









昇腾Atlas800IA2安装GPUStack
- 部署参考官网
自GPUStack更新到了V0.6版本后,已经开始支持昇腾硬件了,也为国内的硬件生态添加了一柄利器。本文介绍如何在昇腾Atlas800IA2使用GPUStack,并部署大模型(基于Mindie的环境单机设备部署)。
一、说明
1、根据官网文档介绍目前GPUStack支持的设备有如下:
- Supported Devices
- Ascend 910B series (910B1 ~ 910B4)
- Ascend 310P3
2、昇腾后台推理引擎支持如下:
- Supported backends
- llama-box (Only supports FP16 precision)
- MindIE (GPUStack提供的镜像使用的MindIE1.0的版本)
3、设备信息
- Atlas800IA2(32GB)
- 内存(2T)
- 硬盘 (8T)
4、软件信息
- 固件驱动 (24.1.RC3)
- Docker version 19.03.0
- 基础软件安装请参考之前文章或者是官网文章安装,不赘述。
二、GPUStack安装使用
1、首先获取gpustack/gpustack:latest-npu镜像。
- 可以直接使用如下命令下拉:
docker pull gpustack/gpustack:latest-npu
- 如果下载不了,可以使用如下命令下载tar包
wget https://tools.obs.cn-south-292.ca-aicc.com:443/tools/mindie_docker_images/gpustack-npu-910B.tar
然后使用docker load < gpustack-npu-910B.tar加载
使用docker images查看镜像是否下拉成功:

2、创建并运行容器
- 创建命令参考
docker run -d --name gpustack \
--shm-size=16g \
--privileged=true \
--restart=always \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
--network=host \
