






-
Efficient Finetuning
1. P-tuning
出发点就是,硬模板构建不灵活,效果对于构造的文字十分敏感,因此加入一组可学习的visual token embedding来学习一个连续的prompt
很简单,就是单独开辟一个token embedding,shape就是num_visual_tokens x hidden_dim。然后后面会选择一个LSTM或者MLP层进行进一步拟合。得到的结果和原来LLM的 token embedding的结果做拼接,再输入transformer block。
2. P-tuning V2
1. 移除重参数化的编码器。以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning 中的 MLP 、P-Tuning 中的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
2. 针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与 Prefix-Tuning 中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
3. 引入多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务学习对我们的方法来说是可选的,但可能是相当有帮助的。一方面,连续提示的随机性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。我们的实验表明,在一些困难的序列任务中,多任务学习可以作为P-tuning v2的有益补充。
其他的和prefix tuning一样,将每层的 kv插入Prompting
3. prefix tuning
(总结: 就是给每一层LLM都加入visual token,且是拼接在K,V之后的,拼接完了之后再做attention,最后attention的结果就是原始attention结果和拼接的部分通过门控机制做输出,一般来说也是要加MLP层的)
针对每种任务,学习prefix vector
启发于prompting,调整上下文内容让模型去输出自己想要的内容
核心就是找到一个上下文去引导模型解决NLP生成任务
传统情况下,我们为了得到想要的结果,会人工去设计一些模版,这被称为硬模板

这种人工设计模版的方式往往需要大量尝试,所以另一种可以通过模型学习的,添加一组没有明确意义的prompt tensor的方式被提出,叫做软模板
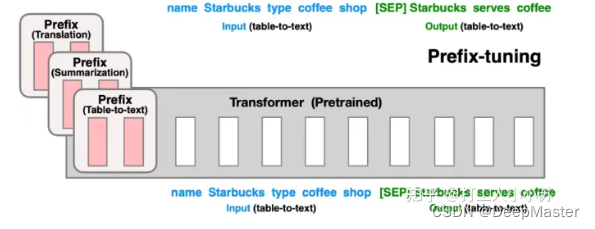
实际实现中,就是添加了一个embedding层,形状为prefix_tokens * target_dims,
这个target_dims在p-tuing中就是直接等于hidden_size.
但是prefix-tuning在实验过程中发现这样效果并不好,于是改成在每层都加入prefix_layer,其实就是在每层的attention计算的时候,给K,V tensor(x Wk, x Wv之后的结果)前面拼接prefix tensor

通过上面等式的变换,等式的前部分是不加入prefix向量的初始attention计算的公式,后半部分则是上下文向量无关的部分。通过一个类似门的机制来计算前后两部分的比重
其实就是在原有attention中加入了一个Q tensor和k v的prefix tensor计算attention的过程,结果用门控机制做加和
关于Embedding部分,实现在了一个PrefixEncoder中,作者实验结果中得出,如果仅仅对prefix tensor做优化,结果不稳定,加入一个MLP层会更好,MLP结构就是(hs ->low_dim)+激活函数+(low_dim->hs),就是先降维再升维,训练完后仅保留MLP输出的结果
class PrefixEncoder(torch.nn.Module):
"""
The torch.nn model to encode the prefix Input shape: (batch-size, prefix-length) Output shape: (batch-size, prefix-length, 2*layers*hidden) """ def __init__(self, config: ChatGLMConfig):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
# Use a two-layer MLP to encode the prefix
kv_size = config.num_layers * config. hidden_dim* 2
self.embedding = torch.nn.Embedding(config.pre_seq_len, kv_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(kv_size, config.hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.hidden_size, kv_size)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len,
config.num_layers * config. hidden_dim * 2)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values关于Embedding的维度,输出是hs * layer_nums*2,因为每一层都要加入prefix,所以乘上layer_nums,由于要给K V都拼接,所以乘2
self.prefix_projection用于区分是否要加入MLP结构,这也是区分Prefix tuning和p-tuningV2的一个方式,p-tuning v2中认为中重参数化的方式收益很小,选择不加入MLP层,其他部分基本和Prefix tuing一致。
具体插入过程,在huggingface实现中,是通过past_key_values的方式给巧妙地传递到每层的
4. 关于传统的prompt tuing
Prompt Tuning是一种微调方法,它在预训练语言模型的输入中添加可学习的嵌入向量作为提示。这些提示被设计成在训练过程中更新,以引导模型输出对特定任务更有用的响应。
Prompt Tuning和Prefix Tuning都涉及在输入数据中加入可学习的向量,这些元素是在输入层添加的,但两者的策略和目的是不一样的:
Prompt Tuning:可学习向量(通常称为prompt tokens)旨在模仿自然语言提示的形式,它们被设计为引导模型针对特定任务生成特定类型的输出。这些向量通常被看作是任务指导信息的一部分,倾向于用更少量的向量模仿传统的自然语言提示。
Prefix Tuning:可学习前缀则更多地用于提供输入数据的直接上下文信息,这些前缀作为模型内部表示的一部分,可以影响整个模型的行为。
下面的训练例子说明了两者的区别:
Prompt Tuning示例:
输入序列: [Prompt1][Prompt2] "这部电影令人振奋。"
问题: 评价这部电影的情感倾向。
答案: 模型需要预测情感倾向(例如“积极”)
提示: 无明确的外部提示,[Prompt1][Prompt2]充当引导模型的内部提示,因为这里的问题是隐含的,即判断文本中表达的情感倾向。
Prefix Tuning 示例:
输入序列: [Prefix1][Prefix2][Prefix3] "I want to watch a movie."
