视觉适配器
通过一个两层 MLP 将视觉特征映射为适合 LLM 理解的视觉 token。
1.2 音频模态
语音编码器
音频编码器由多个降采样卷积层(4 倍降采样)和 24 层 Transformer 块组成,隐藏层维度为 1024。降采样层降低了音频特征的帧率,从而提高了处理速度。编码器参数量约为 350M,输出帧率为 12.5Hz。音频输入采用 Mel-filter bank features。
语音适配器
由多个 2 倍降采样的卷积层组成,用于进一步处理音频特征。
语音解码器
语音解码模块采用 TiCodec 作为 Codec 模型,使用一个大小为 1024 的单一码本。这种设计简化了推理阶段的解码过程。编解码器负责将连续的语音信号编码为离散语音 token,并能解码回 24,000Hz 的语音信号。
为了让 LLM 能够输出语音 token,VITA-1.5 在文本 token 的基础上增加了两个语音解码器:
1.非自回归(NAR)语音解码器:对文本token进行整体处理,建模语义特征,用于生成初始的语音 token 分布。
2.自回归(AR)语音解码器:基于 NAR 解码器生成的语音信息,逐步生成高质量的语音 token。
最终生成的语音 token 序列通过 Codec 模型解码为连续的语音信号流。
2训练数据

VITA-1.5 的多模态指令微调数据涵盖了多种类别,包括图像描述、问答数据,以及中英文数据。在不同训练阶段,选择性地使用数据子集以实现不同目标。主要数据类别如下:
1. 图像描述数据:包括 ShareGPT4V、ALLaVA-Caption、SharedGPT4o-Image 和合成数据,用于训练模型生成图像的描述性语言。
2.图像问答数据:包括 LLaVA-150K、LLaVA-Mixture-sample、LVIS-Instruct、ScienceQA、ChatQA,以及从LLaVA-OV 中采样的子集(如一般图像问答和数学推理数据),用于训练模型回答基于图像的问题,并执行视觉推理任务。
3. OCR 与图表数据:包括 Anyword-3M、ICDAR2019-LSVT、UReader、SynDOG、ICDAR2019-LSVT-QA,以及从 LLaVA-OV 中采样的相关数据,用于支持模型理解 OCR 和图表内容。
4. 视频数据:包括 ShareGemini 和合成数据,用于训练模型处理视频输入,并执行视频描述和基于视频的问答任务。
5. 纯文本数据:增强模型的语言理解和生成能力,支持文本问答任务。
此外,还引入了以下语音数据:
- 11 万小时的内部语音-转录配对 ASR 数据(覆盖中英文),用于训练音频编码器并将其与 LLM 对齐。
- 3000 小时由 TTS 系统生成的文本-语音配对数据,用于训练语音解码器。
3三阶段训练策略
为了确保 VITA-1.5 在视觉、语言和语音任务中表现出色,需要解决不同模态之间的训练冲突。例如,添加语音数据可能会对视觉内容的理解产生负面影响,因为语音特征与视觉特征差异显著,会在学习过程中造成干扰。为了解决这个问题,设计了一个三阶段的训练策略。核心思想是逐步将不同模态引入模型,使其在增强新模态能力的同时,保持现有模态的能力。
3.1 阶段1:视觉-语言训练

阶段1.1 视觉对齐
目标是弥合视觉和语言之间的差距。视觉特征通过预训练的视觉编码器 InternViT-300M 提取,语言通过 LLM 引入。使用 20% 的描述性 Caption 数据进行训练,仅训练视觉适配器,其他模块冻结。这种方法使得 LLM 初步对齐视觉模态。
阶段1.2 视觉理解
目标是教会 LLM 转录视觉内容。使用全部描述性 Caption 数据,训练过程中视觉模块的编码器和适配器以及 LLM 都是可训练的。重点是通过学习关于视觉的描述性文本,使模型能够通过生成对应的自然语言描述。
阶段1.3 视觉指令微调
在阶段 1.2 之后,模型已获得对图像和视频的基本理解,但指令跟随能力仍有限,难以应对视觉问答任务。在这一阶段使用所有问答数据,同时保留 20% 的描述性 Caption 数据,以增加数据集的多样性和任务的复杂性。训练期间,视觉模块的编码器和适配器以及 LLM 都是可训练的,目标是使模型不仅能够理解视觉内容,还能够根据指令回答问题。
3.2 阶段2:音频输入微调

阶段2.1 音频对齐
完成阶段 1 的训练后,模型在图像和视频理解方面已打下坚实基础。本阶段目标是在阶段 1 的基础上减少语音和语言之间的差异,使 LLM 能够理解音频输入。训练数据包括 11,000 小时的语音-转录对。采用两步法:
(a)语音编码器训练:使用 CTC 损失函数训练语音编码器,目标是让编码器从语音输入中预测转录文本。确保音频编码器能够提取语音特征并将其映射到文本表示空间。
(b)语音适配器训练:训练语音编码器后,将其与 LLM 集成,使用音频适配器将音频特征引入 LLM 的输入层。本阶段的训练目标是使 LLM 输出语音数据的转录文本。此外,在步骤(b)中引入特殊的可训练
输入 token,以引导语音理解过程,这些 token 提供额外的上下文信息,引导 LLM 执行 ASR 任务。
阶段2.2 音频指令微调
本阶段重点是引入语音问题和文本答案的问答功能。为此,从数据集中抽取 4% 的 Caption 数据和 20% 的问答数据。数据处理方面,大约一半的基于文本的问题被随机替换为其对应的语音版本,由外部的 TTS 系统生成。本阶段视觉编码器和适配器、音频编码器和适配器以及 LLM 均是可训练的,旨在提高模型对多模态输入的适应性。
此外,在 LLM 的输出中添加一个分类头,用于区分输入是来自语音还是文本,从而使模型能够更高效灵活地处理不同模态。
3.3 阶段3:音频输出微调

在前两个训练阶段,VITA-1.5 模型已经获得了多模态理解能力。然而,作为一个交互助手,语音输出是必不可少的功能。为了在不影响模型基本能力的情况下引入语音输出功能,采用了 3,000 小时的文本-语音数据,并使用两步训练方法:
阶段3.1 Codec 模型训练
目标是使用语音数据训练一个单一码本的 Codec 模型。Codec 的编码器能够将语音映射为离散 token,其解码器可以将离散 token 映射回语音信号。在 VITA-1.5 的推理阶段,仅使用 Codec 的解码器。
阶段3.2 NAR+AR 语音解码器训练
这一步使用文本-语音配对数据进行训练。其中,文本输入到 LLM 的 tokenizer 和 Embedding 层以获取其 Embedding 向量,而语音输入到 Codec 的编码器以获取其语音 token。
文本 Embedding 被送入非自回归语音解码器(NAR)以获得全局语义特征,然后这些特征被送入自回归语音解码器(AR),以预测相应的语音 token。LLM 在此阶段是完全冻结的,因此此前的多模态性能不受影响。
4
实验发现
4.1 视觉-语言评估

▲ 图像理解能力评测

▲ 视频理解能力评测
上表展示了 VITA-1.5 在图像理解性能上的对比。经过三阶段训练后,VITA-1.5 的表现可与最先进的开源图像-语言模型媲美,显示了 VITA-1.5 在图像-语言任务中的强大能力。在视频理解评估中,VITA-1.5 的表现与顶尖开源模型相当。但与私有模型仍有较大差距,这表明 VITA-1.5 在视频理解方面仍有较大的改进空间和潜力。
VITA-1.5 的一个亮点在于,在第二阶段(音频输入微调)和第三阶段(音频输出微调)训练后,VITA-1.5 几乎保留了其在第一阶段(视觉-语言训练)中的视觉-语言能力,尽量避免了因为引入语音信息导致多模态能力下降。
4.2 语音识别能力评估

基准模型
使用了以下三个基准模型进行比较:Wav2vec2-base、Mini-Omini2、Freeze-Omini 和 VITA-1.0。
评估基准
中文评估集包括三个数据集:aishell-1、test net 和 test meeting。这些数据集用于评估模型在中文语音上的表现,评估指标是字符错误率(CER)。英文评估集包括四个数据集:dev-clean、dev-other、test-clean 和 test-other,用于评估模型在英语语音上的表现,评估指标是词错误率(WER)。
ASR性能
评估结果表明,VITA-1.5 在中文和英文 ASR 任务中均达到了领先的准确性。这表明 VITA-1.5 成功整合了先进的语音能力,用以支持多模态交互。
5
未来工作
VITA-1.5 通过精心设计的三阶段训练策略整合视觉和语音。通过缓解模态之间的固有冲突,VITA-1.5 在视觉和语音理解方面实现了强大的能力,能够在不依赖于独立的 ASR 和 TTS 模块的情况下实现高效的 Speech-to-Speech 能力。不过其实验和文章内容也指出了一些可能的未来改进工作:
增强语音生成质量:虽然 VITA-1.5 已实现内置语音生成能力,但进一步提升生成语音的自然度和清晰度,尤其是带情绪的输出,仍是一个重要的研究方向。
多模态数据扩展:引入更多样化的多模态数据集,尤其是涵盖更多场景和语言的语音数据,将有助于进一步提升模型的泛化能力和适应性。
实时性和效率优化:在保持高性能的同时,进一步优化模型的计算效率和实时响应能力,以便在资源受限的环境中也能有效运行。
#用极小模型复现R1思维链的失败感悟
本文分享作者尝试用0.5B参数的小模型复现R1思维链训练的失败经历,详细记录了在强化学习训练过程中遇到的模型推理过程变短、难以学习复杂问题等挑战,以及对可能原因的分析和总结。
更新:已成功让0.5B模型学会更长思考
无需冷启动,0.5B模型学会更长思考!:https://zhuanlan.zhihu.com/p/30261822063
2025.3.5更新
没想到这篇文章这么火,还有两位大佬转载了我的文章,DeepSeek的流量确实太大了。首先感谢各位的点赞收藏和评论,我尽量回复大家的评论。针对一些常问的问题在这里做个总结。
- 文章中ppl是什么? ppl在这里指KK数据集中某个逻辑问题里有多少人,在谁是说谎者的推理中,人数越多问题就越复杂。附上数据集项目链接:On Memorization of Large Language Models in Logical Reasonin(https://memkklogic.github.io/)
- 入门RL有无推荐资源? 我是看YouTube上的一些视频教程先总体过了一遍,然后跟着HuggingFace的RL系列课程学,它每节课都有配套代码,最后找了一些paper具体看了下推导细节。也推荐easyRL,开源的RL书籍。
后面我将继续抽空探索R1的training dynamic,但因为除了R1以外还有不少其它project,可能得消失一段时间啦。在这里开源wandb的训练记录,大家可以看到更多细节https://api.wandb.ai/links/nextgen-ai-research/2vyg26ie
投完ICML之后火急火燎的入门RL,花了一些时间把RLHF学了。后来在知乎上看到了很多优秀的开源R1复现项目,于是手痒痒啃了下比较火的两个开源项目准备自己实践一下,一个是Huggingface的Open-R1,一个是Logic-RL。由于Logic-RL基于Verl,模型推理和训练过程都是shard到不同显卡上的,Huggingface的GRPOTrainer是单独用一张显卡做vllm推理,所以我在浅尝Open-R1做数学题的训练之后转移到了Logic-RL上面。
因为是民科,手上只有四张降了功率的3090,我就拿0.5B的千问做的实验,中间遇到了不少问题。
探索0.5B模型在KK数据集上的强化学习训练
1.多余的reward会让模型变懒
我首先是使用了Logic-RL中原来配置的reward规则,在原版规则中,模型学会格式后会得到一定奖励,但很快模型的输出就变得很短
The reasoning process here involves understanding the characteristics of knights and knaves, analyzing the statements made by each person, and determining who is a knight and who is a knave.
Ethan is a knight, David is a knave, Samuel is a knight.<|im_end|>
然后模型几乎不care回答是否正确,输出长度急剧下降到只有几十个的长度。于是我尝试更改规则,仅当模型格式正确且回答正确的时候才有reward,其余情况都是最低分。
但令人没想到的模型依然只是水一下思考内容,然后在answer tag里输出答案,似乎只要遵循的格式就会让模型放弃思考过程。我后来将格式reward中有关的要求去掉了,在训练过程中就能顺利保留下来模型的思考过程。
2. 模型很难直接学习3ppl以上的问题
0.5B模型可能是太小了,直接混合3ppl-7ppl的数据集训练会导致reward一直在最低分附近震荡,然后一会就开始输出胡言乱语。训练开始没多久我就看到输出长度爆炸增长,我以为是长思维链的出现,但其实是模型错误预测token导致输出大段胡言乱语。
于是,我转换了2ppl的数据集,让模型在2ppl数据集上先进行10个step的学习,然后在3ppl数据集上进行20个step的学习,再换到4ppl上进行10个step,5ppl上训练10step,最后换到6ppl上进行长的RL训练。这类似于课程学习,但在训练结束后我是保存了模型之后在新的训练中加载保存的模型,所以相当于reference model被更新了。
这个过程中确实观察到了一些有意思的现象,例如
错误检查
- Avery's statement: If Jacob is a knight, then Avery must be a knave, regrettably (vice versa). Since Jacob is not a knight, there's a contradiction here, indicating a mistake in our reasoning. Alternatively, if Jacob is a knight, Avery must be a knave, meaning Jacob cannot be the perfect knight according to her statements.
Recheck
So, the contradiction here comes from Scarlett being a knight. This means the first term is misleading. Let's recheck the clues.
虽然感觉推理过程好像不是很对。。。
还有一些输出我没有保存,例如语言混杂,使用数学来解逻辑问题,以及使用什么蕴含树?来解决问题的过程也是有的。
3. 模型总是会收敛到一个极短的推理过程
这也是为什么说复现是失败的,虽然通过前面的修改模型能顺利学到6ppl的问题上,但是模型的推理过程总是会变得极为简单,我分别多次尝试了在预热训练(前面提到的课程学习)后在5ppl和6ppl的数据集,或者混合的数据集上训练,都会出现思维链随着准确度越来越高下降的过程