--ipc=host \
-v /data:/var/lib/gpustack \
gpustack/gpustack:latest-npu
# 其中-v /data:/var/lib/gpustack是将物理机的/data挂载到容器/var/lib/gpustack目录下
运行以上命令后如果不出错的话,容器就能正常跑起来了。

可以使用命令:docker logs -f gpustack,检查容器是否正常运行。

如果显示的日志正常,如上图,请在浏览器中打开 http://服务器IP 以访问 GPUStack UI。使用用户名 admin 和默认密码登录 GPUStack。可以运行以下命令来获取默认设置的密码:
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password

第一次登录需要修改密码。
进入UI界面:
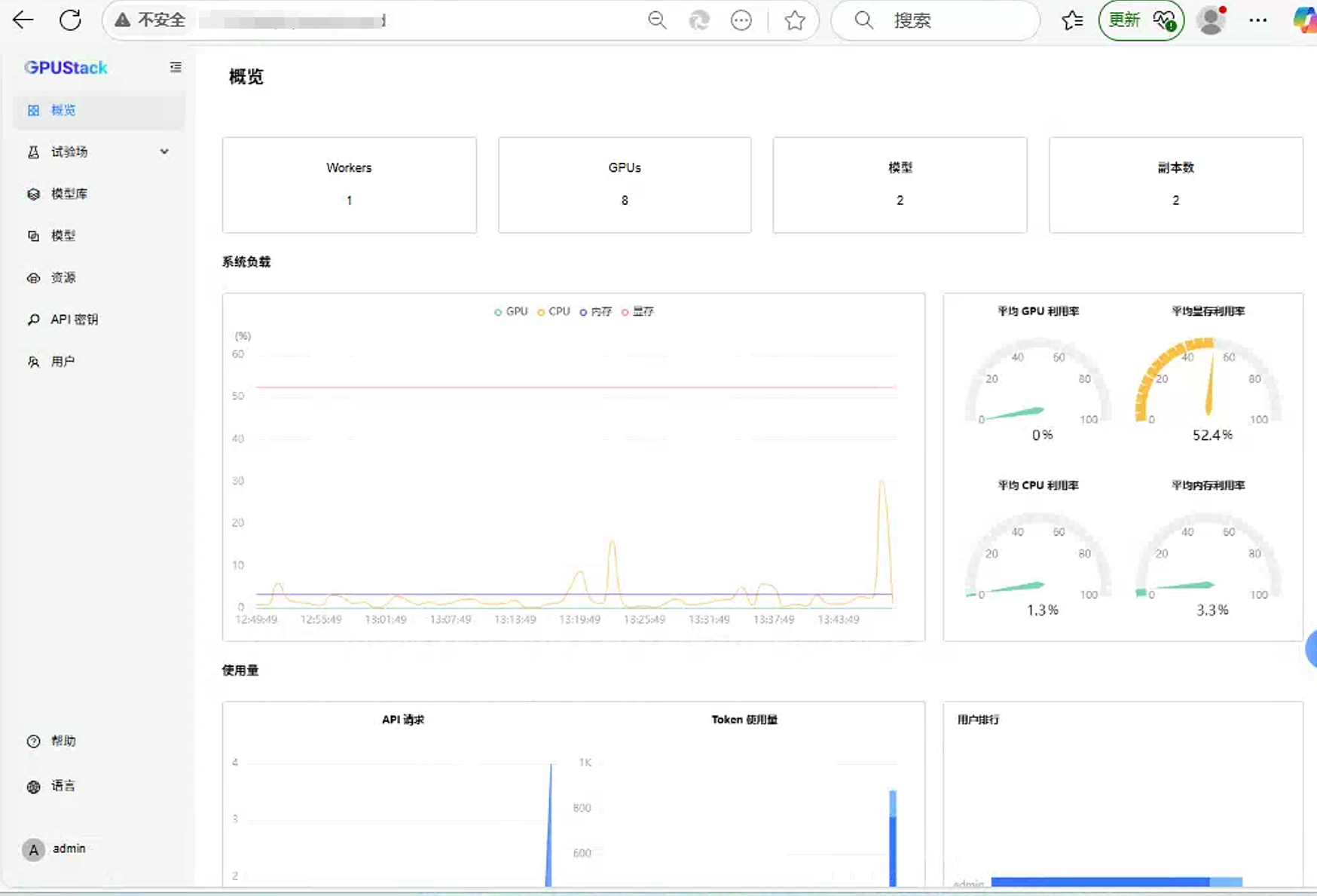
三、部署模型
1、以QWQ-32B为例,在GPUStack上部署。
- 首先下载QwQ-32B模型,本次使用的是QwQ-32B-W8A8的模型来部署。
wget https://tools.obs.cn-south-292.ca-aicc.com:443/samples/Qwen/QwQ-32B-W8A8-.tar
下载完成后,解压到物理机的 * /data * 路径下,该路径为与容器/var/lib/gpustack路径共享,方便后续模型从本地拉取操作。