问题: 根据前缀生成后续的自然语言文本。
答案: 模型生成的文本,如“that is exciting and fun.”
提示: 前缀本身提供上下文信息,没有单独的外部提示
Adapter tuing
Lora系列
Efficient Inference
Quantization基础
数据类型
Float32

符号位用以标明浮点数的正负,指数部分用以标识浮点数的整数,尾数部分用于标识浮点数的尾数。
尾数部分(fraction)用来表示精度


计算方式如上。
exponent的计算部分 -127,是根据exponent部分的位数-1得到的, 就是2 ^ (8-1) -1 = 127
(比如fp16,exponent是5位,那么这里就是2 ^ (5-1) -1 = 15)
但是这样有个问题就是不能够表示0, 于是有两种方式表示float32,根据exponent部分是否为0
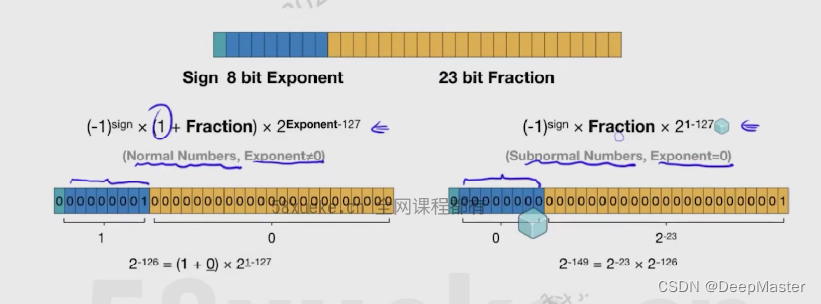
不为0时,按照我们刚才的方式进行计算
为0时,fraction部分就不在+1了
其他数据类型:
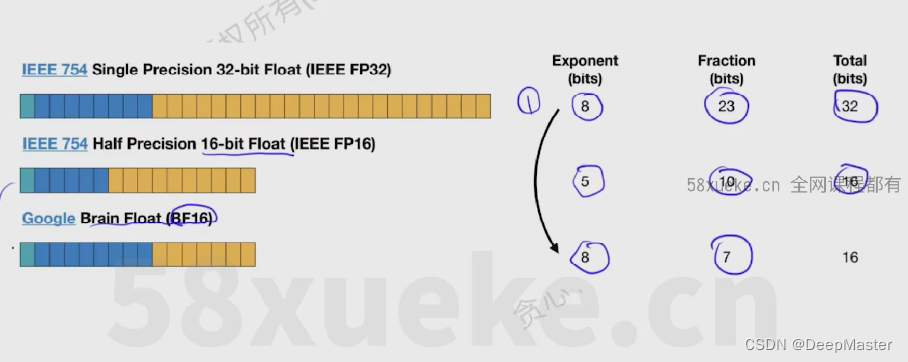
比如fp16 就是一个符号位,exponent 5位,fraction部分10位
但是有一种BF16的数据,也是16位,但是只有7个bit来表示数据,fraction部分位数更少,这样精度会比bf16更低,但是exponent位数更多,相应的其数据表示的范围就更大一些
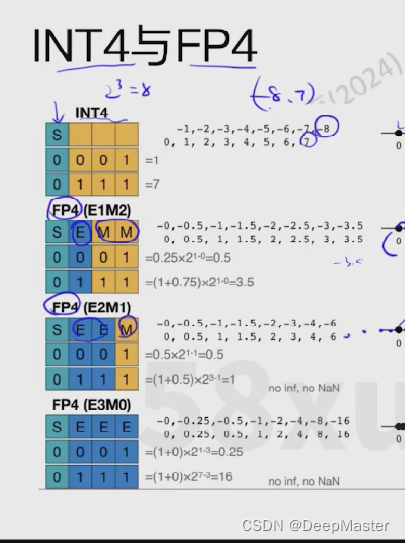
像INT4这种整型类型,就只有exponent部分,没有fraction部分,不存在精度的概念
量化基本概念
量化通常是指从浮点数到整数的映射过程 [245],目前比
较常用的是 8 比特整数量化,即 INT8 量化。针对神经网络模型,通常有两种类型的数据需要进行量化,分别为 权重量化(也称为模型参数量化)和激活(值)量化,它们都以浮点数形式进行表示与存储。
一般形式是
𝒙𝒒 = 𝑅(𝒙/𝑆) − 𝑍.