5ppl上长训练,思维链长度下降

6ppl上长训练,思维链长度下降
观察模型的输出,它最后都会收敛到一个固定的,甚至是错误的推理模式
To determine the identities of each character, we will analyze each statement step by step.
- Avery's statement: "Zoey is a knight if and only if Aiden is a knave." Therefore, Zoey is a knave if Aiden is a knight.
- Zoey's statement: "Aria is not a knave." Hence, Aria is a knight.
- Lily's statement: "Zoey is a knight and Aiden is a knight." Therefore, Zoey is a knight.
- Evelyn's statement: "Aria is a knave or Lily is a knight." Since Aria is a knight, Evelyn must be a knight.
- Aria's statement: "Evelyn is a knight or Avery is a knave." Since Avery is a knight, Aria's statement is true, so Aryan is a knight.
- Aiden's statement: "Avery is a knave." Therefore, Aiden is a knave.
So, the identities of the characters are:
- Avery is a knave,
- Zoey is a knight,
- Lily is a knight,
- Evelyn is a knight,
- Aria is a knight,
- Aiden is a knight.
The final answer is:
(1) Avery is a knave, (2) Zoey is a knight, (3) Lily is a knight, (4) Evelyn is a knight, (5) Aria is a knight, (6) Aiden is a knight.<|im_end|>
模型的回答固定为(1)总起,一步一步推理。(2)先重复每个人的话,在后面紧接着做推理。(3)给出答案。(4)在tag里给出答案。
但是,当我们仔细检查推理过程的时候,发现这个推理是错的,但答案是对的。例如第四条,Since Aria is a knight, Evelyn must be a knight,第五条Aryan名字都没出现过。当然最明显的,推理过程得到的结论,例如第六条Aiden is a Knave和答案Aiden is a knight根本也对不上。
虽然Logic-RL论文中Instruct模型也是经历了输出长度下降之后上升

图源Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
但是我这里并不能在下降后上升,因为在32次rollout中,模型的输出几乎都一模一样了,模型的最短回答和最长回答几乎都收敛了,即模型不再探索新的可能性,熵已经收敛了。
可能原因的讨论
我对于rule based reward+RL训练的理解是,这个过程类似于抽签+筛选。如果抽到了正确的回答,那模型就知道这一次它是做对了的,会继续往这个方向靠,如果回答错误就被惩罚,抛弃这个action,被筛选掉。我们不断抽签过程中,模型的某些行为会被我们保留下来并强化,某些行为会被我们抛弃。
那么首先是筛选过程可能不准确,例如某次回答中模型不思考或胡乱思考,直接猜答案,但是答案猜对了,得到了reward,另一次回答进行了详尽且前后consistent的推理,但不幸答案是错的,那么这个行为会被筛掉。
对于简单的问题,小模型可通过简短的推理,或者直接给出答案的方式做对题,那么这些行为都会被保留下来。但对于难的问题,小模型一开始会尝试使用长思维链解决这个问题,但因为能力不足,它总是答不对,那么长思考的行为就会被我们筛选掉。
总的来说,我感觉是我们抽不出来小模型使用长思维链做对题的签,所以导致思维链收敛到很短。而因为直接给答案做对题概率可能更大,模型对于思考过程几乎不完善,而直接去学从prompt到答案的映射。随着训练进行,模型在val set上的准确度是越来越高的,在我的训练步数内,5ppl上能达到33%,6ppl上能达到22%,且还没有饱和,所以它是有能力做对题,但肯定不是靠思维链做对题。
而大的模型本身应该就有抽出长思维链+正确答案的潜力,所以这个行为能被我们保留并强化,在训练后期,简单题(例如仅靠一次前向推理就能确定所有人的身份)被学完,而后,当rollout出模型依靠更长思维链解决难题的样本后模型自然就会往长思维链解决难题上靠。
总结
总的来说,这次做的几次实验都没成功,模型太小肯定是个问题。换个大一点的模型试试吧,不知道我的四张3090还能不能撑得住。
由于刚入坑RL,很多东西都是速成的,可能理解上有误,还请见谅。
#OmniSVG
好玩!复旦与阶跃星辰联合发布SVG矢量图生成大模型OmniSVG!挑战3万Token极限
在日常生活中,SVG(可缩放矢量图形)被广泛应用于网页设计、图标、徽标等领域。SVG 图形因其可缩放性和清晰度,在以下场景中得到了广泛应用:
- 网页设计:用于制作响应式图标、按钮和装饰元素,确保在不同设备上显示清晰。
- 品牌标识:企业徽标、品牌图形等,保持高质量的视觉效果。
- 用户界面设计:应用程序和网站的界面元素,如导航栏、菜单图标等。
- 教育与培训材料:用于制作插图、流程图和示意图,帮助信息传达。
然而,创建这些图形通常需要专业的设计技能和工具。对非专业人士而言,存在一定的门槛。因此,开发自动化的 SVG 设计与生成工具显得尤为关键。
现有基于优化的方法通过优化可微分的矢量图形光栅化器,迭代地调整 SVG 参数。这些方法在生成 SVG 图标方面有效,但在处理复杂样本时计算开销较大,且生成的输出缺乏结构,存在冗余的锚点。
在现有自回归 SVG 生成方法中,存在两个主要局限性:
- 上下文窗口长度限制:由于模型只能处理有限长度的输入序列,这限制了其生成复杂 SVG 内容的能力,现有自回归方法利用 Transformer 模型或预训练的大型语言模型(LLM),直接生成表示 SVG 的 XML 参数或代码,然而复杂 SVG 需要的上下文长度将超出现有 LLM 上下文窗口长度,从而限制了复杂 SVG 的生成;
- 复杂 SVG 数据匮乏:缺乏包含复杂 SVG 内容的大规模数据集,限制了模型的学习和生成能力。现有数据集通常包括 icon 级别的 SVG 或者较为简单的插画 SVG,目前角色复杂度级别的 SVG 数据集仍然是空缺。
项目中,OmniSVG 引入 SVG 参数化的表达方式,自回归地生成高质量、复杂的 SVG。它通过多种生成模式展示了非凡的多功能性,包括文本到 SVG、图像到 SVG 和角色参考生成 SVG,使其成为适用于各种创意任务的强大而灵活的解决方案。
- 论文标题: OmniSVG: A Unified Scalable Vector Graphics Generation Model
- 论文作者:Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Jiaxu Zhang, Liao Wang, Gang Yu, Xingjun Ma, Yu-Gang Jiang
- 作者单位:复旦大学、阶跃星辰
- 论文地址:https://arxiv.org/pdf/2504.06263
- 项目主页:https://omnisvg.github.io/
- 代码地址:https://github.com/OmniSVG/OmniSVG
- HuggingFace:https://huggingface.co/OmniSVG
值得一提的是,OmniSVG 在发布的当天就成为 Huggingface daily paper upvoted 的第一名,并成为当周排名第二热门的论文。OmniSVG 在 GitHub 上线 7 天,已经斩获了 1.3k star,在国外媒体获得广泛关注。

Huggingface当周第二热门论文

让我们先来看一些生成效果:



1.统一的多模态复杂 SVG 生成框架
OmniSVG 是首个利用预训练视觉语言模型(VLM)进行端到端多模态复杂 SVG 生成的统一框架。通过将 SVG 的坐标和命令参数化为离散的标记,OmniSVG 将结构逻辑与低级几何信息解耦,缓解了代码生成模型中常见的 「坐标幻觉」问题,生成生动且多彩的 SVG 结果。并且得益于下一标记预测的训练目标,OmniSVG 能够在给定部分观测的情况下,生成多样化的 SVG 内容。与传统的自回归 SVG 生成方法相比,OmniSVG 能够处理长度高达 3 万个token 的 SVG,促进了复杂高质量 SVG 的生成。基于预训练的 VLM,OmniSVG 能够理解视觉和文本指令,合成可编辑的高保真 SVG,适用于从图标到复杂插图和动漫角色等多种领域。

OmniSVG 基于预训练的视觉语言模型 Qwen2.5-VL 构建,并集成了 SVG 分词器。该模型将文本和图像输入分词为前缀分词,而 SVG 分词器则将矢量图形命令编码到统一的表示空间中。

2.MMSVG-2M:包含 200 万个 SVG 样本
项目还开源了 MMSVG-2M 数据集和 MMSVG-Bench 评测平台。MMSVG-2M 是一个大规模的 SVG 数据集,包含了 200 万个 SVG 样本,涵盖了网站图标、插图、平面设计、动漫角色等多种类型。MMSVG-2M 数据集的 SVG 样本,涵盖了网站图标、插图、平面设计、动漫角色等多种 SVG 类型,如下图所示。

3. 实验结果
为了进一步推动 SVG 生成技术的发展,MMSVG-Bench 评测平台专注于以下三个主要任务,分别是文本转 SVG、图像转 SVG 以及角色参考生成 SVG。
论文在 MMSVG-2M 数据集(图标、插图和角色)上将所提出的方法与 SOTA 文本转 SVG 和图像转 SVG 均进行了比较。OmniSVG 在指令遵循性和生成的 SVG 的美观性方面均优于现有的最佳方法。

OmniSVG 和最先进的文本转 SVG 任务的比较结果。

OmniSVG 和最先进的图像转 SVG 任务的比较结果。

通过使用自然角色图像和 SVG 数据对进行训练,OmniSVG 能够通过图像角色参考生成角色 SVG。
结论与局限性
综上所述,OmniSVG 是一种统一的可缩放矢量图形(SVG)生成模型,利用预训练的视觉 - 语言模型(VLM)进行端到端的多模态 SVG 生成。通过将 SVG 命令和坐标参数化为离散标记,OmniSVG 有效地将结构逻辑与低级几何信息解耦,提高了训练效率,同时保持了复杂 SVG 结构的表现力。此外,OmniSVG 在多个条件生成任务中表现出色,显示出其在专业 SVG 设计工作流中应用的巨大潜力。
不过,在推理过程中,OmniSVG 会为复杂样本生成数以万计的标记,这不可避免地会导致相当长的生成时间。同时,在可预见的未来,将 SVG 风格的图像和来源更丰富的自然图像,融入协同训练工作流,有望提升模型对输入图像风格的鲁棒性。
#有没有LoRA更好的大模型微调方法?
最近本人一直在研究 SFT 的落地工作,其中 LoRA 是一个无法避开的微调技术。相比全参数微调,LoRA 提供了一种更为友好和安全的微调方案。
首先,LoRA 在资源使用上更为高效。它能显著节省显存,使得我们在有限的计算资源下也能训练 size 更大的模型。其次,LoRA 具有一定的正则化效果,类似于 dropout 或 mask。这种特性使得模型在学习下游任务时,能够减少遗忘现象, 关于这方面的详细分析,可以参考 LoRA Learns Less and Forgets Less。
然而,在实际应用中, 本人还存在很多疑问。例如,为什么 LoRA 的收敛速度相对全参数微调很慢?LoRA 能否达到与全参数微调相媲美的效果?如何选择 LoRA 的 rank 值?这些问题都值得深入探讨。
为了深入挖掘 LoRA 的潜能,解答这些问题并探索 LoRA 在大模型微调中的各种可能性。希望通过这篇文章,能为大家带来新的视角和思考。
前置的线代知识
在讨论各种方法之前,有必要先介绍下线性里面的两个知识点,因为跟后面提出的方法紧密相关.
- 矩阵的秩:大家知道, 矩阵在大多数清况下代表映射. 而矩阵的秩几何意义就是映射后的目标空间是几维的, 我们把它称为像空间 ImA
- SVD定义: 给定大小为 的实数矩阵 A , 其中 m 可以等于或不等于 n ,对 A 进行 SVD 后得到的输出为 。左式表示 SVD 会将大小为 的实数矩阵 A 分解为 的正交矩阵 U 、 的对角矩阵 以及 的正交矩阵 V 。由于正交矩阵的逆就是其转置矩阵,因此
- 性质 1: 对于矩阵 A ,, . 从直观上是显然的, **前者成立的原因在于,从根本上将,目标空间是 m 维的,而包含在其中的 ImA 无论也不可能让自己的维度超过 m . 对于后者, 因为原空间是 n 维的,于是把空间全体通过 A 映射过去,无论如何也不可能超过自己原来的维度 n **.
- 性质 2: 假如矩阵 A 能分解成两个“瘦矩阵的乘积”, 既宽仅为 r 的矩阵 B 和高仅为 r 的矩阵 A 的乘积, A=BC , 则 A 的秩一定不会超过 r.
右面是例子是秩为 2 的情况.例如地,对于 rank(A)=1 的极端清况,可以写成列向量和行向量的乘积的形式,如下所示.
A=BC 在 y=Ax 的变换过程中,分成以下两步进行
第一步 z=Cx 对应 n 维向量 x “压缩”成 r 维向量 z
第二步 y=Bz 对应 r 维向量 z “扩张” 成 m 维向量 y
若矩阵可以进行这样的瓶颈型分解,则 A 的秩显然不超过 r ,只要一度被压缩到低的 r 维,无论怎么扩张,也不可能使维度增加了,因为 ImA 一定不超过 r 维,也可以说,丢失的信息就找不回来了. - 举个例子 y=Ax, 假设这里 A 是一个 3×3 的矩阵, A 对应的映射为是”x所在的 3 维空间”到“y 所在的 3 维空间”的映射. 假如某个矩阵 , 大家有没有发现, 任何一个三维向量经过 A 映射后, z轴(也就是第三维度)的信息都丢了,直接地说所有的三维向量经过 A 映射后都“压缩”到 xy轴张成的平面上. 任何一个3维向量,经过上述的A 映射后,得到的虽然表面上也是三维向量,但这些得到的三维向量张成的空间是3 维向量空间中的一个 2 维线性子空间. 也就是映射后的目标空间是 2 维的, 因此 rank(A)=ImA=2 .那么,问大家一个问题, 矩阵 的秩等于多少呢? 答案是这个矩阵的秩为 1 .
- 知道矩阵秩的几何意义后,就好办了, 这里闲聊秩的两个性质
- SVD分解(奇异值分解): 线性代数的世界里很多分解。 但SVD的魅力最大。原因有两个:第一,SVD对矩阵的形状没什么要求,任何矩阵都可以分解;第二,它能帮我们提取出矩阵中最重要的部分,而恰恰我们很多场景都要分析重要性。