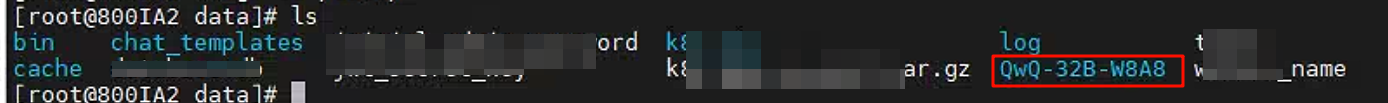
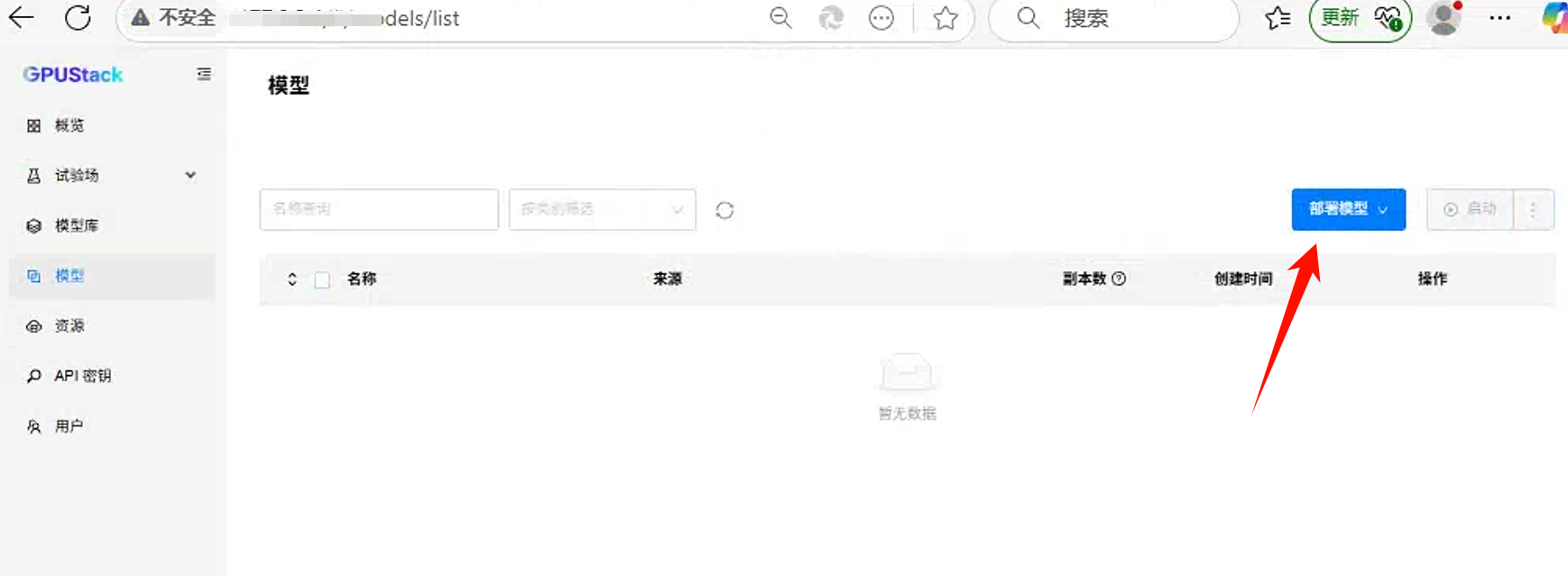
- 模型部署
进入模型,点击部署模型,选择本地模型。具体操作如下:
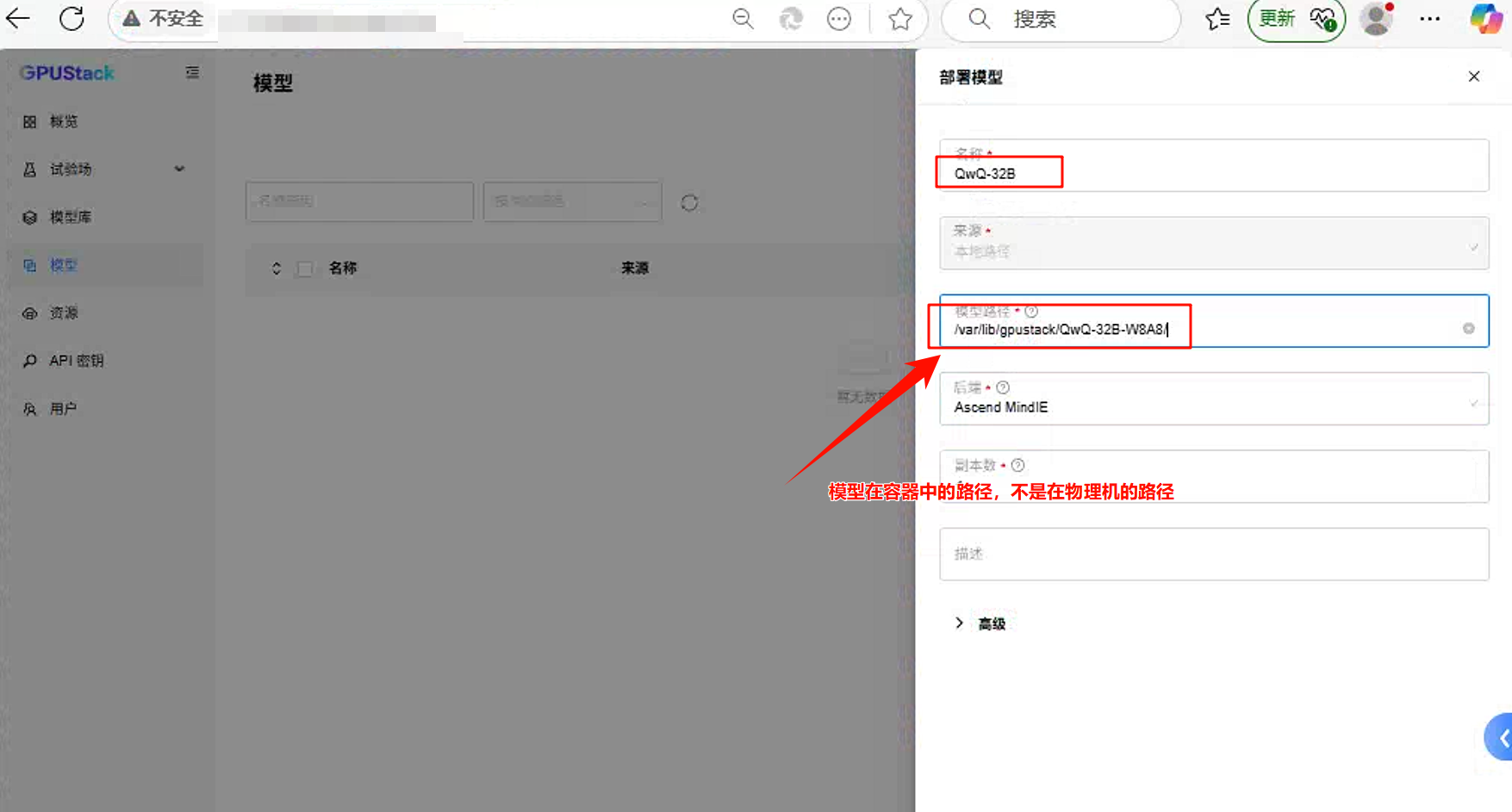
*** 注意:模型选择要选择容器中的路径,不要填物理机的路径,然后点击提交。
递交完成后,如下图所示:
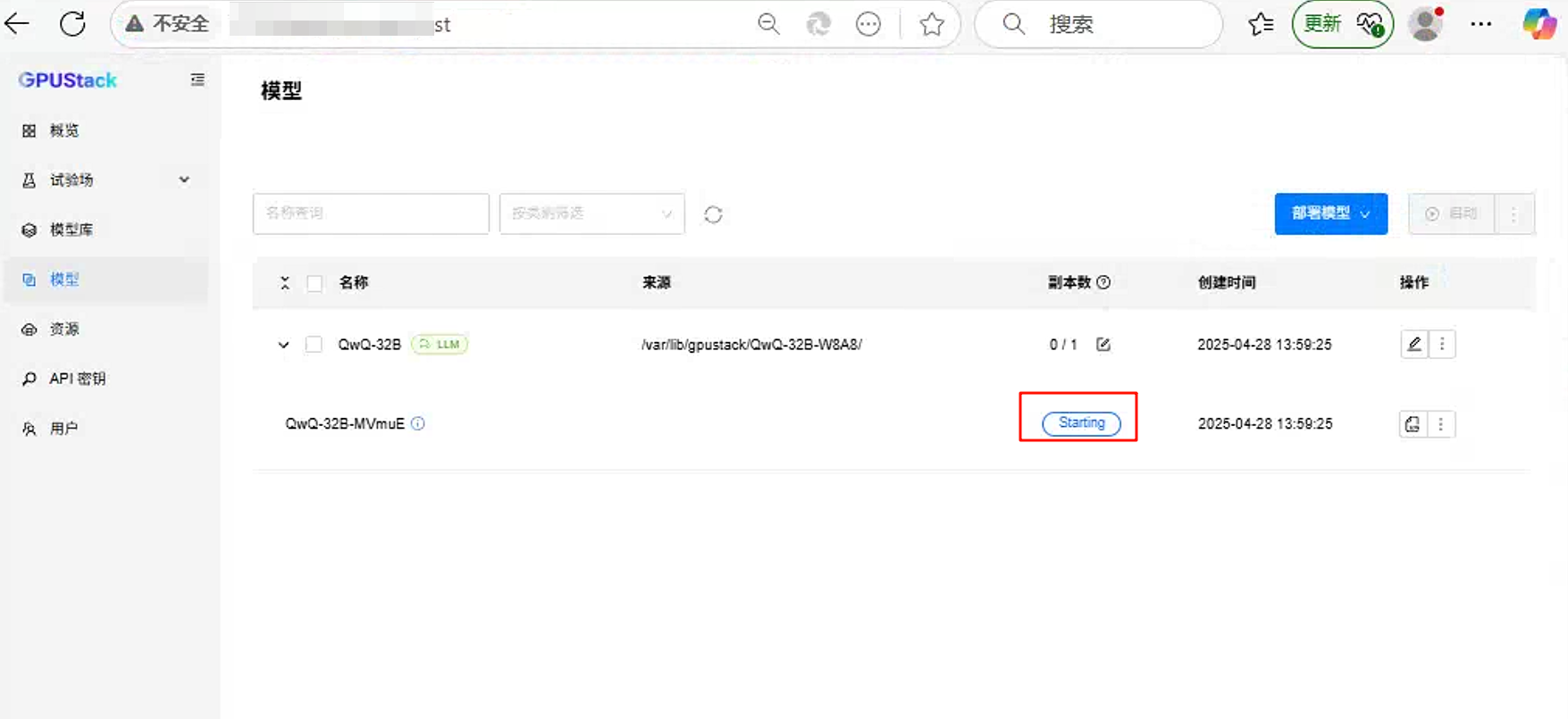
运行成功后的截图:
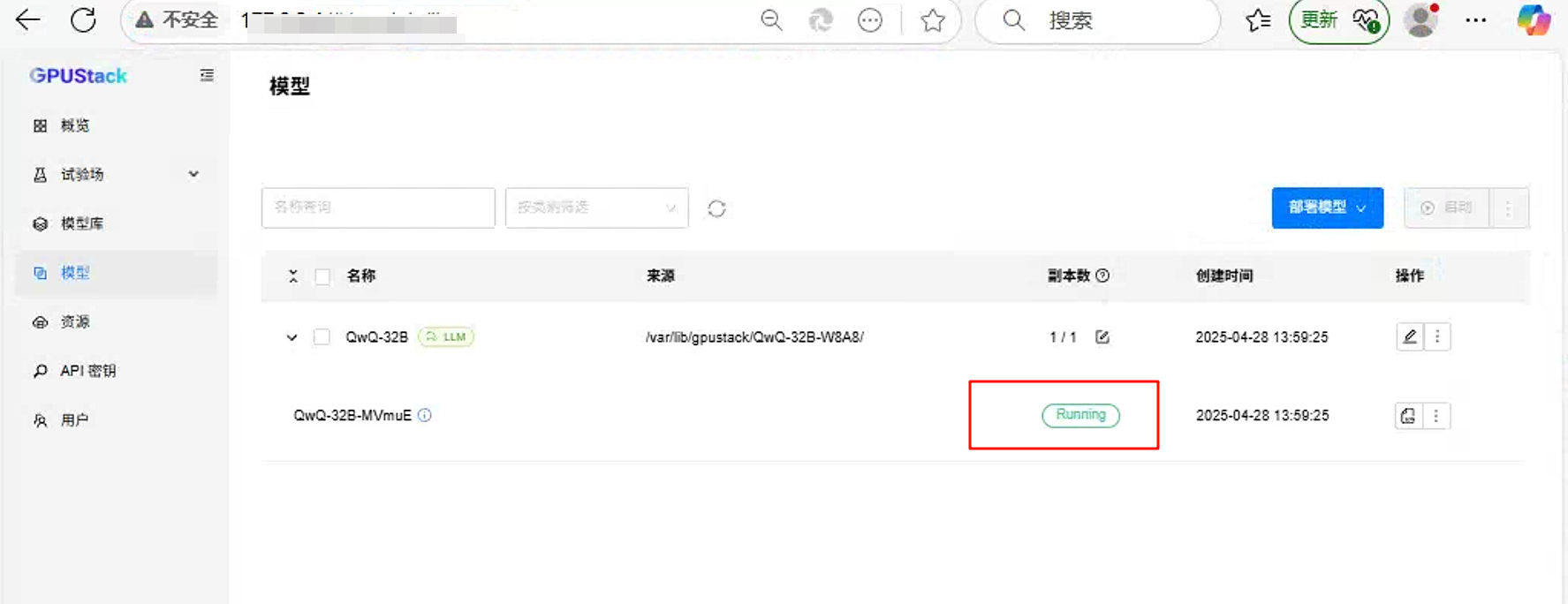
3、模型对话测试