R()用于四舍五入,S为缩放因子,𝑍 表示零点因子,用于确定对称或非对称量化,𝑍为0就是对称量化
反量化的过程是
𝒙˜ = 𝑆 · (𝒙𝒒 + 𝑍).
量化误差是原始值 𝒙 和恢复值 𝒙˜ 之间的数值差异:

量化类型
- 均匀量化和非均匀量化
根据映射函数的数值范围是否均匀,可以将量化分为两类:均匀量化和非均匀量化。均匀量化是指在量化过程中,量化函数产生的量化值之间的间距是均匀分布的。在非均匀量化方法中,它的量化值不一定均匀分布,可以根据输入数据的分布范围而进行调整。其中,均匀量化方法因其简单和高效的特点而在实际中被广泛使用。
- 对称量化和非对称量化
对称量化与非对称量化的一个关键区别在于整数区间零点的映射,对称量化需要确保原始输入数据中的零点(𝑥 = 0)在量化后仍然对应到整数区间的零点。而非对称量化则不
同,根据前面的公式可以看出此时整数区间的零点对应到输入数值的 𝑆 · Z
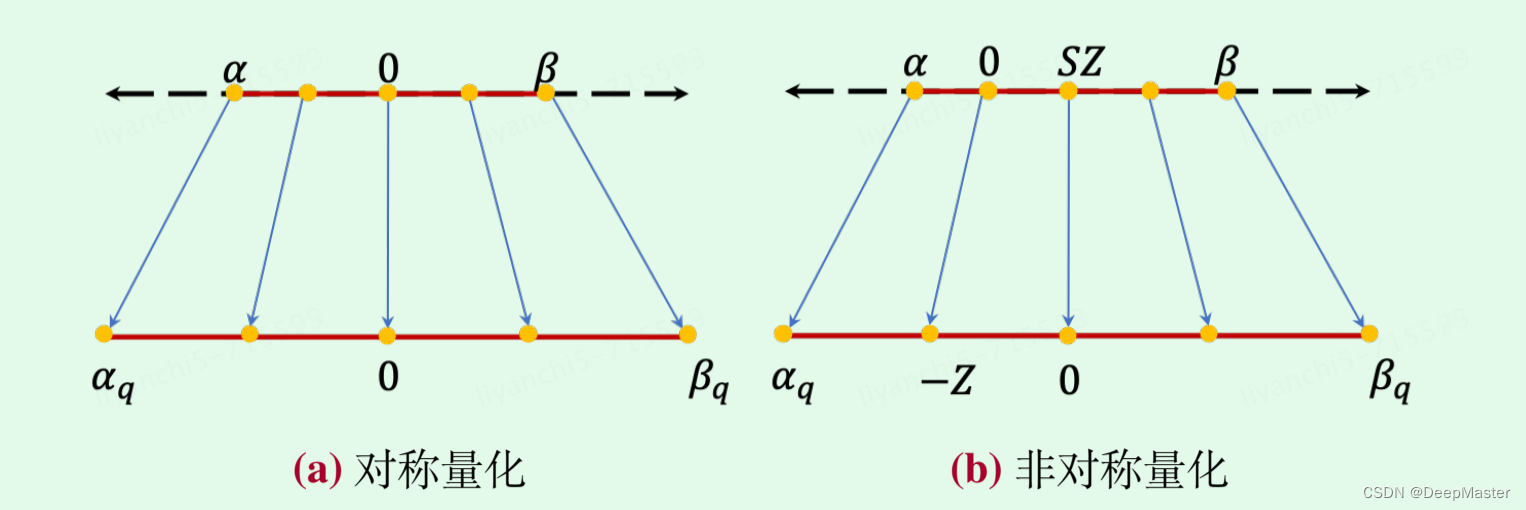
- 量化粒度
一般有三种,Per-tensor quantization 、Per-channel Quantization 、 Group Quantization
最基本的就per-tensor Quantization这是最基本的方法,对于每个tensor计算一个S Z,若tensor中存在异常值,则会影响整个tensor的量化,quantization error较大
为了尽量缩小量化后模型和原模型的差距,可以针对每个张量定义多组量化参数,例如可以为权重矩阵的列维度(也称为 “通道”)设置特定的量化参数,称为按通道量化Per-Channel Quantization。还有一些研究工作采用了更细粒度的量化方案,对一个通道的数值细分为多个组,即按组的方式进行量化Group Quantization。