这样的分解能分解出重要性. 例如假设现在某个矩阵好大,维度为 10000✖️10000, 本来要存 10000* 10000的参数. 但经过分解后, 发现第一个奇异值和第二个奇异值,已经占了总奇异值的 90%, 那我们现在只要存, 也是就 4 个奇异向量和两个奇异值,一共4* 10000+2个参数,就能恢复这个矩阵的 90%! 压缩比达到2500! 这就是SVD分解的魅力
- SVD几何意义: 本质是变基(变到 V 表示的正交基,对应乘以), 再拉伸压缩(对应乘以), 再旋转(对应乘以 U ), 详细的可以看https://www.bilibili.com/video/BV15k4y1p72z/?spm_id_from=333.337.search-card.all.click&vd_source=85b8a3ae5654a8e5f740cb43ae25c959
聊聊 LoRA
LoRA: Low-rank adaptation of large language models.
22年微软的工作
Lora 原理:
通过在已经预训练的模型权重基础上添加两个低秩矩阵的乘积来进行微调。具体来说,权重矩阵维被分解为一个高瘦矩阵 维和一个矮胖矩阵维的乘积,从而达到降低秩的目的(回想一下秩的性质,因为能这样分解, 因此最终)。
Lora论文中埋下的伏笔(都是后续工作的优化点):
- 初始化方式:在原论文中,矩阵 A 使用随机高斯分布初始化,而矩阵 B 使用零初始化。这意味着训练一开始时,。是否存在更好的初始化方法,可能可以加速训练或提高性能? 当然是肯定有的.
- 缩放因子的作用:按照进行缩放,其中是关于 r 中的一个常数, 例如在 llama_factory 里,假如你不指定,那会把设置为 r 的两倍。调节大致等同于调节学习率。因此,论文将设为他们尝试的第一个,并保持固定不变。这种缩放机制的引入有助于在调整超参数时减少过多的重新调节需求。
- 旁路矩阵的应用范围: 在原论文中,LoRA 仅在注意力层引入了旁路矩阵,并且所有层的秩参数 r 都被统一设置为 1、4 或 8,没有根据不同层的特点进行区别设置。
Lora 碎碎念
碎碎念1: Lora work的原因:
Lora 效果能好是建立在以下的假设上, 在预训练阶段,模型需要处理多种复杂的任务和数据,因此其权重矩阵通常是高秩的,具有较大的表达能力,以适应各种不同的任务。然而,当模型被微调到某个具体的下游任务时,发现其权重矩阵在这个特定任务上的表现实际上是低秩的。也就是说,尽管模型在预训练阶段是高维的,但在特定任务上,只需要较少的自由度(低秩)就可以很好地完成任务。基于这一观察,LoRA提出在保持预训练模型的高秩结构不变的情况下,通过添加一个低秩的调整矩阵来适应特定的下游任务。
碎碎念 2: 训练能省多少?
- 已模型的其中一个矩阵为例: 例如 Qwen2-72B, transformers block 全连接模块的第一个全连接矩阵维度为 8192* 29568, 假如全参数微调, 单微调这个矩阵就涉及242M个参数, 假如用 Lora 微调并取 rank=8呢? 涉及的参数量为81928+29568* 8=0.3M, 只有原来的0.12%!
- 已微调整个模型为例: 以微调整个模型为例,假设使用的是 fp16 精度,模型训练时显存的占用可以分为以下几部分 (参考https://huggingface.co/docs/transformers/model_memory_anatomy#anatomy-of-models-memory)
- 模型权重: 2字节 * 模型总参数量 + 4 字节 * 训练参数量(因为在内存中需要保存一个用于前向传播的 fp16 版本模型,但训练的参数会保留一个 fp32 的副本)。
- 梯度: 4 字节 * 训练参数量(梯度始终以 fp32 格式存储)。
- 优化器: 8 字节 * 训练参数量(优化器维护 2 个状态)。
- 中间状态: 由很多因素决定,主要包括序列长度、隐藏层大小、批量大小等。
- 临时缓存: 临时变量,如为前向和后向传递中的中间量提供临时缓冲,如某些函数占用的缓存, 它们会在计算完成后被释放。
在不考虑中间状态和临时缓存的情况下, 单卡全参数微调 Qwen2-72B 需要的显存大小是18* 72=1296GB,显然这是不可能实现的。即使使用 8 卡并开启 DeepSpeed Zero3(将权重、梯度和优化器都切分到 8 卡上),每张卡的显存需求仍然为 162 GB,也依然过高。 假设使用 LoRA 微调,假设 LoRA 训练参数量仅为原模型全参数量的 1%,则单卡所需的显存可以按以下方式计算:显存需求 =2×模型总参数量+(4+4+8)×训练参数量×0.01=155G. 假如8卡并开启 Zero3,是能把 72B 模型跑起来的。
碎碎念 3: 推理时能省多少?
在推理过程中,LoRA 的低秩调整矩阵可以直接与原始模型的权重合并,因此不会带来额外的推理延迟(No Additional Inference Latency)。这意味着,在推理阶段,计算效率与原始模型基本相同。
碎碎念 4: 不同的高效微调方法
目前,LoRA 已成为主流的高效微调方法之一。与其他方法相比:
- Adapter: 在层之间并行添加额外的结构,但这种额外结构无法与原始权重合并,导致推理时不仅需要更多内存,还会带来推理延迟。
- Prefix tuning: 通过占用输入 token 来实现微调,结构不够优雅,可能影响输入处理。
- LoRA: 训练稳定,效果与其他方法相当,但推理时不产生额外延迟,且不增加显存需求,因而是首选。
碎碎念 5: 高效微调与全参数微调怎么选
谨慎使用全参数微调,除非同时满足以下两个条件
- 你的训练集很大,(通常需要成千上万)
- 你对训练数据集质量非常有信心,包括数据的一致性,多样性.
如果无法同时满足这两个条件,全参数微调的效果可能不如 LoRA。这是因为大模型的拟合能力过强,数据量不足或质量不高时,模型很容易过拟合,反而降低效果。在微调过程中,数据集的构建至关重要。对于如何构建合适的微调数据集,推荐阅读这篇文章:How to Fine-Tune LLMs: PEFT Dataset Curation。、
聊聊Lora 训练时我观察到的现象
现象 1: Lora 模型在训练过程中收敛速度较慢。例如,在实际业务场景中,通常需要训练到 10 个 epoch 左右,才在测试集上取得最高分,而全参数微调模型通常在 3-4 个 epoch 后就能达到最佳效果。此外,Lora 的拟合能力也较弱,模型对训练集的内容记忆不佳。现象 2: 在处理某些复杂任务时,我尝试将 Lora 的 rank 参数增大至 64 或 128,结果模型性能反而下降,甚至出现训练崩溃、梯度变成 nan 的情况。这与直觉相悖,因为理论上对于复杂任务,rank 越大意味着可调整的参数越多,模型的效果理应更好。
ADALoRA:建模成 SVD 分解的形态,每次更新根据重要性得分来取哪些
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
2023年3月
- 研究动机
原生 Lora 方法在每个 attention 层都引入了一个秩为 4 的矩阵,采用的是均分策略。然而,直觉告诉我们,模型中的某些矩阵比其他的更为重要,应该分配更多的参数来进行调整,而有些矩阵则相对不重要,不需要过多修改(回想 BERT 时代的经验,我们认为靠近输入层的权重主要学习语法和词法结构,微调时变化较小;而靠近输出层的权重主要涉及语义知识,需要根据下游任务进行较大的调整)。总而言之,Lora 这种“均分参数”的策略显然不是最优的。论文由此提出一个核心问题:
如何根据transformer不同层,不同模块的重要性自适应地分配参数预算,以提高微调的性能?
- 方法论
- 考虑到参数的重要性,自然会想到使用 SVD(奇异值分解)。SVD 的作用在于将矩阵分解为若干个不同重要性的分量之和。因此,一种直观的做法是:每次更新 A 和 B 时,先对所有的 A 和 B 矩阵进行 SVD 分解。如果某一层的矩阵的重要性较低,我们就只更新重要性高的部分,不更新低重要性的部分。然而,这种方法效率极低,因为每个训练 step 都需要进行 SVD 分解。对于大型模型而言,频繁对高维矩阵应用 SVD 会非常耗时。为了解决这个问题,论文提出不精确地计算 SVD,而是通过参数化来模拟 SVD 的效果。
- 具体做法是,使用对角矩阵来表示奇异值,正交矩阵 P 和 Q 表示 ∆ 的左右奇异向量。为了保证 P 和 Q 的正交性,在训练过程中增加一个正则化惩罚项。这样,模型能够在训练过程中逐渐接近 SVD 分解的形式,避免了对 SVD 进行密集计算,同时提高了效率。


- 在每次更新时,根据某些重要性得分来决定哪些 rank 需要更新,哪些需要保持不变。这些重要性得分可以通过奇异值的大小或 loss 的梯度贡献等方式来计算,具体计算方法可以参考相关论文。通过这种方式,能够更有针对性地调整参数。举个例子,假设当前的 rank 预算为 20,且模型中有 5 个矩阵引入了旁路矩阵 A 和 B 需要训练。初始阶段我们可以设置一个较大的预算,比如 budget rank = 30,每个旁路矩阵的 rank 设置为 6。然后,在每次 step 更新时,根据全局的重要性得分,选择前 20 个最重要的 rank 来进行更新,而不更新剩下的重要性较低的部分。为什么要这样做? 翻上文看 AdaLora 的研究动机,本质在于更新得越多未必越好,有些重要性低的,让它更新反而会导致反效果.
- 实验结果
上面这一副图很有意思, 这图想表述的是各层各矩阵模块分配到的参数budget情况。模型的中上层,尤其是、、、和这些模块,分配到的预算明显较多。
- 思考:合乎常理的感觉,训练时有些模块就是不用怎么动,有些模块就是要尽可能微调,让模型自己去判断。
rsLoRA: 调节γ, 让输入和输出保持一个量级
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
2023年 11 月
- 研究动机
Lora 的原论文有做一个实验,实验的结果是 rank=64 在训练中没有带来显著提升,所以论文得出了非常低的 rank(如 4、8、16)就“足够”的结论。然而,这显然是反直觉的。按理来说,任务与预训练之间的差异越大,所需的 rank 应该越高,因为这意味着可调节的参数也应该越多。然而,实际结果却显示,随着 rank 增加,模型效果反而变差(对应上述提到的现象二)。 例如,如下图所示,LoRA 部分中 rank=512 和 rank=2048 时的橙色和黄色曲线较高。按照常理,rank 增加,引入了更多可微调的参数,应该使训练过程钟 perplexity 下降得更快,但结果却与预期相反。
进一步分析可以看出,作者试图引出的问题是:在使用 LoRA 适配器时,通过参数(上文提到,是关于 r 的一个常数)对矩阵乘积 BA 进行缩放会影响模型的学习轨迹。具体而言,关键在于确保的选择在某种程度上是“合理的”,即矩阵在整个学习过程中对于所有 rank 都保持稳定。同时,不应设置得过于激进,以免导致学习不稳定或速度过慢。
- 方法论
- 进一步,论文提出,怎么选择?一个好的应该是 rank-stabilized(秩稳定)的。论文先定义什么叫 rank-stabilized
以下两个条件成立时,适配器是秩稳定的(rank-stabilized):
条件一:如果输入到adpter的数据是独立同分布(iid)的,例如输入的第m阶矩是,那么适配器输出的第m阶矩也是 。 条件二:如果损失函数对adpter输出的梯度是,那么损失函数对适配器输入的梯度在每个条目也是。
hold on, 这里的是什么意思啊?
意思是:在秩 r 增加的情况下,某个量级(例如矩的大小或梯度的大小)保持恒定(或变化非常缓慢,不依赖于 r)。这里的“1”表示与秩 r 无关的常数。具体举个例子,输入到 adpter 的每个条目的第 m 阶矩为,这意味着无论秩 r 是多少,输入数据的第 m 阶矩在每个条目中都是一个常数级别的量。这表示输入的分布不会随着 r 增大而显著变化。这个概念为了保证 adapter 在不同的秩设置下,都能保持稳定的学习和优化过程。
最终经过公式的推导(推导详见论文的 Appendix A),得到定理
考虑形式为的LoRA 适配器,其中初始化时满足,A 的各个元素是独立同分布的,均值为 0,方差为,且不依赖于 r 。当且仅当时,所有适配器都是秩稳定的。特别地,上述结论在学习轨迹的任何点上都成立,且如果,那么对于足够大的 r ,学习过程将是不稳定或坍塌的。
在这个定理中,表示需要按照 的比例缩放。这意味着当秩 r 增大时,应该被设定为 的形式(如,其中是常数)。这种缩放确保了 LoRA 适配器在整个学习过程中保持稳定,防止在 r 很大时出现学习不稳定或梯度崩塌的情况。
- 实验结果
如下图所示,在 rsLoRA 中,随着 rank 的增加,获得的 Perplexity 越低,这符合预期。
再看下面右图,在 LoRA 中,随着 rank 增加,gradient norm 变得非常低,出现了一定程度的梯度崩溃(gradient collapse,指梯度过小了,更新不到位)。相比之下,rsLoRA 在很大程度上抑制了这种现象,即使在 rank=2048 时,gradient norm 仍能保持相对较高。
- 思考:这种训练的稳定性让我联想到 Layer Normalization 和 attention 机制中的归一化。稳定性对于模型训练至关重要,因为它能让模型在每一步都看到相对一致的分布输入。如果每一步的输入分布差异过大,模型容易出现学习不稳定甚至崩溃的现象。而保持输入的稳定性,能使模型更容易学习。
PiSSA: 用奇异值大的部分进行初始化
2024年04月12日
- 研究动机
原生 Lora 收敛得太慢了, Why? (对应上文的现象 1)

仔细看这个公式,在训练的初始阶段,梯度的大小主要由 A 和 B 的值决定。由于在 LoRA 中,A 和 B 是通过高斯噪声和零初始化的,因此初始梯度可能非常小,导致初始梯度可能非常小,进而使微调过程的收敛速度变慢。这种现象在实验中得到了验证,观察到 LoRA 在训练的初期往往在初始点附近徘徊,浪费大量时间。如下图所示,LoRA 在相同的训练步数下,前期收敛速度明显较慢,最终未能达到一个局部最优点。
方法论 论文提出的方式很简单,对原始矩阵进行 SVD 分解,拆开成两部分: 主奇异值部分和残差奇异值部分, fine tuning 主奇异值部分,frozen 残差奇异值. 具体分解如下,其中由奇异值小的那部分组成,A 和 B ,也就是,要训练的那部分由奇异值大的部分组成