点击试验场,点击对话,右边的模型需要选择你刚刚部署的模型(QwQ-32B)
在对话框中输入聊天内容开始聊天。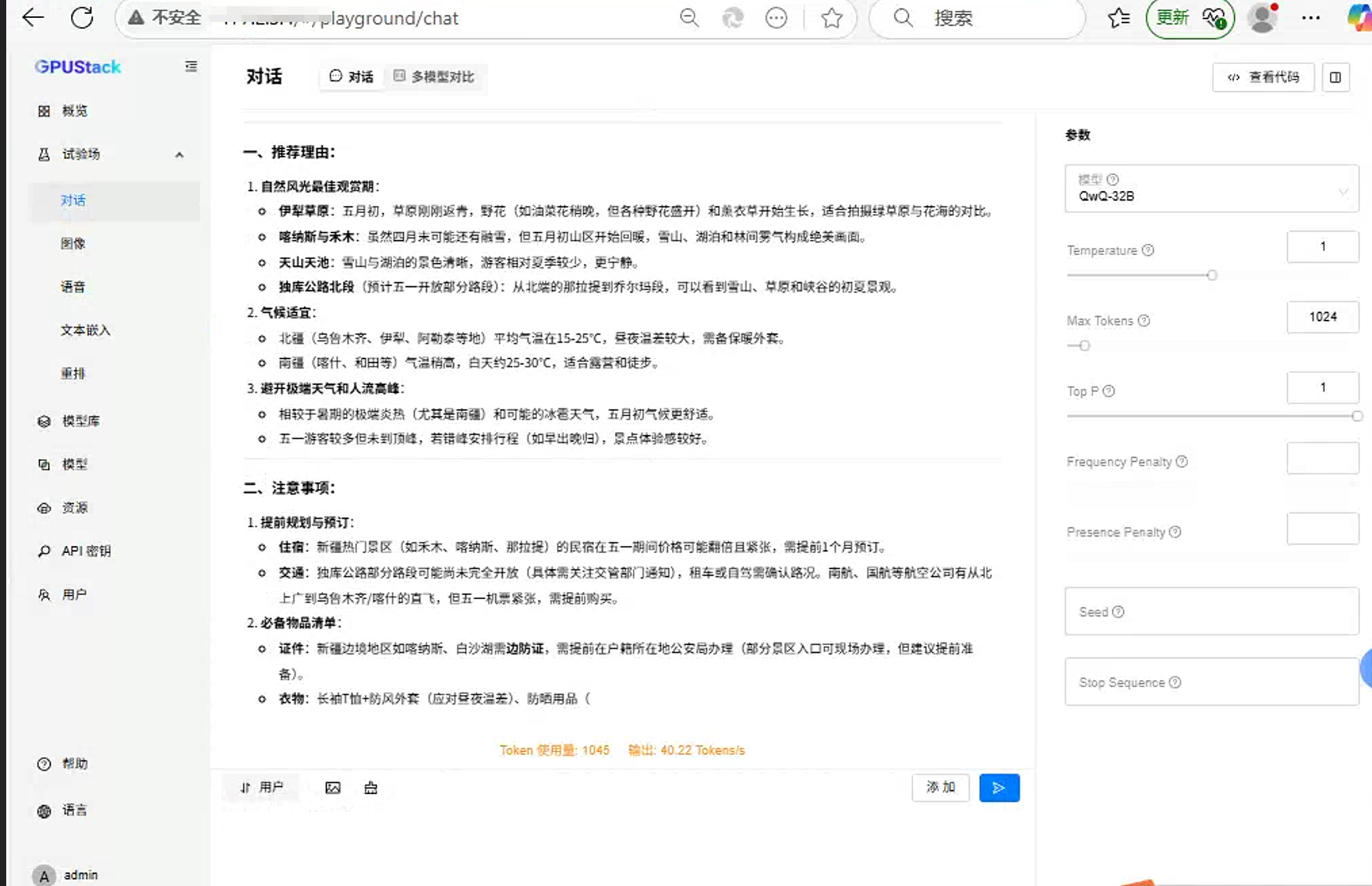
聊天的时候可以检查GPU的使用情况。如下图:
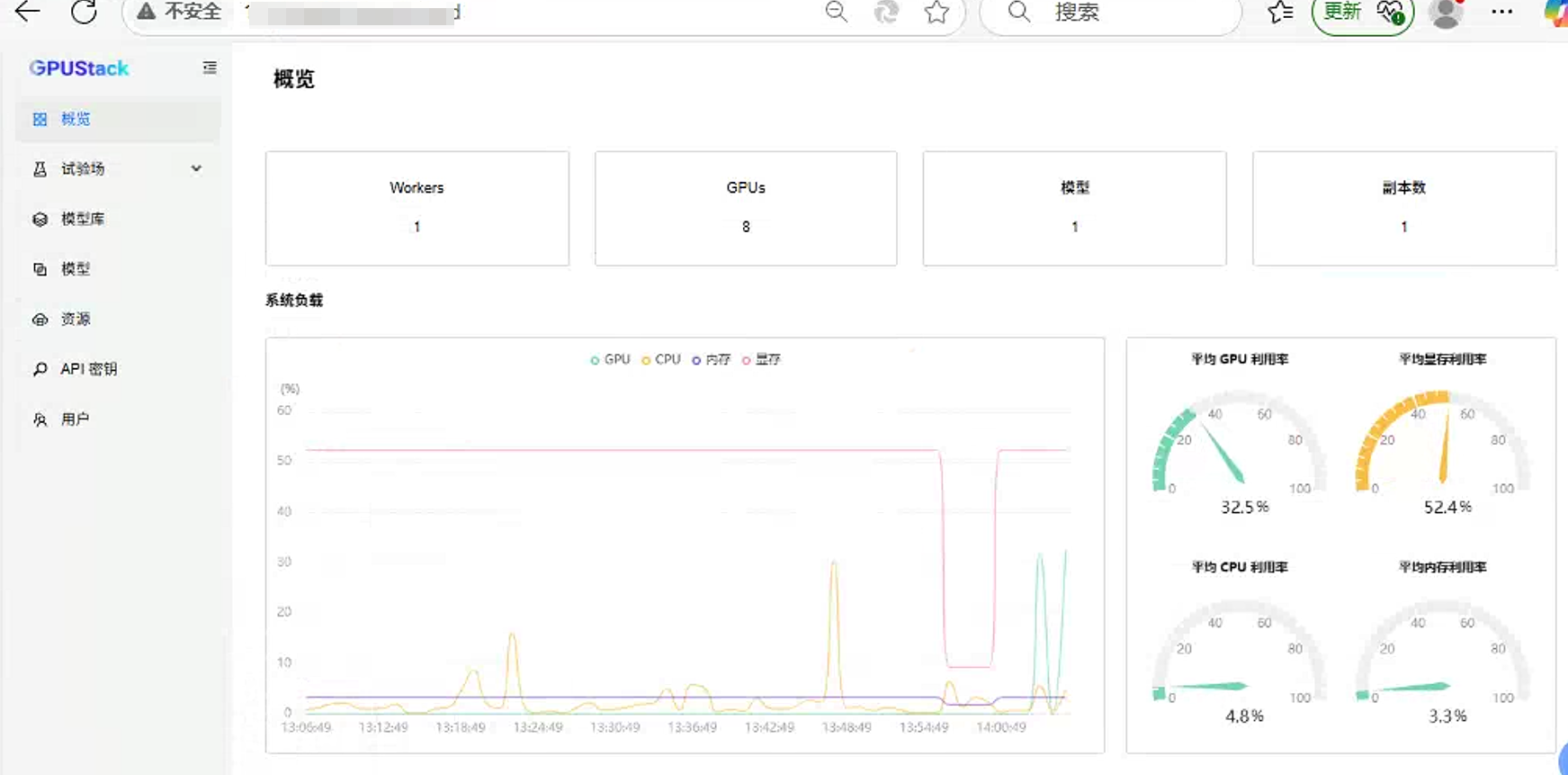
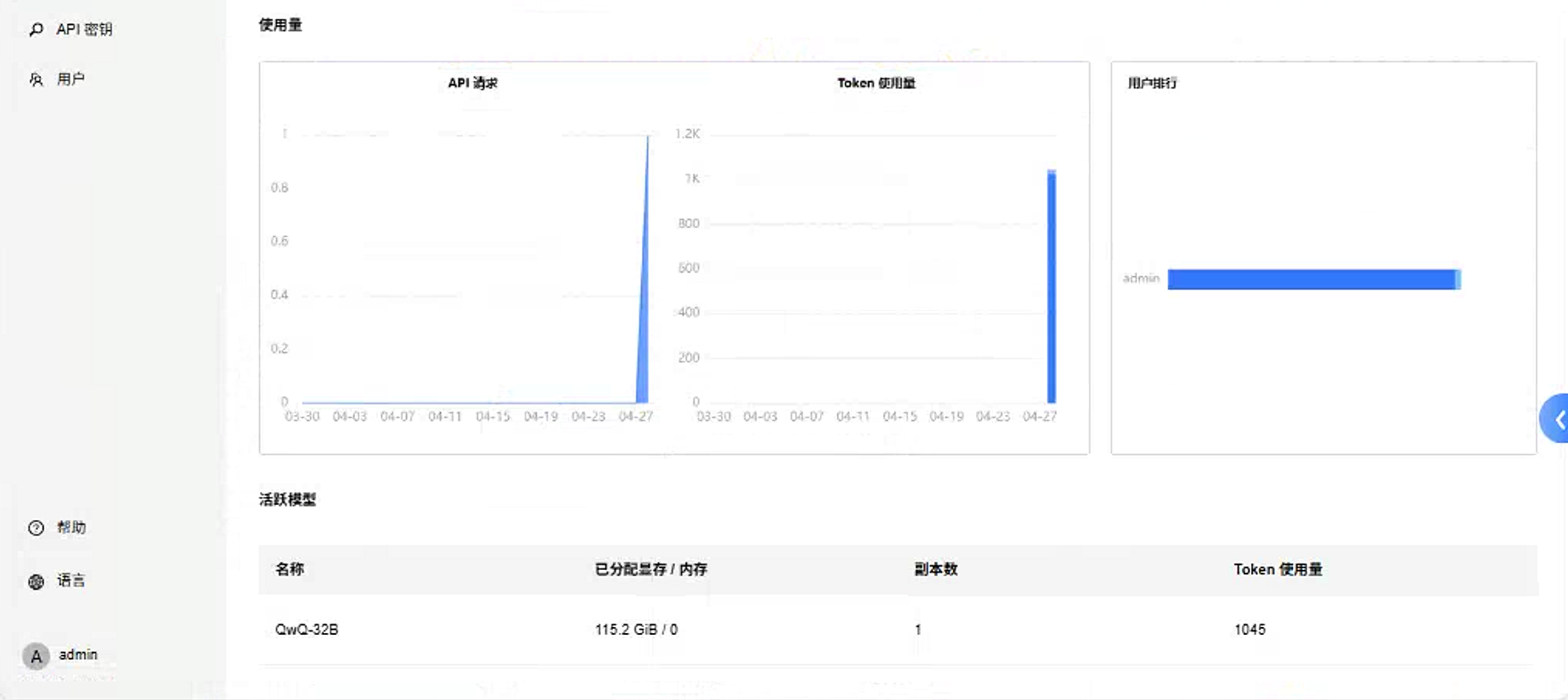
也可以查看tokens使用情况:
四、可以在线下载模型部署
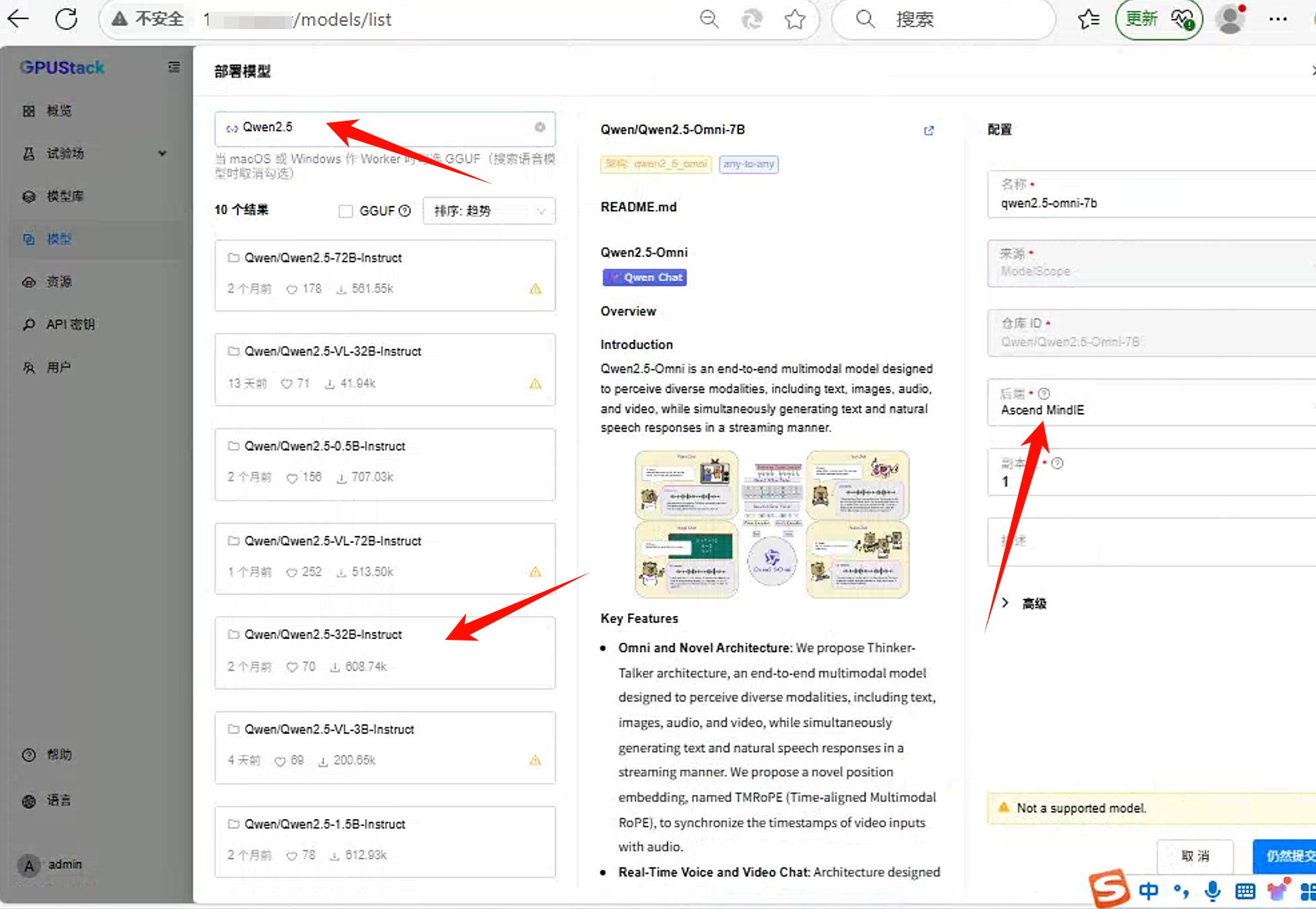
- 例如在线下载Qwen2.5-32B模型。
点击模型->部署模型->modelscope,然后搜索相应的模型部署。(以Qwen2.5-32B为例)