(比如128个参数为一个组);在神经网络量化中,从按张量到按组,量化粒度越来越小,且使用较小的粒度通常可以提高量化的准确性,有效保持原始模型的性能。但是由于引入了更多的量化参数,在使用时会带来额外的计算开销,所以在选择量化粒度的时候要做一个trade-off
Example
以 8 比特量化为例。给定输入数据 𝒙 = [ [1.2, 2.4, 3.6], [11.2, 12.4, 13.6]]
1. 非对称量化
首先需要将待量化数据的边界和量化目标数据范围对齐,比如这里最小值是1.2 那么就对应int8 的-128, 最大值是13.6 对应int8的127
根据反量化公式,有
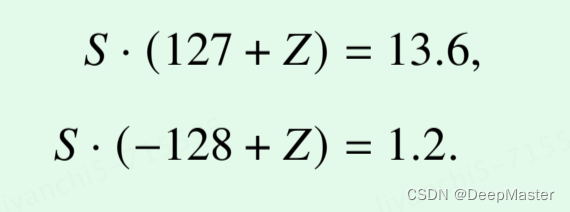
有 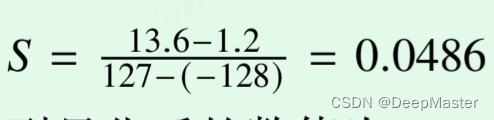
其实S就等于(待量化数据的尺度) / (目标数据类型的尺度),𝑍 = −152
,可以得到量化后的数值为 𝒙𝒒 = [ [−127, −103, −78], [78, 103, 127]]。反量化后的数据为 𝒙˜ = [ [1.2157, 2.3827, 3.5984], [11.1843, 12.4000, 13.5671]]
2. 对称量化
对于对称量化来说,量化前数据的0要对应量化后的离散值的0,Z =0
对称量化需要确保整数区间覆
盖到的输入数据 𝒙 的取值范围是 [−13.6, 13.6]
也就是量化前数据的绝对值的最大值的正负值和目标量化数据类型的最大最小值对应
13.6 -> 127, -13.6 -> -128
此时 𝑆 = 0.1067,量化后得到 𝒙𝒒 = [ [11, 22, 34], [105, 116, 127]]。反量化后的数据为 𝒙˜ = [ [1.1733, 2.3467, 3.6267], [11.2000, 12.3733, 13.5467]]