- 论文解释了这种分解方法之所以有效的原因在于:主奇异值的元素远大于残差奇异值的元素,因此可训练的适配器包含了原始权重矩阵 W 中最重要的方向。在理想情况下,训练 可以在使用较少参数的前提下,模拟微调整个模型的效果。通过直接微调模型中最关键的部分,PiSSA 能够实现更快、更好的收敛。相比之下,LoRA 在初始化适配器 B 和 A 时,使用的是高斯噪声和零值,同时保持原始权重矩阵 W 冻结不变。因此,在微调的早期阶段,梯度要么非常小,要么呈随机分布,导致许多梯度下降步骤被浪费。此外,不良的初始化可能会使模型陷入次优的局部最小值,影响其泛化能力。
- 实验结果
- 思考:
- 这里有点令人疑惑。用主奇异值来初始化 B 和 A 确实可以加速收敛,但从效果上看,按照论文的说法,微调其实主要集中在调整奇异值较大的主成分。然而,这与 LoRA 原始论文的观点存在一定矛盾。在 LoRA 论文的第 7.3 节中提到,主要是放大了 W 中未被强调的方向,也就是说 Lora 放大了下游任务中重要,但在预训练中未被强调的特征部分(也就是奇异值小的部分),这与 PiSSA 的观点是矛盾的。
- 我的个人思考是,如果任务较为通用,那么可能确实需要调整模型中奇异值较大的部分;但如果任务与预训练的差异较大,那么仅调整奇异值大的主成分未必能够得到最佳效果,可能更需要关注那些在预训练中未被强调但在新任务中重要的特征。
DORA: 把权重分解为幅值和方向两个模块进行独立微调
DoRA: Weight-Decomposed Low-Rank Adaptation
2024年2月
- 研究动机
- 为了弥补这一差距,论文首先引入了一种新颖的权重分解分析方法,以研究全参数微调和 Lora 微调之间的差异。基于这些发现,论文提出了一种名为 Weight-Decomposed Low-Rank Adaptation(DoRA)的新方法。DoRA通过将预训练权重分解为大小(magnitude)和方向(direction)两个组成部分进行微调,特别是利用LoRA有效地更新方向部分,以最小化可训练参数的数量。通过这种方法,DoRA旨在提高 LoRA 的学习容量和训练稳定性。
- 方法论
- 通过将权重矩阵分解为幅度和方向两个独立的部分,揭示了 LoRA 与全参数微调(FT)在学习模式上的内在差异。具体的分析方法是:通过检查 LoRA 和 FT 相对于预训练权重在幅度和方向上的更新,深入揭示它们在学习行为上的根本区别。 具体的,矩阵的权重分解可表述为


可以明显看出,LoRA 在所有中间步骤中表现出一致的正斜率趋势,表明方向和幅度的变化之间存在比例关系。相比之下,FT显示出更为多样化的学习模式,具有相对负斜率。这种 FT 和 LoRA 之间的区别可能反映了它们各自的学习能力。尽管 LoRA 倾向于成比例地增加或减少幅度和方向更新,但它缺乏对更细微调整的能力。具体而言,LoRA在执行伴随幅度显著变化的微小方向调整或相反情况下的表现不佳,而这种能力更是FT方法的特点。
论文怀疑,LoRA的这种局限性可能源于同时学习幅度和方向适应性的挑战,这对于LoRA来说可能过于复杂, 引出了论文的方法论。
- 方法论
- 根据作者对权重分解分析的见解,论文进一步引入了权重分解的低秩适应方法(DoRA)。DoRA首先将预训练的权重分解为其幅度和方向分量,并对这两个分量进行微调。由于方向分量在参数数量上较大,论文进一步通过 LoRA对其进行分解,以实现高效微调。
- 作者的直觉有两个方面。
- 首先,限制LoRA专注于方向调整,同时允许幅度分量可调,相较于LoRA在原方法中需要同时学习幅度和方向的调整,简化了任务。
- 其次,通过权重分解使得方向更新的过程更加稳定。
- 实验结果
上图(c) 中展示了在与 FT 和LoRA相同的设置下,合并后的DoRA权重与 之间的幅度和方向差异。从DoRA和FT的回归线上,DoRA和FT表现出相同的负斜率。论文推测,FT倾向于负斜率是因为预训练权重已经具备了适合多种下游任务的大量知识。因此,在具有足够的学习能力时,仅通过更大幅度或方向的改变就足以进行下游适应。
论文还计算了FT、LoRA 和 DoRA 的和之间的相关性,发现 FT 和 DoRA 的相关性值分别为-0.62和-0.31,均为负相关。而LoRA则显示为正相关,相关性值为0.83。Anyway,DoRA展示了仅通过较小的幅度变化或相反的情况下进行显著方向调整的能力,同时其学习模式更接近FT,表明其相较于LoRA具有更强的学习能力。
- 思考: 感觉合乎常理, 找到一种更 match 问题特性的建模方式,这样模型不仅更容易学习,还能提高学习效果。
实验
际业务数据通常与 benchmark 数据不同,往往是预训练模型未曾见过的,这有时会激活新的模式(pattern)。在此次实验中,我们对比了 LoRA、rsLoRA 和 Dora 在三个具体下游业务任务中的表现。实验参数如下:
epoch=4, learning_rate = 4e-4, learn_scheduler=cosine, rank=8或32,base_model=Qwen2-72B,训练结束后取 checkpoint 在测试集上进行评估
值得注意的是,rsLoRA 在 rank=32 的情况下训练失败,具体表现为 gradient norm 过大,train_loss 居高不下,因此没有将该结果列出。
首先,我们来看训练过程中的 gradient norm。可以明显看到 rsLoRA(rank=8)的 gradient norm 始终较大,表明每个 step 的更新幅度较大,这与原论文中的结论一致。
然后我们再对比下 train_loss、 eval_loss、下游任务测试集的表现
- 观察 1: 对比实验 1 和实验 4,Lora(rank=8) 的效果比 Lora(rank=32) 差,这与现象二一致,证明单纯增大 rank 对 Lora 的性能提升作用有限,甚至反作用。
- 观察 2: 对比实验 1 和实验 2,rsLoRA(rank=8) 的 train_loss 低于 Lora(rank=8),但 eval_loss 和任务指标差异不大。同时,rsLoRA(rank=32) 在训练中失效(训崩)。这可能表明,虽然 rsLoRA 能加速模型的学习,但由于没有优化好 Lora 的初始化,整体效果提升不显著。这也暗示了良好的初始化对 Lora 的重要性??(有没有高人指点)
- 观察 3: Dora(rank=32) 的 train_loss 虽然不是最低的,但 eval_loss 是最低的,表现良好。无论 rank=8 还是 rank=32,Dora 的表现都优于其他方法。
最佳实践建议: 使用 Dora,rank不用调太大(例如 8 、 16 、 32),学习率设置高一些,epoch 维持在 4-5 个左右,并使用 cosine learn scheduler。
总结
文章介绍了多个基于LoRA的改进方法,如AdaLoRA、rsLoRA、PiSSA、DoRA等,分别通过优化训练参数的分配、调节缩放因子、改进初始化等方式提高微调效果。实验结果表明,DoRA表现最佳,提供了模型训练中的最佳实践建议。
今年一个非常明显的趋势,大模型正在加速自动驾驶落地,L3级别的自动驾驶路线图愈发清晰。智能座舱和xx智能这块也是当下非常火爆的方向。未来大模型除了量产上车之外,像数据挖掘、标注等等应该都值得进一步探索。
#5 亿月活用户的 OpenAI ,有哪些「软肋」?
OpenAI 的创始人 Sam Altman 在 4 月 12 日与 TED 主持人克里斯·安德森的对谈中分享了他对 AI 技术发展的诸多担忧,包括对 AI 创造的版权矛盾、大模型面临的开源压力、AI 技术滥用风险以及人类是否能适应 AGI 时代的来临。
目录
01. Sam Altman 对 AI 技术的发展有哪些担忧与思考?
Altman在访谈中谈及了哪些话题?Altman为何不安?他对未来的AI有哪些顾虑?...
02. Sam Altman 如何回应 OpenAI 的版权问题?
Altman对「守旧派」的态度如何?「吉卜力版权争议」解决了吗?OpenAI会如何与DeepSeek竞争?...03. 在安全实践上被评为「D+」的 OpenAI 有哪些关键 「软肋」?Altman对AI的短期突破怎么看?OpenAI在下一代AI的治理中有哪些工作需要开展?...
04. AGI 时刻何时的到来是否真的能为人来带来好处?
OpenAI 对人工智能安全性保证有哪些实际上的动作?Altman对「Agentic AI」怎么看?...
01 Sam Altman 对 AI 技术的发展有哪些担忧与思考?
1、在全球拥有超过五亿月活用户的成就下,OpenAI 无疑是人工智能浪潮的引领者。然而,一个引人深思的问题是:即使站在如此成功的顶峰,其首席执行官 Sam Altman 仍在担忧什么?是什么让这位行业领袖保持警惕,甚至流露出不满足与不安?
2、该场访谈中,Altman 分享了对 AI 生成内容的创意归属与版权纠纷的思考,包括如何界定「创意产出」与「抄袭」,如何回应创作者的担忧,如何在不侵犯版权的前提下促进创意经济,以及 OpenAI 在面对 DeepSeek 等强劲开源模型竞争时的战略调整与挑战。
3、Altman 在访谈中还分享了对 AI 技术滥用、模型失控的疑虑,如不法分子滥用 AI 技术,从而带来网络安全挑战,自我改进模型可能会面临失控等风险。
① 在该话题下,Altman 还讨论了他对 AI 带来的大规模就业冲击和相应社会安全性风险的看法。
4、此外,Altman 在访谈中围绕 AGI 的定义、AGI 到来时机的判断,以及对「智能体型 AI」带来的风险认知,探讨如何通过建立信任机制和可能的外部安全监管来确保人工智能发展的安全性。
① Altman 一方面强调了「AGI 时刻」这一概念的模糊性,称与其争论其节点,不如关注如何在整个发展过程中如何保持系统的安全性。
② 对于「智能体型 AI」的风险,Altman 表示他的担忧聚焦于未来如何实现对智能体行为的规范,以避免这些 AI 做出危险的事情。
02 Sam Altman 如何回应 OpenAI 的版权问题?
1、该场访谈中,Altman 被问及与《花生漫画》(Peanuts)的版权所有者暂未达成协议,他谈到支持人类借助 AI 工具获取灵感并创造作品,但他也表达了对如何界定一项作品属于「创意产出」,还是「抄袭」的迷茫。
① 即使 OpenAI 通过制定版权法并限制使用范围来解决「抄袭」问题,不少的创作家仍认为 OpenAI 图像生成功能和 ChatGPT 写作功能属于窃取作品行为,但也有创作家认为借助 AI 能创作出颠覆性的新作品。
② Altman 对不愿接受技术革新的「守旧派」表示同情,并思考如何改变人类整体对 AI 创造力的接受程度,以及如何在不侵犯版权的前提下促进创意经济的发展。
③ 此前,ChatGPT 生成的吉卜力风格图片引发了版权问题。Altman 强调 AI 生图功能不应直接复制他人作品,但可以借鉴作品风格。
④ 为了评估和缓解 AI 安全性风险,OpenAI 通过引入「伦理黑匣子」制度,建立了系统性框架用于,并记录 AI 关键决策过程。Altman 强调 OpenAI 将不断迭代和改进 AI 安全性监测技术。
⑤ 与此同时,OpenAi 正在寻找如何平衡 AI 的创意生成与版权所有者权益。OpenAI 目前要求用户在使用 AI 生成内容时明确标注来源,确保 AI 生成内容的版权合规性。
⑥ Altman 强调,OpenAi 需要制定新的收益分配模式来处理 AI 生成内容的版权问题。
2、当 Altman 被问及与 DeepSeek 模型开源竞争时,Altman 谈到开源模型将在整个生态系统中占据重要位置,尽管 OpenAI 在开源方面行动迟缓,但会努力做到更好。
#推理模型其实无需「思考」
伯克利发现有时跳过思考过程会更快、更准确
当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。

这项研究认为显式思考过程会显著增加 token 使用量和延迟,导致推理效率低下。
就比如在控制延迟条件时,NoThinking 的效果就显著好于 Thinking。

这项研究给出的出人意料的结论吸引了不少眼球。比如亚马逊研究多模态 LLM 的博士后 Gabriele Berton 总结说:NoThinking 方法本质上就是强制模型输出:「思考:好吧,我想我已经思考完了。」

具体怎么回事?来看一下原文:
- 论文标题:Reasoning Models Can Be Effective Without Thinking
- 论文地址:https://arxiv.org/pdf/2504.09858
与 Thinking 相比,NoThinking 能更好地权衡精度与预算的关系
定义 Thinking 和 NoThinking
大多数现代推理模型,如 R1 和 R1-Distill-Qwen,在其生成过程中都遵循类似的结构:在思考框内的推理过程,以 <|beginning_of_thinking|> 和 <|end_of_thinking|> 为标志,然后是最终答案。基于这种结构,将两种方法(Thinking 和 NoThinking)定义如下。
- Thinking 指的是查询推理模型以生成以下输出的默认方法:思考框内的推理过程、最终解决方案和最终答案(图 1(蓝色))。
- NoThinking 指的是通过提示绕过显式推理过程,直接生成最终解决方案和答案的方法。这可通过在解码过程中强制思维框为空来实现(图 1(橙色)),如下所示。
<|beginning_of_thinking|>
Okay, I think I have finished thinking.
<|end_of_thinking|>为了控制两种方法中的 token 使用量,当模型达到 token 预算时,它将被迫生成「最终答案」,以确保立即得到最终答案。如果模型在达到 token 限制时仍在思考框内,<|end_of_thinking|> 将附加在最终答案标签之前。

实验设置
实验使用 DeepSeek-R1-Distill-Qwen-32B 作为主要模型。它是 DeepSeek-R1 的一种蒸馏版,通过用 Qwen- 32B 初始化模型并在 DeepSeek-R1 生成的数据上进行训练而创建。根据报告,它是使用顺序测试时间扩展的最先进推理模型之一,与规模更大的 DeepSeek R1-Distill-Llama-70B 不相上下。
还提供了一系列具有挑战性的推理基准,包括数学竞赛、编码、奥林匹克竞赛问题和定理证明等任务。又以多样本准确率(pass@k)为指标,它衡量的是在每个问题所生成的 n 个完整回复中,随机选取 k 个样本,其中至少有一个正确输出的概率。
其形式化定义为

