




 文章介绍了如何通过官网的算法,将LiDAR数据转化为语言建模问题,利用LLMs的强大推理能力进行3D场景理解,包括3D标注、3D问答等任务。文章详细阐述了实现流程,包括特征提取、VAT设计以及通过多阶段训练增强模型的高级指令处理能力。
文章介绍了如何通过官网的算法,将LiDAR数据转化为语言建模问题,利用LLMs的强大推理能力进行3D场景理解,包括3D标注、3D问答等任务。文章详细阐述了实现流程,包括特征提取、VAT设计以及通过多阶段训练增强模型的高级指令处理能力。
简介
官网
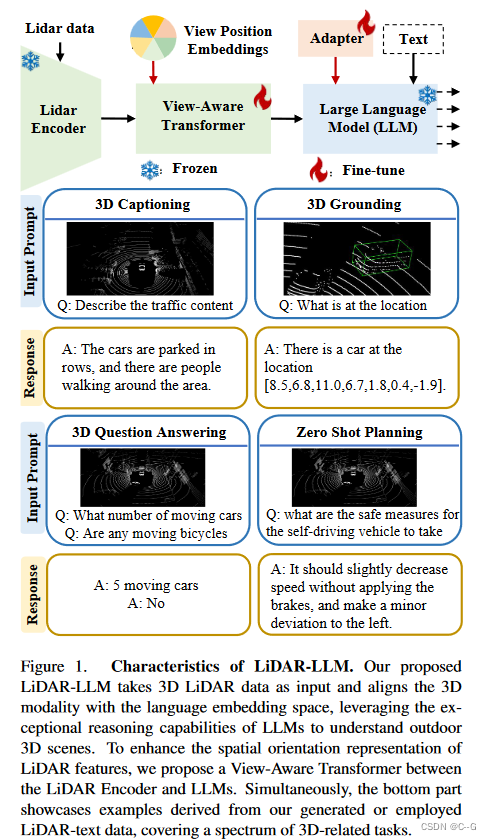
将原始LiDAR数据作为输入,利用LLMs卓越的推理能力,来获得对室外3D场景的全面了解,将3D户外场景认知重构为语言建模问题,如3D captioning, 3D grounding, 3D question answering。
实现流程
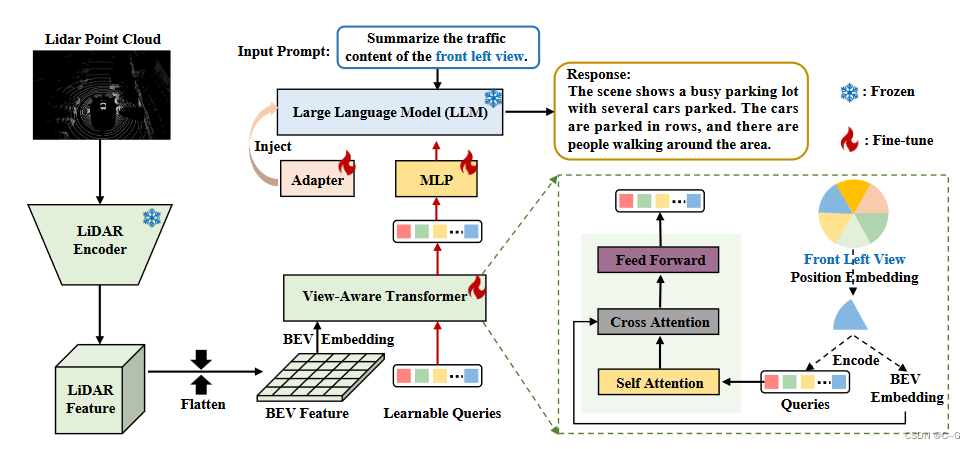
给定LiDAR输入 L ∈ R n × 3 L \in \R^{n \times 3} L∈Rn×3,n 是点的数量,使用 VoxelNet 获取 LiDAR Feature,考虑到计算成本,沿着 z轴展平特征以生成鸟瞰图(BEV) Feature F v ∈ R c × h × w F_v \in \R^{c \times h \times w} F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