由于0点要对应的缘故,所以当量化前的值都是正值时,量化后的数据也都是正值,相当于是-13.6到1.2这部分没有实际数值存在,这会导致大量整型数值的浪费,由于覆盖的范围更大,对称量化会引入更大的量化误差。可以看到,对称量化的数据反量化后的结果与原始结果的差异要大于非对称量化。
Post-training quantization
(训练完后做量化然后做推理)
两个需要量化的点,一个是模型的权重,一个是激活值
一种传统的方式就是,首先让模型保持原有权重(非quantization),让模型过一个小数据集,确定每层输出的激活值的S和Z的大致范围
推理时,首先让输入quanzition,利用刚才得到S和Z做量化,然后反量化,再让权重反量化,计算得到一个FP16/FP32的输出,然后再让这个输出做量化,再反量化,再让下一层权重量化,再计算WX... 以此类推
1. 权重量化
主流的权重量化方法通常是基于逐层量化的方法进行设计的,旨在通过最小化逐层的重构损失来优化模型的量化权重,可以刻画为:

其中 𝑾,𝑾^ 分别表示原始权重和量化后的权重,𝑿 为输入。
GPTQ的基本想法是在逐层量化的基础上,进一步将权重矩阵按照列维度分组(例如 128 个列为一组),对一个组内逐列进行量化,每列参数量化后,需要适当调整组内其他未量化的参数,以弥补当前量化造成的精度损失。因此,GPTQ 量化需要准备校准数据集。
GPT-Q采用 int4/fp16 (W4A16) 的混合量化方案,其中模型权重被量化为 int4 数值类型,而激活值则保留在 float16,是一种仅权重量化方法。在推理阶段,模型权重被动态地反量化回 float16 并在该数值类型下进行实际的运算