其中 n 是每个问题的采样输出数量,c 是正确输出的数量。
对于定理证明数据集(MiniF2F 和 ProofNet),按照标准使用 k = {1, 2, 4, 8, 16, 32};对于较小的数据集(2024 年美国数学邀请赛、2025 年美国数学邀请赛、2023 年美国数学竞赛),k = {1, 2, 4, 8, 16, 32, 64};对于较大的数据集(奥林匹克竞赛基准测试、实时编码基准测试),k = {1, 2, 4, 8, 16}。对于形式定理证明基准测试,「多样本准确率(pass@32)」 是标准指标,而对于数学和编程基准测试,最常用的是「单样本准确率(pass@1)」(即准确率)。
实验结果
在未控制 token 预算的情况下对 Thinking、NoThinking 与 Qwen Instruct 进行对比

首先,在 MiniF2F 和 ProofNet 上,NoThinking 在所有 k 值上的表现与Thinking 相当(两者都显著优于 Qwen-Instruct)。考虑到 NoThinking 使用的 token 比 Thinking 少 3.3–3.7 倍,这一结果尤其令人惊讶。在其他数据集上,结果则更为复杂。在 k=1 时,NoThinking 落后于 Thinking,但随着 k 的增加,差距逐渐缩小。
在所有数据集中,当 k 值最大时,NoThinking 的表现与 Thinking 相当,但 token 使用量却比 Thinking 少 2.0–5.1 倍。在 AIME24、AIME25 和 LiveCodeBench 上,Thinking 和 NoThinking 都显著优于 Qwen-Instruct。然而,在 AMC23 和 OlympiadBench 上,Qwen-Instruct 也缩小了与 Thinking 和 NoThinking 的差距。
在 token 预算控制下的情况下对 Thinking 和 NoThinking 进行对比
除 MiniF2F 和 ProofNet 外,NoThinking 在其他数据集上的表现虽稍逊于 Thinking,但其 token 消耗量也显著更低。
因此,接下来继续通过预算约束方法,在相近 token 预算下比较两者的性能表现。

如图 5 所示,当 token 使用量受到控制时,NoThinking 方法通常优于 Thinking 方法。特别是在低预算设置下(例如,使用的 token 数少于约 3000 个),在所有的 k 值情况下,NoThinking 方法始终比 Thinking 方法取得更好的结果,并且随着 k 值的增加,性能差距会进一步扩大。当 token 使用量较高时(例如,大约 3500 个 token),在单样本准确率 (pass@1)方面,Thinking 方法的表现优于 NoThinking 方法,但从 k = 2 开始,NoThinking 方法的表现就迅速超过了 Thinking 方法。

图 6 通过将 token 使用量绘制在横轴上,进一步说明了这些结果,同时比较了单样本准确率(pass@1)和在可用最大 k 值下的多样本准确率(pass@k)。在多样本准确率(pass@k)方面,NoThinking 方法在整个预算范围内始终无一例外地优于 Thinking 方法。对于单样本准确率(pass@1)而言,NoThinking 方法在低预算情况下表现更好,而在高预算情况下表现较差。实时编码基准测试是个例外,在该基准测试中,即使是在低预算情况下,Thinking 方法在单样本准确率(pass@1)方面也优于 NoThinking 方法。这很可能是因为在实时编码基准测试上,禁用思考模块并不能显著减少 token 使用量。
为了降低数据污染的风险,实验还纳入了新发布的 AIME 2025 ,这些数据不太可能出现在现有模型的预训练数据中。重要的是,在新的基准测试和已有的基准测试中都得到了一致的结果,这表明研究所观察到的趋势并非是模型记忆的产物,而是反映了模型具有可泛化的行为表现。
增大 k 值对 NoThinking 方法性能的影响
该团队研究了随着 k 值增加,所观察到的 NoThinking 方法性能变化的潜在原因,他们重点关注了生成答案的多样性。这是通过计算每个问题的答案分布的熵来衡量的。具体而言,对于答案分布为
![]()
的一个问题,熵的定义为:

其中 p_i 是第 i 个独特答案的经验概率。然后,使用所有问题的熵的均值和标准差来总结多样性。均值熵越高表明总体多样性越大,而标准差越低则意味着各个问题之间的多样性更为一致。这些分析基于图 5 中 Thinking 方法与 NoThinking 方法的对比情况,但不包括缺少确切答案的实时编码基准测试。

从表 1 可以看到,就平均多样性而言,两种模式都没有始终如一的优势。在某些情况下, NoThinking 模式得出的平均熵更高;而在另一些情况下, Thinking 模式的平均熵更高。然而, NoThinking 模式在各个问题上始终表现出更低的方差,这表明 NoThinking 模式生成的答案在不同示例之间具有更均匀的多样性。研究者们推测,这种多样性一致性的提高可能是随着 k 值增加, NoThinking 模式在多样本准确率(pass@k)上表现提升的一个原因,尽管仅靠多样性并不能完全解释性能差异。
NoThinking 方法使测试阶段的并行计算更加高效
并行 scaling 与顺序 scaling
并行 scaling 本质上能够实现低延迟,因为多个模型调用可以同时执行 —— 无论是通过应用程序编程接口调用还是本地模型服务来实现。这可以通过多 GPU 设置或者在单个 GPU 上进行批处理来达成,与顺序 scaling 相比,这种方式能够实现更高的 GPU 利用率。总体延迟由单个最长的生成时间决定。
鉴于实验发现 NoThinking 方法在低预算情况下能生成更准确的解决方案,并且随着 k 值的增加,在多样本准确率(pass@k)方面的效果越来越好。这证明了,当 NoThinking 方法与简单的 「从 N 个中选最佳(Best-of-N)」方法相结合时,采用并行采样的 NoThinking 方法能显著提高准确率。在延迟相当的情况下,它的表现优于其他方法,比如采用强制预算和并行采样的 Thinking 方法。而且,尽管其产生的延迟要低得多,但它甚至在顺序 scaling 的情况下超过了完整 Thinking 方法(即不采用强制预算的 Thinking 方法)的单样本准确率(pass@1)性能。
结果

图 7 中展示了 Thinking 方法和 NoThinking 方法在所有基准测试中的单样本准确率(pass@1)结果。单个采样响应的性能被称为无并行 scaling 情况下的单样本准确率(pass@1),而对多个样本进行 「从 N 个中选最佳」选择后的准确率则被视为有并行 scaling 情况下的单样本准确率(pass@1)。对于没有验证器的任务,在图中使用基于置信度的结果,并在表 2 中给出选定实验的消融实验结果。该表比较了上述讨论的「从 N 个中选最佳」方法。基于置信度的选择方法通常优于多数投票法。还报告了多样本准确率(pass@k),将其作为使用并行 scaling 时单样本准确率(pass@1)的上限。
NoThinking 方法与并行 scaling 相结合,为传统的顺序方法提供了一种高效的替代方案,能够在显著降低延迟和 token 使用量的情况下,达到相似甚至更好的准确率。如图 7 的前两个图所示,NoThinking 方法实现了与 Thinking 方法相当甚至更高的性能,同时延迟要低得多。在没有并行 scaling 的情况下,NoThinking 方法在准确率上与 Thinking 方法相近,而延迟仅为后者的一小部分。

如果有一个完美的验证器可用,那么从 k 个采样响应中选择最佳的一个就能实现 pass@k 准确度。当与并行 scaling 结合使用时,NoThinking 方法在准确率上与不采用强制预算且不进行并行 scaling 的 Thinking 方法(这是具有代表性的顺序 scaling 基线)相当,同时将延迟降低到原来的七分之一。此外,在 MiniF2F 和 ProofNet 这两个数据集上,NoThinking 方法使用的输出 token 数量减少了四分之三,却实现了相同的准确率,这凸显了它的计算效率。这些结果强调了在有验证器可用的情况下,并行采样的有效性。
当 NoThinking 方法与并行 scaling 以及基于置信度的选择方法相结合时,在大多数基准测试中,它在低 token 预算的情况下始终优于 Thinking 方法。图 7(最后五个图)展示了基于置信度选择方法在多个基准测试中的结果,比较了在受控 token 使用量情况下 Thinking 方法和 NoThinking 方法的表现。
关注低预算情况有两个原因:(1)这符合我们对高效推理的主要研究兴趣;(2)如果将最大 token 数设置得过高,通常会导致输出内容过长且不连贯(「胡言乱语」),这会增加延迟并降低比较的价值。
正如预期的那样,并行 scaling 提高了 Thinking 方法和 NoThinking 方法的单样本准确率(pass@1)性能。然而,在所有数学基准测试中,NoThinking 方法始终处于帕累托最优边界的主导地位。
在采用并行 scaling 的 Thinking 方法方面,NoThinking 方法展现出了更优的准确率与预算之间的权衡。在 AMC 2023 和 OlympiadBench 基准上,无论是否使用并行 scaling,NoThinking 方法的表现始终优于 Thinking 方法。值得注意的是,即使与完整的 Thinking 方法(不采用强制预算的 Thinking 方法)相比,NoThinking 方法在将延迟降低到原来的九分之一的同时,还实现了更高的单样本准确率(pass@1)得分(55.79 比 54.1)。
NoThinking 方法在 LiveCodeBench 上的效果较差,该基准测试似乎是个例外情况。这可能是因为基于置信度的选择方法在编码任务中存在局限性,在没有完全匹配输出的情况下,投票策略无法应用。在这些情况下,只能退而求其次,选择置信度最高的答案,而这种方式的可靠性较低。如表 2 所示,与在可应用投票策略的任务中基于投票的方法相比,这种方法的表现一直较差(通常差距很大)。总体而言,这些结果凸显了在无验证器的情况下,当 NoThinking 方法与并行采样以及强大的选择策略相结合时的有效性。
随着 k 值的增加,NoThinking 方法在多样本准确率(pass@k)方面令人惊喜的表现可以通过并行 scaling 得到进一步利用,从而在相似甚至显著更低的延迟(最多可降低至原来的九分之一)情况下,提升单样本准确率(pass@1)的结果。对于配备了完美验证器的任务,这种方法还能在达到相似或更高准确率的同时,将 token 的总使用量减少多达四分之三。
总结
大型语言模型在生成解答之前会产生冗长的思考过程,这种方式在推理任务上已经取得了很好的成果。该研究对这一过程的必要性提出了质疑,为此引入了 NoThinking 方法。
这是一种简单而有效的提示策略,能够绕过显式的思考过程。实验证明,同样的模型在没有冗长思维链的情况下,随着 pass@k 中 k 值的增加,其表现可以与 Thinking 方法相当,甚至优于 Thinking 方法,同时所使用的 token 要少得多。
在 token 预算相当的情况下,对于大多数 k 值,NoThinking 方法的表现始终优于传统的 Thinking 结果。
此外,研究还发现,NoThinking 方法可以与 「从 N 个中选最佳」的选择方法相结合,从而在准确率和延迟的权衡方面,取得比标准 Thinking 方法更好的效果。
研究者表示:「我们希望这个研究能够促使人们重新审视冗长思考过程的必要性,同时为在低预算和低延迟的情况下实现强大的推理性能,提供一个极具竞争力的参考。」
#谷歌发布Gemma 3全系QAT版模型
一台3090就能跑Gemma 3 27B
谷歌 Gemma 3 上线刚刚过去一个月,现在又出新版本了。

该版本经过量化感知训练(Quantization-Aware Training,QAT)优化,能在保持高质量的同时显著降低内存需求。
比如经过 QAT 优化后,Gemma 3 27B 的 VRAM 占用量可以从 54GB 大幅降至 14.1GB,使其完全可以在 NVIDIA RTX 3090 等消费级 GPU 上本地运行!