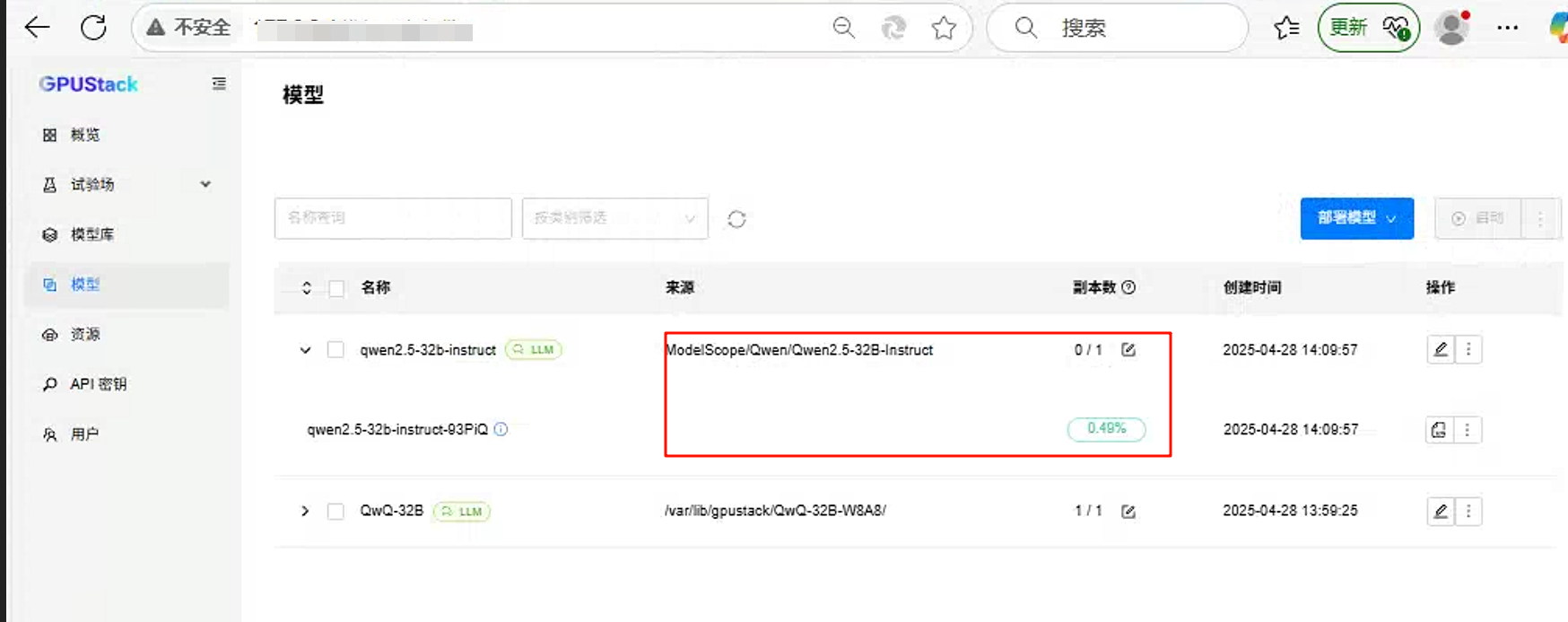
- 模型部署成功。
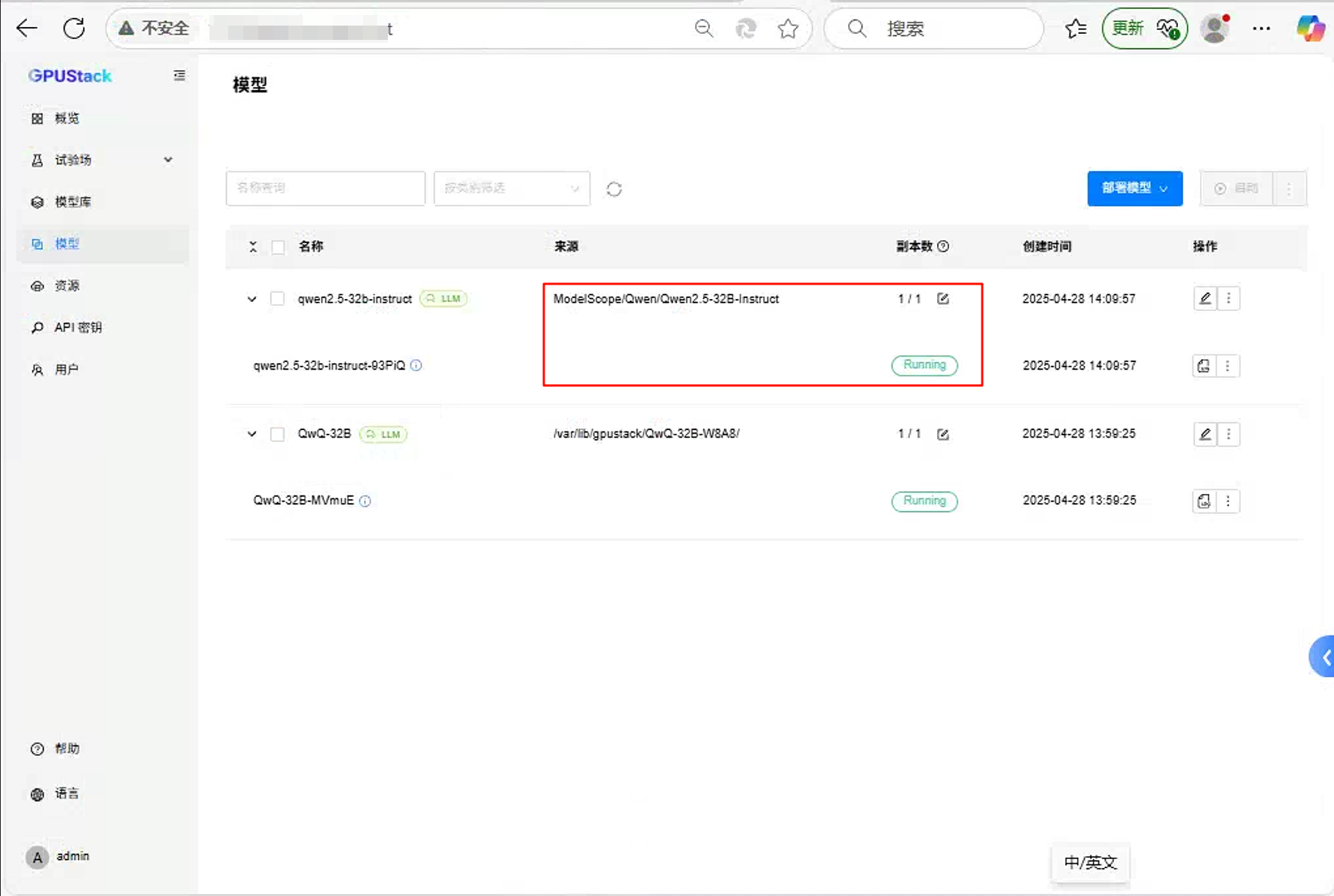
- 聊天测试
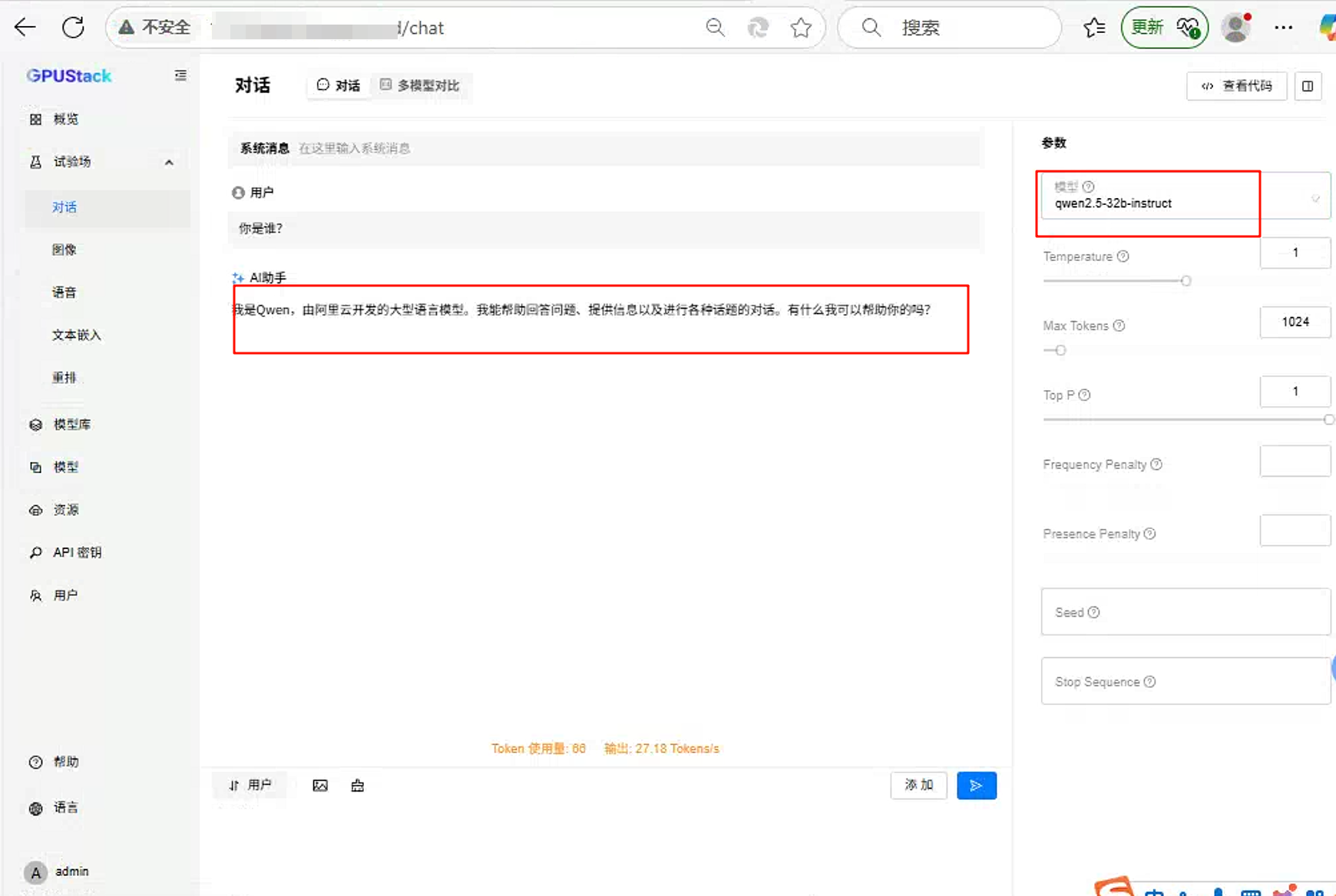
当然目前还有好多功能、好多模型是在昇腾设备上是跑不通的,也希望国内的AI生态更完善,种类更丰富,希望HW能够开源更多的技术底层,让国产化更好用、更强大。
致谢
感谢GPUStack团队提供方便、好用的工具。


















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