AWQ指出 LLM其实只有一小部分参数 对于模型性能较重要,需要加强对这部分参数的关注。通过观察激活值,引入针对权重的激活感知缩放策略
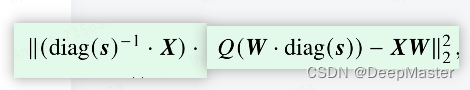
其中 𝑄 为量化函数。通过引入缩放因子 𝒔,AWQ 算法可以使得量化方法更为针对性地处理关键权重所对应的权重维度。AWQ在量化过程中会跳过一小部分权重,这有助于减轻量化损失
2. 激活值量化
一般来说,激活值量化比权重量化更难。
当模型参数规模超过一定阈值后(如6.7B),神经网络中的激活值中会出现一些异常的超大数值,称为异常值涌现现象。有趣的是,这些异常值主要分布在 Transformer 层的某些特定激活值特征维度中。
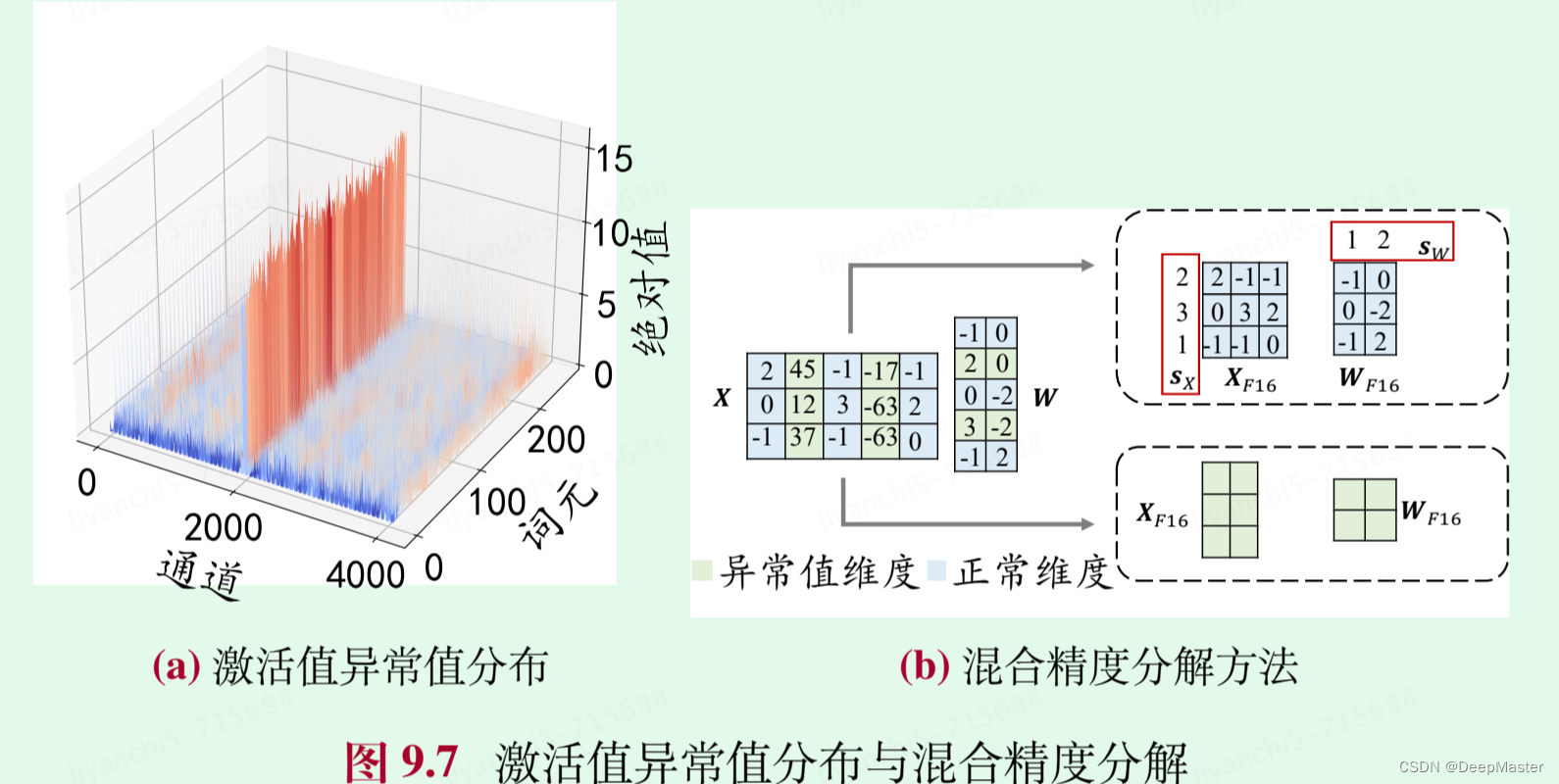
如图a,激活值中有一个通道的值特别大。在量化的时候就可以将这部分激活值和其他激活值分别进行处理。 这里就涉及到混合精度分解
对于这两部分进行计算时分别使用 16-比特浮点数(FP16)和 8-比特整数(INT8),从而以较高精度地恢复
过程:
1. 非异常值维度
首先将激活值和权重分别量化到 8 比特整数,得到 𝑿𝐼8 和 𝑾𝐼8
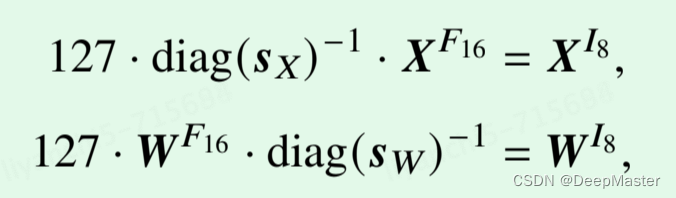
,𝒔𝑋 和 𝒔𝑊 分别表示输入的激活值和权重中每一行/每一列中绝对值的最大值
就是每行/列/通道 除以最大值乘以127
diag 表示将向量中的元素排列在对角线上,其他位置为零,形成对角矩阵
在forward时,要进行反量化,具体做法是
先用INT8直接做计算

得到的结果用32位的整数保存,然后再进行反量化
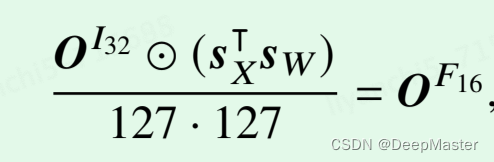
2. 异常值部分
直接采用 16 比特浮点数乘法
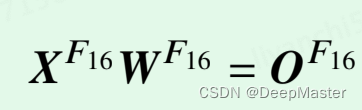