Chatbot Arena Elo 得分:更高的分数(最上面的数字)表明更大的用户偏好。点表示模型使用 BF16 数据类型运行时所需的 NVIDIA H100 GPU 预估数量。
在一台配备了 RTX 3070 的电脑上简单测试了其中的 12B 版本,可以看到虽然 Gemma 3 的 token 输出速度不够快,但整体来说还算可以接受。
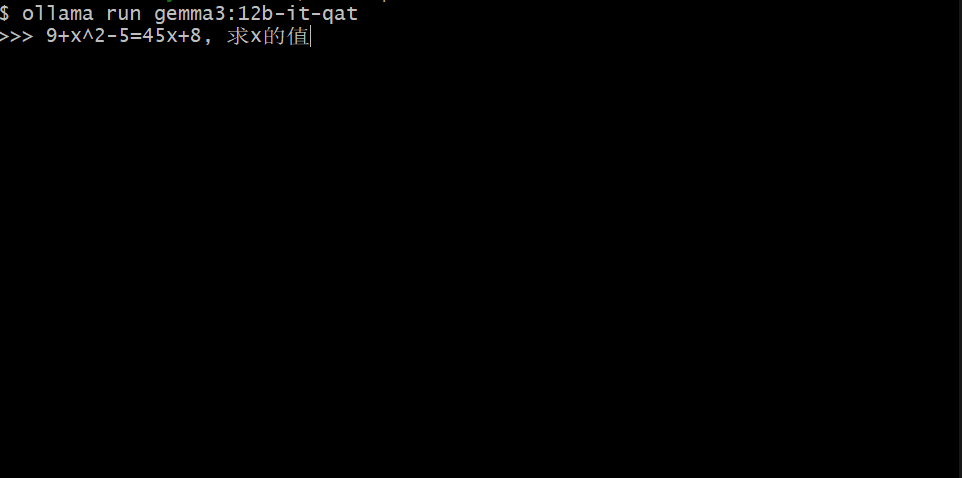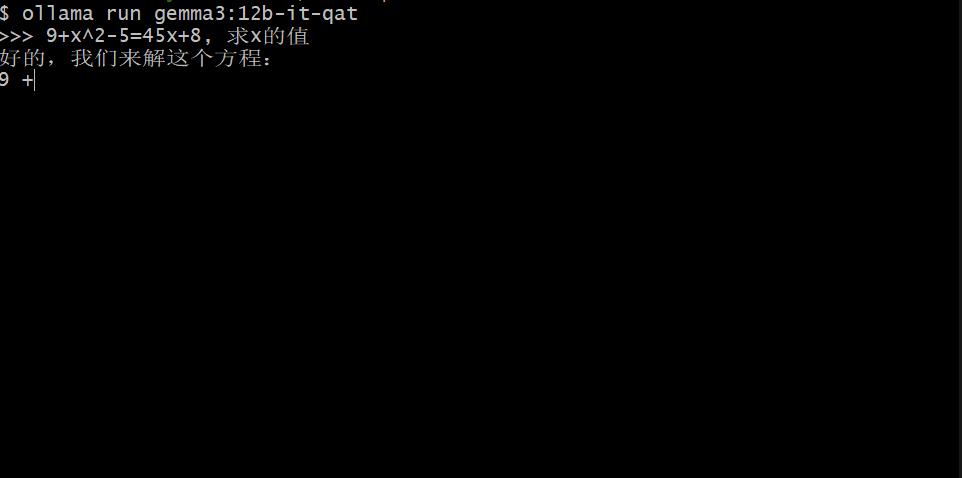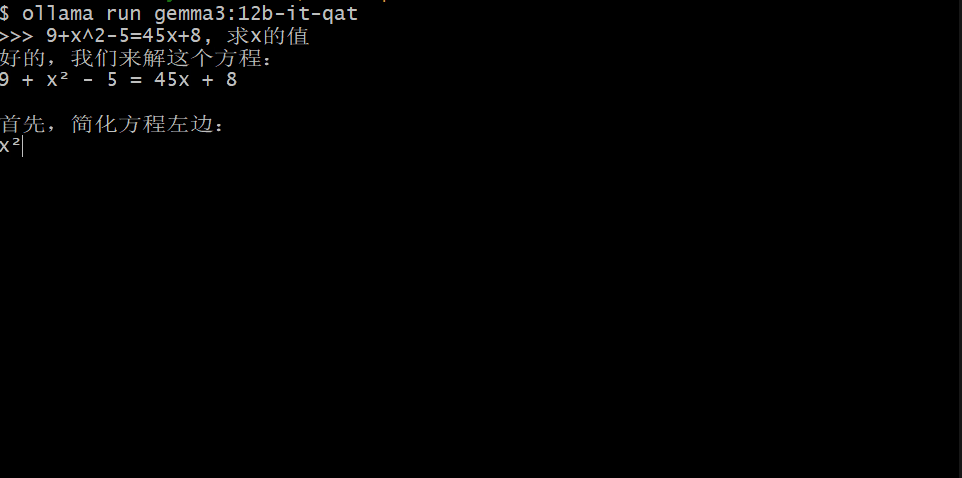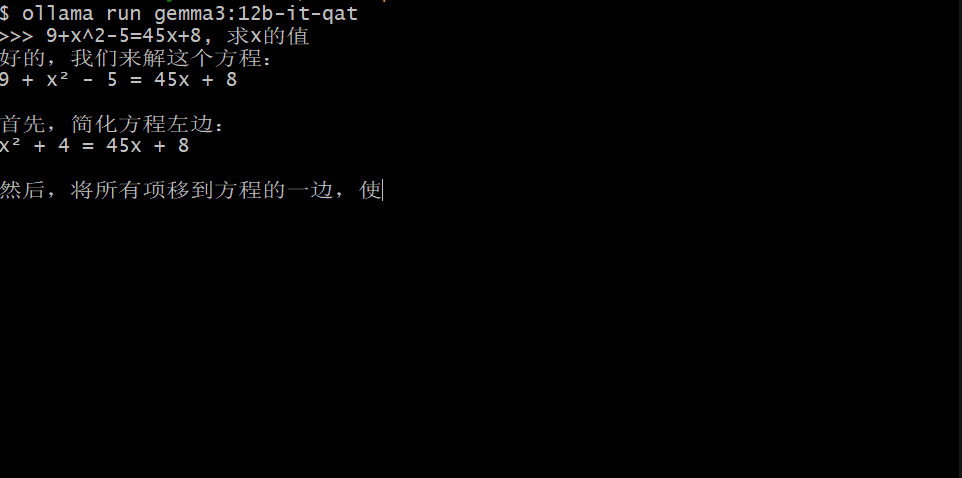
基于量化感知训练的 Gemma 3
在 AI 模型中,研究者可以使用更少的位数例如 8 位(int8)甚至 4 位(int4)进行数据存储。
采用 int4 量化意味着每个数值仅用 4 bit 表示 —— 相比 BF16 格式,数据大小缩减至 1/4。
但是,这种量化方式通常会导致模型性能下降。
那谷歌是如何保持模型质量的?答案是采用 QAT。
与传统在模型训练完成后才进行量化的方式不同,QAT 将量化过程直接融入训练阶段 —— 通过在训练中模拟低精度运算,使模型在后续被量化为更小、更快的版本时,仍能保持准确率损失最小化。
具体实现上,谷歌基于未量化的 checkpoint 概率分布作为目标,进行了约 5,000 步的 QAT 训练。当量化至 Q4_0(一种常见的量化格式) 时,困惑度下降了 54%。
这样带来的好处之一是加载模型权重所需的 VRAM 大幅减少:
- Gemma 3 27B:从 54 GB(BF16)降至仅 14.1 GB(int4)
- Gemma 3 12B:从 24 GB(BF16)缩减至仅 6.6 GB(int4)
- Gemma 3 4B:从 8 GB(BF16)精简至 2.6 GB(int4)
- Gemma 3 1B:从 2 GB(BF16)降至仅 0.5 GB(int4)

此图仅表示加载模型权重所需的 VRAM。运行该模型还需要额外的 VRAM 用于 KV 缓存,该缓存存储有关正在进行的对话的信息,并取决于上下文长度。
现在看来,用户在消费级设备上就能运行更大、更强的 Gemma 3 模型,其中:
- Gemma 3 27B (int4):现在可以轻松安装在单张 NVIDIA RTX 3090(24GB VRAM)或类似显卡上,本地就能运行最大的 Gemma 3 版本;
- Gemma 3 12B (int4):可在 NVIDIA RTX 4060 GPU(8GB VRAM)等笔记本电脑 GPU 上高效运行,为便携式设备带来强大的 AI 功能;
- 更小的型号(4B、1B):为资源较为有限的系统(包括手机和烤面包机)提供更强大的可访问性。

来自 Two Minute Papers 频道的玩笑
官方 int4 和 Q4_0 非量化 QAT 模型已在 Hugging Face 和 Kaggle 上线。谷歌还与众多热门开发者工具合作,让用户无缝体验基于 QAT 的量化 checkpoint:
- Ollama:从今天起,只需一个简单命令即可原生支持 Gemma 3 QAT 模型。
- LM Studio:通过用户友好界面,轻松下载并在桌面上运行 Gemma 3 QAT 模型。
- MLX:利用 MLX 在苹果芯片上对 Gemma 3 QAT 模型进行高效推理。
- Gemma.cpp:使用专用的 C++ 实现,直接在 CPU 上进行高效推理。
- llama.cpp:得益于对 GGUF 格式 QAT 模型的原生支持,可轻松集成到现有工作流程中。
激动的网友已经无法抑制内心的喜悦:「我的 4070 就能运行 Gemma 3 12B,这次谷歌终于为即将破产的开发者做了一些事情。」

「希望谷歌朝着 1bit 量化使使劲。」

这个可以本地运行的 Gemma 3 你用了吗,效果如何,欢迎大家评论区留言。
参考链接:https://developers.googleblog.com/en/gemma-3-quantized-aware-trained-state-of-the-art-ai-to-consumer-gpus/?linkId=14034718
#F5R-TTS
语音合成突破:首次实现非自回归模型的GRPO优化,零样本克隆性能显著提升
在人工智能技术日新月异的今天,语音合成(TTS)领域正经历着一场前所未有的技术革命。最新一代文本转语音系统不仅能够生成媲美真人音质的高保真语音,更实现了「只听一次」就能完美复刻目标音色的零样本克隆能力。这一突破性进展的背后,是大规模语音数据的积累和大模型技术的快速发展。
同时在技术前沿,DeepSeek 系列凭借其 GRPO 算法(群体相对策略优化),正以强化学习引领大语言模型(LLM)研究的新趋势。目前,强化学习已扩展至自回归 TTS 系统。然而,由于非自回归架构与大型语言模型(LLMs)存在根本性的结构差异,此前非自回归 TTS 系统尚未出现成功的强化学习集成案例,这一技术难题仍有待可行的研究解决方案。
近日,腾讯PCG社交线的研究团队针对这一挑战提出了 F5R-TTS 系统,首创性地通过将模型输出转化为概率表征,打通了非自回归 TTS 模型强化学习的「任督二脉」。
- 论文标题:F5R-TTS: Improving Flow-Matching based Text-to-Speech with Group Relative Policy Optimization
- 论文链接:https://arxiv.org/abs/2504.02407
- 项目主页:https://frontierlabs.github.io/F5R/
F5R-TTS 的创新架构
F5R-TTS 通过模型架构创新,有效融合了强化学习。这项研究的主要贡献体现在三个方面:
- 概率化输出转换:研究团队创新性地将 flow-matching 的 TTS 模型输出转化为概率表征。这一转换使得强化学习在非自回归模型中的应用成为可能,为后续的优化奠定了基础。
- GRPO 优化方法:首次成功将 GRPO 方法应用于非自回归 TTS 模型,采用词错误率(WER)和说话人相似度(SIM)作为奖励信号,有效引导模型优化方向。
- 零样本语音克隆验证:在零样本语音克隆场景中,F5R-TTS 模型展现出显著优势。相较于传统非自回归 TTS 基线模型,在可懂度(WER 相对降低 29.5%)和说话人一致性(SIM 相对提升 4.6%)两方面均实现显著提升。

F5R-TTS 的训练流程分为两个关键阶段:第一阶段基于 flow-matching 损失函数进行预训练;第二阶段采用 GRPO 算法对模型进行精细优化。这种两阶段训练策略既保证了模型的初始性能,又通过强化学习实现了针对性优化。
概率化改造:强化学习的基础
我们选用了当前效果领先的非自回归 TTS——F5-TTS 作为骨架。为了使非自回归模型适配 GRPO 框架,F5R-TTS 进行了关键的概率化改造。具体而言,模型被设计为预测每一步输出时的分布概率,而非直接预测确定性的输出值。这一改造使得模型输出具有了概率分布特性,为强化学习中的策略梯度计算提供了必要条件。

在第一阶段预训练中,目标函数仍采用 flow-matching 的形式,其核心思想是将标准正态分布 x0 的概率路径匹配到近似真实数据 x1 的分布上。模型在最后一层预测高斯分布的均值与方差,并通过优化参数以最大化 x1 −x0 的对数似然函数。这一过程可以形式化为以下目标函数:

简化后,模型使用下式作为预训练的目标函数

GRPO 强化
在 GRPO 阶段,预训练模型作为策略模型进行微调,同时以预训练参数初始化参考模型。
具体实现上,策略模型的前向运算需要执行类似推理过程的采样操作 —— 从标准高斯分布初始输入开始,逐步计算每一步的输出概率分布,并进行采样。采样结果既用于计算奖励信号,也需要与参考模型输出比较以计算 KL 散度损失,确保优化过程的稳定性。

奖励函数的设计是 GRPO 阶段的核心。研究团队选择了词错误率(WER)和说话人相似度(SIM)作为主要奖励指标,分别对应语音克隆任务中最关键的两个方面:语义准确性和音色保真度。
最终,GRPO 阶段的目标函数定义如下:

实验
研究团队设计了全面的实验来验证 F5R-TTS 的有效性。实验设置包括:
- 预训练阶段:采用 7226 小时开源数据集 WenetSpeech4TTS Basic
- GRPO 微调:随机选取 100 小时高质量语音数据
- 评估体系:基于 Seed-TTS 测试标准,构建包含 2560 个测试样本(含 400 个高难度样本、140 个带噪样本)的评估集,计算 WER 和 SIM

研究团队首先采用 t-SNE 技术对说话人相似度进行二维空间可视化。结果如图 4 显示,对比其他方法,F5R-TTS 模型的合成结果能够更准确地按照目标说话人实现聚类。这一可视化结果直观地证明了 F5R-TTS 模型在说话人相似度方面的优越表现。

其次,采用全局方差(Global Variance, GV)指标进行频谱分析。如图 5 所示,F5R 模型的曲线与真实语音的曲线吻合度最高,再次验证 F5-R 模型的合成语音在频谱特性上与真实语音具有更高的相似性。


