







LIDAR 市场分析
1. 自动驾驶市场
1.1 全球自动驾驶市场
技术成熟度方面Waymo目前是处于领先的地位,中国的自动驾驶公司在技术和发展来看都有比较大差距,分析报告参考Waymo 案例分析。
依照目前的势头和资本市场情况看,马斯特的特斯拉一马当先, 目前的市值已经超过7000亿美元,重点分析特斯拉供应链及需求量,参考文章特斯拉供应链. 特斯拉盈利方案可能是靠其软件优势建立生态系统,参考文章特斯拉软件生态。
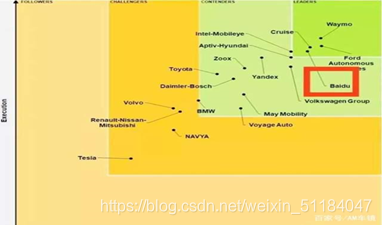
国内市场百度Apollo为第一梯队,其余的产商跟随。纤细资料参考:[中国自动驾驶十大关键公司](D:\0Solar\Lidar\Lidar 行业资料\中国自动驾驶10大关键公司! - 知乎.docx) 。百度Apollo 属于开放式平台。 目前与吉利汽车,威马汽车有深入合作。
**Auto_AI Sheet ** : 表格中收集了目前全球市场所有的整车制造商和方案以及发展历程及大致规模。

1.2 Waymo 供应链
TBD
1.3 特斯拉供应链分析

从特斯拉的供应链列表可以看出目前特斯拉Model Y中并没有LIDAR,联创电子是车载摄像头生产产商, 均胜电子为车载Radar 供应商。 后续L4驾驶系统应该会使用LIDAR传感器。
最新消息,Innovusion 和 均胜电子正在进行深入合作。 主要关注就是激光雷达。与 5G V2X 终端数据连接。


2. LIDAR 产商
2.1 国外重要LIDAR 产商分析。
| LIDAR | Velodyne | Luminar | Innoviz | Aeva | Ouster |
|---|---|---|---|---|---|
| 市值/估值 | 41亿美金(市值)Nasdaq | 107亿美金(市值)(Nasdaq) | 14亿美金(估值) | 21亿美金(估值) | 19亿美金(估值) |
| 核心技术 | 微缩小型激光雷达阵列(MLA) | 光通讯激光功率放大与高灵敏度,1550纳米激光二极管 | MEMS | 线性激光调频芯片(FMCW) | VCSEL+SPAD,全半导体真固态 |
| 技术成熟度 | 高 | 高 | 最高 | 很低 | 一般 |
| 产品性能 | 佳 | 最佳 | 一般 | 佳 | 一般(IBEO可以做到佳) |
| 产品成本 | 中 | 高 | 最低 | 最高 | 低 |
| 产品信噪比 | 一般 | 最高 | 低 | 高 | 一般(IBEO可以做到高) |
| 车规难易度 | 易 | 难 | 易 | 易 | 最易 |
| 体积 | 很小 | 大 | 大 | 大 | 很小 |
| 有效距离 | 远 | 最远 | 一般 | 远 | 近(IBEO可可以做得很远) |
| 合作伙伴 | 现代、福特、维宁尔 | 丰田、沃尔沃 Mobileye | 宝马、麦格纳、 安波福 | 奥迪、采埃孚 | 英伟达、赛灵思 |
这五大激光雷达公司,目前最高的 Luminar 市值超百亿美元,最低 Innoviz 估值也达到 14 亿美元。本田和丰田已确定在其L3级自动驾驶车型上使用激光雷达;奔驰、沃尔沃、宝马、蔚来和小鹏等厂家也准备在2021年的量产车上选用激光雷。激光雷达的真实需求即将到来。
· Velodyne: 核心技术解析:MLA
· Luminar:最高功率带来最高性能
· Innoviz:MEMS 带来最低成本
· Aeva:坚持 FMCW
· Ouster:近似于 Flash 的技术路线
2.2 国内重要LIDAR产商分析
TBD
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2131
2131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