这两部分各自得到的结果进行相加即可得到最终的结果
-
优化
频繁地量化、反量化可能导致模型推理时效率很低,有一种优化思路就是减少反量化量化操作和尽量用Int做计算
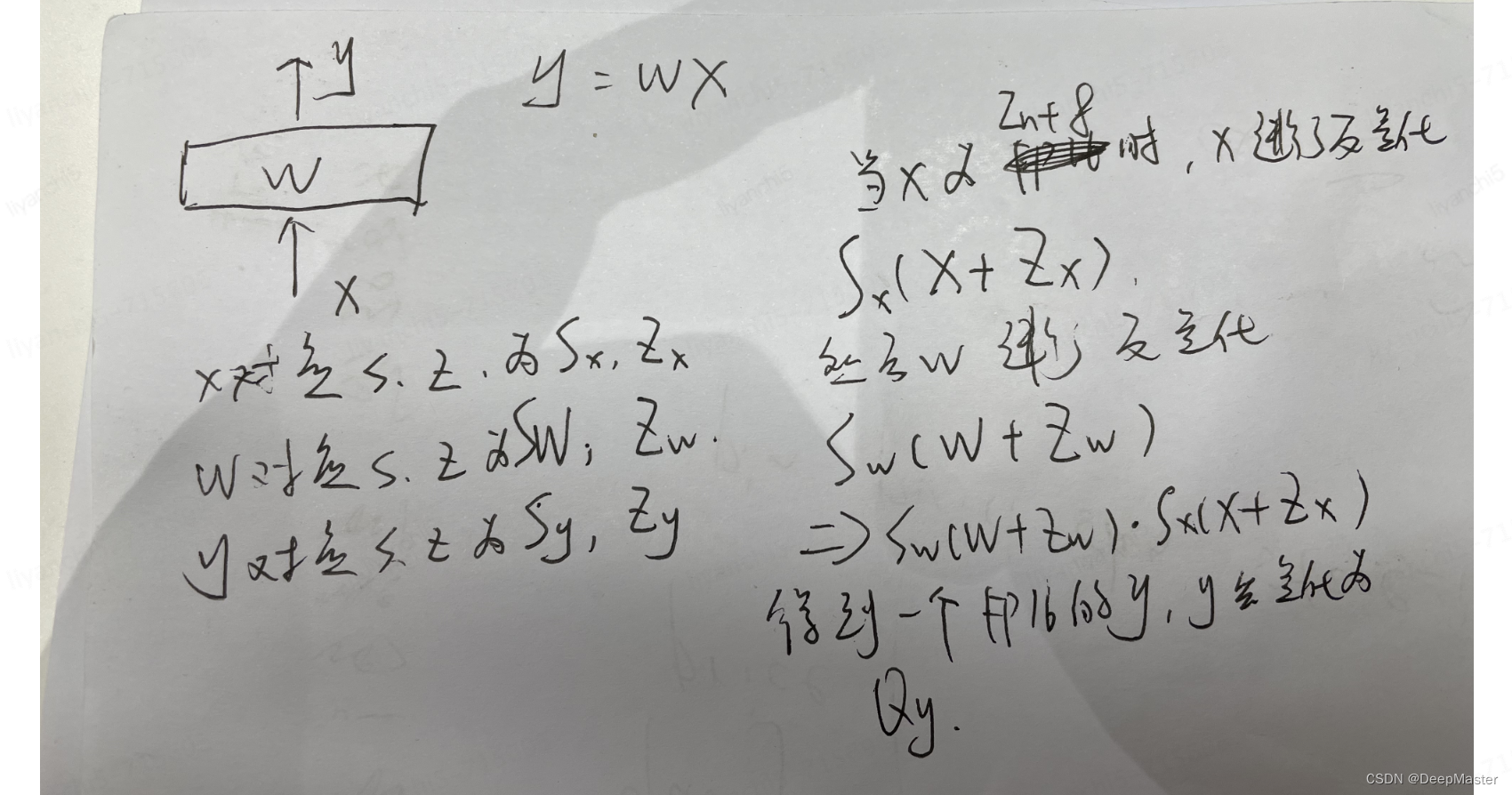
此时Qy为int8类型,就是我们想要的结果
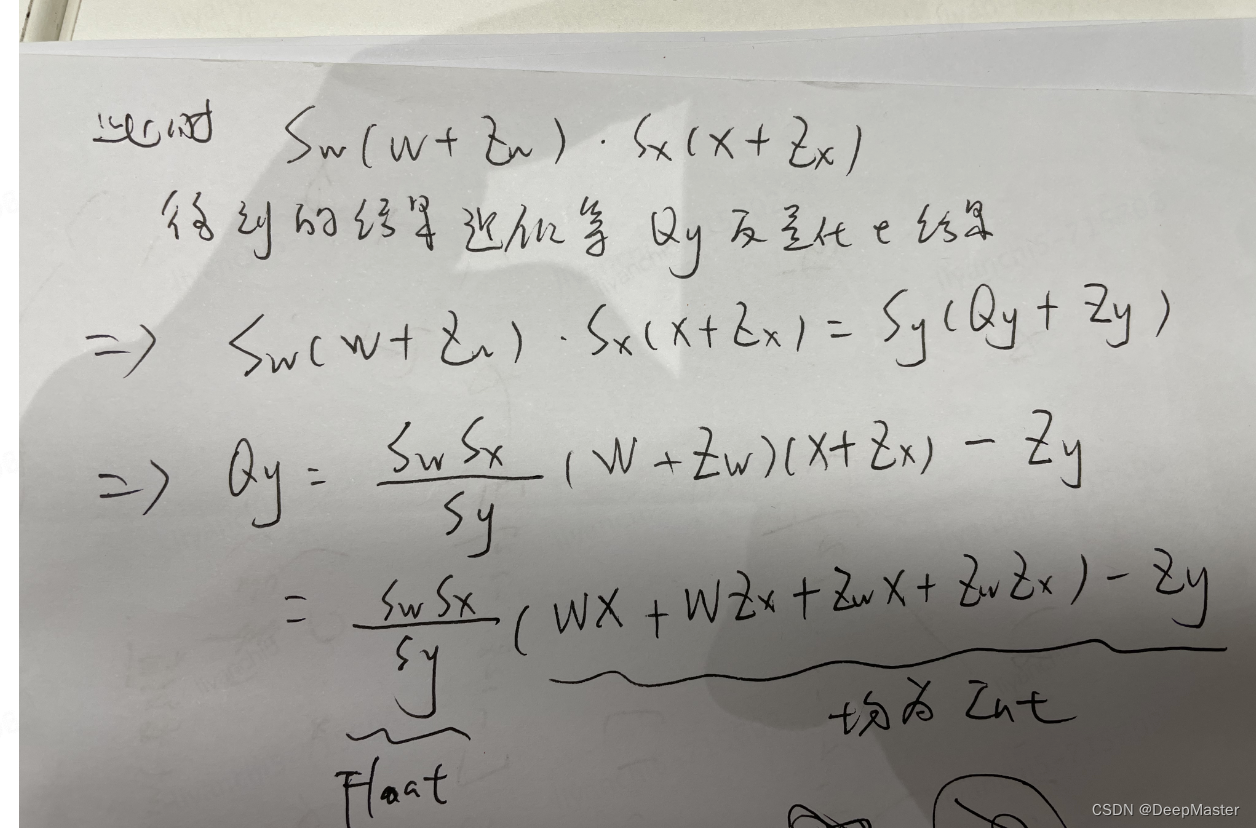
对于int部分,很多硬件都有专门优化过,所以计算速度会很快
而且除了x是动态值,其他的都是提前只晓得,可以提前算好,比如W*Zx, Zw * Zx
对于FLOAT部分 采用bit shift方法也可以高效计算。
LLM常用量化方法
1. SmoothQuant
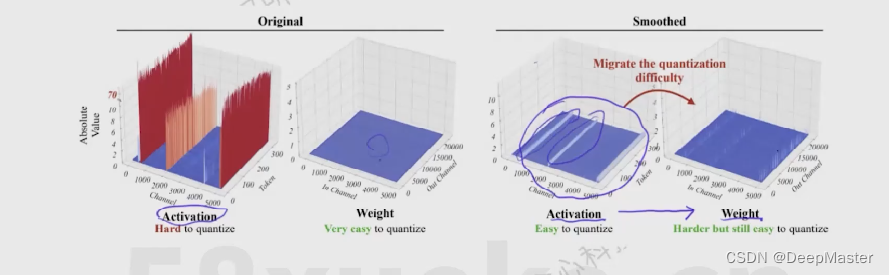
问题:权重好量化,但激活值中常存在异常激活值
解决方法:将模型权重放大,将激活值缩小,将量化难度放到同一尺度上再进行量化
公式:
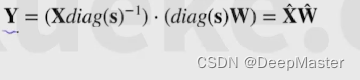
将X除以S,用于缩小X的大小。 将W乘以S,用以放大权重大小
S的计算公式是:
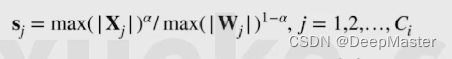
其中α用以调控X 和W的重要程度,α=1则完全以X为主,α=0,则以W为主,一般α设为1/2

以此类推,可计算出

然后对X W的每行/每列 除以/乘上 相应的S

比如X的第一列 除以S1。W的第一行乘以S1, X的第一列 除以S2。W的第一行乘以S2...
然后再进行量化
2. AWQ
针对极低bit量化效果不好为出发点
对不重要的参数用int3量化,对重要参数用fp16
设计了一个loss,用来计算哪些参数改变之后对LOSS影响较小,哪些对loss影响较大