客观测评指标表明,采用 WER 和 SIM 作为奖励信号的 GRPO 方法,使 F5R-TTS 相较于基线在语义准确性和说话人相似度两个维度均获得提升。在说话人相关奖励的引导下,F5R 能够通过上下文学习更精准地克隆目标说话人的声学特征。
值得注意的是,在困难测试集上,F5R 在 WER 指标上的相对优势更为显著 —— 这得益于 WER 相关奖励组件有效增强了模型的语义保持能力。另外,为验证所提方法的泛化能力,实验还用在内部数据集上进行了重复验证,结果表明 GRPO 方法在不同数据集上都能持续提升模型性能。
同时,三个模型在困难测试集上的性能均出现下降,这表明文本复杂度的增加通常会导致模型稳定性降低。该现象将成为后续优化研究的重要切入点。
未来展望
F5R-TTS 首次成功将 GRPO 整合到非自回归 TTS 系统中,突破了非自回归模型难以应用强化学习的技术瓶颈。实验证明该方法能同时提升语义准确性和音色保真度,为零样本语音克隆提供了更优解决方案。文章提出的概率化输出转换策略为其他生成模型的强化学习优化提供了可借鉴的思路。这项研究不仅推动了语音合成技术本身的发展,也为其他生成式 AI 模型的优化提供了新思路。
展望未来,研究团队计划从三个方向继续深入探索:
- 强化学习算法扩展:探索将 PPO、DDPO 等其他强化学习算法整合到非自回归语音合成系统的可行性,寻求更高效的优化路径。
- 奖励函数优化:设计更精细、多层次的奖励函数,进一步提升模型在自然、个性化和表现力等方面的效果。
- 大规模数据验证:在更大规模、更多样化的训练数据上验证方法的扩展性,探索数据规模与模型性能的量化关系。
随着技术的不断成熟,期待未来出现更加自然、个性化和富有表现力的语音合成系统,为智能交互、内容创作、辅助技术等领域带来全新可能。
#英特尔®xx智能大小脑融合方案发布
构建xx智能落地新范式
在 4 月 18 日举办的 2025 英特尔xx智能解决方案推介会上,英特尔正式发布其xx智能大小脑融合方案(下称xx智能方案)。该方案基于英特尔® 酷睿™ Ultra 处理器的强大算力,以及全新的xx智能软件开发套件和 AI 加速框架打造。凭借创新性地模块化设计,其不仅能够兼顾操作精度和智能泛化能力,而且以卓越的性价比满足不同领域需求,为具xx智能的规模化、场景化应用落地夯实基础。
英特尔市场营销集团副总裁、中国区 OEM & ODM 销售事业部总经理郭威表示:“以人形机器人为代表的xx智能行业正迎来前所未有的发展热潮,然而,系统架构的非一致性、解决方案的泛化能力不足、场景适配的复杂性等挑战,正在制约其大规模商业化的进程。基于此,英特尔携手生态伙伴,通过大小脑融合的方式,打造更高效、更智能的解决方案,以基础通用大模型与硬件技术的协同突破,以及开放生态所带来的加速效应,推动xx智能向实践应用场景的迈进。”
英特尔中国边缘计算事业部 EIS 高级总监李岩发表演讲
本次英特尔发布的xx智能方案以大小脑融合为亮点,能够使感知、交互、任务规划和运动控制在统一的系统中实现高效整合。而作为其中的算力中枢,英特尔® 酷睿™ Ultra 处理器通过 CPU 、集成的英特尔锐炫™ GPU 与 NPU 协同运行,以高性能异构算力和高精度实时性能,支持xx智能的多样化负载稳定运行,同时也大幅提升xx智能系统的整体效率和响应能力。
其中,通过 CPU 可以支持xx智能方案进行复杂的运动控制,集成的英特尔锐炫™ GPU 用于xx智能处理环境感知、任务识别、任务规划、大语言模型(LLM)、视觉语言模型(VLM)和端到端模型等复杂任务,NPU 则承载语音识别、实时视觉处理、传感器数据分析等需长时间运行的 AI 任务。
对xx智能解决方案而言,硬件是基础,而软件优化则是提升整体性能和用户体验不可忽视的一环。基于此,英特尔亦推出xx智能软件开发套件,通过包括 OpenVINO™ 工具套件、英特尔® oneAPI 工具包、Intel® Extension for PyTorch-LLM(IPEX)、英特尔® 工业边缘控制平台(ECI)、基于开源机器人操作系统的库、中间件和示例应用程序,使代码实现一次开发多平台部署,缩短评估和开发时间,加快客户应用程序的部署以及算法和应用的运行。
此外,英特尔亦提供跨平台 AI 模型优化工具以及端到端流程加速方案,以简化方案搭建过程,加快产品上市。

英特尔 ®xx智能软件开发套件
在持续推动xx智能软硬件创新的同时,英特尔亦携手本地生态伙伴展开深度合作,探索从技术研发到场景落地的全链路协同模式,构建起协同共进的产业生态格局,为行业发展注入强劲动力。
其中,信步科技推出的xx智能硬件开发平台 HB03,搭载英特尔® 酷睿™ Ultra 200 系列处理器和英特尔锐炫™ B570 显卡,能够提供强大且灵活的算力,并实现极强的控制实时性。信步 H03 平台通过紧凑结构、扩展接口与工业级可靠性设计,为xx智能 “大小脑” 融合构建了有力的硬件支撑。同时,浙江人形机器人创新中心也基于英特尔® 酷睿™处理器,打造出 “领航者 2 号 NAVIAI” 人形机器人,实现了可泛化高精准视觉伺服、多行为联合学习的长序列行为规划、视力融合的操作行为学习等技术突破,能够使其在工业场景中执行复杂任务,也可以在服务场景中完成人机交互和辅助等任务,助力机器人智能化的深度演进,并推动其向更高层次的智慧形态发展。
在xx智能产业迎来 “井喷前夜” 之时,英特尔xx智能方案凭借大小脑融合架构的创新,带来功耗、成本、算力的平衡,成为构建xx智能系统的理想选择。未来,英特尔也将持续深化技术创新,与生态伙伴拓展其在医疗、教育、养老等关键领域的应用场景,共建开放、协同的xx智能生态体系,使xx智能真正赋能千行百业,为社会的高效运转与可持续发展提供助力。
#近40年前「拉马努金图」概率的赌局
被姚班校友黄骄阳等三位数学家用物理方法终结
一切始于一场赌局。
20 世纪 80 年代末,在洛桑的一次会议上,两位数学家 Noga Alon 和 Peter Sarnak 展开了一场友好的辩论。两人当时都在研究由节点和边组成的集合即图,他们特别想更好地理解一种名为「扩展图」的看似矛盾的图类型,这种图的边相对较少,但仍然高度互连。
争论的焦点在于最优扩展图:那些连通性尽可能强的扩展图。Sarnak 认为这样的图很少见,他和两位合作者很快发表了一篇论文,运用数论中的复杂思想来构建示例,并指出任何其他结构都同样难以实现。
而 Alon 则寄希望于随机图通常展现出各种最优性质的事实,他认为这些极其优秀的扩展图会很常见。如果你从大量可能性中随机选择一个图,则几乎可以保证它是一个最优扩展图。
左为 Peter Sarnak,右为 Noga Alon。
如今,Sarnak 和 Alon 是普林斯顿大学的同事。几十年来,这场赌局的细节已经变得模糊不清。「当时并不太严肃,」Alon 回忆道,「我们甚至对赌局的内容都意见不一。」
尽管如此,这个传说依然流传,它微妙地提醒着数学家们,究竟谁才是对的。
最近,三位数学家通过探究物理学中一个关键现象,并将其推向极限,最终对这场赌局做出了裁决。他们两人都错了。
- 论文标题: Ramanujan Property and Edge Universality of Random Regular Graphs
- arXiv 地址:https://arxiv.org/pdf/2412.20263
扩展的极限
自 20 世纪 60 年代数学家开始研究扩展图以来,它们就被用于大脑建模、统计分析和构建纠错码。由于扩展图的边数极少,因此效率极高。同时,由于扩展图高度连通,因此仍然能够抵御潜在的网络故障。Sarnak 表示,这种矛盾「使得扩展图既违反直觉,又非常有用」。
因此,数学家们想要更好地理解它们。「减少边数」和「增加图的连通性」之间的这种矛盾可以延伸到多远?以及在张力最高的好的扩展图有多普遍?
为了回答这些问题,研究人员需要精确地定义扩展图。有很多方法可以做到这一点,其中一种是:为了将扩展图拆分成两个独立的部分,你需要擦除许多边。另一种是:如果你沿着图的边缘徘徊,在每一步随机选择方向,你很快就能探索整个图。
下图为扩展图示例,每个节点只有三条边,但连通性很高。如果你沿着图的边随机游走,那么探索整个图不需要花费很长时间。

下图为非扩展器示例,该图连通性较差,从一个节点到另一个节点的路径很少。

1984 年,数学家 Józef Dodziuk 证明,所有这些扩张度量都通过一个量联系起来 —— 至少对于某些类型的图而言是如此。在这些所谓的「正则图」中,每个节点都有相同数量的边,这确保了整个图的边数相对较少。因此,要使其成为扩展图,你只需证明它是连通的。这就是 Dodziuk 数(quantity)的来源。
要计算这个数,你必须首先构造一个由 1 和 0 组成的数组,称为邻接矩阵。这个邻接矩阵表示图中哪些节点通过边连接,哪些节点没有通过边连接。
然后,你可以使用该矩阵计算一系列数字,称为特征值(eigenvalues),这些数字可以提供有关原始图的有用信息。例如,最大的特征值给出了连接到图中每个节点的边数。Józef Dodziuk 发现,第二大特征值可以告诉你图的连通性。该数字越小,图的连通性越好 —— 这使得它成为一个更好的扩展图。
在 Józef Dodziuk 发现之后不久,Alon 和另一位数学家 Ravi Boppana 证明,如果正则图中的每个节点都有 d 条边,则第二个特征值不可能比

小很多。第二个特征值接近「Alon-Boppana 界限」的正则图是一个良好的扩展图;相对于具有相同边数的其他正则图,它的连通性良好。但是,如果第二个特征值实际上达到了界限,那么该图就是可以想象到的最优扩展图。
对于包括 Sarnak 在内的一些数学家来说,「Alon-Boppana 界限」是一个令人着迷的挑战。他们想知道:能否构建达到这个极限的图?
随机性赌博
在 1988 年发表的一篇具有里程碑意义的论文中,Sarnak、Alexander Lubotzky 和 Ralph Phillips 斯找到了方法。他们利用印度数学天才 Srinivasa Ramanujan 在数论领域取得的一项高超技术成果,构建了满足「Alon-Boppana 界限」的正则图。
因此,他们将这些最优扩展图称为「拉马努金图」(Ramanujan graphs)。(同年,Grigorii Margulis 使用了不同但同样高超的方法构建了其他示例。)

