







 文章介绍了一种方法,通过训练扩散模型控制相对摄像机视点,从而在给定初始图像和目标视点的情况下生成新的对象图像,应用于3D重建。该技术结合了CLIP嵌入、扩散目标公式和ScoreJacobianChaining优化,以提高3D表示的保真度和一致性。
文章介绍了一种方法,通过训练扩散模型控制相对摄像机视点,从而在给定初始图像和目标视点的情况下生成新的对象图像,应用于3D重建。该技术结合了CLIP嵌入、扩散目标公式和ScoreJacobianChaining优化,以提高3D表示的保真度和一致性。
简介
官网
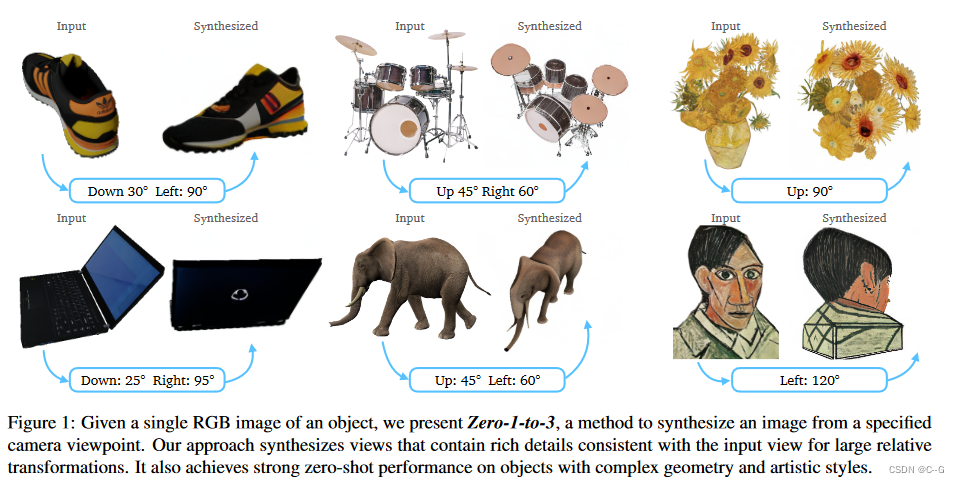
使用合成数据集来学习相对摄像机视点的控制,这允许在指定的摄像机变换下生成相同对象的新图像,用于从单个图像进行三维重建的任务。
实现流程
输入图像
x
∈
R
H
×
W
×
3
x \in \R^{H \times W \times 3}
x∈RH×W×3,所需视点的相对摄像机旋转和平移
R
∈
R
3
×
3
,
T
∈
R
3
R\in \R^{3 \times 3},T \in \R^3
R∈R3×3,T∈R3,合成视点图像的函数公式表示为:
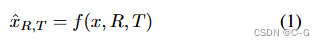
难点:
- 尽管在不同视点的大量对象上训练了大规模生成模型,但其表示并未明确编码视点之间的对应关系。
- 如下图所示,Stable Diffusion倾向于生成具有规范姿势的面向前方的椅子的图像

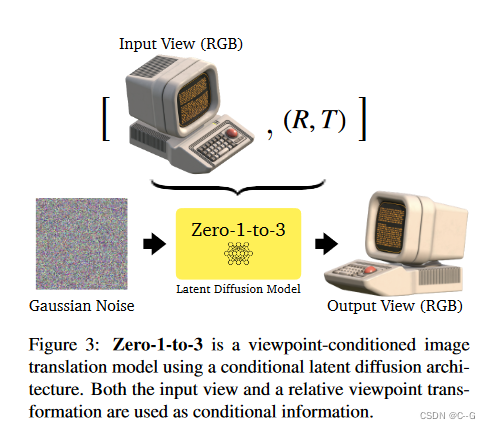
Learning to Control Camera Viewpoint
给定初始图像,目标图像及其相机位姿数据集
{
(
x
,
x
(
R
,
T
)
,
R
,
T
)
}
\{(x,x_{(R,T)},R,T)\}
{(x,x(R,T),R,T)},如下图微调预训练的扩散模型,以便在不破坏其余表示的情况下学习对相机参数的控制。
扩散目标公式表示为:
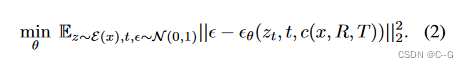
View-Conditioned Diffusion
输入图像的CLIP嵌入与(R, T)连接,形成一个“pose CLIP”嵌入 c(x, R, T)。使用交叉注意来调节去噪的U-Net,它提供了输入图像的高级语义信息。输入图像与被去噪的图像进行通道连接,帮助模型保持被合成对象的身份和细节
3D Reconstruction
采用框架Score Jacobian Chaining (SJC)来优化具有文本到图像扩散模型先验的3D表示,SJC中使用的一项关键技术是将无分类器的引导值设置为显著高于通常值。这种方法减少了每个样本的多样性,但提高了重建的保真度。
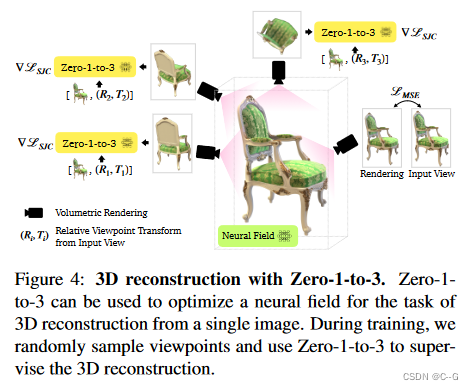
如上图所示,输入图片 x,CLIP嵌入
c
(
x
,
R
,
T
)
c(x,R,T)
c(x,R,T) 和时间 t,以便向无噪声输入
X
π
X_{\pi}
Xπ 近似得分。
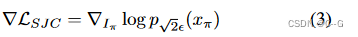
▽ L S J C \triangledown L_{SJC} ▽LSJC 是【Score jacobian chaining: Lifting pretrained 2D diffusion models for 3D generation】引入的PAAS分数。
使用MSE损失来优化输入视图,对每个采样视点应用深度平滑损失,对near-view consistency loss进行正则化,以规范nearby views 之间的变化。
实验
使用Objaverse 数据集(100K+艺术家创建的800K+ 3D模型),对于数据集中的每个对象,随机采样12个指向对象中心的相机外部矩阵,并使用光线追踪引擎渲染12个视图,训练时,每个对象的两个视图形成一个图像对
(
x
,
x
R
,
T
)
(x, x_{R,T})
(x,xR,T)。对应的相对视点变换(R, T)定义了两个透视图之间的映射,可以很容易地从两个外部矩阵中导出。



















 2138
2138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