Quantization-aware training
通过训练,来让学习应该如何去量化,甚至去学习出S和Z,成本较高
高效微调增强量化
(将量化的过程融合到训练里,减少量化损失)
通过微调和量化相结合的方式来提高模型的性能。通过在微调的基础上应用量化技术,可以进一步优化模型在低精度下的性能,同时保持较高的准确性,比如GPT-Q
一些经验性结论
1. INT8 权重量化通常对于大语言模型性能的影响较小,更低精度权重量化的效果取决于具体的量化方法。与小型语言模型不同的是,低比特权重量化对于大语言模型的影响通常较小 。因此,在实际使用中,在相同显存开销的情况下,建议优先使用参数规模较大的语言模型,而不是表示精度较高的语言模型,量化精度为 4 比特的 60GB 的语言模型在性能上往往会优于量化精度 8 比特的 30GB 的语言模型
2. 当 Transformer 语言模型的参数规模超过一个阈值后,激活值开始出现较大的异常值 [249]。数值较大的异常值对大语言模型激活量化带来了重要的挑战。为了克服这一问题,需要采用特定的处理方法,例如混合精度分解 [249]、细粒度量化和困难值迁移 来减轻异常值的影响
3. 轻量化微调方法可以用于补偿量化大语言模型的性能损失
上述基于 LoRA 微调的性能补偿方法能够较好地恢复超低比特量化模型的性能:QLoRA 在基于 4 比特量化模型的微调后,能够获得与 16 比特模型全参数微调以及 LoRA 微调相似的效果。总结来说,通过轻量化微调来补偿量化大语言模型的精度损失,可以在模型效果和训练成本之间取得较好平衡,具有良好的应用前景。

















 2612
2612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