论文地址:https://link.springer.com/article/10.1007/BF02126799
新泽西州普林斯顿高等研究院的 Ramon van Handel 表示:「直观地看,你似乎可以预料到构建拉马努金图几乎难以实现的难度。并且看起来,最优图应该非常难以实现。」
但在数学中,难以构造的事物往往出奇地常见。「这是数学界的普遍现象,」van Handel 说。「任何你能想象的例子都不会具备这些属性,但一个随机的例子却会。」
包括 Alon 在内的一些研究人员认为,拉马努金图或许也适用同样的原理。Alon 认为,寻找这些图所需的巨大努力与其说是物质的丰富性,不如说更多地反映了人类的思维方式。这种信念促成 Sarnak 和 Alon 的赌局:Sarnak 打赌,如果把所有正则图都收集起来,其中只有极小一部分是拉马努金图;而 Alon 则认为几乎所有图都是拉马努金图。
很快,关于 Sarnak 和 Alon 打赌的传闻就在社区里流传开来,尽管人们对当时的记忆各不相同。「说实话,这更像是民间传说,」Sarnak 承认道,「我其实不记得那件事了。」
几十年后,在 2008 年,对大量正则图及其特征值的分析表明,答案并非一目了然。有些图符合拉马努金定理,有些则不然。这只会让找出确切的比例变得更加艰巨。
在证明一个适用于所有图(或所有图都不适用)的性质时,数学家们拥有丰富的工具箱。但要证明某些图符合拉马努金定理,而其他图则不然,则需要精确度,而图论学家们并不确定这种精确度从何而来。
后来发现,在一个完全不同的数学领域,一位名叫姚鸿泽(Horng-Tzer Yau)的研究员正在解决这个问题。在花了十多年时间研究与随机图相关的矩阵之后,姚鸿泽解决了一个有关它们行为的重大难题。
姚鸿泽
一个「疯狂」的想法
在图论研究者还在努力理解 2008 年那项研究的意义时,哈佛大学教授姚鸿泽已经沉迷特征值问题好几年了。他研究的特征值来源于更广泛的一类矩阵,这些矩阵的元素是通过随机方式生成的 —— 比如抛硬币或进行其他随机过程。姚鸿泽想弄清楚:使用不同的随机过程,矩阵的特征值会如何变化。
这个问题可以追溯到 1955 年,当时物理学家 Eugene Wigner 使用随机矩阵来模拟像铀这样重原子中原子核的行为。他希望通过研究这些矩阵的特征值,来了解系统所具有的能量。
很快,Wigner 注意到一个奇怪的现象:不同的随机矩阵模型的特征值似乎都呈现出相同的分布模式。对于任何一个随机矩阵,每个特征值本身也是随机的 —— 你选定一个数值区间,某个特征值落在这个区间内的概率是可以计算的。但神奇的是,这种概率分布似乎与矩阵的具体构造无关:无论一个随机矩阵的元素只是由 1 和 −1 组成,还是可以是任意实数,其特征值落入某个区间的概率都几乎不变。
Eugene Wigner
Wigner 在他研究的各种随机系统中,观察到了出人意料的普遍行为。如今,数学家们已经将这种行为的适用范围进一步拓展。
Wigner 曾猜想,任何随机矩阵的特征值都应遵循相同的概率分布。这个预测后来被称为普遍性猜想。
姚鸿泽表示这个想法太过疯狂,导致很多人根本不相信他说的是真的。但随着时间推移,他和其他数学家不断证明,这一猜想在许多不同类型的随机矩阵中都成立。一次又一次,Wigner 的理论被证实是正确的。
姚鸿泽开始思考,自己还能将这一猜想推进多远。他想寻找那些能突破对标准矩阵理解的问题。
于是,在 2013 年,当 Sarnak 提出让他研究与随机正则图相关的矩阵的特征值时,他接受了这个挑战。
如果姚鸿泽能证明这些特征值也满足普遍性猜想,那么他就能掌握它们的概率分布。接下来,他就可以利用这些信息来计算第二特征值达到 Alon–Boppana 界限的概率。
换句话说,他将能够为 Sarnak 和 Alon 的赌局 —— 有多少比例的正则图是拉马努金图 —— 给出一个明确答案。
于是,他开始动手了。
快要成功了
许多类型的随机矩阵,包括曾启发 Wigner 提出普适性猜想的那些矩阵,本身具备一些良好性质,使得人们可以直接计算它们的特征值分布。然而,邻接矩阵并不具备这些性质。
大约在 2015 年,姚鸿泽与他的研究生黄骄阳(2010-201 年在清华大学交叉信息研究院计算机科学实验班学习)以及另外两位合作者提出了一项计划。首先,他们将使用一个随机过程,对邻接矩阵中的元素做出微小调整,从而得到一个新的随机矩阵,这个矩阵具备他们所需的那些良好性质。
接着,他们将计算这个新矩阵的特征值分布,并证明它满足普遍性猜想。
最后,他们还要证明,这些所做的调整足够小,不会影响原始邻接矩阵的特征值 —— 这就意味着,原始邻接矩阵也满足普遍性猜想。
黄骄阳在概率论领域的研究,使他涉足了数学、物理与计算机科学中的多个难题。
2020 年,黄博士毕业后,他与合作者终于能够借助这一方法,将普遍性猜想扩展到一定规模的正则图。只要图的边数足够多,它的第二特征值就会呈现出几十年前 Wigner 研究过的那种分布。但要解答 Alon 和 Sarnak 之间的赌约,仅仅证明一部分正则图还不够 —— 他们需要对所有正则图都证明这一猜想成立。
到了 2022 年秋天,一位名叫 Theo McKenzie 的博士后研究员来到哈佛大学,希望深入了解黄骄阳、姚鸿泽及其合作者在 2020 年证明中使用的工具和方法。他有很多内容需要「补课」。「我们已经在这个问题上钻研了很长时间」姚鸿泽说。
但加州大学伯克利分校的数学家、McKenzie 的前博士导师 Nikhil Srivastava 表示,McKenzie 非常无畏,他并不害怕去攻克这些非常棘手的问题。
在花了几个月时间深入研究黄骄阳和姚鸿泽的方法后,McKenzie 终于做好准备,能够以新的视角和力量加入进来。「你希望有人能检查大量细节,并提出各种不同的问题,」姚鸿泽说,「有时候,你就是需要更多人手。」
一开始,这三位数学家只能取得部分结果。他们还无法精准地完成证明策略中的第二步 —— 计算经过微调的矩阵的特征值分布,因此还不足以证明所有正则图都满足普遍性猜想。但他们已经能够证明,这些特征值仍然满足一些关键性质,而这些性质强烈暗示:这个猜想极有可能成立。
McKenzie 是最后一位加入这个数学家团队的成员 —— 他们解决了一个关于所谓拉马努金图的争论,这个问题已经悬而未决了数十年。
「我知道他们已经接近彻底解决这个问题的边缘了。」Sarnak 说。
而事实证明,在另一项研究中,黄骄阳其实早已在尝试他们最终所需的那一关键要素。
闭合循环
黄骄阳正在独立研究一组被称为「循环方程(loop equations)」的数学公式,这些方程描述了随机矩阵模型中特征值的行为。他意识到,如果他、McKenzie 和姚鸿泽能够证明他们的矩阵足够精确地满足这些方程,那就能补上他们在第二步推理中所缺失的信息。
他们最终确实做到了。经过数月细致入微的计算,他们完成了证明。所有的正则图都遵循 Wigner 普遍性猜想:随机选取一个正则图,它的特征值将呈现出已知的那种分布形式。
这也意味着,这三位数学家现在已经知道第二特征值取值的具体分布情况。他们可以进一步计算出,有多少比例的第二特征值达到了 Alon-Boppana 界限 —— 也就是说,有多少比例的随机正则图是完美扩展图。三十多年后,Sarnak 和 Alon 终于得到了他们打赌的答案。这个比例大约是 69%,这意味着这些图既不算常见,也不算稀有。
最先得知这个消息的是 Sarnak。黄骄阳说:「他告诉我们,这是他收到过的最棒的圣诞礼物。」他笑着补充道:「所以我们觉得一切都值得了。」
这一结果也表明,普遍性猜想比研究者原先预想的更加广泛且强大。数学家们希望继续突破这一猜想的适用边界,并利用这次新证明中的技术来解决相关问题。
而与此同时,他们也可以稍稍放松一下,享受在神秘莫测的拉马努金图宇宙中,又多掌握了一点点知识的喜悦。
「我们两个其实都不太对,」Alon 说道。「不过,我还是稍微更接近正确一些,因为这个概率超过了一半。」他笑着补充道。
原文链接:
#d1模型
扩散LLM推理用上类GRPO强化学习!优于单独SFT,UCLA、Meta新框架d1开源
大语言模型的推理能力,不再是 AR(自回归)的专属。扩散模型现在也能「动脑子」,新框架 d1 让它们学会了解数学、懂逻辑、会思考。
当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能。
不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。
与此同时,离散扩散大语言模型(dLLM)成为有潜力的语言建模的非自回归替代。不像以因果方式逐 token 生成文本的自回归模型那样,dLLM 通过迭代去噪过程生成文本,在多步骤操作中优化序列的同时并通过双向注意力利用过去和未来的上下文。其中,LLaDA 等开放的掩码 dLLM 实现了媲美同尺寸自回归模型的性能,而 Mercury 等闭源 dLLM 进一步展现了出色的推理延迟。
然而,顶级的开源 dLLM 并没有使用 RL 后训练,使得这一有潜力的研究方向还有很大的挖掘空间。这一范式转变引出了重要的问题:RL 后训练如何在非自回归上下文中高效地实现?
RL 算法适应掩码 dLLM 面临一些独特的挑战,原因在于自回归模型采用的已有方法(如 PPO、GRPO)通过计算生成序列的对数概率来估计和优化策略分布,导致无法直接应用于 dLLM。虽然这种计算在自回归模型中通过序列因式分解很容易实现,但 dLLM 由于它们的迭代、非序列生成过程而缺乏这种自然分解。
为了解决这些问题,来自 UCLA 和 Meta AI 的研究者提出了一个两阶段后训练框架 d1,从而可以在掩码 dLLM 中进行推理。在第一阶段,模型在高质量推理轨迹中进行监督微调;在第二即 RL 阶段,研究者引入了用于掩码 dLLM 的新颖策略梯度方法 diffu-GRPO,它利用提出的高效一步(one-step)对数概率估计在 GRPO 的基础上创建。
研究者表示,他们的估计器利用了随机提示词掩码,作为策略优化的一种正则化,使得可以扩展 per batch 的梯度更新数量并减少 RL 训练所需的在线生成数量。这将极大地降低计算时间。
- 论文标题:d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
- 论文地址:https://arxiv.org/pdf/2504.12216
- 项目主页:https://dllm-reasoning.github.io/
- GitHub 地址:https://github.com/dllm-reasoning/d1
在实验部分,研究者使用 LLaDA-8B-Instruct 作为基础模型实例化 d1。他们将 d1-LLaDA 的性能与基础 LLaDA 模型以及仅使用 SFT 和仅使用 diffu-GRPO 训练的 LLaDA 模型进行比较。结果表明,d1 在四个数学和逻辑推理基准测试中始终优于基础模型,如下图 1 所示。d1-LLaDA 同样优于仅使用 SFT 方法和仅使用 diffu-GRPO 方法的模型。

方法概览
d1 是一个两阶段框架,通过依次结合监督微调(SFT)和在线强化学习(RL)来增强预训练掩码 dLLMs 的推理性能。
其中,在线强化学习(特别是 GRPO 算法)已被证明能有效提升离线训练语言模型的性能。然而,GRPO 的学习策略并不能直接泛化到 dLLMs。
GRPO 的目标函数(如公式 3 所示)需要同时计算当前策略 π_θ 和旧策略 π_θold 在以下两个层面的(对数)似然比:
- token 层面(用于优势权重计算);
- 序列层面(用于反向 KL 散度项)。
核心问题在于:研究者需要高效计算 dLLMs 生成内容的逐 token 对数概率和序列对数概率。
自回归(AR)模型,如 Transformer,直接对每个 token 的对数概率进行建模,并且可以通过链式法则使用一次前向传递轻松计算出序列级别的对数概率

。同样,KL 项可以分解为

。
与 AR 模型不同,dLLMs 不遵循序列对数概率的顺序分解。同时,每个 token 的对数概率计算成本也很高,因为解码过程中需要多次调用掩码预测器 f_θ。基于此,该研究提出了一个高效的对数概率估计器。
对于序列对数概率,该研究使用均场近似方法,将其分解为独立的每个 token 对数概率的乘积。
对于每个 token 的对数概率,该研究引入了一种估计方法,该方法仅调用一次 f_θ。
基于新引入的对数概率估计器,该研究将 GRPO 扩展到掩码 dLLMs,推导出 diffu-GRPO 的损失函数。

算法如下图所示。

实验结果
表 1 报告了基线模型 LLaDA-8B-Instruct 与采用不同后训练优化方案的模型,在四项任务上的零样本性能对比。

图 3 绘制了有效 token 的平均数量:

基于实验,该研究得出以下主要发现:
diffu-GRPO 在所有 12 种设置中都一致优于基础的 LLaDA 和 SFT(监督式微调)。diffu-GRPO 和 SFT 都相较于 LLaDA-8B-Instruct 基线有所提升,但 diffu-GRPO 显示出更持续且幅度更大的增益。具体来说,diffu-GRPO 在所有 12 种设置中都优于 LLaDA-8B-Instruct 和 SFT,而 SFT 仅在其中的 7 种设置中优于 LLaDA-8B-Instruct,这表明 diffu-GRPO 相比于单独的 SFT 实现了更强的整体性能提升。
LLaDA+diffu-GRPO 在所有设置中都优于基础的 LLaDA-8B-Instruct 模型,而 d1-LLaDA 在每种情况下都超过了 LLaDA+SFT。这表明,无论初始化是来自预训练模型还是经过 SFT 调整的检查点,diffu-GRPO 都能提供可靠的性能提升。
d1 训练方案实现了最显著的性能提升。通过先进行监督微调(SFT)、再结合 diffu-GRPO 训练所形成的 d1-LLaDA 模型,产生了超越单一方法的叠加增益。这种组合式方法在 12 个实验设置中有 11 项优于纯 diffu-GRPO 方案,表明两个训练阶段存在协同效应。
定性结果表明,在 SFT 和 d1-LLaDA 生成中出现了顿悟时刻。尽管与 LLaDA-8B-Instruct 相比,生成序列长度为 128 和 256 的性能随着 SFT、diffu-GRPO 和 d1 有所提高,但从质的方面看,在生成的推理轨迹中并未观察到显著差异。然而当序列长度达到 512 时,该研究开始观察到 SFT 和 d1-LLaDA 模型展现出两种关键能力:自我修正机制和回溯行为。
#AETHER
合成数据也能通吃真实世界?首个融合重建-预测-规划的生成式世界模型AETHER开源
近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,可助力机器人完成目标导向的视觉规划、4D 动态重建、动作条件的视频预测等复杂任务。
研究团队将几何重建与生成式建模深度融合,首创「重建 — 预测 — 规划」 一体化框架,通过 AETHER 使大模型能够感知周围环境,理解物体之间的位置、运动和因果关系,从而做出更智能的行动决策。
实验表明,传统世界模型通常聚焦于 RGB 图像的预测而忽略了背后隐含的几何信息,引入空间建模后,各项指标均显著提升,其中视频一致性指标提升约 4%。更重要的是,即使只使用合成数据进行训练,模型在真实环境中依然展现出强大的零样本泛化能力。
论文与模型已经同步开源。
- 论文标题:AETHER: Geometric-Aware Unified World Modeling
- 论文链接:https://arxiv.org/abs/2503.18945
- 项目主页:https://aether-world.github.io
,时长00:59
三大核心技术
攻克动态环境中的智能决策困境
传统世界模型主要应用于自动驾驶与游戏开发等领域,通过其丰富的动作标签来预测接下来的视觉画面。
但由于缺乏对真实三维空间的建模能力,这容易导致模型预测结果出现不符合物理规律的现象。同时,由于依赖且缺乏真实数据,面对更复杂多变的场景时,其泛化能力也明显不足。
针对以上问题,研究团队提出了生成式世界模型 AETHER,基于三维时空建模,通过引入并构建几何空间,大幅提升了模型空间推理的准确性与一致性。
具体而言,研究团队利用海量仿真 RGBD 数据,开发了一套完整的数据清洗与动态重建流程,并标注了丰富的动作序列。同时,他们提出一种多模态数据的动态融合机制,首次将动态重建、视频预测和动作规划这三项任务融合在一个统一的框架中进行优化,从而实现了真正的一体化多任务协同,大幅提高了模型的稳定性与鲁棒性。
面对复杂多变的现实世界,如何让具身智能系统实现可靠、高效的决策是人工智能领域的一项重大挑战。研究团队在 AETHER 框架中通过三项关键技术突破,显著提升了具身系统在动态环境中的感知、建模与决策能力。
- 目标导向视觉规划:可根据起始与目标场景,自动生成一条实现视觉目标的合理路径,并以视频形式呈现全过程。通过联合优化重建与预测目标,AETHER 内嵌空间几何先验知识,使生成结果兼具物理合理性。这使得具身智能系统能像人类一样「看路规划」—— 通过摄像头观察环境后,自动生成既安全又符合物理规律的行动路线。
- 4D 动态重建:通过自动标注流水线,构建合成 4D 数据集,无需真实世界数据即可实现零样本迁移,精准捕捉并重建时空环境的动态变化。例如,输入一段街景视频,系统即可重建包含时间维度的三维场景模型,精确呈现行人行走、车辆运动等动态过程,建模精度可达毫米级。

自动相机标注 pipeline。
- 动作条件视频预测:创新性地采用相机轨迹作为全局动作表征,可直接基于初始视觉观察和潜在动作,预测未来场景的变化趋势。相当于给具身智能系统装上了预测未来的「镜头」。
可零样本泛化至真实场景
不同于传统仅预测图像变化的世界模型,AETHER 不仅能同时完成四维时空的重建与预测,还支持由动作控制驱动的场景推演与路径规划。值得强调的是,该方法完全在虚拟数据上训练,即可实现对真实世界的零样本泛化,展现出强大的跨域迁移能力。
具体流程如下图所示,图中黄色、蓝色和红色分别表示图像、动作与深度的潜在变量,灰色表示噪声项,白色框为零填充区域。模型通过组合不同的条件输入(如观察帧、目标帧和动作轨迹),结合扩散过程,实现对多种任务的统一建模与生成。
就像在拼一副完整的动态拼图,观察帧提供了「现在的样子」,目标帧给出了「未来的样子」,动作轨迹则是「怎么从这里走到那里」,而扩散过程则像是拼图的拼接逻辑,把这些零散信息有序组合起来,最终还原出一个连续、合理且可预测的时空过程。

为了支持同时完成重建、预测和规划这三类不同任务,AETHER 设计了一种统一的多任务框架,首次实现在同一个系统中整合动态重建、视频预测和动作规划。
其核心在于:能够融合图像、动作、深度等多模态信息,建立一个跨模态共享的时空一致性建模空间,实现不同任务在同一认知基础上的协同优化。
实验结果
在多个实验任务中,AETHER 在动态场景重建方面已达到甚至超过现有 SOTA 水平。同时发现在多任务框架下,各个任务有很好的促进,尤其在动作跟随的准确度上面有较大的提升。

该方法有望为具身智能大模型在数据增强、路径规划以及基于模型的强化学习等方向研究提供技术支撑。

















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









